Yesterday, David Benjamin posted a pretty esoteric note on the IETF’s TLS mailing list. At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and some of my colleagues, however, it was like that scene in X-Files where Mulder and Scully finally learn that aliens are real.
Those fossilized printers confirmed a theory we’d developed in 2014, but had been unable to prove: namely, the existence of a specific feature in RSA’s BSAFE TLS library called “Extended Random” — one that we believe to be evidence of a concerted effort by the NSA to backdoor U.S. cryptographic technology.
Before I get to the details, I want to caveat this post in two different ways. First, I’ve written about the topic of cryptographic backdoors way too much. In 2013, the Snowden revelations revealed the existence of a campaign to sabotage U.S. encryption systems. Since that time, cryptographers have spent thousands of hours identifying, documenting, and trying to convince people to care about these backdoors. We’re tired and we want to do more useful things.
The second caveat covers a problem with any discussion of cryptographic backdoors. Specifically, you never really get absolute proof. There’s always some innocent or coincidental explanation that could sort of fit the evidence — maybe it was all a stupid mistake. So you look for patterns of unlikely coincidences, and use Occam’s razor a lot. You don’t get a Snowden every day.
With all that said, let’s talk about Extended Random, and what this tells us about the NSA. First some background.
Dual_EC_DRBG and RSA BSAFE
To understand the context of this discovery, you need to know about a standard called Dual EC DRBG. This was a proposed random number generator that the NSA developed in the early 2000s. It was standardized by NIST in 2007, and later deployed in some important cryptographic products — though we didn’t know it at the time.
Dual EC has a major problem, which is that it likely contains a backdoor. This was pointed out in 2007 by Shumow and Ferguson, and effectively confirmed by the Snowden leaks in 2013. Drama ensued. NIST responded by pulling the standard. (For an explainer on the Dual EC backdoor, see here.)
Somewhere around this time the world learned that RSA Security had made Dual EC the default random number generator in their popular cryptographic library, which was called BSAFE. RSA hadn’t exactly kept this a secret, but it was such a bonkers thing to do that nobody (in the cryptographic community) had known. So for years RSA shipped their library with this crazy algorithm, which made its way into all sorts of commercial devices.
The RSA drama didn’t quite end there, however. In late 2013, Reuters reported that RSA had taken $10 million to backdoor their software. RSA sort of denies this. Or something. It’s not really clear.
Regardless of the intention, it’s known that RSA BSAFE did incorporate Dual EC. This could have been an innocent decision, of course, since Dual EC was a NIST standard. To shed some light on that question, in 2014 my colleagues and I decided to reverse-engineer the BSAFE library to see if it the alleged backdoor in Dual EC was actually exploitable by an attacker like the NSA. We figured that specific engineering decisions made by the library designers could be informative in tipping the scales one way or the other.
It turns out they were.
Extended Random
In the course of reverse engineering the Java version of BSAFE, we discovered a funny inclusion. Specifically, we found that BSAFE supports a non-standard extension to the TLS protocol called “Extended Random”.
The Extended Random extension is an IETF Draft proposed by an NSA employee named Margaret Salter (at some point the head of NSA’s Information Assurance Directorate, which worked on “defensive” crypto for DoD) along with Eric Rescorla as a contractor. (Eric was very clearly hired to develop a decent proposal that wouldn’t hurt TLS, and would primarily be used on government machines. The NSA did not share their motivations with him.)
It’s important to note that Extended Random by itself does not introduce any cryptographic vulnerabilities. All it does is increase the amount of random data (“nonces”) used in a TLS protocol connection. This shouldn’t hurt TLS at all, and besides it was largely intended for U.S. government machines.
The only thing that’s interesting about Extended Random is what happens when that random data is generated using the Dual EC algorithm. Specifically, this extra data acts as “rocket fuel”, significantly increasing the efficiency of exploiting the Dual EC backdoor to decrypt TLS connections.
In short, if you’re an agency like the NSA that’s trying to use Dual EC as a backdoor to intercept communications, you’re muchbetter off with a system that uses both Dual EC DRBG and Extended Random. Since Extended Random was never standardized by the IETF, it shouldn’t be in any systems. In fact, to the best of our knowledge, BSAFE is the only system in the world that implements it.
In addition to Extended Random, we discovered a variety of features that, combined with the Dual EC backdoor, could make RSA BSAFE fairly easy to exploit. But Extended Random is by far the strangest and hardest to justify.
So where did this standard come from? For those who like technical mysteries, it turns out that Extended Random isn’t the only funny-smelling proposal the NSA made. It’s actually one of four failed IETF proposals made by NSA employees, or contractors who work closely with the NSA, all of which try to boost the amount of randomness in TLS. Thomas Ptacek has a mind-numbingly detailed discussion of these proposals and his view of their motivation in this post.
Oh my god I never thought spies could be so boring. What’s the new development?
Despite the fact that we found Extended Random in RSA BSAFE (a free version we downloaded from the Internet), a fly in the ointment was that it didn’t actually seem to be enabled. That is: the code was there but the switches to enable it were hard-coded to “off”.
This kind of put a wrench in our theory that RSA might have included Extended Random to make BSAFE connections more exploitable by the NSA. There might be some commercial version of BSAFE out there with this code active, but we were never able to find it or prove it existed. And even worse, it might appear only in some special “U.S. government only” version of BSAFE, which would tend to undermine the theory that there was something intentional about including this code — after all, why would the government spy on itself?
Which finally brings us to the news that appeared on the TLS mailing list the other day. It turns out that certain Canon printers are failing to respond properly to connections made using the new version of TLS (which is called 1.3), because they seem to have implemented an unauthorized TLS extension using the same number as an extension that TLS 1.3 needs in order to operate correctly. Here’s the relevant section of David’s post:
The web interface on some Canon printers breaks with 1.3-capable ClientHello messages. We have purchased one and confirmed this with a PIXMA MX492. User reports suggest that it also affects PIXMA MG3650 and MX495 models. It potentially affects a wide range of Canon printers.
These printers use the RSA BSAFE library to implement TLS and this library implements the extended_random extension and assigns it number 40. This collides with the key_share extension and causes 1.3-capable handshakes to fail.
So in short, this news appears to demonstrate that commercial (non-free) versions of RSA BSAFE did deploy the Extended Random extension, and made it active within third-party commercial products. Moreover, they deployed it specifically to machines — specifically off-the-shelf commercial printers — that don’t seem to be reserved for any kind of special government use.
(If these turn out to be special Department of Defense printers, I will eat my words.)
Ironically, the printers are now the only thing that still exhibits the features of this (now deprecated) version of BSAFE. This is not because the NSA was targeting printers. Whatever devices they were targeting are probably gone by now. It’s because printer firmware tends to be obsolete and yet highly persistent. It’s like a remote pool buried beneath the arctic circle that preserves software species that would otherwise vanish from the Internet.
Which brings us to the moral of the story: not only are cryptographic backdoors a terrible idea, but they totally screw up the assigned numbering system for future versions of your protocol.
Actually no, that’s a pretty useless moral. Instead, let’s just say that you can deploy a cryptographic backdoor, but it’s awfully hard to control where it will end up.
A few months ago it was starting to seem like you couldn’t go a week without a new attack on TLS. In that context, this summer has been a blessed relief. Sadly, it looks like our vacation is over, and it’s time to go back to school.
Today brings the news that Karthikeyan Bhargavan and Gaëtan Leurent out of INRIA have a new paper that demonstrates a practical attack on legacy ciphersuites in TLS (it’s called “Sweet32”, website here). What they show is that ciphersuites that use 64-bit blocklength ciphers — notably 3DES — are vulnerable to plaintext recovery attacks that work even if the attacker cannot recover the encryption key.
While the principles behind this attack are well known, there’s always a difference between attacks in principle and attacks in practice. What this paper shows is that we really need to start paying attention to the practice.
So what’s the matter with 64-bit block ciphers?
Block ciphers are one of the most widely-used cryptographic primitives. As the nameimplies, these are schemes designed to encipher data in blocks, rather than a single bit at a time.
The two main parameters that define a block cipher are its block size (the number of bits it processes in one go), and its key size. The two parameters need not be related. So for example, DES has a 56-bit key and a 64-bit block. Whereas 3DES (which is built from DES) can use up to a 168-bit key and yet still has the same 64-bit block. More recent ciphers have opted for both larger blocks and larger keys.
When it comes to the security provided by a block cipher, the most important parameter is generally the key size. A cipher like DES, with its tiny 56-bit key, is trivially vulnerable to brute force attacks that attempt decryption with every possible key (often using specialized hardware). A cipher like AES or 3DES is generally not vulnerable to this sort of attack, since the keys are much longer.
However, as they say: key size is not everything. Sometimes the block size matters too.
You see, in practice, we often need to encrypt messages that are longer than a single block. We also tend to want our encryption to be randomized. To accomplish this, most protocols use a block cipher in a scheme called a mode of operation. The most popular mode used in TLS is CBC mode. Encryption in CBC looks like this:
Source: Wikipedia
The nice thing about CBC is that (leaving aside authentication issues) it can be proven (semantically) secure if we make various assumptions about the security of the underlying block cipher. Yet these security proofs have one important requirement. Namely, the attacker must not receive too much data encrypted with a single key.
The reason for this can be illustrated via the following simple attack.
Imagine that an honest encryptor is encrypting a bunch of messages using CBC mode. Following the diagram above, this involves selecting a random Initialization Vector () of size equal to the block size of the cipher, then XORing with the first plaintext block (), and enciphering the result (). The is sent (in the clear) along with the ciphertext.
Most of the time, the resulting ciphertext block will be unique — that is, it won’t match any previous ciphertext block that an attacker may have seen. However, if the encryptor processes enough messages, sooner or later the attacker will see a collision. That is, it will see a ciphertext block that is the same as some previous ciphertext block. Since the cipher is deterministic, this means the cipher’s input () must be identical to the cipher’s previous input that created the previous block.
In other words, we have , which can be rearranged as . Since the IVs are random and known to the attacker, the attacker has (with high probability) learned the XOR of two (unknown) plaintexts!
What can you do with the XOR of two unknown plaintexts? Well, if you happen to know one of those two plaintext blocks — as you might if you were able to choose some of the plaintexts the encryptor was processing — then you can easily recover the other plaintext. Alternatively, there are known techniques that can sometimes recover useful data even when you don’t know both blocks.
The main lesson here is that this entire mess only occurs if the attacker sees a collision. And the probabilityof such a collision is entirely dependent on the size of the cipher block. Worse, thanks to the (non-intuitive) nature of the birthday bound, this happens much more quickly than you might think it would. Roughly speaking, if the cipher block is b bits long, then we should expect a collision after roughly encrypted blocks.
In the case of a 64-bit blocksize cipher like 3DES, this is somewhere in the vicinity of , or around 4 billion enciphered blocks.
(As a note, the collision does not really need to occur in the first block. Since all blocks in CBC are calculated in the same way, it could be a collision anywhere within the messages.)
Whew. I thought this was a practical attack. 4 billion is a big number!
It’s true that 4 billion blocks seems like an awfully large number. In a practical attack, the requirements would be even larger — since the most efficient attack is for the attacker to know a lot of the plaintexts, in the hope that she will be able to recover one unknown plaintext when she learns the value (P ⊕ P’).
However, it’s worth keeping in mind that these traffic numbers aren’t absurd for TLS. In practice, 4 billion 3DES blocks works out to 32GB of raw ciphertext. A lot to be sure, but not impossible. If, as the Sweet32 authors do, we assume that half of the plaintext blocks are known to the attacker, we’d need to increase the amount of ciphertext to about 64GB. This is a lot, but not impossible.
The Sweet32 authors take this one step further. They imagine that the ciphertext consists of many HTTPS connections, consisting of 512 bytes of plaintext, in each of which is embedded the same secret 8-byte cookie — and the rest of the session plaintext is known. Calculating from these values, they obtain a requirement of approximately 256GB of ciphertext needed to recover the cookie with high probability.
That is really a lot.
But keep in mind that TLS connections are being used to encipher increasingly more data. Moreover, a single open browser frame running attacker-controlled Javascript can produce many gigabytes of ciphertext in a single hour. So these attacks are not outside of the realm of what we can run today, and presumably will be very feasible in the future.
How does the TLS attack work?
While the cryptographic community has been largely pushing TLS away from ciphersuites like CBC, in favor of modern authenticated modes of operation, these modes still exist in TLS. And they exist not only for use not only with modern ciphers like AES, but they are often available for older ciphersuites like 3DES. For example, here’s a connection I just made to Google:
Of course, just because a server supports 3DES does not mean that it’s vulnerable to this attack. In order for a particular connection to be vulnerable, both the client and server must satisfy three main requirements:
The client and server must negotiate a 64-bit cipher. This is a relatively rare occurrence, but can happen in cases where one of the two sides is using an out-of-date client. For example, stock Windows XP does not support any of the AES-based ciphersuites. Similarly, SSL3 connections may negotiate 3DES ciphersuites.
The server and client must support long-lived TLS sessions, i.e., encrypting a great deal of data with the same key. Unfortunately, most web browsers place no limit on the length of an HTTPS session if Keep-Alive is used, provided that the server allows the session. The Sweet32 authors scanned and discovered that many servers (including IIS) will allow sessions long enough to run their attack.Across the Internet, the percentage of vulnerable servers is small (less than 1%), but includes some important sites.
The client must encipher a great deal of known data, including a secret session cookie. This is generally achieved by running adversarial Javascript code in the browser, although it could be done using standard HTML as well.
These caveats aside, the authors were able to run their attack using Firefox, sending at a rate of about 1500 connections per second. With a few optimizations, they were able to recover a 16-byte secret cookie in about 30 hours (a lucky result, given an expected 38 hour run time).The client must encipher a great deal of known data, including a secret session cookie. This is generally achieved by running adversarial Javascript code in the browser, although it could be done using standard HTML as well.
So what do we do now?
While this is not an earthshaking result, it’s roughly comparable to previous results we’ve seen with legacy ciphers like RC4.
In short, while these are not the easiest attacks to run, it’s a big problem that there even exist semi-practical attacks that undo the encryption used in standard encryption protocols. This is a problem that we should address, and these attack papers help to make those problems more clear.
To every thing there is a season. And in the world of cryptography, today we have the first signs of the season of TLS vulnerabilities.
This year’s season is off to a roaring start with not one, but two serious bugs announcements by the OpenSSL project, each of which guarantees that your TLS connections are much less than private than you’d like them to be. I can’t talk about both vulnerabilities and keep my sanity, so today I’m going to confine myself to the more dramatic of the two vulnerabilities: a new cross-protocol attack on TLS named “DROWN”.
Technically DROWN stands for “Decrypting RSA using Obsolete and Weakened eNcryption”, but honestly feel free to forget that because the name itself is plenty descriptive. In short, due to a series of dumb mistakes on the part of a vast number of people, DROWN means that TLS connections to a depressingly huge slice of the web (and mail servers, VPNs etc.) are essentially open to attack by fairly modest adversaries.
So that’s bad news. The worse news — as I’ll explain below — is that this whole mess was mostly avoidable.
For a detailed technical explanation of DROWN, you should go read the complete technical paper by Aviram et al. Or visit the DROWN team’s excellent website. If that doesn’t appeal to you, read on for a high level explanation of what DROWN is all about, and what it means for the security of the web. Here’s the TL;DR:
If you’re running a web server configured to use SSLv2, and particularly one that’s running OpenSSL (even with all SSLv2 ciphers disabled!), you may be vulnerable to a fast attack that decrypts many recorded TLS connections made to that box. Most worryingly, the attack does not require the client to ever make an SSLv2 connection itself, and it isn’t a downgrade attack. Instead, it relies on the fact that SSLv2 — and particularly the legacy “export” ciphersuites it incorporates — are pure poison, and simply having these active on a server is enough to invalidate the security of all connections made to that device.
For the rest of this post I’ll use the “fun” question and answer format I save for this kind of attack. First, some background.
What are TLS and SSLv2, and why should I care?
Transport Layer Security (TLS) is the most important security protocol on the Internet. You should care about it because nearly every transaction you conduct on the Internet relies on TLS (v1.0, 1.1 or 1.2) to some degree, and failures in TLS can flat out ruin your day.
But TLS wasn’t always TLS. The protocol began its life at Netscape Communications under the name “Secure Sockets Layer”, or SSL. Rumor has it that the first version of SSL was so awful that the protocol designers collected every printed copy and buried them in a secret New Mexico landfill site. As a consequence, the first public version of SSL is actually SSL version 2. It’s pretty terrible as well — but not (entirely) for the reasons you might think.
Let me explain.
The reason you might think SSLv2 is terrible is because it was a product of the mid-1990s, which modern cryptographers view as the “dark ages of cryptography”. Many of the nastier cryptographic attacks we know about today had not yet been discovered. As a result, the SSLv2 protocol designers were forced to essentially grope their way in the dark, and so were frequently devoured by grues — to their chagrin and our benefit, since the attacks on SSLv2 offered priceless lessons for the next generation of protocols.
And yet, these honest mistakes are not worst thing about SSLv2. The most truly awful bits stem from the fact that the SSLv2 designers were forced to ruin their own protocol. This was the result of needing to satisfy the U.S. government’s misguided attempt to control the export of cryptography. Rather than using only secure encryption, the designers were forced to build in a series of “export-grade ciphersuites” that offered abysmal 40-bit session keys and other nonsense. I’ve previously written about the effect of export crypto on today’s security. Today we’ll have another lesson.
Wait, isn’t SSLv2 ancient history?
For some time in the early 2000s, SSLv2 was still supported by browsers as a fallback protocol, which meant that active attackers could downgrade an SSLv3 or TLS connection by tricking a browser into using the older protocol. Fortunately those attacks are long gone now: modern web browsers have banished SSLv2 entirely — along with export cryptography in general. If you’re using a recent version of Chrome, IE or Safari, you should never have to worry about accidentally making an SSLv2 connection.
The problem is that while clients (such as browsers) have done away with SSLv2, many servers still support the protocol. In most cases this is the result of careless server configuration. In others, the blame lies with crummy and obsolete embedded devices that haven’t seen a software update in years — and probably never will. (You can see if your server is vulnerable here.)
And then there’s the special case of OpenSSL, which helpfully provides a configuration option that’s intended to disable SSLv2 ciphersuites — but which, unfortunately, does no such thing. In the course of their work, the DROWN researchers discovered that even when this option is set, clients may still request arbitrary SSLv2 ciphersuites. (This issue was quietly patched in January. Upgrade.)
The reason this matters is that SSL/TLS servers do a very silly thing. You see, since people don’t like to buy multiple certificates, a server that’s configured to use both TLS and SSLv2 will generally use the same RSA private keyto support both protocols. This means any bugs in the way SSLv2 handles that private key could very well affect the security of TLS.
And this is where DROWN comes in.
So what is DROWN?
DROWN is a classic example of a “cross protocol attack”. This type of attack makes use of bugs in one protocol implementation (SSLv2) to attack the security of connections made under a different protocol entirely — in this case, TLS. More concretely, DROWN is based on the critical observation that while SSLv2 and TLS both support RSA encryption, TLS properly defends against certain well-known attacks on this encryption — while SSLv2’s export suites emphatically do not.
I will try to make this as painless as possible, but here we need to dive briefly into the weeds.
You see, both SSLv2 and TLS use a form of RSA encryption padding known as RSA-PKCS#1v1.5. In the late 1990s, a man named Daniel Bleichenbacher proposed an amazing attack on this encryption scheme that allows an attacker to decrypt an RSA ciphertext efficiently — under the sole condition that they can ask an online server to decrypt many related ciphertexts, and give back only one bit of information for each one — namely, the bit representing whether decryption was successful or not.
Bleichenbacher’s attack proved particularly devastating for SSL servers, since the standard SSL RSA-based handshake involves the client encrypting a secret (called the Pre-Master Secret, or PMS) under the server’s RSA public key, and then sending this value over the wire. An attacker who eavesdrops the encrypted PMS can run the Bleichenbacher attack against the server, sending it thousands of related values (in the guise of new SSL connections), and using the server’s error responses to gradually decrypt the PMS itself. With this value in hand, the attacker can compute SSL session keys and decrypt the recorded SSL session.
A nice diagram of the SSL handshake, courtesy of Cloudflare (who don’t know I’m using it. Thanks guys!)
The main SSL/TLS countermeasure against Bleichenbacher’s attack is basically a hack. When the server detects that an RSA ciphertext has decrypted improperly, it lies. Instead of returning an error, which the attacker could use to implement the attack, it generates a random pre-master secret and continues with the rest of the protocol as though this bogus value was what it actually decrypted. This causes the protocol to break down later on down the line, since the server will compute essentially a random session key. But it’s sufficient to prevent the attacker from learning whether the RSA decryption succeeded or not, and that kills the attack dead.
Anti-Bleichenbacher countermeasure from the TLS 1.2 spec.
Now let’s take a moment to reflect and make an observation.
If the attacker sends a valid RSA ciphertext to be decrypted, the server will decrypt it and obtain some PMS value. If the attacker sends the same valid ciphertext a second time, the server will decrypt and obtain the same PMS value again. Indeed, the server will always get the same PMS even if the attacker sends the same valid ciphertext a hundred times in a row.
On the other hand, if the attacker repeatedly sends the same invalid ciphertext, the server will choose a different PMS every time. This observation is crucial.
In theory, if the attacker holds a ciphertext that might be valid or invalid — and the attacker would like to know which is true — they can send the same ciphertext to be decrypted repeatedly. This will lead to two possible conditions. In condition (1) where the ciphertext is valid, decryption will produce the “same PMS every time”. Condition (2) for an invalid ciphertext will produce a “different PMS each time”. If the attacker could somehow tell the difference between condition (1) and condition (2), they could determine whether the ciphertext was valid. That determination alone would be enough to resurrect the Bleichenbacher attack. Fortunately in TLS, the PMS is never used directly; it’s first passed through a strong hash function and combined with a bunch of random nonces to obtain a Master Secret. This result then used in further strong ciphers and hash functions. Thanks to the strength of the hash function and ciphers, the resulting keys are so garbled that the attacker literally cannot tell whether she’s observing condition (1) or (2).
And here we finally we run into the problem of SSLv2.
You see, SSLv2 implementations include a similar anti-Bleichenbacher countermeasure. Only here there are some key differences. In SSLv2 there is no PMS — the encrypted value is used as the Master Secret and employed directly to derive the encryption session key. Moreover, in export modes, the Master Secret may be as short as 40 bits, and used with correspondingly weak export ciphers. This means an attacker can send multiple ciphertexts, then brute-force the resulting short keys. After recovering these keys for a tiny number of sessions, they will be able to determine whether they’re in condition (1) or (2). This would effectively resurrect the Bleichenbacher attack.
This still sounds like an attack on SSLv2, not on TLS. What am I missing?
And now we come to the full horror of SSLv2.
Since most servers configured with both SSLv2 and TLS support will use the same RSA private key for decrypting sessions from either protocol, a Bleichenbacher attack on the SSLv2 implementation — with its vulnerable crappy export ciphersuites — can be used to decrypt the contents of a normal TLS-based RSA ciphertext. After all, both protocols are using the same darned secret key. Due to formatting differences in the RSA ciphertext between the two protocols, this attack doesn’t work all the time — but it does work for approximately one out of a thousand TLS handshakes.
To put things succinctly: with access to a whole hell of a lot of computation, an attacker can intercept a TLS connection, then at their leisure make many thousands of queries to the SSLv2-enabled server, and decrypt that connection. The “general DROWN” attack actually requires watching about 1,000 TLS handshakes to find a vulnerable RSA ciphertext, about 40,000 queries to the server, and about 2^50 offline operations.
LOL. That doesn’t sound practical at all. You cryptographers suck.
First off, that isn’t really a question, it’s more a rude statement. But since this is exactly the sort of reaction cryptographers often get when they point out perfectly practical theoretical attacks on real protocols, I’d like to take a moment to push back.
While the attack described above seems costly, it can be conducted in several hours and $440 on Amazon EC2. Are your banking credentials worth $440? Probably not. But someone else’s probably are. Given all the things we have riding on TLS, it’s better for it not to be broken at all.
More urgently, the reason cryptographers spend time on “impractical attacks” is that attacks always get better. And sometimes they get better fast.
The attack described above is called “General DROWN” and yes, it’s a bit impractical. But in the course of writing just this single paper, the DROWN researchers discovered a second variant of their attack that’s many orders of magnitude faster than the general one described above. This attack, which they call “Special DROWN” can decrypt a TLS RSA ciphertext in about one minute on a single CPU core.
This attack relies on a bug in the way OpenSSL handles SSLv2 key processing, a bug that was (inadvertently) fixed in March 2015, but remains open across the Internet. The Special DROWN bug puts DROWN squarely in the domain of script kiddies, for thousands of websites across the Internet.
So how many sites are vulnerable?
This is probably the most depressing part of the entire research project. According to wide-scale Internet scans run by the DROWN researchers, more than 2.3 million HTTPS servers with browser-trusted certificates are vulnerable to special DROWN, and 3.5 million HTTPS servers are vulnerable to General DROWN. That’s a sizeable chunk of the encrypted web, including a surprising chunk of the Chinese and Colombian Internet.
And while I’ve focused on the main attacks in this post, it’s worth pointing out that DROWN also affects other protocol suites, like TLS with ephemeral Diffie-Hellman and even Google’s QUIC. So these vulnerabilities should not be taken lightly.
In January, OpenSSL patched the bug that allows the SSLv2 ciphersuites to remain alive. Last March, the project inadvertently fixed the bug that makes Special DROWN possible. But that’s hardly the end. The patch they’re announcing today is much more direct: hopefully it will make it impossible to turn on SSLv2 altogether. This will solve the problem for everyone… at least for everyone willing to patch. Which, sadly, is unlikely to be anywhere near enough.
More broadly, attacks like DROWN illustrate the cost of having old, vulnerable protocols on the Internet. And they show the terrible cost that we’re still paying for export cryptography systems that introduced deliberate vulnerabilities in encryption so that intelligence agencies could pursue a small short-term advantage — at the cost of long-term security.
In case you haven’t heard, there’s a new SSL/TLS vulnerability making the rounds. Nicknamed Logjam, the new attack is ‘special’ in that it may admit complete decryption or hijacking of any TLS connection you make to an improperly configured web or mail server. Worse, there’s at least circumstantial evidence that similar (and more powerful) attacks might already be in the toolkit of some state-level attackers such as the NSA.
This work is the result of an unusual collaboration between a fantastic group of co-authors spread all around the world, including institutions such as the University of Michigan, INRIA Paris-Rocquencourt, INRIA Paris-Nancy, Microsoft Research, Johns Hopkins and the University Of Pennsylvania. It’s rare to see this level of collaboration between groups with so many different areas of expertise, and I hope to see a lot more like it. (Disclosure: I am one of the authors.)
The absolute best way to understand the Logjam result is to read the technical research paper. This post is mainly aimed at people who want a slightly less technical form. For those with even shorter attention spans, here’s the TL;DR:
It appears that the the Diffie-Hellman protocol, as currently deployed in SSL/TLS, may be vulnerable to a serious downgrade attack that restores it to 1990s “export” levels of security, and offers a practical “break” of the TLS protocol against poorly configured servers. Even worse, extrapolation of the attack requirements — combined with evidence from the Snowden documents — provides some reason to speculate that a similar attack could be leveraged against protocols (including TLS, IPSec/IKE and SSH) using 768- and 1024-bit Diffie-Hellman.
I’m going to tackle this post in the usual ‘fun’ question-and-answer format I save for this sort of thing.
What is Diffie-Hellman and why should I care about TLS “export” ciphersuites?
Diffie-Hellman is probably the most famous public key cryptosystem ever invented. Publicly discovered by Whit Diffie and Martin Hellman in the late 1970s (and a few years earlier, in secret, by UK GCHQ), it allows two parties to negotiate a shared encryption key over a public connection.
Diffie-Hellman is used extensively in protocols such as SSL/TLS and IPSec, which rely on it to establish the symmetric keys that are used to transport data. To do this, both parties must agree on a set of parameters to use for the key exchange. In traditional (‘mod p‘) Diffie-Hellman, these parameters consist of a large prime number p, as well as a ‘generator’ g. The two parties now exchange keys as shown below:
TLS supports several variants of Diffie-Hellman. The one we’re interested in for this work is the ‘ephemeral’ non-elliptic (“DHE”) protocol variant, which works in a manner that’s nearly identical to the diagram above. The server takes the role of Alice, selecting (p, g, ga mod p) and signing this tuple (and some nonces) using its long-term signing key. The client responds gb mod p and the two sides then calculate a shared secret.
Just for fun, TLS also supports an obsolete ‘export’ variant of Diffie-Hellman. These export ciphersuites are a relic from the 1990s when it was illegal to ship strong encryption out of the country. What you need to know about “export DHE” is simple: it works identically to standard DHE, but limits the size of p to 512 bits. Oh yes, and it’s still out there today. Because the Internet.
How do you attack Diffie-Hellman?
The best known attack against a correct Diffie-Hellman implementation involves capturing the value ga and solving to find the secret key a. The problem of finding this value is known as the discrete logarithm problem, and it’s thought to be a mathematically intractable, at least when Diffie-Hellman is implemented in cryptographically strong groups (e.g., when p is of size 2048 bits or more).
Unfortunately, the story changes dramatically when p is relatively small — for example, 512 bits in length. Given a value ga mod p for a 512-bit p, itshould at least be possible to efficiently recover the secret a and read traffic on the connection.
Most TLS servers don’t use 512-bit primes, so who cares?
The good news here is that weak Diffie-Hellman parameters are almost never used purposely on the Internet. Only a trivial fraction of the SSL/TLS servers out there today will organically negotiate 512-bit Diffie-Hellman. For the most part these are crappy embedded devices such as routers and video-conferencing gateways.
However, there is a second class of servers that are capable of supporting 512-bit Diffie-Hellman when clients request it, using a special mode called the ‘export DHE’ ciphersuite. Disgustingly, these servers amount to about 8% of the Alexa top million sites (and a whopping 29% of SMTP/STARTLS mail servers). Thankfully, most decent clients (AKA popular browsers) won’t willingly negotiate ‘export-DHE’, so this would also seem to be a dead end.
It isn’t.
ServerKeyExchange message (RFC 5246)
You see, before SSL/TLS peers can start engaging in all this fancy cryptography, they first need to decide which ciphers they’re going to use. This is done through a negotiation process in which the client proposes some options (e.g., RSA, DHE, DHE-EXPORT), and the server picks one.
This all sound simple enough. However, one of the early, well known flaws in SSL/TLS is the protocol’s failure to properly authenticate these ‘negotiation’ messages. In very early versions of SSL they were not authenticated at all. SSLv3 and TLS tacked on an authentication process — but one that takes place only at the end of the handshake.*
This is particularly unfortunate given that TLS servers often have the ability to authenticate their messages using digital signatures, but don’t really take advantage of this. For example, when two parties negotiate Diffie-Hellman, the parameters sent by the server are transmitted within a signed message called the ServerKeyExchange (shown at right). The signed portion of this message covers the parameters, but neglects to include any information about which ciphersuite the server thinks it’s negotiating. If you remember that the only difference between DHE and DHE-EXPORT is the size of the parameters the server sends down, you might start to see the problem.
Here it is in a nutshell: if the server supports DHE-EXPORT, the attacker can ‘edit’ the negotiation messages sent from the a client — even if the client doesn’t support export DHE — replacing the client’s list of supported ciphers with only export DHE. The server will in turn send back a signed 512-bit export-grade Diffie-Hellman tuple, which the client will blindly accept — because it doesn’t realize that the server is negotiating the export version of the ciphersuite. From its perspective this message looks just like ‘standard’ Diffie-Hellman with really crappy parameters.
Overview of the Logjam active attack (source: paper).
All this tampering should run into a huge snag at the end of the handshake, when he client and server exchange Finished messages embedding include a MAC of the transcript. At this point the client should learn that something funny is going on, i.e., that what it sent no longer matches what the server is seeing. However, the loophole is this: if the attacker can recover the Diffie-Hellman secret quickly — before the handshake ends — she can forge her own Finished messages. In that case the client and server will be none the wiser.
The upshot is that executing this attack requires the ability to solve a 512-bit discrete logarithm before the client and server exchange Finished messages. That seems like a tall order.
Can you really solve a discrete logarithm before a TLS handshake times out?
In practice, the fastest route to solving the discrete logarithm in finite fields is via an algorithm called the Number Field Sieve (NFS). Using NFS to solve a single 512-bit discrete logarithm instance requires several core-years — or about week of wall-clock time given a few thousand cores — which would seem to rule out solving discrete logs in real time.
However, there is a complication. In practice, NFS can actually be broken up into two different steps:
Pre-computation (for a given prime p). This includes the process of polynomial selection, sieving, and linear algebra, all of which depend only on p. The output of this stage is a table for use in the second stage.
Solving to find a (for a given ga mod p). The final stage, called the descent, uses the table from the precomputation. This is the only part of the algorithm that actually involves a specific g andga.
The important thing to know is that the first stage of the attack consumes the vast majority of the time, up to a full week on a large-scale compute cluster. The descent stage, on the other hand, requires only a few core-minutes. Thus the attack cost depends primarily on where the server gets its Diffie-Hellman parameters from. The best case for an attacker is when p is hard-coded into the server software and used across millions of machines. The worst case is when p is re-generated routinely by the server.
I’ll let you guess what real TLS servers actually do.
In fact, large-scale Internet scans by the team at University of Michigan show that most popular web servers software tends to re-use a small number of primes across thousands of server instances. This is done because generating prime numbers is scary, so implementers default to using a hard-coded value or a config file supplied by your Linux distribution. The situation for export Diffie-Hellman is particularly awful, with only two (!) primes used across up 92% of enabled Apache/mod_ssl sites.
Number of seconds to solve a 512-bit discrete log (source: paper).
The upshot of all of this is that about two weeks of pre-computation is sufficient to build a table that allows you to perform the downgrade against most export-enabled servers in just a few minutes (see the chart at right). This is fast enough that it can be done before the TLS connection timeout. Moreover, even if this is not fast enough, the connection can often be held open longer by using clever protocol tricks, such as sending TLS warning messages to reset the timeout clock.
Keep in mind that none of this shared prime craziness matters when you’re using sufficiently large prime numbers (on the order of 2048 bits or more). It’s only a practical issue you’re using small primes, like 512-bit, 768-bit or — and here’s a sticky one I’ll come back to in a minute — 1024 bit.
How do you fix the downgrade to export DHE?
The best and most obvious fix for this problem is to exterminate export ciphersuites from the Internet. Unfortunately, these awful configurations are the default in a number of server software packages (looking at you Postfix), and getting people to update their configurations is surprisingly difficult (see e.g., FREAK).
A simpler fix is to upgrade the major web browsers to resist the attack. The easy way to do this is to enforce a larger minimum size for received DHE keys. The problem here is that the fix itself causes some collateral damage — it will break a small but significant fraction of lousy servers that organically negotiate (non-export) DHE with 512 bit keys.
The good news here is that the major browsers have decided to break the Internet (a little) rather than allow it to break them. Each has agreed to raise the minimum size limit to at least 768 bits, and some to a minimum of 1024 bits. It’s still not perfect, since 1024-bit DHE may not be cryptographically sound against powerful attackers, but it does address the immediate export attack. In the longer term the question is whether to use larger negotiated DHE groups, or abandon DHE altogether and move to elliptic curves.
What does this mean for larger parameter sizes?
The good news so far is that 512-bit Diffie-Hellman is only used by a fraction of the Internet, even when you account for active downgrade attacks. The vast majority of servers use Diffie-Hellman moduli of length at least 1024 bits. (The widespread use of 1024 is largely due to a hard-cap in older Java clients. Go away Java.)
While 2048-bit moduli are generally believed to be outside of anyone’s reach, 1024-bit DHE has long been considered to be at least within groping range of nation-state attackers. We’ve known this for years, of course, but the practical implications haven’t been quite clear. This paper tries to shine some light on that, using Internet-wide measurements and software/hardware estimates.
If you recall from above, the most critical aspect of the NFS attack is the need to perform large amounts of pre-computation on a given Diffie-Hellman prime p, followed by a relatively short calculation to break any given connection that uses p. At the 512-bit size the pre-computation only requires about a week. The question then is, how much does it cost for a 1024-bit prime, and how common are shared primes?
While there’s no exact way to know how much the 1024-bit attack would cost, the paper attempts to provide some extrapolations based on current knowledge. With software, the cost of the pre-computation seems quite high — on the order of 35 million core-years. Making this happen for a given prime within a reasonable amount of time (say, one year) would appear to require billions of dollars of computing equipment if we assume no algorithmic improvements. Even if we rule out such improvements, it’s conceivable that this cost might be brought down to a few hundred million dollars using hardware. This doesn’t seem out of bounds when you consider leaked NSA cryptanalysis budgets.
What’s interesting is that the descent stage, required to break a given Diffie-Hellman connection, is much faster. Based on some implementation experiments by the CADO-NFS team, it may be possible to break a Diffie-Hellman connection in as little as 30 core-days, with parallelization hugely reducing the wall-clock time. This might even make near-real-time decryption of Diffie-Hellman connections practical.
Is the NSA actually doing this?
So far all we’ve noted is that NFS pre-computation is at least potentially feasible when 1024-bit primes are re-used. That doesn’t mean the NSA is actually doing any of it.
There is some evidence, however, that suggests the NSA has decryption capability that’s at least consistent with such a break. This evidence comes from a series of Snowden documents published last winter in Der Spiegel. Together they describe a large-scale effort at NSA and GCHQ, capable of decrypting ‘vast’ amounts of Internet traffic, including IPSec, SSH and HTTPS connections.
NSA slide illustrating exploitation of IPSec encrypted traffic (source: Spiegel).
While the architecture described by the documents mentions attacks against many protocols, the bulk of the energy seems to be around the IPSec and IKE protocols, which are used to establish Virtual Private Networks (VPNs) between individuals and corporate networks such as financial institutions.
The nature of the NSA’s exploit is never made clear in the documents, but diagram at right gives a lot of the architectural details. The system involves collecting Internet Key Exchange (IKE) handshakes, transmitting them to the NSA’s Cryptanalysis and Exploitation Services (CES) enclave, and feeding them into a decryption system that controls substantial high performance computing resources to process the intercepted exchanges. This is at least circumstantially consistent with Diffie-Hellman cryptanalysis.
Of course it’s entirely possible that the attack is based on a bad random number generator, weak symmetric encryption, or any number of engineered backdoors. There are a few pieces of evidence that militate towards a Diffie-Hellman break, however:
IPSec (or rather, the IKE key exchange) uses Diffie-Hellman for every single connection, meaning that it can’t be broken without some kind of exploit, although this doesn’t rule out the other explanations.
The IKE exchange is particularly vulnerable to pre-computation, since IKE uses a small number of standardized prime numbers called the Oakley groups, which are going on 17 years old now. Large-scale Internet scanning by the Michigan team shows that a majority of responding IPSec endpoints will gladly negotiate using Oakley Group 1 (768 bit) or Group 2 (1024 bit), even when the initiator offers better options.
The NSA’s exploit appears to require the entireIKE handshake as well as any pre-shared key (PSK). These inputs would be necessary for recovery of IKEv1 session keys, but are not required in a break that involves only symmetric cryptography.
The documents explicitly rule out the use of malware, or rather, they show that such malware (‘TAO implants’) is in use — but that malware allows the NSA to bypass the IKE handshake altogether.
I would stipulate that beyond the Internet measurements and computational analysis, this remains firmly in the category of ‘crazy-eyed informed speculation’. But while we can’t rule out other explanations, this speculation is certainly consistent with a hardware-optimized break of Diffie-Hellman 768 and 1024-bit, along with some collateral damage to SSH and related protocols.
So what next?
The paper gives a detailed set of recommendations on what to do about these downgrade attacks and (relatively) weak DHE groups. The website provides a step-by-step guide for server administrators. In short, probably the best long-term move is to switch to elliptic curves (ECDHE) as soon as possible. Failing this, clients and servers should enforce at least 2048-bit Diffie-Hellman across the Internet. If you can’t do that, stop using common primes.
Making this all happen on anything as complicated as the Internet will probably consume a few dozen person-lifetimes. But it’s something we have to do, and will do, to make the Internet work properly.
Notes: * There are reasons for this. Some SSL/TLS ciphersuites (such as the RSA encryption-based ciphersuites) don’t use signatures within the protocol, so the only way to authenticate the handshake is to negotiate a ciphersuite, run the key exchange protocol, then use the resulting shared secret to authenticate the negotiation messages after the fact. But SSL/TLS DHE involves digital signatures, so it should be possible to achieve a stronger level of security than this. It’s unfortunate that the protocol does not.
This is the story of how a handful of cryptographers ‘hacked’ the NSA. It’s also a story of encryption backdoors, and why they never quite work out the way you want them to.
But I think I’m getting ahead of myself a bit here.
Today’s Washington Post has the story of a nasty bug in some TLS/SSL servers and clients, one that has the potential to downgrade the security of your TLS connections to something that isn’t really secure at all. In this post I’m going to talk about the technical aspects of the attack, why it matters, and how bad it is.
If you don’t want to read a long blog post, let me give you a TL;DR:
A group of cryptographers at INRIA, Microsoft Research and IMDEA have discovered some serious vulnerabilities in OpenSSL (e.g., Android) clients and Apple TLS/SSL clients (e.g., Safari) that allow a ‘man in the middle attacker’ to downgrade connections from ‘strong’ RSA to ‘export-grade’ RSA. These attacks are real and exploitable against a shocking number of websites — including government websites. Patch soon and be careful.
You can find a detailed description of the work by the researchers — Beurdouche, Bhargavan, Delignat-Lavaud, Fournet, Kohlweiss, Pironti, Strub, Zinzindohoue, Zanella-Béguelin — at their site SmackTLS.com. You should go visit that site and read about the exploits directly. The proof of concept implementation also involved contributions from Nadia Heninger at U. Penn.
I’m going to explain the rest of it in the ‘fun’ question and answer format I save for this kind of attack.
What is SSL/TLS and what are ‘EXPORT cipher suites’ anyway?
In case you’re not familiar with SSL and its successor TLS, what you should know is that they’re the most important security protocols on the Internet. In a world full of untrusted networks, SSL and TLS are what makes modern communication possible.
Or rather, that’s the theory. In practice, SSL and TLS have been a more like a work in progress. In part this is because they were developed during an era when modern cryptographic best practices weren’t nailed down yet. But more to the point: it’s because even when the crypto is right, many software implementations still get things wrong.
With all that in mind, there’s a third aspect of SSL/TLS that doesn’t get nearly as much attention. That is: the SSL protocol itself was deliberately designed to be broken.
Let me explain what I mean by that.
Back in the early 1990s when SSL was first invented at Netscape Corporation, the United States maintained a rigorous regime of export controls for encryption systems. In order to distribute crypto outside of the U.S., companies were required to deliberately ‘weaken’ the strength of encryption keys. For RSA encryption, this implied a maximum allowed key length of 512 bits.*
The 512-bit export grade encryption was a compromise between dumb and dumber. In theory it was designed to ensure that the NSA would have the ability to ‘access’ communications, while allegedly providing crypto that was still ‘good enough’ for commercial use. Or if you prefer modern terms, think of it as the original “golden master key“.
The need to support export-grade ciphers led to some technical challenges. Since U.S. servers needed to support both strong and weak crypto, the SSL designers used a ‘cipher suite’ negotiation mechanism to identify the best cipher both parties could support. In theory this would allow ‘strong’ clients to negotiate ‘strong’ ciphersuites with servers that supported them, while still providing compatibility to the broken foreign clients.
This story has a happy ending, after a fashion. The U.S eventually lifted the most onerous of its export policies. Unfortunately, the EXPORT ciphersuites didn’t go away. Today they live on like zombies — just waiting to eat our flesh.
If EXPORT ciphers are known to be broken, what’s the news here?
We don’t usually worry about export-grade cipher suites very much, because supposedly they aren’t very relevant to the modern Internet. There are three general reasons we don’t think they matter anymore:
Most ‘modern’ clients (e.g., web browsers) won’t offer export grade ciphersuites as part of the negotiation process. In theory this means that even if the server supports export-grade crypto, your session will use strong crypto.
Almost no servers, it was believed, even offer export-grade ciphersuites anymore.
Even if you do accidentally negotiate an export-grade RSA ciphersuite, a meaningful attack still requires the attacker to factor a 512-bit RSA key (or break a 40-bit symmetric cipher). This is doable, but it’s generally considered too onerous if you have to do it for every single connection.
This was the theory anyway. It turns out that theory is almost always different than practice. Which brings us to the recent work by Beurdouche et al. from INRIA, Microsoft Research and IMDEA.
What these researchers did was develop a fairly beautiful piece of formal analysis tooling that allows them to ‘fuzz’ the state machines of most modern SSL/TLS implementations. They found a bunch of wonderful things in the course of doing this — some of them quite nasty. I’m not going to cover all of them in this post, but the one we care about here is quite simple.
You see, it turns out that some modern TLS clients — including Apple’s SecureTransport and OpenSSL — have a bug in them. This bug causes them to accept RSA export-grade keys even when the client didn’t ask for export-grade RSA. The impact of this bug can be quite nasty: it admits a ‘man in the middle’ attack whereby an active attacker can force down the quality of a connection, provided that the client is vulnerable and the server supports export RSA.
The MITM attack works as follows:
In the client’s Hello message, it asks for a standard ‘RSA’ ciphersuite.
The MITM attacker changes this message to ask for ‘export RSA’.
The server responds with a 512-bit export RSA key, signed with its long-term key.
The client accepts this weak key due to the OpenSSL/SecureTransport bug.
The attacker factors the RSA modulus to recover the corresponding RSA decryption key.
When the client encrypts the ‘pre-master secret’ to the server, the attacker can now decrypt it to recover the TLS ‘master secret’.
From here on out, the attacker sees plaintext and can inject anything it wants.
So that’s bad news and it definitely breaks our assumption in point (1) above. But at least in theory we should still be safe based on points (2) and (3).
Right?
How common are export-enabled TLS servers?
No matter how bad you think the Internet is, it can always surprise you. The surprise in this case is that export-grade RSA is by no means as extinct as we thought it was.
While the numbers are impressive, the identity of those sites is a bit more worrying. They include U.S. government sites like www.nsa.gov (Oy vey), http://www.whitehouse.gov and http://www.irs.gov. It turns out that the FBI tip reporting site (tips.fbi.gov) was also vulnerable.
(Facebook have updated their configuration as a result of this work.)
Factoring an RSA key seems pretty expensive for breaking one session.
This brings us to the most awful part of this attack. You don’t have to be that fast.
You see, it turns out that generating fresh RSA keys is a bit costly. So modern web servers don’t do it for every single connection. In fact, Apache mod_ssl by default will generate a single export-grade RSA key when the server starts up, and will simply re-use that key for the lifetime of that server.
What this means is that you can obtain that RSA key once, factor it, and break every session you can get your ‘man in the middle’ mitts on until the server goes down. And that’s the ballgame.
PoC or GTFO.
Fortunately, a proof of concept for this attack requires only a few ingredients. First, you need some tooling to actually run the MITM attack. Then you need the ability to (quickly) factor 512-bit RSA keys. From there it’s just a question of finding a vulnerable client and server.
This is what happens to EC2 spot pricing
when Nadia runs 75 ‘large’ instances to factor a 512-bit key.
Just because someone saysan implementation is vulnerable doesn’t mean it actually is. You should ask for proof.
The guts of the PoC were put together by Karthik Bhargavan and Antoine Delignat-Lavaud at INRIA. They assembled an MITM proxy that can intercept connections and re-write them to use export-RSA against a willing website.
To factor the 512-bit export keys, the project enlisted the help of Nadia Heninger at U. Penn, who has been working on “Factoring as a Service” for exactly this purpose. Her platform uses cado-nfs on a cluster of EC2 virtual servers, and (with Nadia doing quite a bit of handholding to deal with crashes) was able to factor a bunch of 512-bit keys — each in about 7.5 hours for $104 in EC2 time.
From there all you need is a vulnerable website.
Since the NSA was the organization that demanded export-grade crypto, it’s only fitting that they should be the first site affected by this vulnerability. There’s great video on the SmackTLS site. After a few hours of factoring, one can take the original site (which looked like this):
And change it into this:
Attack images courtesy Karthik, Antoine INRIA.
Very dramatic.
Some will point out that an MITM attack on the NSA is not really an ‘MITM attack on the NSA’ because NSA outsources its web presence to the Akamai CDN (see obligatory XKCD at right). These people may be right, but they also lack poetry in their souls.
Is it patched?
The most recent of OpenSSL does have a patch. This was announced (though not very loudly) in January of this year.
Apple is working on a patch.
Akamai and other CDNs are also rolling out a patch to solve these problems. Over the next two weeks we will hopefully see export ciphersuites extinguished from the Internet. In the mean time, try to be safe.
What does it all mean?
You might think this is all a bit absurd and doesn’t affect you very much. In a strictly technical sense you’re probably right. The client bugs will soon be patched (update your devices! unless you have Android in which case you’re screwed). With good luck, servers supporting export-grade RSA cipher suites will soon be rare curiosity.
Still, to take this as the main lesson of the work would, I think, be missing the forest for the trees. There’s a much more important moral to this story.
The export-grade RSA ciphers are the remains of a 1980s-vintage effort to weaken cryptography so that intelligence agencies would be able to monitor foreign traffic. This was done badly. So badly, that while the policies were ultimately scrapped, they’re still hurting us today.
This might be an academic point if it was only a history lesson. However, for the past several months, U.S. and European politicians have been publicly mooting the notion of a new set of cryptographicbackdoors in systems we use today. While the proposals aren’t explicit, they would presumably involve deliberately weakening encryption tech so that governments can intercept and read our conversations. While officials carefully avoid the term “back door” — or any suggestion of weakening our encryption systems against real attackers — this is wishful thinking. These systems are already so complex that even normal issues stress them to the breaking point. There’s just no room for new backdoors.
To be blunt about it, the moral is pretty simple:
Encryption backdoors will always turn around and bite you in the ass. They are never worth it.
Acknowledgements
Special thanks to Karthik and Antoine for sharing this with me, Nadia for factoring, Ivan Ristic for interrupting his vacation to get us data, and the CADO-NFS team for the software that made this possible. Notes:
* Export controls might have made some sense in the days when ‘encryption’ meant big clunky pieces of hardware, but it was nonsensical in a world of software. Non-U.S. users could easily skirt the paltry IP-address checks to download strong versions of browsers such as Netscape, and — when that was too much trouble — they could easily re-implement the crypto themselves or use foreign open source libraries. (The requirements became so absurd that mainstream U.S. companies like RSA Security wound up hiring foreign developers to build their encryption libraries, since it was easier to import strong encryption than to export it.)
The information security news today is all about Lenovo’s default installation of a piece of adware called “Superfish” on a number of laptops shipped before February 2015. The Superfish system is essentially a tiny TLS/SSL “man in the middle” proxy that attacks secure connections by making them insecure — so that the proxy can insert ads in order to, oh, I don’t know, let’s just let Lenovo tell it:
“To be clear, Superfish comes with Lenovo consumer products only and is a technology that helps users find and discover products visually,” the representative continued. “The technology instantly analyses images on the web and presents identical and similar product offers that may have lower prices, helping users search for images without knowing exactly what an item is called or how to describe it in a typical text-based search engine.”
Whatever.
The problem here is not just that this is a lousy idea. It’s that Lenovo used the same certificate on every single Laptop it shipped with Superfish. And since the proxy software also requires the corresponding private key to decrypt and modify your web sessions, that private key was also shipped on every laptop. It took all of a day for a numberof researchers to find that key and turn themselves into Lenovo-eating interception proxies. This sucks for Lenovo users.
If you’re a Lenovo owner in the affected time period, go to this site to find out if you’re vulnerable and (hopefully) what to do about it. But this isn’t what I want to talk about in this post.
Instead, what I’d like to discuss is some of the options for large-scale automated fixes to this kind of vulnerability. It’s quite possible that Lenovo will do this by themselves — pushing an automated patch to all of their customers to remove the product — but I’m not holding my breath. If Lenovo does not do this, there are roughly three options:
Lenovo users live with this and/or manually patch. If the patch requires manual effort, I’d estimate it’ll be applied to about 30% of Lenovo laptops. Beware: the current uninstall package does not remove the certificate from the root store!
Microsoft drops the bomb. Microsoft has a nuclear option themselves in terms of cleaning up nasty software — they can use the Windows Update mechanism or (less universally) the Windows Defender tool to remove spyware/adware. Unfortunately not everyone uses Defender, and Microsoft is probably loath to push out updates like this without massive testing and a lot of advice from the lawyers.
Google and Mozilla fix internally. This seems like a more promising option. Google Chrome in particular is well known for quickly pushing out security updates that revoke keys, add public key pins, and generally make your browsing experience more secure.
It seems unlikely that #1 and #2 will happen anytime soon, so the final option looks initially like the most promising. Unfortunately it’s not that easy. To understand why, I’m going to sum up some reasoning given to me (on Twitter) by a couple of members of the Chrome security team.
The obvious solution to fixing things at the Browser level is to have Chrome and/or Mozilla push out an update to their browsers that simply revokes the Superfish certificate. There’s plenty of precedent for that, and since the private key is now out in the world, anyone can use it to build their own interception proxy. Sadly, this won’t work! If Google does this, they’ll instantly break every Lenovo laptop with Superfish still installed and running. That’s not nice, or smart business for Google.
A more promising option is to have Chrome at least throw up a warning whenever a vulnerable Lenovo user visits a page that’s obviously been compromised by a Superfish certificate. This would include most (secure) sites any Superfish-enabled Lenovo user visits — which would be annoying — and just a few pages for those users who have uninstalled Superfish but still have the certificate in their list of trusted roots.
This seems much nicer, but runs into two problems. First, someone has to write this code — and in a hurry, because attacks may begin happening immediately. Second, what action item are these warnings going to give people? Manually uninstalling certificates is hard, and until a very nice tool becomes available a warning will just be an irritation for most users.
One option for Google is to find a way to deal with these issues systemically — that is, provide an option for their browser to tunnel traffic through some alternative (secure) protocol to a proxy, where it can then go securely to its location without being molested by Superfish attackers of any flavor. This would obviously require consent by the user — nobody wants their traffic being routed through Google otherwise. But it’s at least technically feasible.
Google even has an extension for Android/iOS that works something like this: it’s a compressing proxy extension that you can install in Chrome. It will shrink your traffic down and send it to a proxy (presumably at Google). Unfortunately this proxy won’t work even if it was available for Windows machines — because Superfish will likely just intercept its connections too 😦
So that’s out too, and with it the last obvious idea I have for dealing with this in a clean, automated way. Hopefully the Google team will keep going until they find a better solution.
The moral of this story, if you choose to take one, is that you should never compromise security for the sake of a few bucks — because security is so terribly, awfully difficult to get back.
If you don’t follow NSA news obsessively, you might have missed yesterday’s massive Snowden document dump from Der Spiegel. The documents provide a great deal of insight into how the NSA breaks our cryptographic systems. I was very lightly involved in looking at some of this material, so I’m glad to see that it’s been published.
Unfortunately with so much material, it can be a bit hard to separate the signal from the noise. In this post I’m going to try to do that a little bit — point out the bits that I think are interesting, the parts that are old news, and the things we should keep an eye on.
Background
Those who read this blog will know that I’ve been wondering for a long time how NSA works its way around our encryption. This isn’t an academic matter, since it affects just about everyone who uses technology today.
What we’ve learned since 2013 is that NSA and its partners hoover up vast amounts of Internet traffic from fiber links around the world. Most of this data is plaintext and therefore easy to intercept. But at least some of it is encrypted — typically protected by protocols such as SSL/TLS or IPsec.
Conventional wisdom pre-Snowden told us that the increasing use of encryption ought to have shut the agencies out of this data trove. Yet the documents we’ve seen so far indicate just the opposite. Instead, the NSA and GCHQ have somehow been harvesting massive amounts of SSL/TLS and IPSEC traffic, and appear to be making inroads into other technologies such as Tor as well.
How are they doing this? To repeat an old observation, there are basically three ways to crack an encrypted connection:
Go after the mathematics. This is expensive and unlikely to work well against modern encryption algorithms (with a fewexceptions). The leaked documents give very little evidence of such mathematical breaks — though a bit more on this below.
Go after the implementation. The new documents confirm a previously-reported and aggressive effort to undermine commercial cryptographic implementations. They also provide context for how important this type of sabotage is to the NSA.
Steal the keys. Of course, the easiest way to attack any cryptosystem is simply to steal the keys. Yesterday we received a bit more evidence that this is happening.
I can’t possibly spend time on everything that’s covered by these documents — you should go read them yourself — so below I’m just going to focus on the highlights.
Not so Good Will Hunting
First, the disappointing part. The NSA may be the largest employer of cryptologic mathematicians in the United States, but — if the new story is any indication — those guys really aren’t pulling their weight.
In fact, the only significant piece of cryptanalytic news in the entire stack comes is a 2008 undergraduate research project looking at AES. Sadly, this is about as unexciting as it sounds — in fact it appears to be nothing more than a summer project by a visiting student. More interesting is the context it gives around the NSA’s efforts to break block ciphers such as AES, including the NSA’s view of the difficulty of such cryptanalysis, and confirmation that NSA has some ‘in-house techniques’.
Additionally, the documents include significant evidence that NSA has difficulty decrypting certain types of traffic, including Truecrypt, PGP/GPG, Tor and ZRTP from implementations such as RedPhone. Since these protocols share many of the same underlying cryptographic algorithms — RSA, Diffie-Hellman, ECDH and AES — some are presenting this as evidence that those primitives are cryptographically strong.
As with the AES note above, this ‘good news’ should also be taken with a grain of salt. With a small number of exceptions, it seems increasingly obvious that the Snowden documents are geared towards NSA’s analysts and operations staff. In fact, many of the systems actually seem aimed at protecting knowledge of NSA’s cryptanalytic capabilities from NSA’s own operational staff (and other Five Eyes partners). As an analyst, it’s quite possible you’ll never learn why a given intercept was successfully decrypted.
To put this a bit more succinctly: the lack of cryptanalytic red meat in these documents may not truly be representative of the NSA’s capabilities. It may simply be an artifact of Edward Snowden’s clearances at the time he left the NSA.
Tor
One of the most surprising aspects of the Snowden documents — to those of us in the security research community anyway — is the NSA’s relative ineptitude when it comes to de-anonymizing users of the Tor anonymous communications network.
The reason for our surprise is twofold. First, Tor was never really designed to stand up against a global passive adversary — that is, an attacker who taps a huge number of communications links. If there’s one thing we’ve learned from the Snowden leaks, the NSA (plus GCHQ) is the very definition of the term. In theory at least, Tor should be a relatively easy target for the agency.
The real surprise, though, is that despite this huge signals intelligence advantage, the NSA has barely even tested their ability to de-anonymize users. In fact, this leak provides the first concrete evidence that NSA is experimenting with traffic confirmation attacks to find the source of Tor connections. Even more surprising, their techniques are relatively naive, even when compared to what’s going on in the ‘research’ community.
This doesn’t mean you should view Tor as secure against the NSA. It seems very obvious that the agency has identified Tor as a high-profile target, and we know they have the resources to make much more headway against the network. The real surprise is that they haven’t tried harder. Maybe they’re trying now.
SSL/TLS and IPSEC
A few months ago I wrote a long post speculating about how the NSA breaks SSL/TLS. Because it’s increasingly clear that the NSA does break these protocols, and at relatively large scale.
The new documents don’t tell us much we didn’t already know, but they do confirm the basic outlines of the attack. The first portion requires endpoints around the world that are capable of performing the raw decryption of SSL/TLS sessions provided they know the session keys. The second is a separate infrastructure located on US soil that can recover those session keys when needed.
All of the real magic happens within the key recovery infrastructure. These documents provide the first evidence that a major attack strategy for NSA/GCHQ involves key databases containing the private keys for major sites. For the RSA key exchange ciphersuites of TLS, a single private key is sufficient to recover vast amounts of session traffic — in real time or even after the fact.
The interesting question is how the NSA gets those private keys. The easiest answer may be the least technical. A different Snowden leak shows gives some reason to believe that the NSA may have relationships with employees at specific named U.S. entities, and may even operate personnel “under cover”. This would certainly be one way to build a key database.
But even without the James Bond aspect of this, there’s every reason to believe that NSA has other means to exfiltrate RSA keys from operators. During the period in question, we know of at least one vulnerability (Heartbleed) that could have been used to extract private keys from software TLS implementations. There are still other, unreported vulnerabilities that could be used today.
Pretty much everything I said about SSL/TLS also applies to VPN protocols, with the additional detail that many VPNs use broken protocols and relatively poorly-secured pre-shared secrets that can in some cases be brute-forced. The NSA seems positively gleeful about this.
Open Source packages: Redphone, Truecrypt, PGP and OTR
The documents provide at least circumstantial evidence that some open source encryption technologies may thwart NSA surveillance. These include Truecrypt, ZRTP implementations such as RedPhone, PGP implementations, and Off the Record messaging. These packages have a few commonalities:
They’re all open source, and relatively well studied by researchers.
They’re not used at terribly wide scale (as compared to e.g., SSL or VPNs)
They all work on an end-to-end basis and don’t involve service providers, software distributers, or other infrastructure that could be corrupted or attacked.
What’s at least as interesting is which packages are not included on this list. Major corporate encryption protocols such as iMessage make no appearance in these documents, despite the fact that they ostensibly provide end-to-end encryption. This may be nothing. But given all we know about NSA’s access to providers, this is definitely worrying.
A note on the ethics of the leak
Before I finish, it’s worth addressing one major issue with this reporting: are we, as citizens, entitled to this information? Would we be safer keeping it all under wraps? And is this all ‘activist nonsense‘?
This story, more than some others, skates close to a line. I think it’s worth talking about why this information is important.
To sum up a complicated issue, we live in a world where targeted surveillance is probably necessary and inevitable. The evidence so far indicates that NSA is very good at this kind of work, despite some notable failuresin actually executing on the intelligence it produces.
Unfortunately, the documents released so far also show that a great deal of NSA/GCHQ surveillance is not targeted at all. Vast amounts of data are scooped up indiscriminately, in the hope that some of it will someday prove useful. Worse, the NSA has decided that bulk surveillance justifies its efforts to undermine many of the security technologies that protect our own information systems. The President’s own hand-picked review council has strongly recommended this practice be stopped, but their advice has — to all appearances — been disregarded. These are matters that are worthy of debate, but this debate hasn’t happened.
Unfortunate if we can’t enact changes to fix these problems, technology is probably about all that’s left. Over the next few years encryption technologies are going to be widely deployed, not only by individuals but also by corporations desperately trying to reassure overseas customers who doubt the integrity of US technology.
In that world, it’s important to know what works and doesn’t work. Insofar as this story tells us that, it makes us all better off.
Believe it or not, there’s a new attack on SSL. Yes, I know you’re thunderstruck. Let’s get a few things out of the way quickly.
First, this is not another Heartbleed. It’s bad, but it’s not going to destroy the Internet. Also, it applies only to SSLv3, which is (in theory) an obsolete protocol that we all should have ditched a long time ago. Unfortunately, we didn’t.
Anyway, enough with the good news. Let’s get to the bad.
The attack is called POODLE, and it was developed by Bodo Möller, Thai Duong and Krzysztof Kotowicz of Google. To paraphrase Bruce Schneier, attacks only get better — they never get worse. The fact that this attack is called POODLE also tells us that attack names do get worse. But I digress.
The rough summary of POODLE is this: it allows a clever attacker who can (a) control the Internet connection between your browser and the server, and (b) run some code (e.g., script) in your browser to potentially decrypt authentication cookies for sites such as Google, Yahoo and your bank. This is obviously not a good thing, and unfortunately the attack is more practical than you might think. You should probably disable SSLv3 everywhere you can. Sadly, that’s not so easy for the average end user.
To explain the details, I’m going to use the usual ‘fun’ question and answer format I employ for attacks like these.
What is SSL?
SSL is probably the most important security protocol on the Internet. It’s used to encrypt connections between two different endpoints, most commonly your web browser and a web server. We mostly refer to SSL by the dual moniker SSL/TLS, since the protocol suite known as Secure Sockets Layer was upgraded and renamed to Transport Layer Security back in 1999.
This bug has nothing to do with TLS, however. It’s purely a bug in the old pre-1999 SSL, and specifically version 3 — something we should have ditched a long time ago. Unfortunately, for legacy reasons many browsers and servers still support SSLv3 in their configurations. It turns out that when you try to turn this option off, a good portion of the Internet stops working correctly, thanks to older browsers and crappy load balancers, etc.
As a result, many modern browsers and servers continue to support SSLv3 as an option. The worst part of this is that in many cases an active attacker can actually trigger a fallback. That is, even if both the server and client support more modern protocols, as long as they’re willing to support SSLv3, an active attacker can force them to use this old, terrible protocol. In many cases this fallback is transparent to the user.
What’s the matter with SSL v3?
So many things it hurts to talk about. For our purposes we need focus on just one. This has to do with the structure of encryption padding used when encrypting with the CBC mode ciphersuites of SSLv3.
SSL data is sent in ‘record’ structures, where each record is first authenticated using a MAC. It’s subsequently enciphered using a block cipher (like 3DES or AES) in CBC mode. This MAC-then-encrypt design has been the cause of much heartache in the past. It’s also responsible for the problems now.
Here’s the thing: CBC mode encryption requires that the input plaintext length be equal to a multiple of the cipher’s block size (8 bytes in the case of 3DES, 16 bytes for AES). To make sure this is the case, SSL implementations add ‘padding’ to the plaintext before encrypting it. The padding can be up to one cipher block in length, is not covered by the MAC, and always ends with a single byte denoting the length of the padding that was added.
In SSLv3, the contents of the rest of the padding is unspecified. This is the problem that will vex us here.
How does the attack work?
Let’s imagine that I’m an active attacker who is able to obtain a CBC-encrypted record containing an interesting message like a cookie. I want to learn a single byte of this cookie — and I’m willing to make the assumption that this byte happens to live at the end of a cipher block boundary.
(Don’t worry about how I know that the byte I want to learn is in this position. Just accept this as a given for now.)
Imagine further that the final block of the record in question contains a full block of padding. If we’re using AES as our cipher, this means that the last byte of the plaintext of the final block contains a ’15’ value, since there are 15 bytes of padding. The preceding 15 bytes of said block contain arbitrary values that the server will basically strip off and ignore upon decryption, since SSLv3 doesn’t specify what they should contain. (NB: TLS does, which prevents this issue.)
The attack works like this. Since I control the Internet connection, I can identify the enciphered block that I want to learn within an encrypted record. I can then substitute (i.e., move) this block in place of the final block that should contain only padding.
When the server receives this new enciphered record, it will go ahead and attempt to decrypt the final block (which I’ll call C_n) using the CBC decryption equation, which looks like this:
Decrypted final block := Decipher(C_n) XOR C_{n-1}
Note that C_{n-1} is the second-to-last block of the encrypted record.
If the decrypted final block does not contain a ’15’ in the final position, the server will assume either that the block is bogus (too much padding) or that there’s less padding in the message than we intended. In the former case it will simply barf. In the latter case it will assume that the meaningful message is longer than it actually is, which should trigger an error in decryption since MAC verification will fail. This should also terminate the SSL connection.
Indeed, this is by far the most likely outcome of our experiment, since the deciphered last byte is essentially random — thus failure will typically occur 255 out of every 256 times we try this experiment. In this case we have to renegotiate the handshake and try again.
Every once in a while we’ll get lucky. In 1/256 of the cases, the deciphered final block will contain a 15 byte at the final position, and the server will accept this as as a valid padding length. The preceding fifteen bytes have also probably been changed, but the server will then strip off and ignore those values — since SSLv3 doesn’t care about the contents of the padding. No other parts of the ciphertext have been altered, so decryption will work perfectly and the server should report no errors.
This case is deeply meaningful to us. If this happens, we know that the decipherment of the final byte of C_n, XORed with the final byte of the preceding ciphertext block, is equal to ’15’. From this knowledge we can easily determine the actual plaintext value of the original byte we wanted to learn. We can recover this valueby XORing it with the final byte of the preceding ciphertext block, then XOR that with the last byte of the ciphertext block that precedes the original block we targeted.
Voila, in this case — which occurs with probability 1/256 — we’ve decrypted a single byte of the cookie.
The important thing to know is that if at first we don’t succeed, we can try, try again. That’s because each time we fail, we can re-run the SSL handshake (which changes the encryption key) and try the attack again. As long as the cookie byte we’re attacking stays in the same position, we can continue our attempts until we get lucky. The expected number of attempts needed for success is 256.
We’ve got one byte, how do we get the rest?
The ability to recover a single byte doesn’t seem so useful, but in fact it’s all we need to decipher the entire cookie — if we’re able to control the cookie’s alignment and location within the enciphered record. In this case, we can simply move one byte after another into that critical final-byte-of-the-cipher-block location and run the attack described above.
One way to do this is to trick the victim’s browser into running some Javascript we control. This script will make SSL POST requests to a secure site like Google. Each time it does so, it will transmit a request path first, followed by an HTTP cookie and other headers, followed by a payload it controls.
Since the script controls the path and payload, by varying these values and knowing the size of the intermediate headers, the script can systematically align each specific byte of the cookie to any location it wants. It can also adjust the padding length to ensure that the final block of the record contains 16 bytes of padding.
This means that our attack can now be used to decrypt an entire cookie, with an average of 256 requests per cookie byte. That’s not bad at all.
So should we move to West Virginia and stock up on canned goods?
Portions of the original SSL v3 specification being
reviewed at IETF 90.
Maybe. But I’m not so sure. For a few answers on what to do next, see Adam Langley and Rob Graham’s blog posts on this question.
Note that this entire vulnerability stems from the fact that SSLv3 is older than Methuselah. In fact, there are voting-age children who are younger than SSLv3. And that’s worrying.
The obvious and correct solution to this problem is find and kill SSLv3 anywhere it lurks. In fact, this is something we should have done in the early 2000s, if not sooner. We can do it now, and this whole problem goes away.
The problem with the obvious solution is that our aging Internet infrastructure is still loaded with crappy browsers and servers that can’t function without SSLv3 support. Browser vendors don’t want their customers to hit a blank wall anytime they access a server or load balancer that only supports SSLv3, so they enable fallback. Servers administrators don’t want to lock out the critical IE6 market, so they also support SSLv3. And we all suffer.
Hopefully this will be the straw that breaks the camel’s back and gets us to abandon obsolete protocols like SSLv3. But nobody every went bankrupt betting on insecurity. It’s possible that ten years from now we’ll still be talking about ways to work around POODLE and its virulent flesh-eating offspring. All we can do is hope that reason will prevail.
The other day Apple released a major security update that fixes a number of terrifying things that can happen to your OS/X and iOS devices. You should install it. Not only does this fix a possible remote code execution vulnerability in the JPEG parser (!), it also patches a TLS/SSL protocol bug known as the “Triple Handshake” vulnerability. And this is great timing, since Triple Handshakes are something I’ve been meaning (and failing) to write about for over a month now.
But before we get there: a few points of order.
First, if Heartbleed taught us one thing, it’s that when it comes to TLS vulnerabilities, branding is key. Henceforth, and with apologies to Bhargavan, Delignat-Lavaud, Pironti, Fournet and Strub (who actually discovered the attack*), for the rest of this post I will be referring to the vulnerability simply as “3Shake”. I’ve also taken the liberty of commissioning a logo (courtesy @Raed667). I hope you like it.
On a more serious note, 3Shake is not Heartbleed. That’s both good and bad. It’s good because Heartbleed was nasty and 3Shake really isn’t anywhere near as dangerous. It’s bad since, awful as it was, Heartbleed was only an implementation vulnerability — and one in a single TLS library to boot. 3Shake represents a novel and fundamental bug in the TLS protocol.
The final thing you should know about 3Shake is that, according to the cryptographic literature, it shouldn’t exist.
You see, in the last few years there have been at least threefourmajorcryptopapers purporting to prove the TLS protocol secure. The existence of 3Shake doesn’t make those results wrong. It may, however, indicate that cryptographers need to think a bit more about what ‘secure’ and ‘TLS’ actually mean. For me, that’s the most fascinating implication of this new attack.
I’ll proceed with the usual ‘fun’ question-and-answer format I save for this sort of thing.
What is TLS and why should you care?
Since you’re reading this blog, you probably already know something about TLS. You might even realize how much of our infrastructure is protected by this crazy protocol.
In case you don’t: TLS is a secure transport protocol that’s designed to establish communications between two parties, who we’ll refer to as the Client and the Server. The protocol consists of two sub-protocols called the handshake protocol and the record protocol. The handshake is intended to authenticate the two communicating parties and establish shared encryption keys between them. The record protocol uses those keys to exchange data securely.
For the purposes of this blog post, we’re going to focus primarily on the handshake protocol, which has (at least) two major variants: the RSA handshake and the Diffie-Hellman handshake (ECDHE/DHE). These are illustrated below.
Simplified description of the TLS handshakes. Top: RSA handshake. Bottom: Diffie-Hellman handshake.
All this means we’re just now starting to uncover some of the bugs that have been present in the protocol since it was first designed. And we’re likely to discover more! That’s partly because this analysis is at a very early stage. It’s also partly because, from an analysts’ point of view, we’re still trying to figure out exactly what the TLS handshake is supposed to do.As much as I love TLS, the protocol is a hot mess. For one thing, it inherits a lot of awful cryptography from its ancient predecessors (SSLv1-3). For another, it’s only really beginning to be subjected to rigorous, formal analysis.
Well, what is the TLS handshake supposed to do?
Up until this result, we thought we had a reasonable understanding of the purpose of the TLS handshake. It was intended to authenticate one or both sides of the connection, then establish a shared cryptographic secret (called the Master Secret) that could be used to derive cryptographic keys for encrypting application data.
The first problem with this understanding is that it’s a bit too simple. There isn’t just one TLS handshake, there are several variants of it. Worse, multiple different handshake types can be used within a single connection.
The standard handshake flow is illustrated — without crypto — in the diagram below. In virtually every TLS connection, the server authenticates to the client by sending a public key embedded in a certificate. The client, for its part, can optionally authenticate itself by sending a corresponding certificate and proving it has the signing key. However this client authentication is by no means common. Many TLS connections are authenticated only in one direction.
Common TLS handshakes. Left: only server authenticates.
Right: client and server both authenticate with certificates.
TLS also supports a “renegotiation” handshake that can switch an open connection from one mode to the other. This is typically used to change a connection that was authenticated only in one direction (Server->Client) into a connection that’s authenticated in both directions. The server usually initiates renegotiation when the client has e.g., asked for a protected resource.
Renegotiating a session. A new handshake causes the existing connection to be mutually authenticated.
Renegotiation has had problems before. Back in 2009, Ray and Dispensa showed that a man-in-the-middle attacker could actually establish a (non-authenticated) connection with some server; inject some data; and when the server asks for authentication, the attacker could then “splice” on a real connection with an authorized client by simply forwarding the new handshake messages to the legitimate client. From the server’s point of view, both communications would seem to be coming from the same (now authenticated) person:
Ray/Dispensa attack from 2009. The attacker first establishes an unauthenticated connection and injects some traffic (“drop table *”). When the server initiates a renegotiation for client authentication, the attacker forwards the new handshake messages to an honest client Alice who then sends real traffic. Since the handshakes are not bound together, Bob views this as a single connection to one party.
To fix this, a “secure renegotiation” band-aid to TLS was proposed. The rough idea of this extension was to ‘bind’ the renegotiation handshake to the previous handshake, by having the client present the “Finished” message of the previous handshake. Since the Finished value is (essentially) a hash of the Master Secret and the (hash of) the previous handshake messages, this allows the client to prove that it — not an attacker — truly negotiated the previous connection.
All of this brings us back to the question of what the TLS handshake is supposed to do.
You see, the renegotiation band-aid now adds some pretty interesting new requirements to the TLS handshake. For one thing, the security of this extension depends on the idea that (1) no two distinct handshakes will happen to use the same Master Secret, and (2) that no two handshakes will have the same handshake messages, ergo (3) no two handshakes will have the same Finished message.
Intuitively, this seemed like a pretty safe thing to assume — and indeed, many other systems that do ‘channel binding’ on TLS connections also make this assumption. The 3Shake attack shows that this is not safe to assume at all.
So what’s the problem here?
It turns out that TLS does a pretty good job of establishing keys with people you’ve authenticated. Unfortunately there’s a caveat. It doesn’t truly guarantee the established key will be uniqueto your connection. This is a pretty big violation of the assumptions that underlie the “secure renegotiation” fix described above.
For example: imagine that Alice is (knowingly) establishing a TLS connection to a server Mallory. It turns out that Mallory can simultaneously — and unknown to Alice — establish a different connection to a second server Bob. Moreover, if Mallory is clever, she can force both connections to use the same “Master Secret” (MS).
Mallory creates two connections that use the same Master Secret.
The first observation of the 3Shake attack is that this trick can be played if Alice supports either of the or RSA and DHE handshakes — or both (it does not seem to work on ECDHE). Here’s the RSA version:**
RSA protocol flow from the triple handshake attack (source). The attacker is in the middle, while the client and server are on the left/right respectively. MS is computed as a function of (pms, cr, sr) which are identical in both handshakes.
So already we have a flaw in the logic undergirding secure renegotiation. The Master Secret (MS) values are not necessarily distinct between different handshakes.
Fortunately, the above attack does not let us resurrect the Ray/Dispensa injection attack. While the attacker has tricked the client into using a specific MS value, the handshake Finished messages — which the client will attach to the renegotiation handshake — will not be the same in both handshakes. That’s because (among other things) the certificates sent on each connection were very different, hence the handshake hashes are not identical. In theory we’re safe.
But here is where TLS gets awesome.
You see, there is yet another handshake I haven’t told you about. It’s called the “session resumption handshake”, and it allows two parties who’ve previously established a master secret (and still remember it) to resume their session with new encryption keys. The advantage of resumption is that it uses no public-key cryptography or certificates at all, which is supposed to make it faster.
It turns out that if an attacker knows the previous MS and has caused it to be the same on both sides, it can now wait until the client initiates a session resumption. Then it can replay messages between the client and server in order to update both connections with new keys:
An attacker replays the session resumption handshake to ensure the same key on both sides. Note that the handshake messages are identical in both connections. (authors of source)
Which brings us to the neat thing about this handshake. Not only is the MS the same on both connections, but both connections now see exactly the same (resumption) handshake messages. Hence the hash of these handshakes will be identical, which means in turn that their “Finished” message will be identical.
By combining all of these tricks, a clever attacker can pull off the following — and absolutely insane — “triple handshake” injection attack:
Triple handshake attack. The attacker mediates two handshakes that give MS on both sides, but two different handshake hashes. The resumption handshake leaves the same MS and an identical handshake hash on both sides. This means that the Finished message from the resumption handshake will be the same for the connections on either side of the attacker. Now he can hook up the two without anyone noticing that he previously injected traffic.
In the above scenario, an attacker first runs a (standard) handshake to force both sides of the connection to use the same MS. It then causes both sides to perform session resumption, which results in both sides using the same MSand having the same handshake hash and Finished messages on both sides. When the server initiates renegotiation, the attacker can forward the third (renegotiation) handshake on to the legitimate client as in the Ray/Dispensa attack — secure in the knowledge that both client and server will expect the same Finished token.
And that’s the ballgame.
What’s the fix?
There are several, and you can read about them here.
One proposed fix is to change the derivation of the Master Secret such that it includes the handshake hash. This should wipe out most of the attacks above. Another fix is to bind the “session resumption” handshake to the original handshake that led to it.
Wait, why should I care about injection attacks?
You probably don’t, unless you happen to be one of the critical applications that relies on the client authentication and renegotiation features of TLS. In that case, like most applications, you probably assumed that a TLS connection opened with a remote user was actually from that user the whole time, and not from two different users.
If you — like most applications — made that assumption, you might also forget to treat the early part of the connection (prior to client authentication) as a completely untrusted bunch of crap. And then you’d be in a world of hurt.
What does this have to do with the provable security of TLS?
Of all the questions 3Shake raises, this one is the most interesting. As I mentioned earlier, there have been several recent works that purport to prove things about the security of TLS. They’re all quite good, so don’t take any of this as criticism.
The first reason is simple: many of these works analyze only the basic TLS handshake, or they omit at least one of the possible handshakes (e.g., resumption). This means they don’t catch the subtle interactions between the resumption handshake, the renegotiation handshake, and extensions — all of which are the exact ingredients that make most TLS attacks possible.
The second problem is that we don’t quite know what standard we’re holding TLS to. For example, the common definition of security for TLS is called “Authenticated and Confidential Channel Establishment” (ACCE). Roughly speaking this ensures that two parties can establish a channel and that nobody will be able to determine what data is being sent over said channel.
The problem with ACCE is that it’s a definition that was developed specifically so that TLS could satisfy it. As a result, it’s necessarily weak. For example, ACCE does not actually require that each handshake produces a unique Master Secret — one of the flaws that enables this attack — because such a definition was not possible to achieve with the existing TLS protocol. In general this is what happens when you design a protocol first and prove things about it later.
What’s the future for TLS? Can’t we throw the whole thing out and start over again?
Sure, go ahead and make TLS Rev 2. It can strip out all of this nonsense and start fresh.
But before you get cocky, remember — all these crazy features in TLS were put there for a reason. Someone wanted and demanded them. And sadly, this is the difference between a successful, widely-used protocol and your protocol.
Your new replacement for TLS might be simple and wonderful today, but that’s only because nobody uses it. Get it out into the wild and before long it too will be every bit as crazy as TLS.
Notes: * An earlier version of this post incorrectly identified the researchers who discovered the attack.
** The Diffie-Hellman (DHE) version is somewhat more clever. It relies on the attacker manipulating the D-H parameters such that they will force the client to use a particular key. Since DHE parameters sent down from the server are usually ‘trusted’ by TLS implementations, this trick is relatively easy to pull off.
A few weeks ago I wrote a long post about theNSA’s ‘BULLRUN’ project to subvert modern encryption standards. I had intended to come back to this at some point, since I didn’t have time to discuss the issues in detail. But then things got in the way. A lot of things, actually. Some of which I hope to write about in the near future.
But before I get there, and at the risk of boring you all to tears, I wanted to come back to this subject at least one more time, if only to pontificate a bit about a question that’s been bugging me.
You see, the NSA BULLRUN briefing sheet mentions that NSA has been breaking quite a few encryption technologies, some of which are more interesting than others. One of those technologies is particularly surprising to me, since I just can’t figure how NSA might be doing it. In this extremely long post I’m going to try to dig a bit deeper into the most important question facing the Internet today.
Specifically: how the hell is NSA breaking SSL?
Section of the BULLRUN briefing sheet. Source: New York Times.
To keep things on target I’m going to make a few basic ground rules.
First, I’m well aware that NSA can install malware on your computer and pwn any cryptography you choose. That doesn’t interest me at all, for the simple reason that it doesn’t scale well. NSA can do this to you, but they can’t do it for an entire population. And that’s really what concerns me about the recent leaks: the possibility that NSA is breaking encryption for the purposes of mass surveillance.
For the same reason, we’re not going to worry about man-in-the-middle (MITM) attacks. While we know that NSA does run these, they’re also a very targeted attack. Not only are MITMs detectable if you do them at large scale, they don’t comport with what we know about how NSA does large-scale interception — mostly via beam splitters and taps. In other words: we’re really concerned about passive surveillance.
The rules above aren’t absolute, of course. We will consider limited targeted attacks on servers, provided they later permit passive decryption of large amounts of traffic; e.g., decryption of traffic to major websites. We will also consider arbitrary modifications to software and hardware — something we know NSA is already doing.
One last point: to keep things from going off the rails, I’ve helpfully divided this post into two sections. The first will cover attacks that use only known techniques. Everything in this section can be implemented by a TAO employee with enough gumption and access to software. The second section, which I’ve titled the ‘Tinfoil Hat Spectrum‘ covers the fun and speculative stuff — ranging from new side channel attacks all the way to that huge quantum computer the NSA keeps next to BWI.
We’ll start with the ‘practical’.
Attacks that use Known Techniques
Theft of RSA keys.The most obvious way to ‘crack’ SSL doesn’t really involve cracking anything. Why waste time and money on cryptanalysis when you can just steal the keys? This issue is of particular concern in servers configured for the TLS RSA handshake, where a single 128-byte server key is all you need to decrypt every past and future connection made from the device.
In fact, this technique is so obvious that it’s hard to imagine NSA spending a lot of resources on sophisticated cryptanalytic attacks. We know that GCHQ and NSA are perfectly comfortable suborning even US providers overseas. And inside our borders, they’ve demonstrated a willingness to obtain TLS/SSL keys using subpoena powers and gag orders. If you’re using an RSA connection to a major website, it may be sensible to assume the key is already known.
Of course, even where NSA doesn’t resort to direct measures, there’s always the possibility of obtaining keys via a remote software exploit. The beauty is that these attacks don’t even require remote code execution. Given the right vulnerability, it may simply require a handful of malformed SSL requests to map the full contents of the OpenSSL/SChannel heap.
Suborning hardware encryption chips. A significant fraction of SSL traffic on the Internet is produced by hardware devices such as SSL terminators and VPN-enabled routers. Fortunately we don’t have to speculate about the security of these devices — we already know NSA/GCHQ have been collaborating with hardware manufacturers to ‘enable’ decryption on several major VPN encryption chips.
The NSA documents aren’t clear on how this capability works, or if it even involves SSL. If it does, the obvious guess is that each chip encrypts and exflitrates bits of the session key via ‘random’ fields such as IVs and handshake nonces. Indeed, this is relatively easy to implement on an opaque hardware device. The interesting question is how one ensures these backdoors can only be exploited by NSA — and not by rival intelligence agencies. (Some thoughts on that here.)
Side channel attacks. Traditionally when we analyze cryptographic algorithms we concern ourselves with the expected inputs and outputs of the system. But real systems leak all kinds of extra information. These ‘side channels’ — whichinclude operation time, resource consumption, cache timing, and RF emissions — can often be used to extract secret key material.
The good news is that most of these channels are only exploitable when the attacker is in physical proximity to a TLS server. The bad news is that there are conditions in which the attacker can get close. The most obvious example involves virtualized TLS servers in the cloud setting, where a clever attacker may share physical resources with the target device.
A second class of attack uses remote timing information to slowly recover an RSA key. These attacks can be disabled via countermeasures such as RSA blinding, though amusingly, some ‘secure’ hardware co-processors may actually turn these countermeasures off by default! At very least, this makes the hardware vulnerable to attacks by a local user, and could even facilitate remote recovery of RSA keys.
Weak random number generators. Even if you’re using strong Perfect Forward Secrecy ciphersuites, the security of TLS depends fundamentally on the availability of unpredictable random numbers. Not coincidentally, tampering with random number generator standards appears to have been a particular focus of NSA’s efforts.
Random numbers are critical to a number of elements in TLS, but they’re particularly important in three places:
On the client side, during the RSA handshake. The RNG is used to generate the RSA pre-master secret and encryption padding. If the attacker can predict the output of this generator, she can subsequently decrypt the entire session. Ironically, a failure of the server RNG is much less devastating to the RSA handshake.*
On the client or server side, during the Diffie-Hellman handshake(s). Since Diffie-Hellman requires a contribution from each side of the connection, a predictable RNG on either side renders the session completely transparent.
During long-term key generation, particularly of RSA keys. If this happens, you’re screwed.
And you just don’t need to be that sophisticated to weaken a random number generator. These generators are already surprisingly fragile, and it’s awfully difficult to detect when one is broken. Debian’s maintainers made this point beautifully back in 2008 when an errant code cleanup reduced the effective entropy of OpenSSL to just 16 bits. In fact, RNGs are so vulnerable that the challenge here is not weakening the RNG — any idiot with a keyboard can do that — it’s doing so without making the implementation trivially vulnerable to everyone else.
The good news is that it’s relatively easy to tamper with an SSL implementation to make it encrypt and exfiltrate the current RNG seed. This still requires someone to physically alter the library, or install a persistent exploit, but it can be done cleverly without even adding much new code to the existing OpenSSL code. (OpenSSL’s love of function pointers makes it particularly easy to tamper with this stuff.)
If tampering isn’t your style, why not put the backdoor in plain sight? That’s the approach NSA took with the Dual_EC RNG, standardized by NIST in Special Publication 800-90. There’s compelling evidence that NSA deliberately engineered this generator with a backdoor — one that allows them to break any TLS/SSL connection made using it. Since the generator is (was) the default in RSA’s BSAFE library, you should expect every TLS connection made using that software to be potentially compromised.
Esoteric Weaknesses in PFS systems.Many web servers, including Google and Facebook, now use Perfect Forward Secrecy ciphersuites like ephemeral Diffie-Hellman (DHE and ECDHE). In theory these ciphersuites provide the best of all possible worlds: keys persist for one session and then disappear once the connection is over. While this doesn’t save you from RNG issues, it does make key theft a whole lot more difficult.
PFS ciphersuites are a good thing, but a variety of subtle issues can cramp their style. For one thing, the session resumption mechanism can be finicky: session keys must either be stored locally, or encrypted and given out to users in the form of session tickets. Unfortunately, the use of session tickets somewhat diminishes the ‘perfectness’ of PFS systems, since the keys used for encrypting the tickets now represent a major weakness in the system. Moreover, you can’t even keep them internal to one server, since they have to be shared among all of a site’s front-end servers! In short, they seem like kind of a nightmare.
A final area of concern is the validation of Diffie-Hellman parameters. The current SSL design assumes that DH groups are always honestly generated by the server. But a malicious implementation can violate this assumption and use bad parameters, which enable third party eavesdropping. This seems like a pretty unlikely avenue for enabling surveillance, but it goes to show how delicate these systems are.
The Tinfoil Hat Spectrum
I’m going to refer to the next batch of attacks as ‘tinfoil hat‘ vulnerabilities. Where the previous issues all leverage well known techniques, each of the following proposals require totally new cryptanalytic techniques. All of which is a way of saying that the following section is pure speculation. It’s fun to speculate, of course. But it requires us to assume facts not in evidence. Moreover, we have to be a bit careful about where we stop.
So from here on out we are essentially conducting a thought-experiment. Let’s imagine the NSA has a passive SSL-breaking capability; and furthermore, that it doesn’t rely on the tricks of the previous section. What’s left?
The following list begins with the most ‘likely’ theories and works towards the truly insane.
Breaking RSA keys. There’s a persistent rumor in our field that NSA is cracking 1024-bit RSA keys. It’s doubtful this rumor stems from any real knowledge of NSA operations. More likely it’s driven by the fact that cracking 1024-bit keys is highly feasible for an organization with NSA’s resources.
How feasible? Several credible researchers have attempted to answer this question, and it turns out that the cost is lower than you think. Way back in 2003, Shamir and Tromer estimated $10 million for a purpose-built machine that could factor one 1024-bit key per year. In 2013, Tromer reduced those numbers to about $1 million, factoring in hardware advances. And it could be significantly lower. This is pocket change for NSA.
Along similar lines, Bernstein, Heninger and Lange examined at the feasibility of cracking RSA using distributed networks of standard PCs. Their results are pretty disturbing: in principal, a cluster about the size of the real-life Conficker botnet could do serious violence to 1024-bit keys.
Given all this, you might ask why this possibility is even in the ‘tinfoil hat’ category. The simple answer is: because nobody’s actually done it. That means it’s at least conceivable that the estimates above are dramatically too high — or even too low. Moreover, RSA-1024 keys are being rapidly being phased out. Cracking 2048 bit keys would require significant mathematical advances, taking us much deeper into the tinfoil hat.**
Cracking RC4. On paper, TLS supports a variety of strong encryption algorithms. In practice, about half of all TLS traffic is secured with the creaky old RC4 cipher. And this should worry you — because RC4 is starting to show its age. In fact, as used in TLS it’s already vulnerable to (borderline) practical attacks. Thus it seems like a nice candidate for a true cryptanalytic advance on NSA’s part.
Unfortunately the problem with this theory is that we simply don’t know of any attack that would allow the NSA to usefully crack RC4! The known techniques require an attacker to collect thousands or millions of ciphertexts that are either (a)encrypted with related keys (as in WEP) or (b)contain the same plaintext. The best known attack against TLS takes the latter form — it requires the victim to establish billions of sessions, and even then it only recovers fixed plaintext elements like cookies or passwords.
The counterargument is that the public research community hasn’t been thinking very hard about RC4 for the past decade — in part because we thought it was so broken people had stopped using it (oops!) If we’d been focusing all our attention on it (or better, the NSA’s attention), who knows what we’d have today.
If you told me the NSA had one truly new cryptanalytic capability, I’d agree with Jake and point the finger at RC4. Mostly because the alternatives are far scarier.
New side-channel attacks. For the most part, remote timing attacks appear to have been killed off by the implementation of countermeasures such as RSA blinding, which confound timing by multiplying a random blinding factor into each ciphertext prior to decryption. In theory this should make timing information essentially worthless. In practice, many TLS implementations implement compromises in the blinding code that might resurrect these attacks, things like squaring a blinding factor between decryption operations, rather than generating a new one each time. It’s quite unlikely there are attacks here, but who knows.
Goofy stuff.Maybe NSA does have something truly amazing up its sleeve. The problem with opening this Pandora’s box is that it’s really hard to get it closed again. Did Jerry Solinas really cook the NIST P-curves to support some amazing new attack (which NSA knew about way back in the late 1990s, but we have not yet discovered)? Does the NSA have a giant supercomputer named TRANSLTR that can brute-force any cryptosystem? Is there a giant quantum computer at the BWI Friendship annex? For answers to these questions you may as well just shake the Magic 8-Ball, cause I don’t have a clue.
Conclusion
We don’t know and can’t know the answer to these things, and honestly it’ll make you crazy if you start thinking about it. All we can really do is take NSA/GCHQ at their word when they tell us that these capabilities are ‘extremely fragile’. That should at least give us hope.
The question now is if we can guess well enough to turn that fragility from a warning into a promise. Notes:
* A failure of the server RNG could result in some predictable values like the ServerRandom and session IDs. An attacker who can predict these values may be able to run active attacks against the protocol, but — in the RSA ciphersuite, at least — they don’t admit passive compromise.
** Even though 1024-bit RSA keys are being eliminated, many servers still use 1024-bit for Diffie-Hellman (mostly for efficiency reasons). The attacks on these keys are similar to the ones used against RSA — however, the major difference is that fresh Diffie-Hellman ‘ephemeral’ keys are generated for each new connection. Breaking large amounts of traffic seems quite costly.
 At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and some of my colleagues, however, it was like that scene in X-Files where Mulder and Scully finally learn that aliens are real.
At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and some of my colleagues, however, it was like that scene in X-Files where Mulder and Scully finally learn that aliens are real. on TLS. In that context, this summer has been a blessed relief. Sadly, it looks like our vacation is over, and it’s time to go back to school.
on TLS. In that context, this summer has been a blessed relief. Sadly, it looks like our vacation is over, and it’s time to go back to school. implies, these are schemes designed to encipher data in blocks, rather than a single bit at a time.
implies, these are schemes designed to encipher data in blocks, rather than a single bit at a time.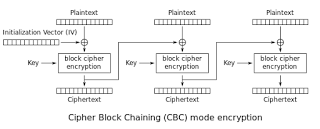
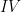 ) of size equal to the block size of the cipher, then XORing
) of size equal to the block size of the cipher, then XORing  ), and enciphering the result (
), and enciphering the result (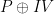 ). The
). The 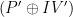 that created the previous block.
that created the previous block.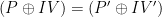 , which can be rearranged as
, which can be rearranged as  . Since the IVs are random and known to the attacker, the attacker has (with high probability) learned the XOR of two (unknown) plaintexts!
. Since the IVs are random and known to the attacker, the attacker has (with high probability) learned the XOR of two (unknown) plaintexts! encrypted blocks.
encrypted blocks.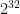 , or around 4 billion enciphered blocks.
, or around 4 billion enciphered blocks.
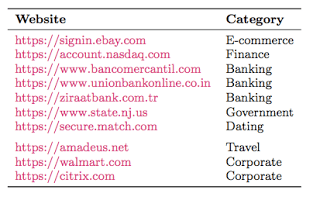




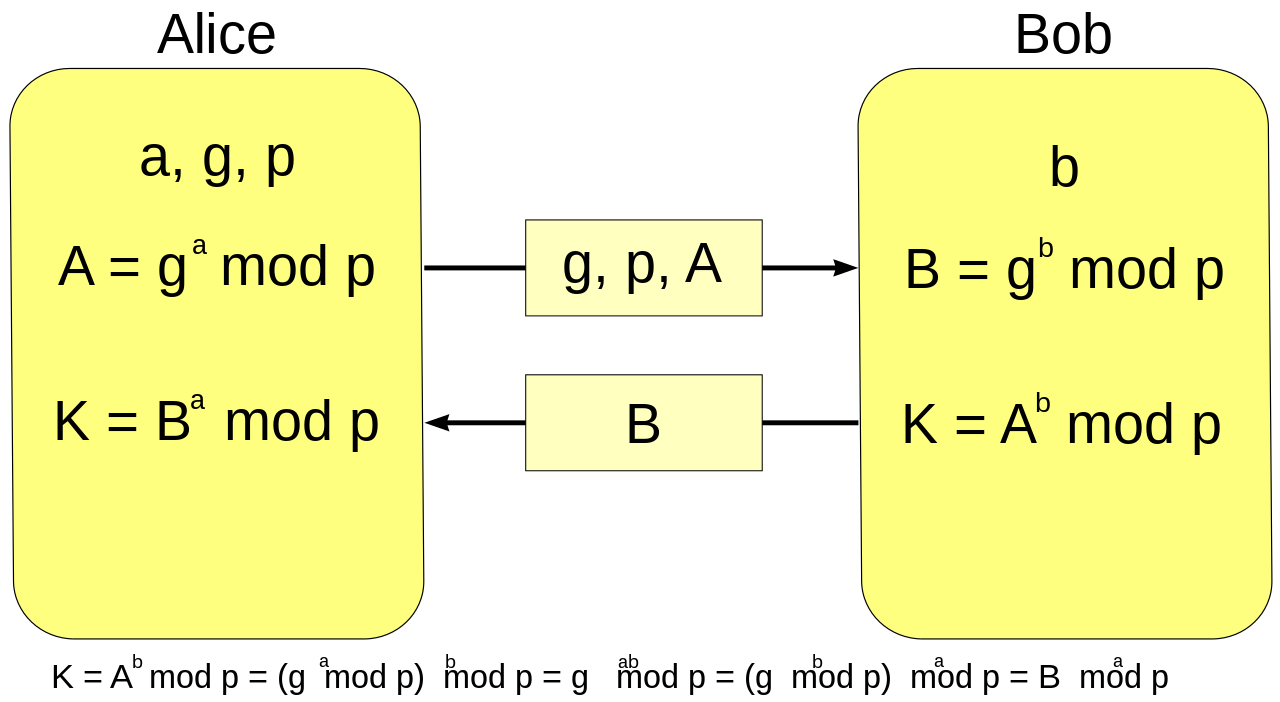
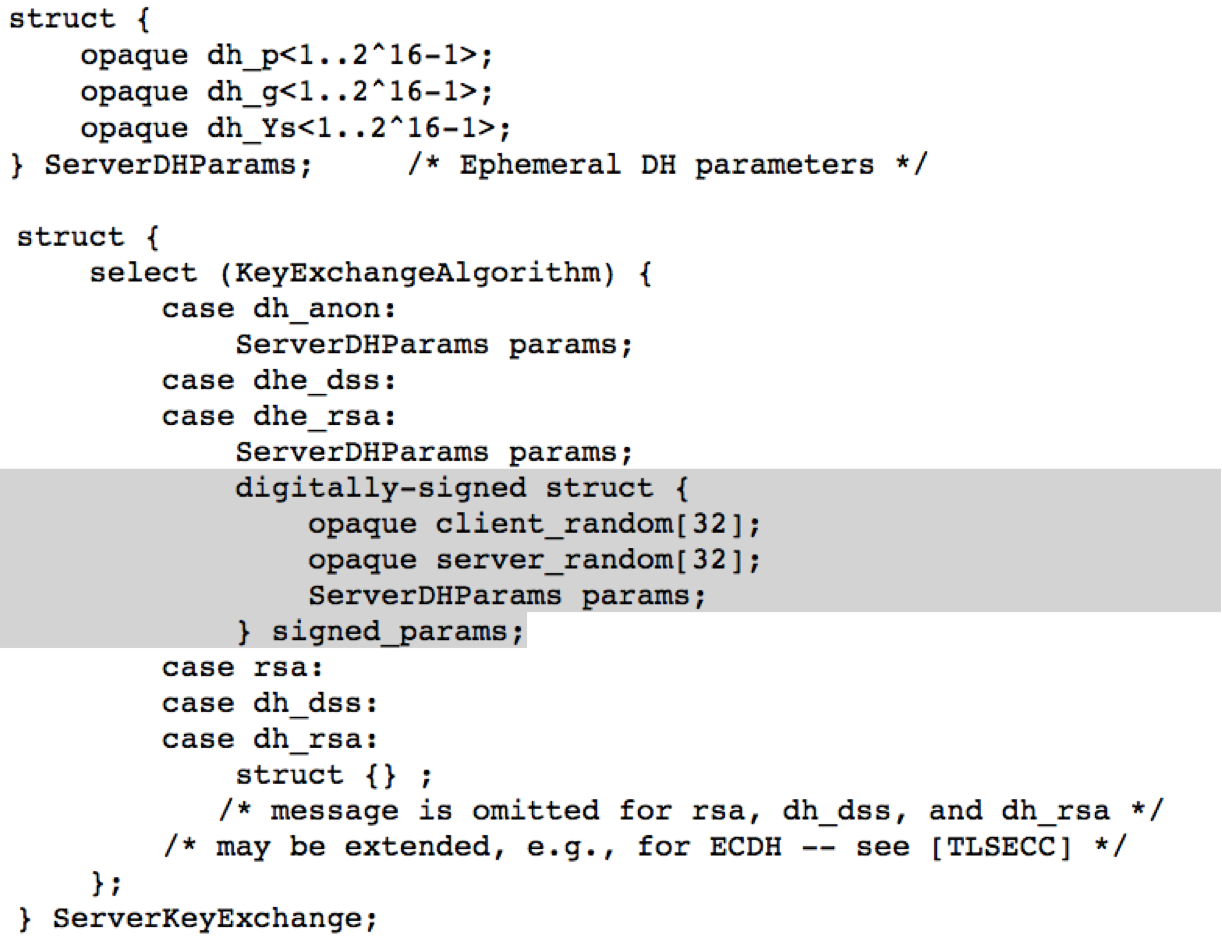
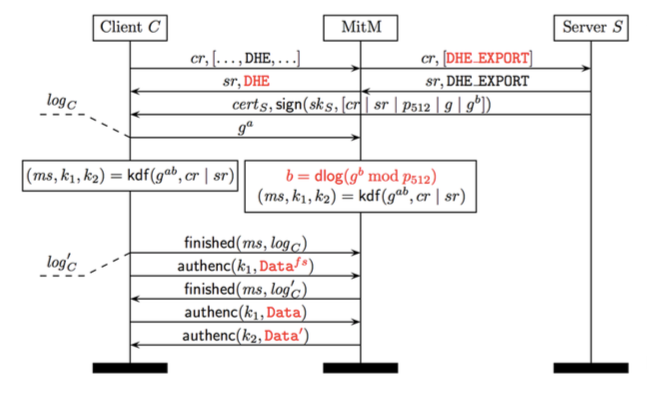
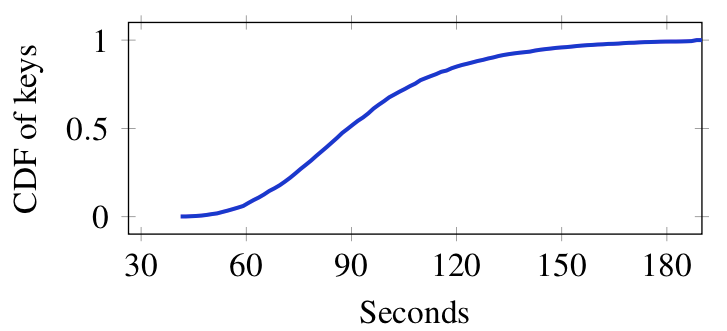

 cryptographers ‘hacked’ the NSA. It’s also a story of encryption backdoors, and why they never quite work out the way you want them to.
cryptographers ‘hacked’ the NSA. It’s also a story of encryption backdoors, and why they never quite work out the way you want them to.






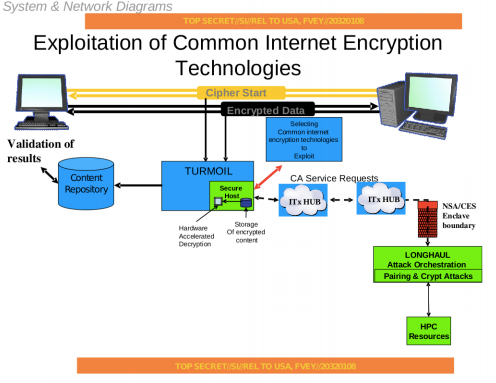





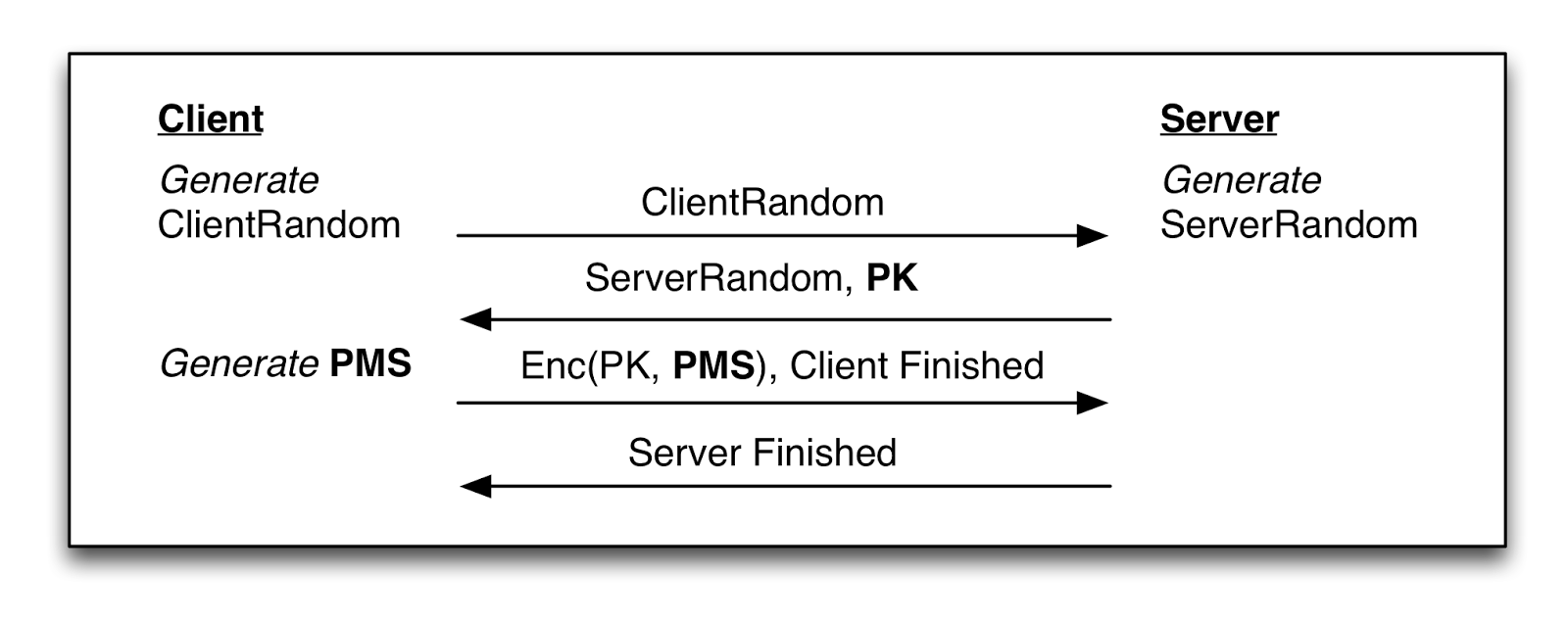



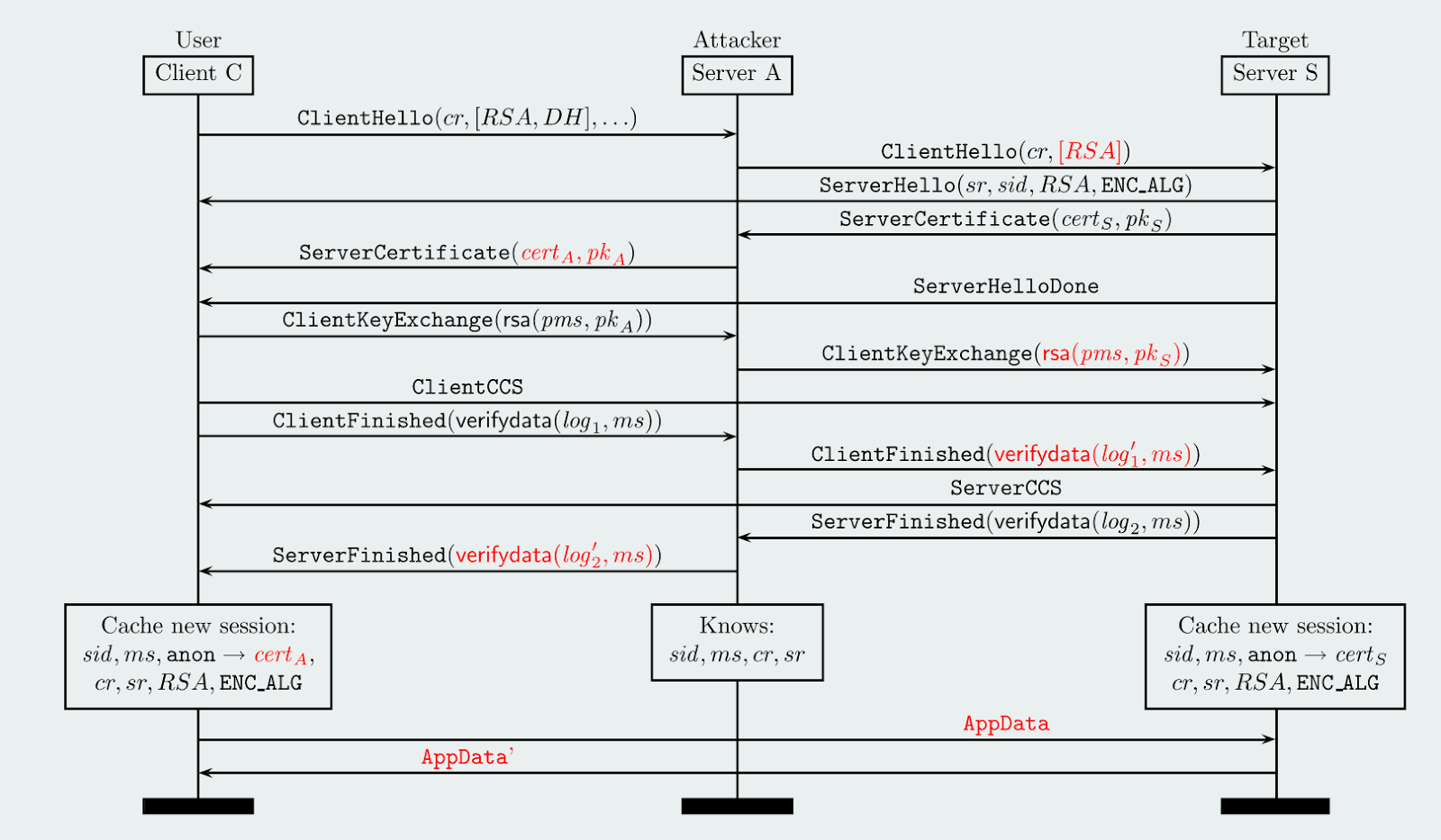







{kind=link}