
This is the second part of a two three four-part series, which covers some recent results on “verifiable computation” and possible pitfalls that could occur there. This post won’t make much sense on its own, so I urge you to start with the first part.
In the previous post we introduced a handful of concepts, including (1) the notion of “verifiable computation” proof systems (sometimes inaccurately called “ZK” by the Ethereum community), (2) hash functions, and (3) some ideal models that we use for our security proofs, and (4) the idea that these “ideal models” are bogus — and sometimes they can make us confident in schemes that are totally insecure in the real world.
Today I want to move forward and (get closer) to actually talking about the recent result alluded to in the title: the recent paper by Khovratovich, Rothblum and Soukhanov entitled “How to Prove False Statements: Practical Attacks on Fiat-Shamir” (henceforth: KRS.) This paper shows that a proving scheme that appears to be secure in one setting, might not actually be secure.
One approach to discussing this paper would be to start at the beginning of the paper and then move towards the end. We will not do that. Instead, I plan to pursue an approach that involves a lot of jumping around. There is a method to my madness.
Before we can get there, we need to cover a bit more essential background.
Background Part One: Interactive proof systems
I have introduced these posts by reiterating a critique of something called the random oracle model paradigm, in which we pretend that hash functions are actually random functions. Thoughtful cryptographers will no doubt be upset with me about this, since in fact the KRS paper is not about random oracles at all! Instead it demonstrates a problem with a different “heuristic” that cryptographers use everywhere: this is called the Fiat-Shamir heuristic.
While Fiat-Shamir is not the same as the random oracle model, the two live in the same neighborhood and send their kids to the same school. What I mean is: Fiat-Shamir can (in some very limited theoretical senses) live without the random oracle model, but in practice the two are usually interdependent.
To explain this new result I therefore need to explain what Fiat-Shamir does. And before I can do that, I need to explain what interactive proofs are. (Feel free to skip forward if you already know this part.)
Many of the verifiable computation “proof systems” we use today are members of a class of protocols called interactive proofs. These are protocols in which two parties, a Prover and a Verifier, exchange messages so that the Prover can convince a Verifier of the truth of a given statement (such as “I know an input x that makes this particular program happy.”, and maybe a witness w to help me prove that) In many cases, these protocols obey a pattern of interaction that takes the following form:

- The Prover sends a message that “commits” to the input and witness, and maybe some other things. This commitment message is sent to the Verifier.
- The Verifier then generates one or more challenges that the Prover must respond to. The exact nature of what happens here can change from scheme to scheme.
- The Prover then computes responses to each of the challenges, and the Verifier checks that each response is valid (again, in a manner that is highly specific to the proving scheme.) It rejects the proof if any of the responses don’t check out.
- The pair may repeat the above steps many times — either sequentially or in parallel.
Yes I know that I’m being incredibly vague about what’s happening with these challenges and responses! The truth is that, for the moment, we don’t care. All you need to know is that the challenge/response bits should be easy for the Prover to respond to if it is being honest, that is — that is, if the witness (input) really satisfies the program. It should be unlikely that the Prover can correctly respond to a random challenge if it’s cheating, i.e., if it does not have a proper witness.
(Note that we don’t demand that the challenges be impossible for a cheating Prover to sneak past! This is why proving systems often repeat the challenge/response phase many times: even if there’s a small chance that a cheating Prover could cheat their way through one challenge, we’d argue that they have a much lower probability of cheating many times.)
What you may notice about this entire setup is that (1) interactive proofs require lots of (duh) interaction. What might not be so obvious is that (2) they assume an honest Verifier who formulates “good” challenges.
This need for interaction is pretty annoying in many applications. It is particularly aggravating for systems like blockchains, where there can be thousands (or millions) of computers who will all need to verify that a given statement (say, a transaction) is correct. It would be much, much easier if the Prover could run the proof just once time with a single Verifier, then the pair could just publish the transcript of their interaction. Anyone could just check the transcript to make sure the Prover answered all the challenges correctly!
Unfortunately, there is a critical problem with that idea! The security of these protocols rides on the idea that the Verifier’s challenges are random, or at least highly unpredictable to the Prover. If the Prover can somehow anticipate which values it will be challenged on before it commits to its inputs in step (1), it can often cheat by altering its approach in the first message. To be more concrete: a dishonest Verifier can “collude” with the Prover to help it prove a false statement, by sneakily letting it know the challenges in advance. For this reason it is: critically important that the Verifier must be honest, and not colluding with the Prover.
But the whole point of these systems is that we shouldn’t need to trust individual parties at all! If we’re just going to trust that people are behaving honestly, what’s the point of any of this?
More background: Fiat-Shamir
Now I want to take you way back in time. All the way back to the mid-1980s.

Back in 1986, two cryptographers named Amos Fiat and Adi Shamir (pictured above) were stuck on a problem very much like this one. They had an interactive proof system — a much simpler one, since it was the 1980s after all — and they wanted to turn their interactive proofs into non-interactive proofs that any party could verify. They thought about the transcript idea described above, and they realized it wouldn’t work — a Verifier could simply collude with the Prover to help it cheat. To address this, they came up with an ingenious solution that was elegant, simple, and also would open up a yawning chasm of theory that we are still trying to dig out of today.
Fiat turned to Shamir (I imagine) and outlined the overall problem. Fiat (or Shamir) said: “Perhaps we could find a way for a Verifier to select the challenges in some random but reproducible way — one that would allow anyone to ensure that the challenges were actually random and unpredictable.” And then one of them said: that sounds a lot like a hash function.
And thus was born the Fiat-Shamir heuristic.
Instead of choosing the challenge values at random, Fiat and Shamir proposed that the “Verifier” would select the challenge values by hashing the “commitment” message sent by the Prover, perhaps along with other junk (such as the “program” or circuit being proved.) The Prover would then respond to these challenge messages, and output a transcript of the whole proof.
And that’s it. That’s the entire trick.
Despite its simplicity, there are some obvious attractive features to this Fiat-Shamir approach:
- Good hash functions typically output stuff that looks pretty “random”, which is what we want for challenges.
- Any third party can easily check a transcript, simply by verifying that the challenge values match the hash of the Prover’s “commitment” message. (In other words, there’s no more room for the Verifier to collude or cheat, since it is now fully deterministic.
Critically, there is a cool “circular” paradox in here. A cheating Prover might try the following trick to predict the values it will be challenged on. Specifically, it might (1) pick a commitment message and then (2) hash that message to find the challenges. Once it knows the challenge values, it might try to change its inputs to step (1) so it can more easily cheat on those specific challenge points. But critically that approach creates a paradox…! if the Prover changes its inputs to step (1), that will result in a whole new “commitment” message! Once hashed, that new commitment message will produce a very different set of challenge messages, and our cheater is locked in an infinite time-loop that it can never escape!1

The great thing about Fiat-Shamir is that once your (challenge-generating) Verifier is fully deterministic, there’s no more reason to even have that code run by a separate party. The Prover can run the deterministic challenge-generation code all by itself, i.e., performing all necessary hashing to make the challenges, and then outputting the final transcript. So the Prover and (original) “Verifier” code collapse into a single party (that we will now just call the Prover), and the new Verifier is an algorithm that checks the transcript — performing all the necessary hashes and challenge/response checks to make sure everything is kosher.
The resulting proofs (“transcripts”) do not require any interaction to verify, and so we can even post them on blockchains. They can be verified by thousands or millions of people, and we are now set to hang big piles of money off of them.

I bet you’re going to yammer on about the provable security of Fiat-Shamir now, right?
Wait, how did you know that’s what I was going to talk about? Oh that’s right: “you” are me, and so I’m just answering my own questions. (Wasn’t that a cute illustration of the paradox that Fiat-Shamir helps to solve!)
I am going to make this as quick and painless as I can, but here’s the deal. Fiat-Shamir seems like a nutty trick. We even call it a heuristic, which is literally an admission of this. And yet. Literally hundreds of papers have been written about the provable security of Fiat-Shamir and schemes that use it.
The general TL;DR is that Fiat-Shamir can often be proven secure (for various definitions of “secure”) if we make one helpful assumption. Specifically: that the hash function we use is actually a random oracle (please see this footnote for more pedantic stuff!2) I’m not going to get very deep into the argument, but I just want you to remember how random oracles work:
- In the random oracle model, the hash function is a random function. Phrased imprecisely, this means that (when queried on some fresh value) it outputs random bits that are completely uncorrelated with the input.
- The hash function “lives” inside a totally separate party called an oracle. You send things to be hashed, if the input has not been hashed before, you get back unpredictable random values.
This clearly looks a lot like the interactive proof setting! Put succinctly (no pun): if an appropriate scheme can be proven secure in an interactive setting where the Prover interacts with an honest Verifier (who picks random challenges), then it seems likely that the Fiat-Shamir version of that protocol should also work with a random oracle. The random oracle is essentially acting like the Verifier in the original interactive scheme: it is generating random challenges that everyone can “trust” to be truly random, and yet any third party can also ask it to reproduce the same challenges later on, when they want to check a transcript!

And for many purposes, this random oracle approach usually works ok. Some folks have come up with crazy theoretical counterexamples (meaning, contrived interactive protocols that are secure in the random oracle model, yet blow apart when used with real hash functions.) But mostly practitioners just ignore these because they’re so obviously full of weird nonsense.
Out in the real world where applied cryptographers design new proving systems on a daily basis, we’ve adopted a pretty standard pattern. A new proof system will be specified as an interactive protocol first. Ultimately everyone knows this proof system won’t be used interactively, it will be Fiat-Shamir flattened and used on a blockchain. Yet the authors won’t spend a lot of time arguing about the Fiat-Shamir part. They’ll simply describe an interactive protocol with the right structure, then they say something like “of course this can be flattened using Fiat-Shamir, if we assume a random oracle or something” and everyone nods and deposits a billion dollars onto it.
But there’s a catch, isn’t there?
Indeed, there is a major asterisk (*) about this whole strategy that I must now raise.
Even though we can sometimes prove Fiat-Shamir protocols secure, usually in the ROM, a critical feature of these ROM proofs is that we (the participants in the protocol) do not know a compact description of the hash function. This is inevitable, since the hash function used in the random oracle model is a giant random function that cannot possibly expressed in a compact form.
In the real world we will naturally replace the random oracle with something like SHA-3 or an even more exciting hash function like Poseidon. Suddenly, everyone in the protocol will know a compact description of the hash function. As I mentioned above, this can lead to theoretical problems. Way back in 2004, Goldwasser and Tauman (now Kalai) designed a specific interactive protocol that exploded when the hash was instantiated with any concrete hash function.
But the Goldwasser/Tauman protocol was very artificial. It did silly things you could see in the protocol description. So obviously as long as we don’t do those things, we were fine, maybe?
The problem now is that we are deploying proof systems that can prove the satisfaction of literally any reasonable program (or “NP-relation”.) These programs might contain an implementation of the Fiat-Shamir hash function. In the random oracle model, this is literally impossible — so we just assume it cannot happen. In the real world it’s eminently possible, and we kind of have to assume it can and will happen.
In fact it is extremely likely that some circuits really will contain an implementation of the Fiat-Shamir hash function! The reason is because of those recursive proofs I mentioned in the previous post.
Let’s say we want to build a recursive proof system that works to verify one of our flattened Fiat-Shamir proofs. Recall that to do this, we have to take the Verify algorithm that checks a Fiat-Shamir transcript, and implement it within a program (or circuit.) We then need to run that program and generate a proof that we ran that program successfully! And to make all this work, we really do need to include a copy of the Fiat-Shamir hash function inside our programs — this is not optional at all.
The crazy thing is that we can’t even prove these recursive Fiat-Shamir-based proofs secure in the random oracle model! In the random oracle model there is no compact description of the hash function, and so no there is no compact recursive Verify program/circuit that we could write. Recursion of this sort is totally impossible. Indeed, recursive Fiat-Shamir proofs can only exist outside of the random oracle model, where we use something like SHA-3 to implement the hash function. But of course, outside of the ROM we can’t prove anything about their security. As a result: anytime you see a recursive Fiat-Shamir proof we’re just basically tossing provable security out the window and full-on YOLOing it.
This situation is very bad and many theoreticians have died (inside) thinking about it.
I have now written an entire second post and I have not yet gotten to the KRS result I came here to talk about! Is anyone still reading? Is this thing still on? I sure hope so.
We are now ready to talk about KRS, and I am going to do that immediately in the next post. Before I close this post and get ready for the big one I will tackle next, allow me recap where we are.
- We know that Fiat-Shamir can be proven secure, but generally (for full-on SNARKs) only in the random oracle model.2
- Once we actually instantiate Fiat-Shamir with real hash functions, any weird thing could happen: especially if the same hash function is implemented within the programs/circuits we want to prove things about.
- Recursive (Fiat-Shamir) proofs actually require us to implement the hash function inside of the programs we’re going to prove things about, so that’s ultra-worrying.
What remains, however, is to demonstrate that Fiat-Shamir can actually be insecure in practice. Or more concretely: that there exist “evil” programs/circuits that can somehow break a perfectly good proof system that uses Fiat-Shamir.
In the next post I’m finally going to talk about that.
Notes:
- The Fiat-Shamir technique isn’t immune to a few obvious attacks, of course. For example: a cheating Prover (who is typically also the “Verifier”) can “grind” the proof — by trying many different inputs to the first message and then, for each one, testing the resulting challenges to see if they’re amenable to cheating. If there is a small probability of cheating, this “try the game many times” approach can significantly boost a cheater’s probability of getting lucky at cheating on a challenge/response, since they now have millions (or billions!) of attempts to find a lucky challenge.
However, a realistic assumption here is that real-world cheating Provers only have so much computing power. Even if a Prover can try a huge number of hashing attempts (say 250) you can easily set up your scheme so that the probability they succeed is still arbitrarily small. Not everyone does this perfectly, of course: my PhD student Pratyush recently co-authored a nice paper about the parameter choices made by some real-world blockchain Proving systems. - When I say that the provable security of Fiat-Shamir depends on the random oracle model, I am being slightly imprecise. The random oracle model is usually sufficient to prove claims about Fiat-Shamir. But in fact there are some (relatively) recent results that show how to construct Fiat-Shamir for very specific interactive protocols using hash functions that are not random oracles: these are called correlation intractable functions. To the best of my knowledge, it is not possible to prove Fiat-Shamir-based SNARKs that work with arbitrary (adaptively-chosen) programs/circuits using these functions. But I am open to being wrong on this detail.


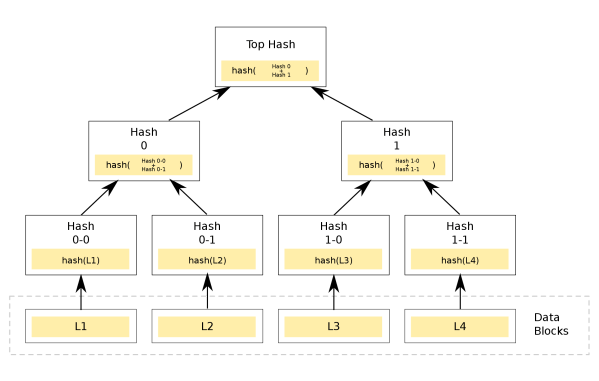
 they don’t do it themselves. They instead calling out to a third party, the “random oracle” who keeps a giant table of random function inputs and outputs. At a high level, the model looks like sort of like this:
they don’t do it themselves. They instead calling out to a third party, the “random oracle” who keeps a giant table of random function inputs and outputs. At a high level, the model looks like sort of like this:
 . Building this new scheme will mostly consist of grafting weird bells and whistles onto the algorithms of the original scheme S.
. Building this new scheme will mostly consist of grafting weird bells and whistles onto the algorithms of the original scheme S.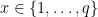 with the specific requirement that q is an integer such that
with the specific requirement that q is an integer such that  . Here
. Here  represents the length of the encoding of program P in bits, and k is the scheme’s adjustable security parameter (for example, k=128).
represents the length of the encoding of program P in bits, and k is the scheme’s adjustable security parameter (for example, k=128).
















 and I’ll pick a bit
and I’ll pick a bit  at random, and return to you the encryption of
at random, and return to you the encryption of  , which I will denote as
, which I will denote as ") .
. I’ll reject your attempt. But I’ll decrypt any other ciphertext you send me, even if it’s only slightly different from
I’ll reject your attempt. But I’ll decrypt any other ciphertext you send me, even if it’s only slightly different from  . They “win” the game if
. They “win” the game if  .
. at step (3). It must be the case that I cannot easily “maul” that ciphertext into a new ciphertext
at step (3). It must be the case that I cannot easily “maul” that ciphertext into a new ciphertext  that contains a closely related plaintext (and that the challenger will be able and willing to meaingfully decrypt). It’s easy to see that if I could get away with this, by the rules of the game I could probably win at step (4), simply by sending
that contains a closely related plaintext (and that the challenger will be able and willing to meaingfully decrypt). It’s easy to see that if I could get away with this, by the rules of the game I could probably win at step (4), simply by sending  or
or  . (This is, in fact, a very weak explanation of what the Bleichenbacher attack does.)
. (This is, in fact, a very weak explanation of what the Bleichenbacher attack does.) and
and  that don’t exist in the v1.5 predecessor. (These are sometimes referred to as “mask generation functions”, which is just a fancy way of saying they’re hash functions with outputs of a custom, chosen size. Such functions can be easily built from existing hash functions like SHA256.)
that don’t exist in the v1.5 predecessor. (These are sometimes referred to as “mask generation functions”, which is just a fancy way of saying they’re hash functions with outputs of a custom, chosen size. Such functions can be easily built from existing hash functions like SHA256.)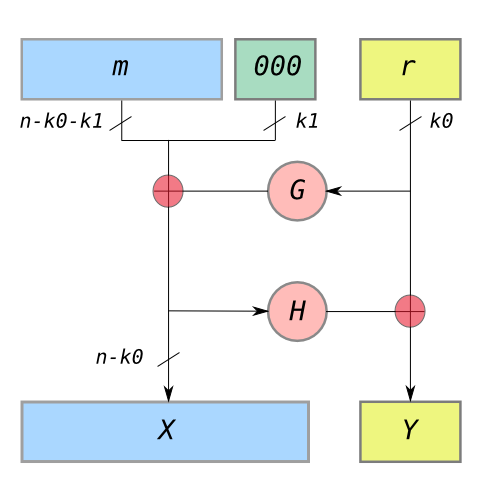
 and some random padding
and some random padding  to a padded message) and backwards — that is, it’s an easily-invertible permutation. The key to this feature is the Feistel network structure.
to a padded message) and backwards — that is, it’s an easily-invertible permutation. The key to this feature is the Feistel network structure. where
where  is an RSA public key of unknown factorization and “programming” the random oracles such that
is an RSA public key of unknown factorization and “programming” the random oracles such that  . The intuitive idea is that an attacker who is able to learn something about the underlying message must query the functions
. The intuitive idea is that an attacker who is able to learn something about the underlying message must query the functions  such that
such that 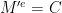 .
.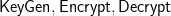 . We’ll also make use of two independent hash functions
. We’ll also make use of two independent hash functions 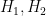 .
. algorithm is randomized. This actually has to be the case, due to the definition of IND-CPA. (See
algorithm is randomized. This actually has to be the case, due to the definition of IND-CPA. (See  to produce the random bits that will be used for encryption. This turns a randomized encryption into a deterministic one. (This, of course, requires that both the input and the internals of
to produce the random bits that will be used for encryption. This turns a randomized encryption into a deterministic one. (This, of course, requires that both the input and the internals of  , which we’ll express as some fixed-length string of bits:
, which we’ll express as some fixed-length string of bits: from the message space of the original CPA-secure scheme.
from the message space of the original CPA-secure scheme.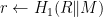 .
. . Note that here
. Note that here 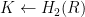 .
. .
.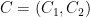 .
.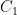 , which (if all is well) should give us
, which (if all is well) should give us 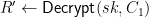 .
.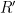 to recover the key
to recover the key  and thus the message
and thus the message 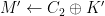 .
.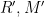 are valid by re-computing the randomness
are valid by re-computing the randomness  and verifying the condition
and verifying the condition  . If this final check fails, simply output a decryption error.
. If this final check fails, simply output a decryption error.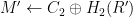 . So what we really want to prove is that in order to construct a valid ciphertext the attacker must already know
. So what we really want to prove is that in order to construct a valid ciphertext the attacker must already know  . The idea of this proof is that it should be hard for an attacker to construct such a
. The idea of this proof is that it should be hard for an attacker to construct such a  . If she has called the hash function to produce this portion of the ciphertext, then she already knows those values and the decryption oracle provides her with no additional information she didn’t already have. (Alternatively, if she did not call the hash function, then her probability of making a valid
. If she has called the hash function to produce this portion of the ciphertext, then she already knows those values and the decryption oracle provides her with no additional information she didn’t already have. (Alternatively, if she did not call the hash function, then her probability of making a valid  . In this case her strategy is twofold: she can tamper with the first portion of the ciphertext and/or she can tamper with the second. But it’s easy to see that this will tend to break some portion of the decryption checks:
. In this case her strategy is twofold: she can tamper with the first portion of the ciphertext and/or she can tamper with the second. But it’s easy to see that this will tend to break some portion of the decryption checks: , she will change the recovered message into a new value that we can call
, she will change the recovered message into a new value that we can call  . However this will in turn (with overwhelming probability) cause the decryptor to recover very different random coins
. However this will in turn (with overwhelming probability) cause the decryptor to recover very different random coins  than were used in the original construction of
than were used in the original construction of  , and thus decryption check on that piece will probably fail.
, and thus decryption check on that piece will probably fail.
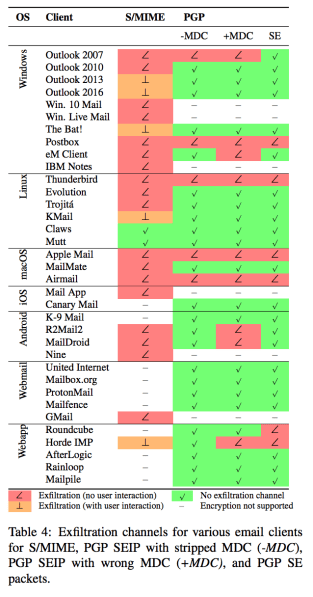

 and I’ll pick a bit
and I’ll pick a bit  at random, and return to you the encryption of
at random, and return to you the encryption of  , which I will denote as
, which I will denote as  .
. . They “win” the game if
. They “win” the game if 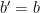 .
. that we are now allowed to submit for decryption. We are now allowed (by the rules of the game) to submit this ciphertext, and obtain
that we are now allowed to submit for decryption. We are now allowed (by the rules of the game) to submit this ciphertext, and obtain 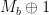 , which we can use to figure out
, which we can use to figure out 
 that researchers have spent the past forty years designing. We see this every day in examples ranging from
that researchers have spent the past forty years designing. We see this every day in examples ranging from  to be considered a ‘cryptographic’ hash, it must achieve some specific security requirements. There are a number of these, but here we’ll just focus on three common ones:
to be considered a ‘cryptographic’ hash, it must achieve some specific security requirements. There are a number of these, but here we’ll just focus on three common ones: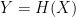 , it should be time-consuming to find an input
, it should be time-consuming to find an input  such that
such that 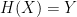 . (There are many caveats to this, of course, but ideally the best such attack should require a time comparable to a brute-force search of whatever distribution
. (There are many caveats to this, of course, but ideally the best such attack should require a time comparable to a brute-force search of whatever distribution  such that
such that 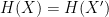 .
. such that
such that 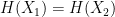 . Note that this is a much stronger assumption than second-preimage resistance, since the attacker has complete freedom to find any two messages of its choice.
. Note that this is a much stronger assumption than second-preimage resistance, since the attacker has complete freedom to find any two messages of its choice.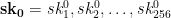
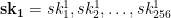
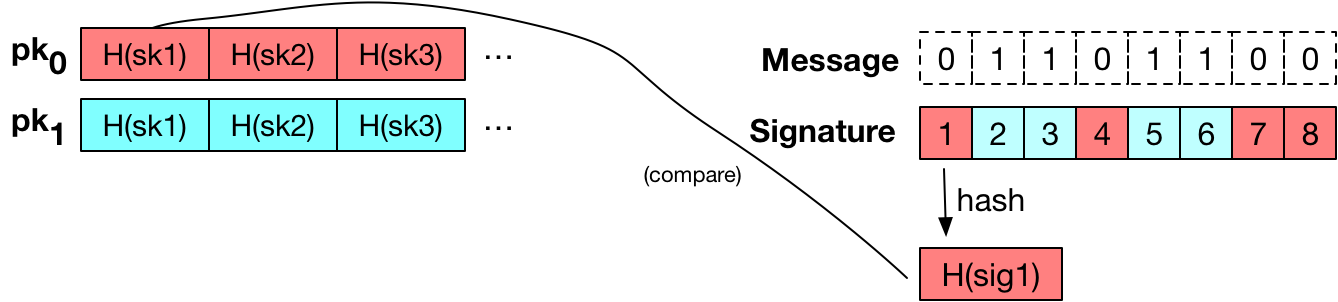
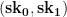 represent the secret key that we’ll use for signing. To generate the public key, we now simply hash every one of those random strings using our function
represent the secret key that we’ll use for signing. To generate the public key, we now simply hash every one of those random strings using our function 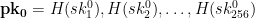

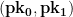 to the entire world. For example, we can send it to our friends, embed it into a certificate, or post it on
to the entire world. For example, we can send it to our friends, embed it into a certificate, or post it on 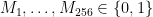
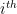 message bit
message bit  , we grab the
, we grab the  from the
from the  list, and output that string as part of our signature. If the message bit
list, and output that string as part of our signature. If the message bit 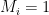 we copy the appropriate string
we copy the appropriate string 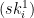 from the
from the  list. Having done this for each of the message bits, we concatenate all of the strings we selected. This forms our signature.
list. Having done this for each of the message bits, we concatenate all of the strings we selected. This forms our signature.
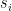 represent the
represent the 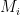 and computes hash
and computes hash  . If
. If 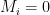 the result should match the corresponding element from
the result should match the corresponding element from  . If
. If 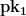 .
.
 , then I’m going to end up handing out both secret key values for that position. This can be a problem.
, then I’m going to end up handing out both secret key values for that position. This can be a problem.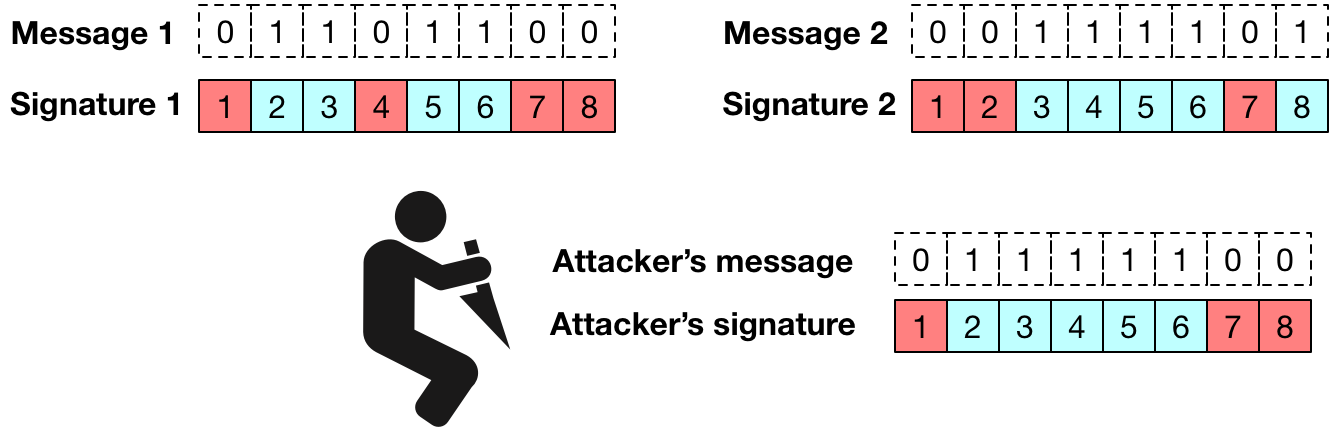
 of them. The most obvious approach is to simply generate
of them. The most obvious approach is to simply generate  .
.
 in our secret key. For each bit position of the message where
in our secret key. For each bit position of the message where  . For every position where
. For every position where 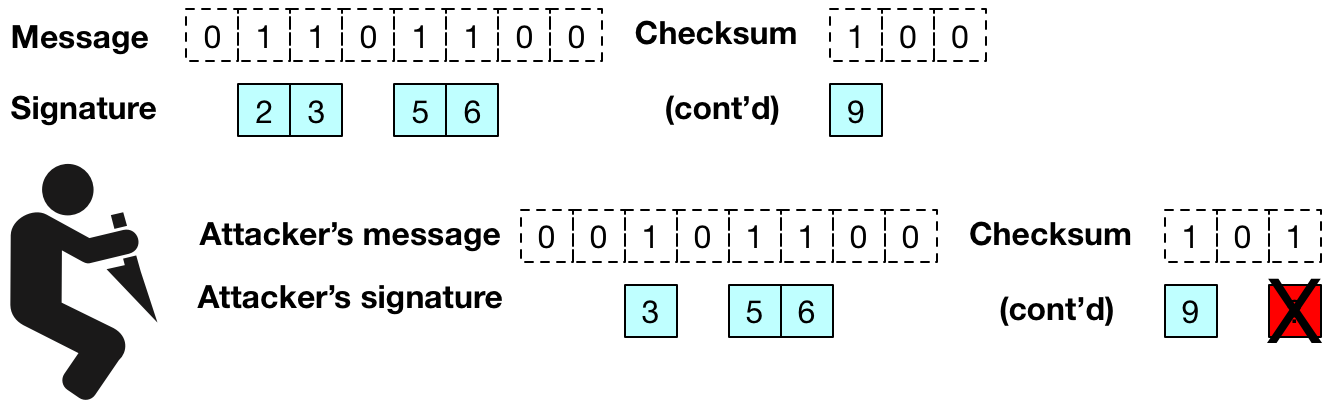
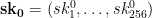 for our initial secret key. Rather than generating additional lists randomly, he proposed to use the hash function
for our initial secret key. Rather than generating additional lists randomly, he proposed to use the hash function 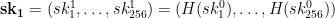 . And similarly, one can use the hash function again on that list to get the next list
. And similarly, one can use the hash function again on that list to get the next list  . And so on for many possible lists.
. And so on for many possible lists.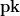 . (In practice we only need 255 secret key lists, since we can treat the final secret key list as the public key.) The elegance of this approach is that given any one of the possible secret key values it’s always possible to check it against the public key, simply by hashing forward multiple times and seeing if we reach a public key element.
. (In practice we only need 255 secret key lists, since we can treat the final secret key list as the public key.) The elegance of this approach is that given any one of the possible secret key values it’s always possible to check it against the public key, simply by hashing forward multiple times and seeing if we reach a public key element.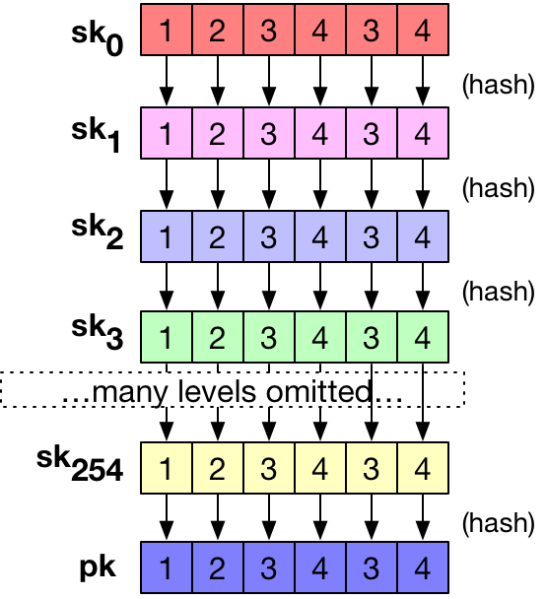
 . For bytes with the maximal value “255” we don’t have a secret key list. That’s ok: in this case we can output an empty string, or we can output the appropriate element of
. For bytes with the maximal value “255” we don’t have a secret key list. That’s ok: in this case we can output an empty string, or we can output the appropriate element of 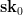 . The verifier only holds the public key vector and (as mentioned above) simply hashes forward an appropriate number of times — depending on the message byte — to see whether the result is equal to the appropriate component of the public key.
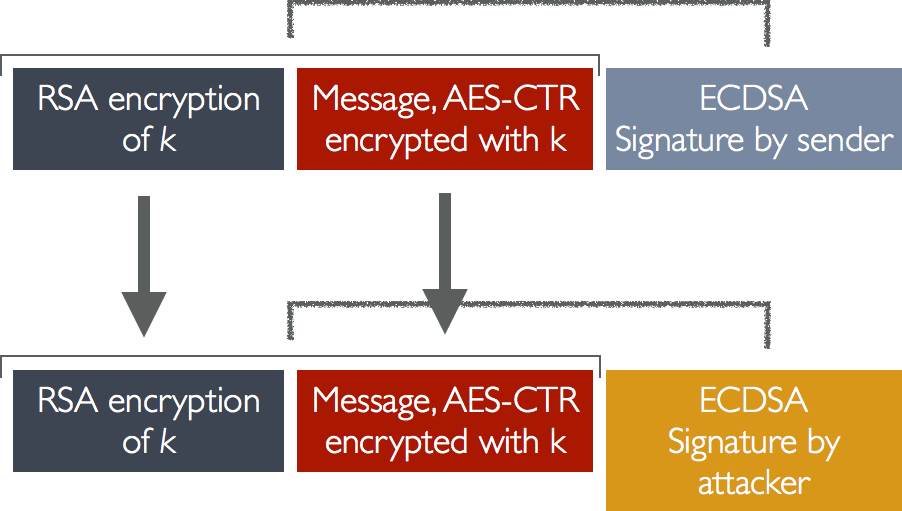
. The verifier only holds the public key vector and (as mentioned above) simply hashes forward an appropriate number of times — depending on the message byte — to see whether the result is equal to the appropriate component of the public key. ), anyone who sees a message that signs the message “0” can easily change the corresponding byte of the message to a “1”, and update the signature to match. In fact, an attacker can increment the value of any byte(s) in the message. Without some check on this capability, this would allow very powerful forgery attacks.
), anyone who sees a message that signs the message “0” can easily change the corresponding byte of the message to a “1”, and update the signature to match. In fact, an attacker can increment the value of any byte(s) in the message. Without some check on this capability, this would allow very powerful forgery attacks.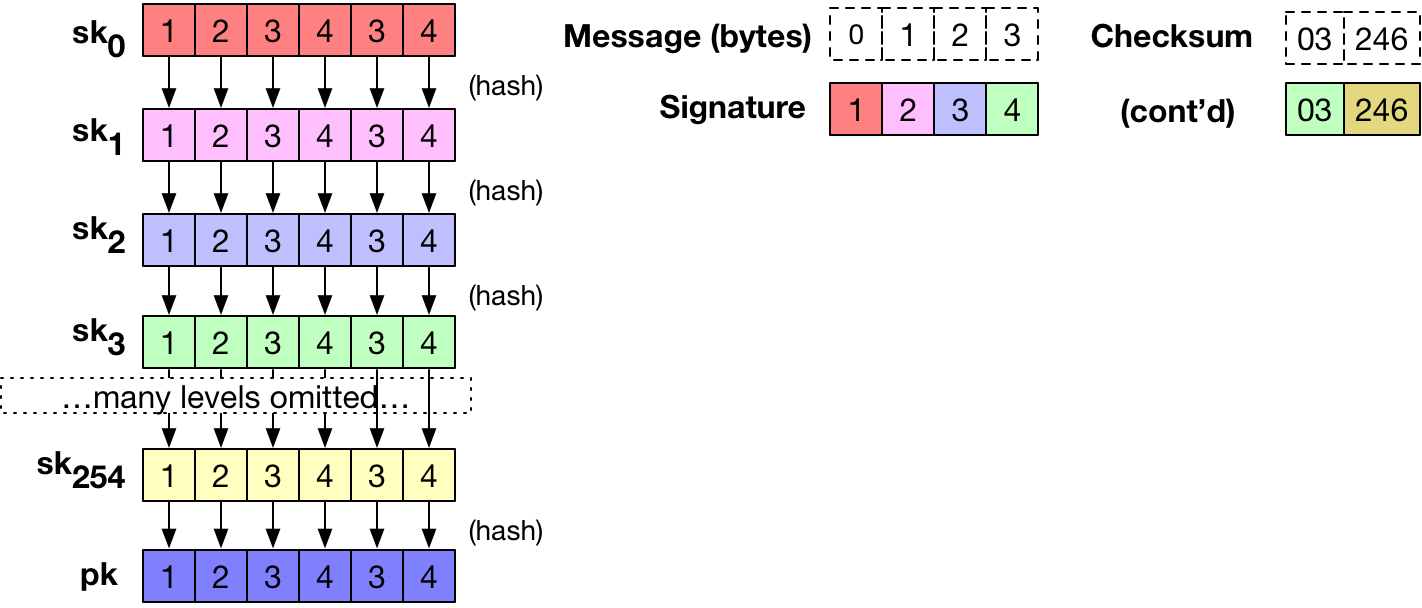
 , an attacker who is able to compute hash preimages can easily recover a valid secret key for that component of the signature. This attack obviously renders the scheme insecure.
, an attacker who is able to compute hash preimages can easily recover a valid secret key for that component of the signature. This attack obviously renders the scheme insecure.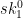 . If such an attacker can find a second pre-image for the public key
. If such an attacker can find a second pre-image for the public key  she can’t sign a different message. But she has produced a new signature. In the strong definition of signature security (
she can’t sign a different message. But she has produced a new signature. In the strong definition of signature security (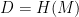 and then the sign the resulting value
and then the sign the resulting value  instead of the message.
instead of the message.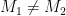 such that
such that 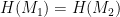 has now found a valid signature on two different messages. This leads to a trivial break of
has now found a valid signature on two different messages. This leads to a trivial break of  At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and
At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and 
{kind=link}