A few weeks ago, U.S. Attorney General William Barr joined his counterparts from the U.K. and Australia to publish an open letter addressed to Facebook. The Barr letter represents the latest salvo in an ongoing debate between law enforcement and the tech industry over the deployment of end-to-end (E2E) encryption systems — a debate that will soon be moving into Congress.
The latest round is a response to Facebook’s recent announcement that it plans to extend end-to-end encryption to more of its services. It should hardly come as a surprise that law enforcement agencies are unhappy with these plans. In fact, governments around the world have been displeased by the increasing deployment of end-to-end encryption systems, largely because they fear losing access to the trove of surveillance data that online services and smartphone usage has lately provided them. The FBI even has a website devoted to the topic.
If there’s any surprise in the Barr letter, it’s not the government’s opposition to encryption. Rather, it’s the new reasoning that Barr provides to justify these concern. In past episodes, law enforcement has called for the deployment of “exceptional access” mechanisms that would allow law enforcement access to plaintext data. As that term implies, such systems are designed to treat data access as the exception rather than the rule. They would need to be used only in rare circumstances, such as when a judge issued a warrant.
The Barr letter appears to call for something much more agressive.
Rather than focusing on the need for exceptional access to plaintext, Barr focuses instead on the need for routine, automated scanning systems that can detect child sexual abuse imagery (or CSAI). From the letter:
More than 99% of the content Facebook takes action against – both for child sexual exploitation and terrorism – is identified by your safety systems, rather than by reports from users. …
We therefore call on Facebook and other companies to take the following steps:
Embed the safety of the public in system designs, thereby enabling you to continue to act against illegal content effectively with no reduction to safety, and facilitating the prosecution of offenders and safeguarding of victims;
To many people, Barr’s request might seem reasonable. After all, nobody wants to see this type of media flowing around the world’s communications systems. The ability to surgically detect it seems like it could do some real good. And Barr is correct that true that end-to-end encrypted messaging systems will make that sort of scanning much, much difficult.
What’s worrying in Barr’s letter is the claim we can somehow square this circle: that we can somehow preserve the confidentiality of end-to-end encrypted messaging services, while still allowing for the (highly non-exceptional) automated scanning for CSAI. Unfortunately, this turns out to be a very difficult problem — given the current state of our technology.
In the remainder of this post, I’m going to talk specifically about that problem. Since this might be a long discussion, I’ll briefly list the questions I plan to address:
- How do automated CSAI scanning techniques work?
- Is there a way to implement these techniques while preserving the security of end-to-end encryption?
- Could these image scanning systems be subject to abuse?
I want to stress that this is a (high-level) technical post, and as a result I’m going to go out of my way not to discuss the ethical questions around this technology, i.e., whether or not I think any sort of routine image scanning is a good idea. I’m sure that readers will have their own opinions. Please don’t take my silence as an endorsement.
Let’s start with the basics.
How do automated CSAI scanning techniques work?
Facebook, Google, Dropbox and Microsoft, among others, currently perform various forms of automated scanning on images (and sometimes video) that are uploaded to their servers. The goal of these scans is to identify content that contains child sexual abuse imagery (resp. material), which is called CSAI (or CSAM). The actual techniques used vary quite a bit.
The most famous scanning technology is based on PhotoDNA, an algorithm that was developed by Microsoft Research and Dr. Hany Farid. The full details of PhotoDNA aren’t public — this point is significant — but at a high level, PhotoDNA is just a specialized “hashing” algorithm. It derives a short fingerprint that is designed to closely summarize a photograph. Unlike cryptographic hashing, which is sensitive to even the tiniest changes in a file, PhotoDNA fingerprints are designed to be robust even against complex image transformations like re-encoding or resizing.
The key benefit of PhotoDNA is that it gives providers a way to quickly scan incoming photos, without the need to actually deal with a library of known CSAI themselves. When a new customer image arrives, the provider hashes the file using PhotoDNA, and then compares the resulting fingerprint against a list of known CSAI hashes that are curated by the National Center for Missing and Exploited Children (NCMEC). If a match is found, the photo gets reported to a human, and ultimately to NCMEC or law enforcement.

The obvious limitation of the PhotoDNA approach is that it can only detect CSAI images that are already in the NCMEC database. This means it only finds existing CSAI, not anything new. (And yes, even with that restriction it does find a lot of it.)
To address that problem, Google recently pioneered a new approach based on machine learning techniques. Google’s system is based on a deep neural network, which is trained on a corpus of known CSAI examples. Once trained — a process that is presumably ongoing and continuous — the network can be applied against fresh images in to flag media that has similar characteristics. As with the PhotoDNA approach, images that score highly can be marked for further human review. Google even provides an API that authorized third parties can use for this purpose.
Both of these approaches are very different. But they have an obvious commonality: they only work if providers to have access to the plaintext of the images for scanning, typically at the platform’s servers. End-to-end encrypted (E2E) messaging throws a monkey wrench into these systems. If the provider can’t read the image file, then none of these systems will work.
For platforms that don’t support E2E — such as (the default mode) of Facebook Messenger, Dropbox or Instagram — this isn’t an issue. But popular encrypted messaging systems like Apple’s iMessage and WhatsApp are already “dark” to those server-side scanning technologies, and presumably future encrypted systems will be too.
Is there some way to support image scanning while preserving the ability to perform E2E encryption?
Some experts have proposed a solution to this problem: rather than scanning images on the server side, they suggest that providers can instead push the image scanning out to the client devices (i.e., your phone), which already has the cleartext data. The client device can then perform the scan, and report only images that get flagged as CSAI. This approach removes the need for servers to see most of your data, at the cost of enlisting every client device into a distributed surveillance network.
The idea of conducting image recognition locally is not without precedent. Some device manufacturers (notably Apple) have already moved their neural-network-based image classification onto the device itself, specifically to eliminate the need to transmit your photos out to a cloud provider.

Unfortunately, while the concept may be easy to explain, actually realizing it for CSAI-detection immediately runs into a very big technical challenge. This is the result of a particular requirement that seems to be present across all existing CSAI scanners. Namely: the algorithms are all secret.
While I’ve done my best to describe how PhotoDNA and Google’s techniques work, you’ll note that my descriptions were vague. This wasn’t due to some lack of curiosity on my part. It reflects the fact that all the details of these algorithms — as well as the associated data they use, such as the database of image hashes curated by NCMEC and any trained neural network weights — are kept under strict control by the organizations that manage them. Even the final PhotoDNA algorithm, which is ostensibly the output of an industry-academic collaboration, is not public.
While the organizations don’t explicitly state this, the reason for this secrecy seems to be a simple one: these technologies are probably very fragile.
Presumably, the concern is that criminals who gain free access to these algorithms and databases might be able to subtly modify their CSAI content so that it looks the same to humans but no longer triggers detection algorithms. Alternatively, some criminals might just use this access to avoid transmitting flagged content altogether.
This need for secrecy makes client-side scanning fundamentally much more difficult. While it might be possible to cram Google’s neural network onto a user’s phone, it’s hugely more difficult to do so on a billion different phones, while also ensuring that nobody obtains a copy of it.
Can fancy cryptography help here?
The good news is that cryptographers have spent a lot of time thinking about this exact sort of problem: namely, finding ways to allow mutually-distrustful parties to jointly compute over data that each, individually, wants to keep secret. The name for this class of technologies is secure multi-party computation, or MPC for short.
CSAI scanning is exactly the sort of application you might look to MPC to implement. In this case, both client and service provider have a secret. The client has an image it wants to keep confidential, and the server has some private algorithms or neural network weights.* All the parties want in the end is a “True/False” output from the detection algorithm. If the scanner reports “False”, then the image can remain encrypted and hidden from the service provider.
So far this seems simple. The devil is in the (performance) details.
While general MPC (and two-party, or 2PC) techniques have long existed, some recent papers have investigated the costs of implementing secure image classification via neural networks using these techniques. (This approach is much more reminiscent of the Google technique, rather than PhotoDNA, which would have its own complexities. See notes below.***)
The papers in question (e.g., CryptoNets, MiniONN, Gazelle, Chameleon and XONN) employ sophisticated cryptographic tools such as leveled fully-homomorphic encryption, partially-homomorphic encryption, and circuit garbling, in many cases making specific alterations to the neural network structure in order to allow for efficient evaluation. The tools are also interactive: a client and server must exchange data in order to perform the classification task, and the result appears only after this exchange of data.
All of this work is remarkable, and really deserves a much more in-depth discussion. Unfortunately I’m only here to answer a basic question — are these techniques practical yet? To do that I’m going to do a serious disservice to all this excellent research. Indeed, the current state of the art can largely be summarized by following table from one of the most recent papers:
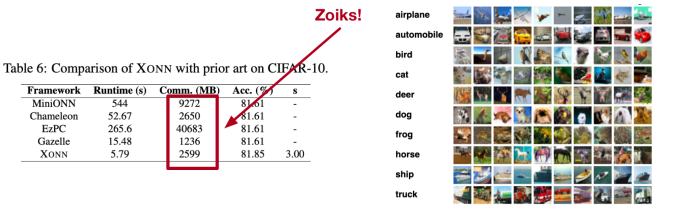
What this table shows is the bandwidth and computational cost of securely computing a single image classification using several of the tools I mentioned above. A key thing to note here is that the images to be classified are fairly simple — each is a 32×32-bit pixel color thumbnail. And while I’m no judge of such things, the neural networks architectures used for the classification also seem relatively simple. (At very least, it’s hard to imagine that a CSAI detection neural network is going to be that much less complex.)
Despite the relatively small size of these problem instances, the overhead of using MPC turns out to be pretty spectacular. Each classification requires several seconds to minutes of actual computation time on a reasonably powerful machine — not a trivial cost, when you consider how many images most providers transmit every second. But the computational costs pale next to the bandwidth cost of each classification. Even the most efficient platform requires the two parties to exchange more than 1.2 gigabytes of data.**
Hopefully you’ve paid for a good data plan.
Now this is just one data point. And the purpose here is certainly not to poo-poo the idea that MPC/2PC could someday be practical for image classification at scale. My point here is simply that, at present, doing this sort of classification efficiently (and privately) remains firmly in the domain of “hard research problems to be solved”, and will probably continue to be there for at least several more years. Nobody should bank on using this technology anytime soon. So client-side classification seems to be off the table for the near future.
But let’s imagine it does become efficient. There’s one more question we need to consider.
Are (private) scanning systems subject to abuse?
As I noted above, I’ve made an effort here to dodge the ethical and policy questions that surround client-side CSAI scanning technologies. I’ve done this not because I back the idea, but because these are complicated questions — and I don’t really feel qualified to answer them.
Still, I can’t help but be concerned about two things. First, that today’s CSAI scanning infrastructure represents perhaps the most powerful and ubiquitous surveillance technology ever to be deployed by a democratic society. And secondly, that the providers who implement this technology are so dependent on secrecy.
This raises the following question. Even if we accept that everyone involved today has only the best intentions, how can we possibly make sure that everyone stays honest?
Unfortunately, simple multi-party computation techniques, no matter how sophisticated, don’t really answer this question. If you don’t trust the provider, and the provider chooses the (hidden) algorithm, then all the cryptography in the world won’t save you.
Abuse of a CSAI scanning system might range from outsider attacks by parties who generate CSAI that simply collides with non-CSAI content; to insider attacks that alter the database to surveil specific content. These concerns reach fever pitch if you imaginea corrupt government or agency forcing providers to alter their algorithms to abuse this capability. While that last possibility seems like a long shot in this country today, it’s not out of bounds for the whole world. And systems designed for surveillance should contemplate their own misuse.
Which means that, ultimately, these systems will need some mechanism to ensure that service providers are being honest. Right now I don’t quite know how to do this. But someone will have to figure it out, long before these systems can be put into practice.
Notes:
* Most descriptions of MPC assume that the function (algorithm) to be computed is known to both parties, and only the inputs (data) is secret. Of course, this can be generalized to secret algorithms simply by specifying the algorithm as a piece of data, and computing an algorithm that interprets and executes that algorithm. In practice, this type of “general computation” is likely to be pretty costly, however, and so there would be a huge benefit to avoiding it.
** It’s possible that this cost could be somewhat amortized across many images, though it’s not immediately obvious to me that this works for all of the techniques.
*** Photo hashing might or might not feasible to implement using MPC/2PC. The relatively limited information about PhotoDNA describes is as including a number of extremely complex image manipulation phases, followed by a calculation that occurs on subregions of the image. Some sub-portions of this operation might be easy to move into an MPC system, while others could be left “in the clear” for the client to compute on its own. Unfortunately, it’s difficult to know which portions of the algorithm the designers would be willing to reveal, which is why I can’t really speculate on the complexity of such a system.

“insider attacks that alter the database to surveil specific content. These concerns reach fever pitch if you imagine a corrupt government or agency forcing providers to alter their algorithms to abuse this capability. While that last possibility seems like a long shot in this country today, it’s not out of bounds for the whole world.”
It’s worth noting that Antivirus software is a client-side scanning system that uses an opaque database of “hashes” — and Kaspersky AV is credibly accused of using exactly that feature to spy on targets and steal data for Russian intelligence services.
Loved the article! Another point to add is that most of the works on secure image classification only deal with optimizing for a semi-honest threat model. I think out of the papers you list only XONN discusses how to extend to malicious security but it’s rather expensive.
Also, here’s some additional recent work on secure image classification https://www.usenix.org/system/files/sec20spring_mishra_prepub.pdf
Thank you for the article!
Concerning this question “how can we possibly make sure that everyone stays honest?”, can we use some cut-and-choose-like protocols?
I mean, to force the providers to stay honest.
To prevent dishonest clients who generate adversarial contents, maybe that’s related to the robustness of the algorithm?