Ever since I started writing this blog (and specifically, the posts on SSL/TLS) I’ve had a new experience: people come up to me and share clever attacks that they haven’t made public yet.
This is pretty neat — like being invited to join an exclusive club. Unfortunately, being in this club mostly sucks. That’s because the first rule of ‘TLS vulnerability club’ is: You don’t talk about TLS vulnerability club. Which takes all the fun out of it.
(Note that this is all for boring reasons — stuff like responsible disclosure, publication and fact checking. Nobody is planning a revolution.)
Anyway, it’s a huge relief that I’m finally free to tell you about a neat new TLS attack I learned about recently. The new result comes from Nadhem AlFardan and Kenny Paterson of Royal Holloway. Dubbed ‘Lucky 13’, it takes advantage of a very subtle bug in the way records are encrypted in the TLS protocol.
If you aren’t into long crypto posts, here’s the TL;DR:
There is a subtle timing bug in the way that TLS data decryption works when using the (standard) CBC mode ciphersuite. Given the right set of circumstances, an attacker can use this to completely decrypt sensitive information, such as passwords and cookies.
The attack is borderline practical if you’re using the Datagram version of TLS (DTLS). It’s more on the theoretical side if you’re using standard TLS. However, with some clever engineering, that could change in the future. You should probably patch!
For the details, read on. As always, we’ll do this in the ‘fun’ question/answer format I save for these kinds of posts.
What is TLS, what is CBC mode, and why should I care if it’s broken?
Some background: Transport Layer Security (née SSL) is the most important security protocol on the Internet. If you find yourself making a secure connection to another computer, there’s a very good chance you’ll be doing it with TLS. (Unless you’re using UDP-based protocol, in which case you might use TLS’s younger cousin Datagram TLS [DTLS]).
The problem with TLS is that it kind of stinks. Mostly this is due to bad decisions made back in the the mid-1990s when SSL was first designed. Have you seen the way people dressed back then? Protocol design was worse.
While TLS has gotten better since then, it still retains many of the worst ideas from the era. One example is the
CBC-mode ciphersuite, which I’ve
written about several times before on this blog. CBC-mode uses a block cipher (typically
AES) to encrypt data. It’s the most common ciphersuite in use today, probably because it’s the only
mandatory ciphersuite given in the spec.
What’s wrong with CBC mode?
The real problem with TLS is not the encryption itself, but rather the Message Authentication Code (MAC) that’s used to protect the integrity (authenticity) of each data record.
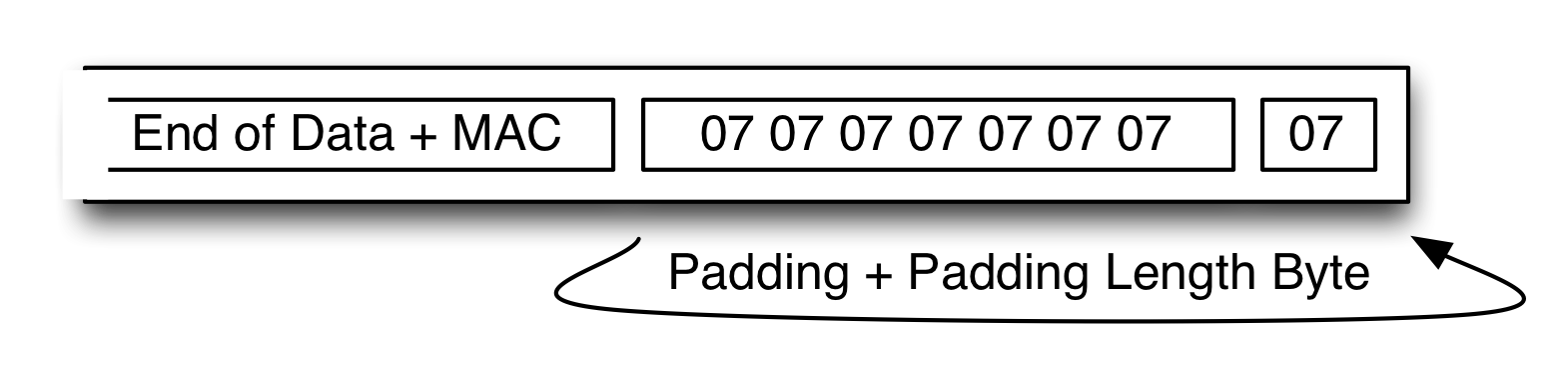
Our modern understanding is that you should always encrypt a message first, then apply the MAC to the resulting ciphertext. But TLS gets this backwards. Upon encrypting a record, the sender first applies a MAC to the plaintext, then adds up to 255 bytes of padding to get the message up to a multiple of the cipher (e.g., AES’s) block size. Only then does it CBC-encrypt the record.
 |
| Structure of a TLS record. The whole thing is encrypted with CBC mode. |
The critical point is that the padding is not protected by the MAC. This means an attacker can tamper with it (by flipping specific bits in the ciphertext), leading to a very nasty kind of problem known as a padding oracle attack.
In these attacks (example here), an attacker first captures an encrypted record sent by an honest party, modifies it, then re-transmits it to the server for decryption. If the attacker can learn whether her changes affected the padding — e.g., by receiving a padding error as opposed to a bad MAC error — she can use this information to adaptively decrypt the whole record. The structure of TLS’s encryption padding makes it friendly to these attacks.
 |
| Closeup of a padded TLS record. Each byte contains the padding length, followed by another (pointless, redundant) length byte. |
But padding oracle attacks are well known, and (D)TLS has countermeasures!
The TLS designers learned about padding oracles way back in 2002, and immediately took steps to rectify them. Unfortunately, instead of fixing the problem, they decided to apply band-aids. This is a time-honored tradition in TLS design.
The first band-aid was simple: eliminate any error messages that could indicate to the attacker whether the padding check (vs. the MAC check) is what caused a decryption failure.
This seemed to fix things for a while, until some researchers figured out that you could simply time the server to see how long decryption takes, and thereby learn if the padding check failed. This is because implementations of the time would first check the padding, then return immediately (without checking the MAC) if the padding was bad. That resulted in a noticeable timing differential the attacker could detect.
Thus a second band-aid was needed. The TLS designers decreed that decryption should always take
the same amount of time, regardless of how the padding check comes out. Let’s roll the TLS 1.2
spec:
[T]he best way to do this is to compute the MAC even if the padding is incorrect, and only then reject the packet. For instance, if the pad appears to be incorrect, the implementation might assume a zero-length pad and then compute the MAC.
Yuck. Does this even work?
Unfortunately, not quite. When the padding check fails, the decryptor doesn’t know how much padding to strip off. That means they don’t know how long the actual message is, and therefore how much data to MAC. The recommended countermeasure (above) is to assume no padding, then MAC the whole blob. As a result, the MAC computation can take a tiny bit longer when the padding is damaged.
The TLS designers realized this, but by this point they were exhausted and wanted to go think about something else. So they left us with the following note:
This leaves a small timing channel, since MAC performance depends to some extent on the size of the data fragment, but it is not believed to be large enough to be exploitable, due to the large block size of existing MACs and the small size of the timing signal.
And for the last several years — at least, as far as we know — they were basically correct.
How does this new paper change things?
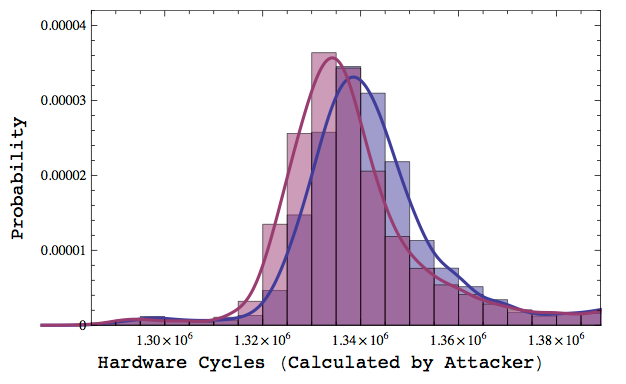
The new AlFardan and Paterson result shows that it is indeed possible to distinguish the tiny timing differential caused by invalid padding, at least from a relatively close distance — e.g., over a LAN. This is partly due to advances in computing hardware: most new computers now ship with an easily accessible CPU cycle counter. But it’s also thanks to some clever statistical techniques that use many samples to smooth out and overcome the jitter and noise of a network connection.
The upshot is that new technique can measure timing differentials of less than 1 microsecond over a LAN connection — for example, if the attacker is in the same data center as your servers. It does this by making several thousand decryption queries and processing the results. Under the right circumstances, this turns out to be enough to bring (D)TLS padding oracle attacks back to life.
How does the attack work?
For the details, you should obviously read the full paper or at least the nice FAQ that Royal Holloway has put out. Here I’ll try to give some intuition.
Before I can explain the attack, you need to know a little bit about how hash-based MACs work. TLS typically uses HMAC with either MD5, SHA1 or SHA256 as the hash function. While these are very different hash functions, the critical point is that each one processes messages in 64-byte blocks.
Consequently, hashing time is a function of the number of blocks in the message, not the number of bytes. Going from a 64-byte input to a 65-byte input means an entire extra block, and hence a (relatively) large jump in the amount of computation time (an extra iteration of the hash function’s compression function).
There are a few subtleties in here. The hash functions incorporate an 8-byte length field plus some special hash function padding, which actually means a one-block message can only contain about 55 bytes of real data (which also includes the 13-byte record header). The HMAC construction adds a (constant) amount of additional work, but we don’t need to think about that here.
So in summary: you can get 55 bytes of data into one block of the hash. Go a single byte beyond that, and the hash function will have to run a whole extra round, causing a tiny (500-1000 hardware cycle) delay.
 The attack here is to take a message that — including the TLS padding — would fall above that 55 byte boundary. However, the same message with padding properly removed would fall below it. When an attacker tampers with the message (damaging the padding), the decryption process will MAC the longer version of the message — resulting in a measurably higher computation time than when the padding checks out.
The attack here is to take a message that — including the TLS padding — would fall above that 55 byte boundary. However, the same message with padding properly removed would fall below it. When an attacker tampers with the message (damaging the padding), the decryption process will MAC the longer version of the message — resulting in a measurably higher computation time than when the padding checks out.
By repeating this process many, many thousand (or millions!) of times to eliminate noise and network jitter, it’s possible to get a clear measurement of whether the decryption succeeded or not. Once you get that, it’s just a matter of executing a standard padding oracle attack.
But there’s no way this will work on TLS! It’ll kill the session!
Please recall that I described this as a practical attack on Datagram TLS (DTLS) — and as a more theoretical one on TLS itself.* There’s a reason for this.
The reason is that TLS (and not DTLS) includes one more countermeasure I haven’t mentioned yet: anytime a record fails to decrypt (due to a bad MAC or padding error), the TLS server kills the session. DTLS does not do this, which makes this attack borderline practical. (Though it still takes millions of packet queries to execute.)
The standard TLS ‘session kill’ feature would appear to stop padding oracle attacks, since they require the attacker to make many, many decryption attempts. Killing the session limits the attacker to one decryption — and intuitively that would seem to be the end of it.
But actually, this turns out not to be true.
You see, one of the neat things about padding oracle attacks is that they can work across different sessions (keys), provided that that (a) your victim is willing to re-initiate the session after it drops, and (b) the secret plaintext appears in the same position in each stream. Fortunately the design of browsers and HTTPS lets us satisfy both of these requirements.
- To make a target browser initiate many connections, you can feed it some custom Javascript that causes it to repeatedly connect to an SSL server (as in the CRIME attack). Note that the Javascript doesn’t need to come from the target webserver — it can even served on an unrelated non-HTTPS page, possibly running in a different tab. So in short: this is pretty feasible.
- Morover, thanks to the design of the HTTP(S) protocol, each of these connections will include cookies at a known location in HTTP stream. While you may not be able to decrypt the rest of the stream, these cookie values are generally all you need to break into somebody’s account.
Thus the only practical limitation on such a cookie attack is the time it takes for the server to re-initiate all of these connections. TLS handshakes aren’t fast, and this attack can take tens of thousands (or millions!) of connections per byte. So in practice the TLS attack would probably take days. In other words: don’t panic.
On the other hand, don’t get complacent either. The authors propose some clever optimizations that could take the TLS attack into the realm of the feasible (for TLS) in the near future.
How is it being fixed?
With more band-aids of course!
But at least this time, they’re excellent band-aids. Adam Langley has written a 500-line OpenSSL patch (!) that modifies the CBC-mode decryption procedure to wipe out the timing differentials used by this attack. I would recommend that you think about updating at least your servers in the future (though we all know you won’t). Microsoft products should also see updates soon are allegedly not vulnerable to this attack, so won’t need updates.**
Still, this is sort of like fixing your fruitfly problem by spraying your kitchen with DDT. Why not just throw away the rotted fruit? In practice, that means moving towards modern AEAD ciphersuites like AES-GCM, which should generally end this madness. We hope.
Why not switch to RC4?
RC4 is not an option in DTLS. However, it will mitigate this issue for TLS, since the RC4 ciphersuite doesn’t use padding at all. In fact, this ancient ciphersuite has been (hilariously) enjoying a resurgence in recent years as the ‘solution’ to TLS attacks like BEAST. Some will see this attack as further justification for the move.
But please don’t do this. RC4 is old and creaky, and we really should be moving away from it too.
So what’s next for TLS?
I’d love to say more, but you see, the first rule of TLS vulnerability club is…
Notes:
* The attack on Datagram TLS is more subtle, and a lot more interesting. I haven’t covered it much in this post because TLS is much more widely used than DTLS. But briefly, it’s an extension of some previous techniques — by the same authors — that I covered in this blog last year. The gist is that an attacker can amplify the impact of the timing differential by ‘clogging’ the server with lots of unrelated traffic. That makes these tiny differentials much easier to detect.
** And if you believe that, I have a lovely old house in Baltimore to sell you…







_1870.jpg)




 about the title above, I ripped it off from an old Belle Waring
about the title above, I ripped it off from an old Belle Waring 



