This is part five of a series on the Random Oracle Model. See here for the previous posts:
Part 1: An introduction
Part 2: The ROM formalized, a scheme and a proof sketch
Part 3: How we abuse the ROM to make our security proofs work
Part 4: Some more examples of where the ROM is used
About eight years ago I set out to write a very informal piece on a specific cryptographic modeling technique called the “random oracle model”. This was way back in the good old days of 2011, which was a more innocent and gentle era of cryptography. Back then nobody foresaw that all of our standard cryptography would turn out to be riddled with bugs; you didn’t have to be reminded that “crypto means cryptography“. People even used Bitcoin to actually buy things.
That first random oracle post somehow sprouted three sequels, each more ridiculous than the last. I guess at some point I got embarrassed about the whole thing — it’s pretty cheesy, to be honest — so I kind of abandoned it unfinished. And that’s been a major source of regret for me, since I had always planned a fifth, and final post, to cap the whole messy thing off. This was going to be the best of the bunch: the one I wanted to write all along.
To give you some context, let me briefly remind you what the random oracle model is, and why you should care about it. (Though you’d do better just to read the series.)
The random oracle model is a bonkers way to model (reason about) hash functions, in which we assume that these are actually random functions and use this assumption to prove things about cryptographic protocols that are way more difficult to prove without such a model. Just about all the “provable” cryptography we use today depends on this model, which means that many of these proofs would be called into question if it was “false”.
And to tease the rest of this post, I’ll quote the final paragraphs of Part 4, which ends with this:
You see, we always knew that this ride wouldn’t last forever, we just thought we had more time. Unfortunately, the end is nigh. Just like the imaginary city that Leonardo de Caprio explored during the boring part of Inception, the random oracle model is collapsing under the weight of its own contradictions.
As promised, this post will be about that collapse, and what it means for cryptographers, security professionals, and the rest of us.
First, to make this post a bit more self-contained I’d like to recap a few of the basics that I covered earlier in the series. You can feel free to skip this part if you’ve just come from there.
In which we (very quickly) remind the reader what hash functions are, what random functions are, and what a random oracle is.
As discussed in the early sections of this series, hash functions (or hashing algorithms) are a standard primitive that’s used in many areas of computer science. They take in some input, typically a string of variable length, and repeatably output a short and fixed-length “digest”. We often denote these functions as follows:

Cryptographic hashing takes this basic template and tacks on some important security properties that we need for cryptographic applications. Most famously these provide well-known properties like collision resistance, which is needed for applications like digital signatures. But hash functions turn up all over cryptography, sometimes in unexpected places — ranging from encryption to zero-knowledge protocols — and sometimes these systems demand stronger properties. Those can sometimes be challenging to put into formal terms: for example, many protocols require a hash function to produce output that is extremely “random-looking”.*
In the earliest days of provably security, cryptographers realized that the ideal hash function would behave like a “random function”. This term refers to a function that is uniformly sampled from the set of all possible functions that have the appropriate input/output specification (domain and range). In a perfect world your protocol could, for example, randomly sample one of vast number of possible functions at setup, bake the identifier of that function into a public key or something, and then you’d be good to go.
Unfortunately it’s not possible to actually use random functions (of reasonably-sized domain and range) in real protocols. That’s because sampling and evaluating those functions is far too much work.
For example, the number of distinct functions that consume a piddly 256-bit input and produce a 256-bit digest is a mind-boggling (2^{256})^{2^{256}}. Simply “writing down” the identity of the function you chose would require memory that’s exponential in the function’s input length. Since we want our cryptographic algorithms to be efficient (meaning, slightly more formally, they run in polynomial time), using random functions is pretty much unworkable.
So we don’t use random functions to implement our hashing. Out in “the real world” we use weird functions developed by Belgians or the National Security Agency, things like like SHA256 and SHA3 and Blake2. These functions come with blazingly fast and tiny algorithms for computing them, most of which occupy few dozen lines of code or less. They certainly aren’t random, but as best we can tell, the output looks pretty jumbled up.
Still, protocol designers continue to long for the security that using truly random function could give their protocol. What if, they asked, we tried to split the difference. How about we model our hash functions using random functions — just for the sake of writing our security proofs — and then when we go to implement (or “instantiate”) our protocols, we’ll go use efficient hash functions like SHA3? Naturally these proofs wouldn’t exactly apply to the real protocol as instantiated, but they might still be pretty good.
A proof that uses this paradigm is called a proof in the random oracle model, or ROM. For the full mechanics of how the ROM works you’ll have to go back and read the series from the beginning. What you do need to know right now is that proofs in this model must somehow hack around the fact that evaluating a random function takes exponential time. The way the model handles this is simple: instead of giving the individual protocol participants a description of the hash function itself — it’s way too big for anyone to deal with — they give each party (including the adversary) access to a magical “oracle” that can evaluate the random function H efficiently, and hand them back a result.
This means that any time one of the parties wants to compute the function 

Since all parties in the system “talk” to the same oracle, they all get the same hash result when they ask it to hash a given message. This is a pretty good standin for what happens with a real hash function. The use of an outside oracle allows us to “bury” the costs of evaluating a random function, so that nobody else needs to spend exponential time evaluating one. Inside this artificial model, we get ideal hash functions with none of the pain.
This seems pretty ridiculous already…
It absolutely is!
However — I think there are several very important things you should know about the random oracle model before you write it off as obviously inane:
1. Of course everyone knows random oracle proofs aren’t “real”. Most conscientious protocol designers will admit that proving something secure in the random oracle model does not actually mean it’ll be secure “in the real world”. In other words, the fact that random oracle model proofs are kind of bogus is not some deep secret I’m letting you in on.
2. And anyway: ROM proofs are generally considered a useful heuristic. For those who aren’t familiar with the term, “heuristic” is a word that grownups use when they’re about to secure your life’s savings using cryptography they can’t prove anything about.
I’m joking! In fact, random oracle proofs are still quite valuable. This is mainly because they often help us detect bugs in our schemes. That is, while a random oracle proof doesn’t imply security in the real world, the inability to write one is usually a red flag for protocols. Moreover, the existence of a ROM proof is hopefully an indicator that the “guts” of the protocol are ok, and that any real-world issues that crop up will have something to do with the hash function.
3. ROM-validated schemes have a pretty decent track record in practice. If ROM proofs were kicking out absurdly broken schemes every other day, we would probably have abandoned this technique. Yet we use cryptography that’s proven (only) in the ROM just about ever day — and mostly it works fine.
This is not to say that no ROM-proven scheme has ever been broken, when instantiated with a specific hash function. But normally these breaks happen because the hash function itself is obvious broken (as happened when MD4 and MD5 both cracked up a while back.) Still, those flaws are generally fixed by simply switching to a better function. Moreover, the practical attacks are historically more likely to come from obvious flaws, like the discovery of hash collisions screwing up signature schemes, rather than from some exotic mathematical flaw. Which brings us to a final, critical note…
4. For years, many people believed that the ROM could actually be saved. This hope was driven by the fact that ROM schemes generally seemed to work pretty well when implemented with strong hash functions, and so perhaps all we needed to do was to find a hash function that was “good enough” to make ROM proofs meaningful. Some theoreticians hoped that fancy techniques like cryptographic obfuscation could somehow be used to make concrete hashing algorithms that behaved well enough to make (some) ROM proofs instantiable.**
So that’s kind of the state of the ROM, or at least — it was the state up until the late 1990s. We knew this model was artificial, and yet it stubbornly refused to explode or produce totally nonsense results.
And then, in 1998, everything went south.
CGH98: an “uninstantiable” scheme
For theoretical cryptographers, the real breaking point for the random oracle model came in the form of a 1998 STOC paper by Canetti, Goldreich and Halevi (henceforth CGH). I’m going to devote the rest of this (long!) post to explaining the gist of what they found.
What CGH proved was that, in fact, there exist cryptographic schemes that can be proven perfectly secure in the random oracle model, but that — terrifyingly — become catastrophically insecure the minute you instantiate the hash function with any concrete function.
This is a really scary result, at least from the point of view of the provable security community. It’s one thing to know in theory that your proofs might not be that strong. It’s a different thing entirely to know that in practice there are schemes that can walk right past your proofs like a Terminator infiltrating the Resistance, and then explode all over you in the most serious way.
Before we get to the details of CGH and its related results, a few caveats.
First, CGH is very much a theory result. The cryptographic “counterexample” schemes that trip this problem generally do not look like real cryptosystems that we would use in practice, although later authors have offered some more “realistic” variants. They are, in fact, designed to do very artificial things that no “real” scheme would ever do. This might lead readers to dismiss them on the grounds of artificiality.
The problem with this view is that looks aren’t a particularly scientific way to judge a scheme. Both “real looking” and “artificial” schemes are, if proven correct, valid cryptosystems. The point of these specific counterexamples is to do deliberately artificial things in order to highlight the problems with the ROM. But that does not mean that “realistic” looking schemes won’t do them.
A further advantage of these “artificial” schemes is that they make the basic ideas relatively easy to explain. As a further note on this point: rather than explaining CGH itseld, I’m going to use a formulation of the same basic result that was proposed by Maurer, Renner and Holenstein (MRH).
A signature scheme
The basic idea of CGH-style counterexamples is to construct a “contrived” scheme that’s secure in the ROM, but totally blows up when we “instantiate” the hash function using any concrete function, meaning a function that has a real description and can be efficiently evaluated by the participants in the protocol.
While the CGH techniques can apply with lots of different types of cryptosystem, in this explanation, we’re going to start our example using a relatively simple type of system: a digital signature scheme.
You may recall from earlier episodes of this series that a normal signature scheme consists of three algorithms: key generation, signing, and verification. The key generation algorithm outputs a public and secret key. Signing uses the secret key to sign a message, and outputs a signature. Verification takes the resulting signature, the public key and the message, and determines whether the signature is valid: it outputs “True” if the signature checks out, and “False” otherwise.
Traditionally, we demand that signature schemes be (at least) existentially unforgeable under chosen message attack, or UF-CMA. This means that that we consider an efficient (polynomial-time bounded) attacker who can ask for signatures on chosen messages, which are produced by a “signing oracle” that contains the secret signing key. Our expectation of a secure scheme is that, even given this access, no attacker will be able to come up with a signature on some new message that she didn’t ask the signing oracle to sign for her, except with negligible probability.****
Having explained these basics, let’s talk about what we’re going to do with it. This will involve several steps:
Step 1: Start with some existing, secure signature scheme. It doesn’t really matter what signature scheme we start with, as long as we can assume that it’s secure (under the UF-CMA definition described above.) This existing signature scheme will be used as a building block for the new scheme we want to build.*** We’ll call this scheme S.
Step 2: We’ll use the existing scheme S as a building block to build a “new” signature scheme, which we’ll call 
Step 3: Having described the working of
Step 4: Finally, we’ll demonstrate that
We’ll start by explaining how
Building a broken scheme
To build our contrived scheme, we begin with the existing secure (in the UF-CMA sense) signature scheme S. That scheme comprises the three algorithms mentioned above: key generation, signing and verification.
We need to build the equivalent three algorithms for our new scheme.
To make life easier, our new scheme will simply “borrow” two of the algorithms from S, making no further changes at all. These two algorithms will be the key generation and signature verification algorithms So two-thirds of our task of designing the new scheme is already done.
Each of the novel elements that shows up in
At the highest level, our new signing algorithm will have two subcases, chosen by a branch that depends on the input message to be signed. These two cases are given as follows:
The “normal” case: for most messages M, the signing algorithm will simply run the original signing algorithm from the original (secure) scheme S. This will output a perfectly nice signature that we can expect to work just fine.
The “evil” case: for a subset of (reasonably-sized) messages that have a different (and very highly specific) form, our signing algorithm will not output a signature. It will instead output the secret key for the entire signature scheme. This is an outcome that cryptographers will sometimes call “very, very bad.”
So far this description still hides all of the really important details, but at least it gives us an outline of where we’re trying to go.
Recall that under the UF-CMA definition I described above, our attacker is allowed to ask for signatures on arbitrary messages. When we consider using this definition with our modified signing algorithm, it’s easy to see that the presence of these two cases could make things exciting.
Specifically: if any attacker can construct a message that triggers the “evil” case, her request to sign a message will actually result in her obtaining the scheme’s secret key. From that point on she’ll be able to sign any message that she wants — something that obviously breaks the UF-CMA security of the scheme. If this is too theoretical for you: imagine requesting a signed certificate from LetsEncrypt, and instead obtaining a copy of LetsEncrypt’s signing keys. Now you too are a certificate authority. That’s the situation we’re describing.
The only way this scheme could ever be proven secure is if we could somehow rule out the “evil” case happening at all.
More concretely: we would have to show that no attacker can construct a message that triggers the “evil case” — or at least, that their probability of coming up with such a message is very, very low (negligible). If we could prove this, then our scheme
In short: what we’ve accomplished is to build a kind of “master password” backdoor into our new scheme
So what is the “backdoor”?
The message that breaks the scheme
More concretely, it will be some kind of program that can decoded within our new signing algorithm, and then evaluated (on some input) by an interpreter that we will also place within that algorithm.
If we’re being formal about this, we’d say the message contains an encoding of a program for a universal Turing machine (UTM), along with a unary-encoded integer t that represents the number of timesteps that the machine should be allowed to run for. However, it’s perfectly fine with me if you prefer to think of the message as containing a hunk of Javascript, an Ethereum VM blob combined with some maximum “gas” value to run on, a .tgz encoding of a Docker container, or any other executable format you fancy.
What really matters is the functioning of the program P.
A program P that successfully triggers the “evil case” is one that contains an efficient (e.g., polynomial-sized) implementation of a hash function. And not just any hash function. To actually trigger the backdoor, the algorithm P must a function that is identical to, or at least highly similar to, the random oracle function H.
There are several ways that the signing algorithm can verify this similarity. The MRH paper gives a very elegant one, which I’ll discuss further below. But for the purposes of this immediate intuition, let’s assume that our signing algorithm verifies this similarity probabilistically. Specifically: to check that P matches H, it won’t verify the correspondence at every possible input. It might, for example, simply verify that P(x) = H(x) for some large (but polynomial) number of random input values x.
So that’s the backdoor.
Let’s think briefly about what this means for security, both inside and outside of the random oracle mode.
Case 1: in the random oracle model
Recall that in the random oracle model, the “hash function” H is modeled as a random function. Nobody in the protocol actually has a copy of that function, they just have access to a third party (the “random oracle”) who can evaluate it for them.
If an attacker wishes to trigger the “evil case” in our signing scheme, they will somehow need to download a description of the random function from the oracle. then encode it into a program P, and send it to the signing oracle. This seems fundamentally hard.
To do this precisely — meaning that P would match H on every input — the attacker would need to query the random oracle on every possible input, and then design a program P that encodes all of these results. It suffices to say that this strategy would not be practical: it would require an exponential amount of time to do any of these, and the size of P would also be exponential in the input length of the function. So this attacker would seem virtually guaranteed to fail.
Of course the attacker could try to cheat: make a small function P that only matches H on a small of inputs, and hope that the signer doesn’t notice. However, even this seems pretty challenging to get away with. For example, to perform a probabilistic check, the signing algorithm can simply verify that P(x) = H(x) for a large number of random input points x. This approach will catch a cheating attacker with very high probability.
(We will end up using a slightly more elegant approach to checking the function and arguing this point further below.)
The above is hardly an exhaustive security analysis. But at a high level our argument should now be clear: in the random oracle model, the scheme
Case 2: In the “real world”
Out in the real world, we don’t use random oracles. When we want to implement a scheme that has a proof in the ROM, we must first “instantiate” the scheme by substituting in some real hash function in place of the random oracle H.
This instantiated hash function must, by definition, be efficient to evaluate and describe. This means implicitly that it possesses a polynomial-size description and can be evaluated in expected polynomial time. If we did not require this, our schemes would never work. Moreover, we must further assume that all parties, including the attacker, possess a description of the hash function. That’s a standard assumption in cryptography, and is merely a statement of Kerckhoff’s principle.
With these facts stipulated, the problem with our new signature scheme becomes obvious.
In this setting, the attacker actually does have access to a short, efficient program P that matches the hash function H. In practice, this function will probably be something like SHA2 or Blake2. But even in a weird case where it’s some crazy obfuscated function, the attacker is still expected to have a program that they can efficiently evaluate. Since the attacker possesses this program, they can easily encode it into a short enough message and send it to the signing oracle.
When the signing algorithm receives this program, it will perform some kind of test of this function P against its own implementation of H, and — when it inevitably finds a match between the two functions with high probability — it will output the scheme’s secret key.
Hence, out in the real world our scheme
A few boring technical details (that you can feel free to skip)
If you’re comfortable with the imprecise technical intuition I’ve given above, feel free to skip this section. You can jump on to the next part, which tries to grapple with tough philosophical questions like “what does this mean for the random oracle model” and “I think this is all nonsense” and “why do we drive on a parkway, and park in a driveway?”
All I’m going to do here is clean up a few technical details.
One of the biggest pieces that’s missing from the intuition above is a specification of how the signing algorithm verifies that the program P it receives from the attacker actually “matches” the random oracle function H. The obvious way is to simply evaluate P(x) = H(x) on every possible input x, and output the scheme’s secret key if every comparison succeeds. But doing this exhaustively requires exponential time.
The MRH paper proposes a very neat alternative way to tackle this. They propose to test the functions on a few input values, and not even random ones. More concretely, they propose checking that P(x) = H(x) for values of 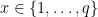

What this means is that to trigger the backdoor, the attacker must come up with a program P that can be described in some number of bits (let’s call it n) , and yet will be able to correctly match the outputs of H at e.g., q=2n+128 different input points. If we conservatively assume that H produces (at least) a 1-bit digest, that means we’re effectively encoding at least 2n+128 bits of data into a string of length n.
If the function H is a real hash function like SHA256, then it should be reasonably easy for the attacker to find some n-bit program that matches H at, say, q=2n+128 different points. For example, here’s a Javascript implementation of SHA256 that fits into fewer than 8,192 bits. If we embed a Javascript interpreter into our signing algorithm, then it simply needs to evaluate this given program on q = 2(8,192)+128 = 16,512 different input points, compare each result to its own copy of SHA256, and if they all match, output the secret key.
However, if H is a random oracle, this is vastly harder for the attacker to exploit. The result of evaluating a random oracle at q distinct points should be a random string of (at minimum) q bits in length. Yet in order for the backdoor to be triggered, we require the encoding of program P to be less than half that size. You can therefore think of the process by which the attacker compresses a random string into that program P to be a very effective compression algorithm, one takes in a random string, and compresses it into a string of less than half the size.
Despite what you may have seen on Silicon Valley (NSFW), compression algorithms do not succeed in compressing random strings that much with high probability. Indeed, for a given string of bits, this is so unlikely to occur that the attacker succeeds with at probability that is at most negligible in the scheme’s security parameter k. This effectively neutralizes the backdoor when H is a random oracle.
Phew.
So what does this all mean?
Judging by actions, and not words, the cryptographers of the world have been largely split on this question.
Theoretical cryptographers, for their part, gently chuckled at the silly practitioners who had been hoping to use random functions as hash functions. Brushing pipe ash from their lapels, they returned to more important tasks, like finding ways to kill off cryptographic obfuscation.
Applied academic cryptographers greeted the new results with joy — and promptly authored 10,000 new papers, each of which found some new way to remove random oracles from an existing construction — while at the same time making said construction vastly slower, more complicated, and/or based on entirely novel made-up and flimsy number-theoretic assumptions. (Speaking from personal experience, this was a wonderful time.)
Practitioners went right on trusting the random oracle model. Because really, why not?
And if I’m being honest, it’s a bit hard to argue with the practitioners on this one.
That’s because a very reasonable perspective to take is that these “counterexample” schemes are ridiculous and artificial. Ok, I’m just being nice. They’re total BS, to be honest. Nobody would ever design a scheme that looks so ridiculous.
Specifically, you need a scheme that explicitly parses an input as a program, runs that program, and then checks to see whether the program’s output matches a different hash function. What real-world protocol would do something so stupid? Can’t we still trust the random oracle model for schemes that aren’t stupid like that?
Well, maybe and maybe not.
One simple response to this argument is that there are examples of schemes that are significantly less artificial, and yet still have random oracle problems. But even if one still views those results as artificial — the fact remains that while we only know of random oracle counterexamples that seem artificial, there’s no principled way for us to prove that the badness will only affect “artificial-looking” protocols. In fact, the concept of “artificial-looking” is largely a human judgement, not something one can realiably think about mathematically.
In fact, at any given moment someone could accidentally (or on purpose) propose a perfectly “normal looking” scheme that passes muster in the random oracle model, and then blows to pieces when it gets actually deployed with a standard hash function. By that point, the scheme may be powering our certificate authority infrastructure, or Bitcoin, or our nuclear weapons systems (if one wants to be dramatic.)
The probability of this happening accidentally seems low, but it gets higher as deployed cryptographic schemes get more complex. For example, people at Google are now starting to deploy complex multi-party computation and others are launching zero-knowledge protocols that are actually capable of running (or proving things about the execution of) arbitrary programs in a cryptographic way. We can’t absolutely rule out the possibility that the CGH and MRH-type counterexamples could actually be made to happen in these weird settings, if someone is a just a little bit careless.
It’s ultimately a weird and frustrating situation, and frankly, I expect it all to end in tears.
Photo by Flickr user joyosity.
Notes:
* Intuitively, this definition sounds a lot like “pseudorandomness”. Pseudorandom functions are required to be indistinguishable from random functions only in a setting where the attacker does not know some “secret key” used for the function. Whereas hash functions are often used in protocols where there is no opporunity to use a secret key, such as in public key encryption protocols.
** One particular hope was that we could find a way to obfuscate pseudorandom function families (PRFs). The idea would be to wrap up a keyed PRF that could be evaluated by anyone, even if they didn’t actually know the key. The result would be indistinguishable from a random function, without actually being one.
*** It might seem like “assume the existence of a secure signature scheme” drags in an extra assumption. However: if we’re going to make statements in the random oracle model it turns out there’s no additional assumption. This is because in the ROM we have access to “secure” (at least collision-resistant, [second] pre-image resistant) hash function, which means that we can build hash-based signatures. So the existence of signature schemes comes “free” with the random oracle model.
**** The “except with negligible probability [in the adjustable security parameter of the scheme]” caveat is important for two reasons. First, a dedicated attacker can always try to forge a signature just by brute-force guessing values one at a time until she gets one that satisfies the verification algorithm. If the attacker can run for an unbounded number of time steps, she’ll always win this game eventually. This is why modern complexity-theoretic cryptography assumes that our attackers must run in some reasonable amount of time — typically a number of time steps that is polynomial in the scheme’s security parameter. However, even a polynomial-time bounded adversary can still try to brute force the signature. Her probability of succeeding may be relatively small, but it’s non-zero: for example, she might succeed after the first guess. So in practice what we ask for in security definitions like UF-CMA is not “no attacker can ever forge a signature”, but rather “all attackers succeed with at most negligible probability [in the security parameter of the scheme]”, where negligible has a very specific meaning.
