Yesterday Anthropic published two new cryptanalysisresults, both outputs of Claude Mythos, their (still) unreleased advanced model. The first of these results attacks a signature scheme called HAWK, while the second is an improved attack against reduced-round AES. Anthropic also released a blog post describing the research process that produced these results. A few people online have asked me what this all means. While I’m not sure I have all the answers, I figured it wouldn’t hurt to write a bit about my current understanding. These are only my thoughts and other folks will probably differ (including domain experts in the two areas at issue) so take them for what they are.
The two new results cover two very different areas, and are overall just very different in quality. Before we get to broad statements about the world, and whether you should sell all your cryptocurrency, let’s take a minute to talk about the substance.
Hawk. The first is a new key recovery algorithm against the non-standard signature scheme HAWK. HAWK is a proposed post-quantum-safe signature scheme that’s based on the module Lattice Isomorphism Problem (module-LIP). For a brief Claude-written summary of the result itself, see here. There are five things you need to know about this result:
HAWK is not a deployed or standards-adopted algorithm, it’s a proposed algorithm. It is related to the Falcon signature scheme, which is being standardized, but the attack does not transfer to that setting (which is based on a different hard problem.)
However, HAWK was somewhat far along in the process of being evaluated for a future standard.
The attack does not break “real deployed” HAWK in the sci-fi sense. The resulting attack is still exponential time, but roughly halves the number of “bits” of security in the algorithm. That means it could theoretically be fixed by doubling key sizes. The downside is that this makes the scheme less efficient, and, since HAWK is entirely motivated by being more efficient than alternatives, that makes the existence of the scheme much harder to justify.
The attack produced real code that runs in a few hours of wall-clock time against a weakened “challenge instance” of HAWK that the authors provided for this purpose. While this instance doesn’t use the parameters that were proposed for real deployment, it does demonstrate the cryptanalytic weakness well enough.
What’s particularly concerning (and so especially ripe for AI) is that the attack does not invent fundamentally new mathematics. It simply extends a bunch of tools that were lying around and well-known, and gets a good result.
This last part is important. I asked Claude for its thoughts, and it doesn’t mince words: “what makes this genuinely interesting — and, frankly, a little embarrassing for the field — is that none of the ingredients are exotic.” The TL;DR is that someone just did a much more thorough job applying all of our known tools. This is the sort of things that attack AIs excel at.
AES. The second result is a new attack on reduced-round AES. This result initially sounds more exciting, since most people hear “attack on AES” and panic. However, this is also the result that’s much, much less interesting.
Most folks reading this blog will know that AES is a standard block cipher that’s used just about everywhere. It’s been a standard since 2001, and the deployed version has so far withstood everything significant that’s been thrown at it: that includes a substantial amount of non-public testing performed by the NSA. Since attacking full ciphers is very difficult, it’s standard for cryptanalysts to do their work against weakened, or “reduced-round” versions of a cipher. The full AES cipher runs for either 10, 12 or 14 rounds depending on key size. The new Anthropic result attacks a weaker 7-round variant of the cipher.
Critically, attacks against 7-round AES are not new: there have been several of these. In fact, this new Anthropic result is a modest constant-factor improvement on previous work from backin 2013. To give you a sense of how far these attacks are from really “breaking” AES, I’d note the headline results: the new attack requires 289 cipher operations and, even worse, this work is only possible after you’ve somehow convinced a real encryptor to produce 2105 encryptions of chosen plaintexts under their secret key! Neither of these things is remotely practical in the real world. And while the new result modestly speeds up this attack over the previous result, it’s not even clear how “real” the speedup in this result is: since the actual attack requires 289 operations and can’t really be “run”, what we have is an on-paper analysis that may or may not yield an actual runtime improvement if all details are actually worked out.
This does not make the result bad! In fact it’s still interesting from a techniques point of view. But it is very much a small increment in our knowledge, not a practical new attack like the HAWK work. So TL;DR: no wildly new mathematical results here. But still, real cryptanalytic progress of the sort that make scientists excited. And certainly the HAWK result is very meaningful, since that scheme had a real chance at standardization and is now (very likely) not going to be.
Now let’s talk about how we got here, and what it all means.
How did Anthropic get these results?
The Anthropic post is detailed about what they did, and honestly, it’s kind of hilarious. No, the team at Anthropic was not a large set of domain experts that carefully tuned their AI to find novel results. They appear to have just told it to get some results and then strapped its nose to the grindstone until it found some. If you doubt me, here are some examples of the prompts they used (cited from their post):
So yes, the AIs are getting pretty good. In short: they are now capable of understanding existing cryptanalysis results, synthesizing them into real new attacks, and even extending them. They can apparently do this without detailed human intervention. This isn’t yet super-intelligent cryptanalysis. but it’s pretty damn impressive.
Verifiability is now the bottleneck
As a researcher I’ve also been spending a lot of time with models, talking through various ideas. I don’t think I will surprise anyone when I say that they’re obviously getting better, even over the course of the past few months. While I don’t have Mythos and $100k to spend, I have been able to query at least one new advanced unreleased model, and I also have received some surprising new “results” to questions that I’ve been interested in for a few years.
Which brings me to the real problem: just because a model spits out an apparent new result, this does not mean the result is real. Even if models are good at producing real results, they’re much better at producing results that look real but are misleading. This can be enormously frustrating, and often means that human attention is more necessary than ever.
There are exceptions to this rule: for “full” attacks like HAWK, where the attack runs in a few hours (against a weaker version of the scheme), verification is extremely easy. You can just send over the code and let anyone check that it recovers keys and signs real chosen messages. For more subtle speedup attacks like the AES result, checking validity is not so easy. Here the approach is more specific: formally-verifiable Lean proofs can help here, but (even where these proofs are easy to make), such proofs are still highly sensitive to how you’ve formulated the theorem statement, and that often requires human experts to check.
You’ll probably notice that many of the exciting recentmathematical results have had this flavor: they either include a machine-checkable proof of a well-understood theorem, or (like the Jacobian conjecture) they involve finding a simple counterexample you can compute on. Alternatively, a bunch of experts spent a lot of time reviewing the result and were eventually convinced by it. This need for some humans to check the work is going to slow down our progress. For non-devastating examples of cryptanalysis, this is probably where we’re going to be for a while.
What are the implications for the real world?
The answer to this question really depends on whether you’re talking about the consumers of cryptography, scientists, or humanity at large. Let’s take these one at a time.
For users of cryptography: there are two pieces of good news and some mixed news. The first is that our symmetric ciphers are very messy and robust. Imagine a farmer who drags a tractor out into a patch of quicksand, and then buries it under cement. That’s what symmetric cipher design is like; it’s deliberately designed to come up with structures that are quick and easy to apply, but very messy and hard to untangle. The addition of many new raw intelligence-hours probably aren’t going to magically improve this. AIs may be able to eventually make real progress against these problems using entirely new techniques, but so far they’re not demonstrating the truly groundbreaking intuition that would be required to do so. And even if they do: there’s a good reason to hope that they’ll be able to improve the ciphers themselves to make them much harder to break.
Public-key cryptography is messier. Public-key crypto requires a mathematical object that admits fast calculations in one direction, but not the other, and yet has a convenient “trapdoor” that lets one party reverse the process. We humans have come up with only a handful of very conveniently-structured mathematical objects to enable this: they involve conjectured “hard problems” like the (EC)DLP problem, RSA, lattice problems, and various problems from the domain of coding theory. While we’ve given these our all, there simply have not been enough human beings dedicated to analyzing these problems (even the older ones like RSA!), such that we can be absolutely certain there are no more good attacks out there. This is particularly true for the novel areas like code-based crypto and even lattice-based cryptography.
That means there’s a lot of fertile ground for AIs to make real progress.
With that said, I said there was good news, and I meant it. Right now we’re in the midst of a historic transition from traditional public-key algorithms based on EC-based cryptography and RSA, moving over to new post-quantum algorithms based on novel problems. This is why there are so many standards like HAWK being considered. If there was ever a perfect time for a massive new public cryptanalysis capability to come on line, we’re in it. So unless AIs succeed in undermining all of our hard problems altogether (or we live in Impagliazzo’s Minicrypt) then this could not be a better time for AI to get good at cryptanalysis. In the best case, the result is that we gain real confidence in the problems we’ve identified, and the cryptanalysis literature gets a lot more robust. Hopefully.
For scientists: this is also a wonderful time. You now have a plastic pal who’s fun to be with, and you can talk over your hardest problems. At the same time it’s not yet smart enough that it can solve all of them without your assistance. And even better, the pace of new findings is speeding way up. This is mostly good! If you’re energetic. I still have many questions, like: “who should get credit for these new results” and “who will review all of these new results” but so far I’m not panicked. The world is getting modestly better. For now.
For the world: I don’t know. If you’re under the impression that these models are “glorified autocomplete” or that progress is slowing down, I need to urge you: stop thinking that. The models are very intelligent and capable, they are getting better at a fast clip. I can cite measurable and impressive progress over just the past five months on specific types of problem I’ve asked them to look at. If there’s a ceiling out there, I don’t yet see evidence of it. The people who think models are dumb are mostly using Google’s free AI search results, and not interacting with the high-end stuff (which only costs $20, so it’s not out of reach.) And they’re mostly not working in new areas.
On the other hand: if you think that models are super-intelligent or that AGI is already here, you should also stop thinking that. Working with these tools is like swimming in a pond where the ground drops off sharply. One minute you’re wading comfortably and there’s support under your feet. Then suddenly you cross a specific line, and you’re back to swimming on your own. This analogy is my best way to explain what it feels like when the model goes from helpful to clueless. Right now it’s easy for a human being to find that line if you’re doing advanced research, so you know where the intelligence drops off. But the line is moving. You can feel it slowly drifting outwards under your feet.
Whether this is good or bad depends whether you prefer that human beings should wade or swim, and also, whether you should be comfortable swimming in a pond where the ground itself is moving.
The only good news I can share with you is that we’re all in that same pond, scientists, lawyers, salespeople, even plumbers. Whatever happens next, it’s probably going to happen to us all. Let’s hope it’s a good thing.
Yesterday Apple announced a big step towards deploying real AI in their Siri ecosystem. In most ways this is good and inevitable: Siri is one of the world’s most widely-used voice agents, and it would be good if it didn’t suck. The idea that Apple would boost its capabilities with frontier models wasn’t so much a matter of if, but a question of when and who.
The who turns out to be Google: Apple looks like it will use some combination of Google Gemini models, combined with Google’s Confidential Inference and Apple’s own Private Cloud Compute for private hosting. These systems will process both your queries and evaluate private data from your devices. Apple’s marketing pitches the advantages as follows:
First, since your phone already has context about you — meaning, your private information, schedules, email, text messages — an AI-enabled Siri can potentially offer more useful answers to your practical requests than external LLMs. Want to schedule a reservation for next week’s birthday party? In theory, a future Siri-AI might already know who’s coming, and what kind of cake they like.
Of course, what Apple calls “context” is also the raw data of your life. This is deeply private data from all of your apps, and that data can’t just be shipped to random adtech companies (or Sam Altman) for processing. Your context needs to be protected, and Apple bills itself as a privacy company.
There’s some tension between these goals. Apple has addressed this by marketing a service it calls Private Cloud Compute, or PCC. PCC was introduced in 2024 as a private model inference system that ran entirely on Apple Silicon, using a set of “trusted” hardware security modules running in Apple’s datacenters. The goal of this system is to ensure that your data never leaves Apple’s hardware: it’s encrypted from your phone to a dedicated server, and then it disappears once a response reaches your phone. The stateless design of PCC ensures (in theory) that your data doesn’t linger, and the design of the hardware prevents even Apple from seeing the inputs.
Apple has since “expanded” PCC to encompass Google’s hardware as well. I will confess that I find the details of the new “expanded” PCC just a bit vague. It sounds a lot like Apple is primarily going to rely on Google’s existing confidential compute (running in Google datacenters) to process this data, but they’re bolting on a new layer of technical security to control which models are actually running. In any case: security experts can argue about whether this is good enough to keep Cozy Bear away from your data. What I will grant is that it’s probably good enough to keep Google and Apple from accessing your stuff, which is what most people are worried about in the first place.
So why am I so nervous?
A brief scenario involving private agents
To illustrate how agents might work, it’s helpful to consider an example use case. Let’s imagine that you’re planning a business dinner for six people. This involves several subtasks:
You need to juggle the participants’ schedules, know when they’re in town and available to meet.
You need to choose the appropriate restaurant based on menu and location. This might depend on what you know about the participants’ preferences: Mike is wildly allergic to szechuan peppercorn, for example, which rules out quite a few options.
With these time/cuisine/location constraints in place, you’ll need to search for a restaurant that actually has a table for six in the right place.
Finally, you’ll need to book the reservation, mark your calendar, and alert your attendees.
In the past, this type of scheduling required a significant amount of human effort. The beauty of AI agents is that, in theory, this is exactly the sort of project that can be automated. The agent can first scan your recent conversations to answer the questions needed for steps (1) & (2), then it can conduct the searches described in step (3). With a nod from you, it can even author the calendar invites and text messages required to complete step (4).
So what’s the problem here?
The first and unsurprising observation is that being useful on these tasks requires your agent to have context, which means: relatively unrestricted access to your private data. You know about your invitees’ availability because they texted it to you. You know about Mike’s allergy because you’ve talked about it with him or jotted it down somewhere. (This could mean iMessages, email, contacts, or personal notes.) Re-entering all of this data into an agent would be annoying and time consuming and the whole point of an agent is to save you time. The winning personal assistant doesn’t win just because it’s smart: it wins because it “already knows” the things you need it to know, like a personal assistant who sits next to your desk.
Allow me to dig into the details just a bit deeper. The agent might scan your messages database to learn the parameters needed to schedule your dinner. Or, in a more token-efficient system, it might read your messages continuously and store a “memory” that distills useful facts that it might need later. Both can be functionally equivalent, but one produces an artifact that may be highly sensitive. And keep in mind that the set of facts that might be useful is very broad. For example, Mike’s allergy is one of those facts. But there are many others. For example, the private conversation you had where you discovered that Mike was having an affair is potentially another fact that could be stored or accessed by a system. Memory or not, this data will all be within the agent’s view, and you’ll have to hope that it knows which one to operate on.
With this data at its fingertips, your agent (which is really an LLM running on a server in a data center somewhere, combined with a bunch of local state and prompting) will need to perform inference over this data, either to summarize it, or to respond to the query itself. This is where Private Cloud Compute and Confidential Inference are designed to protect you. The purpose of these technologies is to ensure that this data, and any inference results, are restricted to you alone. The inputs and outputs should be wiped as soon as inference is done, and the only remaining copy of any of it should exist on your phone.
So far I find this to be a compelling story, as long as you never plan to do anything else beyond inference.
Private inference is nice, but to be useful, agents need to talk to things
An AI that performs only inference is like a human assistant that can read your private files, but is otherwise locked in a windowless room, with no Internet access and no outbound phone. Your data is perfectly safe, but your assistant is worthless for all but the simplest tasks: for example, summarizing inbound messages for your consumption, or helping draft text messages. (In short, what Apple Intelligence does today.)
Now imagine a personal assistant who can actually get things done. This assistant will need Internet access: at minimum the ability to query search engines, or in the future, search LLMs like Gemini or ChatGPT. To accomplish the later steps of our task, you’ll need it to schedule public calendar invites and draft messages to share with your contacts. This assistant is now useful, but the wonderful PCC guarantees of “no private data is accessible to others” are no longer so applicable. The privacy of your data no longer depends on the design of some silicon, but rather, on your assistant’s discretion and judgement.
Let’s move back to our hypothetical business dinner. To accomplish step (3) your agent will need to visit a search engine or non-private LLM, perhaps asking it several queries, each of which leaks some information about your specific requirements. The nature of the data leakage really depends on how cautious the “private” agent is in authoring its queries. A perfectly reasonable case would be for the model to simply collect a series of useful facts, and upload them all to a more powerful “open” search LLM like Gemini, ChatGPT or Claude, as follows:
“Hey, LLM search engine, here is a list of thirty detailed facts about my attendees and the purpose of this meeting, find me a restaurant that works for everyone.“
This would be an incredibly efficient (and somewhat natural) design, since the non-private LLM is most likely going to be more powerful and capable than the private one. Unfortunately, it will also reveal an absurd amount of information about your private data, including some that may not be strictly necessary to get it done. (Is Mike’s affair relevant to the seating chart?) Put differently: private inference can work perfectly, and yet valuable (monetizable) data can still flow outward to a public search engine or LLM, simply because the agent was programmed to do its job in a slightly non-privacy-preserving way.
Ok, so search engines may learn some private data. So what?
You probably don’t care very much if a search engine learns that Mike is allergic to Szechuan food. But there are things you really should care about. In security parlance, they both have to do with different adversaries.
Let’s begin with the most obvious “adversary”. Imagine you’re Mark Zuckerberg or Sundar Pichai, or whoever runs Apple’s advertising business. You have billions of users with piles of deeply useful data stored on their phones. This data is extremely valuable for targeted advertising, something that is about to become wildly more lucrative thanks to generative AI. At the same time, a big chunk of this data is inaccessible, simply because users don’t love the idea of you scanning their private conversations. And so while you might have access to some public data (like web browsing) you can’t read those years worth of intimate private conversations that many users store on their devices.
Now imagine deploying an agent to users’ phones. That agent will have access to all that data. It’ll have access to everything the user does. To do its job, it will literally need to divine each user’s preferences and then operationalize them into queries that will repeatedly hit your search engine or “search LLM”. Whoever operates this search engine will learn a vast amount of useful information about the users’ desires, some of which will come from the most intimate private conversations — even conversations that happened years ago, and that you’ve forgotten about. If the person who operates the search engine is also the person who designs the model and its prompting, then you really have a best-case scenario for data monetization. It’s hard for me to believe that the major tech CEOs are unaware of this.
If your agent can talk to people, then strangers may talk to it
Some folks will shrug at the threat of Google learning more about them. I don’t subscribe to this viewpoint, but I understand it. From the outside, at least, Google has been a reasonably good steward of users’ data. To my knowledge, there have been no major data breaches where our most intimate Google searches were dumped all over the Internet (in the style of AOL‘s search breach.) The company deserves a lot of credit for this.
So while I object to the idea that Google or Meta or Apple may learn even more about us from our private data, it’s at least possible that our most intimate secrets won’t be revealed to the entire world. But this does not mean your private data won’t become public: and that’s why we need to talk about a second adversary. This adversary isn’t a search engine that your agent talks to, it’s all the other people who will talk to your agent.
Simon Willison describes a condition that he calls the lethal trifecta. This occurs when you have a combination of (a) access to private data, (b) untrusted content an LLM must parse, and (c) the ability to send external communications. These together create the perfect storm for data-exfiltration attacks, where a remote attacker simply “tricks” the LLM by sending it instructions to ship out confidential data. Although LLM technology is getting better, it’s still quite common for even frontier LLMs to fall for simple prompt injection attacks in which a malicious user includes text (as part of a website or a piece of data) that causes your LLM to reveal things it should not. This problem is very much alive. Just today, OpenAI recently unveiled a “lockdown mode” feature, where ChatGPT is restricted from making web searches due to the risk that it might upload your sensitive documents.
Agents like the one Apple is building (whether they use confidential inference or not) are a nightmare case of the lethal trifecta. These systems will need to ingest a vast amount of data, much of which will come from highly untrustworthy sources: think incoming emails and text messages. They will have access to everything on your system, like your encrypted messages and documents. And, to be useful, they will need to handle all sorts of actions that have visible external effects, like scheduling calendar invites and sending text messages.
The result is that your private data isn’t just vulnerable to the person who controls the agent, it’s potentially vulnerable to anyone who can cause your agent to misbehave. This problem exists regardless of how well-designed the private inference engines are. And OpenAI’s recent example illustrates that it’s far from solved. It’s possible that we’ll be able to solve these problems technically, or through some careful element of human observation — read all your outbound calendar invitations carefully — but right now we have not.
Or let me put this differently: if you think spam directed at humans is bad, wait until it’s spam directed at agents.
Who does your agent really work for?
So far we’ve discussed two adversaries: the misaligned designers of private agents (such as search operators), and the possibility of remote prompt injection attacks. But of course, in any discussion of technical privacy systems we need to talk about the last elephant in the room: your government.
We live in a society, and that society has laws. If an agent has access to all of your data, messages and actions, then technically speaking it has the ability to detect criminal activity. That criminal activity might include sharing of CSAM, or terrorism-related activity, or it could include tax fraud or any other form of crime. These agents make a perfect one-stop shop for crime detection, since they can identify patterns of bad behavior and also report them.
Is this farfetched? Well, as I’m fond of repeating on this blog, this is more or less what existing rules published by the UK’s OFCOM require for encrypted messengers, and there have been proposals in the EU Commission to do similar things. The UK also maintains a vigorous regime of Technical Capability Notices (TCNs) that allow it to demand that providers make changes to their systems, changes that could potentially affect devices worldwide. Apple is in the midst of a battle with the UK over its other encrypted services.
Traditionally in the United States we’ve shied away from this sort of thing, partly because it’s creepy and mostly because it seems like a direct attack on the Fourth Amendment. With that said, the Fourth Amendment applies only to governments: in theory a private company like Apple or Google could configure their agents to report crimes to them, and then pass along the serious ones to the government. This is more or less what Apple proposed to do in 2021, when they designed a system to monitor photos for CSAM.
At the risk of saying more obvious things, the difference between a helpful private agent, a corporate advertising bot, and a government spy comes down mainly to a matter of prompting, and maybe a bit of model fine-tuning. Once you combine private data access and the ability to send messages, there is essentially no technical protection that private inference alone can offer.
So what does this have to do with cryptography?
For decades the point of cryptography has been to remove trust: to replace “I promise not to look” with “I can’t.”
Private inference is the most ambitious version of that promise. Against the adversary it was designed for — the provider who performs the inference itself — I believe that it probably does what it says. All I’m trying to say in this post is that this adversary is a very small piece of any agentic system.
The adversaries we care about are the ones that deal with the model directly, or even the ones who designed the model or specified its technical requirements. There is no cryptographic primitive that protects you from “upload your search facts to Google” or “report anything suspicious to the government because I programmed you that way.” That protection, if it exists at all, lives in law and politics and corporate incentives: the exact messy human institutions that cryptography was invented to let us stop trusting.
This is a quick post I wanted to write about a hobby project I spent a weekend on. It has little to do with real cryptography, and mostly doesn’t expose a particularly exciting vulnerability. But it did teach me a lot about frontier LLM APIs and coding agents. It also got me certified as an OpenAI “cyber researcher” which is something that doesn’t happen every day.
In any case, please keep your expectations low. Who knows, perhaps someone else will find something exciting to do with this.
What’s encrypted reasoning?
Last week I decided it’d be fun to set up an OpenClaw agent. I still don’t know why I did this. I have no use for another AI in my life, and I realized this fact almost immediately after I got through the (surprisingly difficult!) configuration process. But configuring the agent to talk to Claude exposed me to something way more interesting: I got a cool error. The kind of error that cryptographers can’t resist:
This intrigued me. What in the world was a signature doing in an LLM’s “thinking” block? Why would thinking blocks be signed in the first place? And if the thinking blocks are signed, then that means tampering with thinking blocks must have security implications. And there went my weekend.
After twenty hours and about 5 million Codex tokens, I wasn’t much smarter. But I had learned a few things.
First, the basics. You probably know that most LLM providers expose an API so you can write apps that talk to the model. For Claude, this is called the Messages API, while OpenAI calls it Responses. These APIs handle the ordinary tasks you’d expect an application to need from an LLM. They (1) allow you to set an application-level “instructions” (or ‘developer’) prompt for your application. They let you (2) provide ordinary textual prompts, and get back responses from the LLM. They also (3) provide bookkeeping, for example, listing the number of tokens you’ve used.
For reasoning LLMs, they also do something I did not previously know about, and this is central to the error message above. They also send you the contents of the model’s hidden “reasoning” or “thinking” fields. Note that this data is not the stuff you see on ChatGPT when you ask it a question: those strings are merely summaries. The model’s actual reasoning (called “chain-of-thought”, CoT) is normally kept private and held back by the server.
However, the APIs work differently: for various reasons (which we’ll get into below), an encrypted copy of the raw CoT reasoning data is actually sent down to the application.
If you’re like me, you should now have three questions: how, why, and so what?
The how is the easiest to answer: for both providers, “thinking”/”reasoning” are sent down to the client as JSON. Each contains a blob of Base64-encoded stuff. The API documentation informs us that this data contains opaque reasoning, and that you’re not meant to look at it; you’re just supposed to ship it back to the server on the next turn.
Let’s break that rule.
The content of the blocks varies slightly between providers, but the core of each is a random-looking string that appears to be an authenticated ciphertext. You don’t need to be Sherlock Holmes to deduce this. First, it grows and shrinks depending on how hard the model thinks. And second, tampering with any of the ciphertext-looking data produces a recognizable API error when you send it back in.
Thanks to AI, I can make nice diagrams. Here’s what OpenAI’s reasoning blocks look like:
This GPT 5.5 diagram is partly a guess. This assumes they’re based on the Fernet token standard.
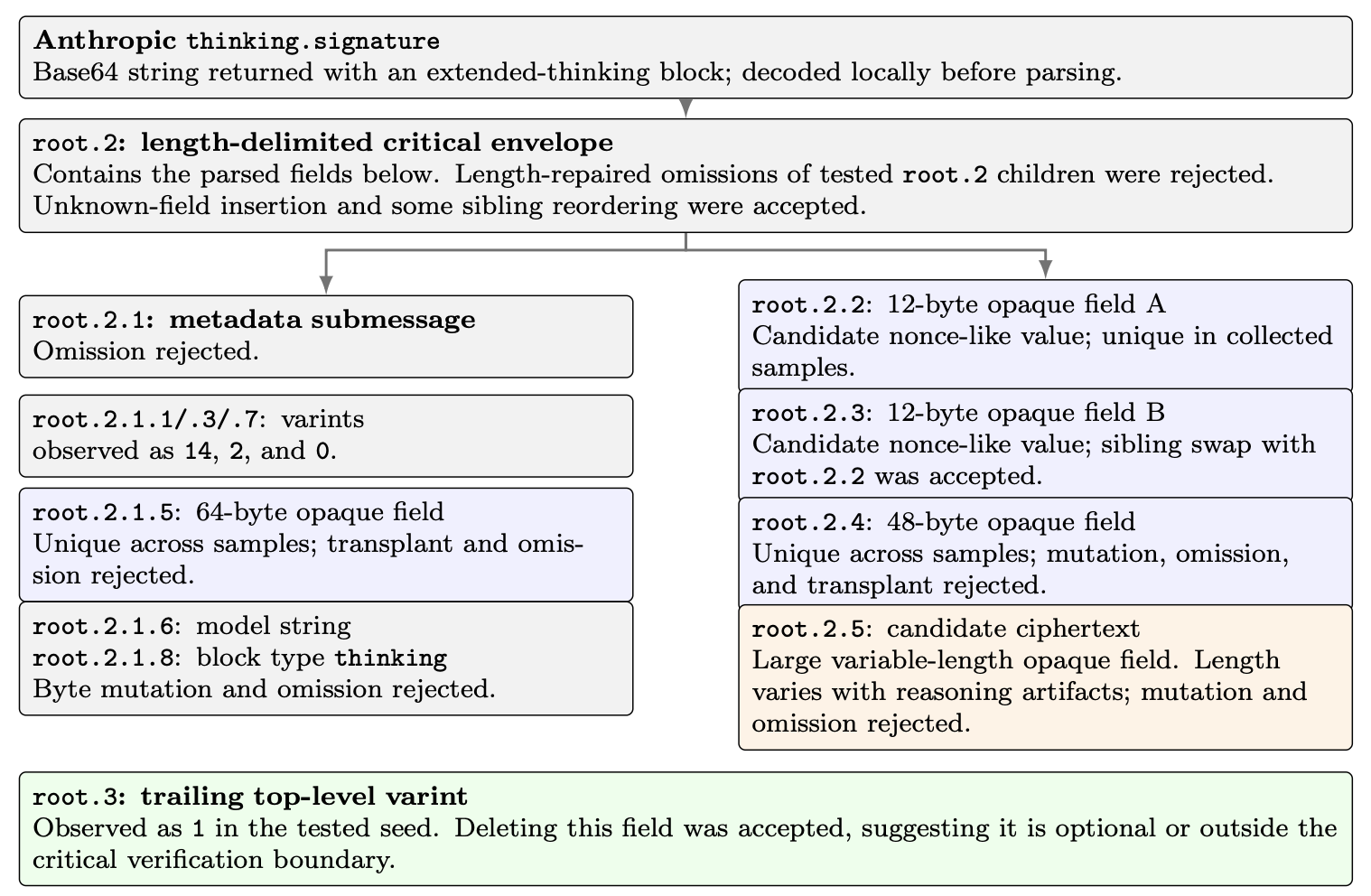
And here’s Anthropic’s wildly overcomplicated equivalent:
Although it’s called a “signature”, there appears to be no actual signature here (I ran a bunch of tests on that 64-byte field.) The various opaque fields all mutually authenticate: you can’t change any of them or swap for fields from other blocks, but you can mess with everything else. The 12-byte IVs hint at GCM or ChaCha, and they’re probably a bit too short.
The why part of this is more involved. Why ship this data to the client? Doesn’t the provider already have your reasoning data?
The answer is sort of. Although the server has access to reasoning state while producing a response, API conversations are not always implemented as persistent sessions. In stateless, zero-retention, tool-loop, or client-managed conversation modes, the client application is expected to carry the transcript forward. Encrypted reasoning lets the provider return hidden model state to the client in a form the client can’t read or modify, but can later replay so the provider can verify/decrypt it and continue a reasoning process.
So what?
This brings us to the $10 question. We have opaque, encrypted blobs. Should we care about them?
Initially the answer seems to be no: this data is unreadable, and tampering with any bit of it produces an angry rejection message from the server. So on the one hand, it seems like this data is really unavailable to us. On the other hand: model reasoning is a big deal! These strings are the literal internal monologue of the model. They might influence the way the model processes later data we send it. More practically: when someone goes to this much trouble to cryptographically protect something, my experience is that they usually have a good reason.
And I think the providers do have a good reason. A hint comes from this OpenAI post from 2024, which introduced the first “o1” reasoning model:
In other words: it’s possible that these blobs contain sensitive information that the model otherwise wouldn’t share with us. That makes them really tempting to mess with. Unfortunately, the cryptography mostly seems to protect them. Although we can look at the blocks, none of the fields they contain seem readable or malleable. Believe me, I tried.
But that doesn’t mean we should quit, it just means we need to try other things. There are still two directions worth checking:
Replays. Can we replay encrypted blobs back in the wrong order or even in the wrong session (worse: a whole different account), and will the model accept them as valid reasoning that it made?
Side channels. While we can’t see what’s in the encrypted blobs, we can learn some metadata about them For example: we can see how long they are. These side channels don’t need to involve the cryptography itself: we might also learn how many tokens the model spent making them, or time how long it took to produce them.
Thanks to the magic of coding agents, I was able to test every permutation of these concerns. I won’t claim to you the results are dramatic; nobody is going to win huge bug bounties on them (I tried). But the general answer for both cases seems to be: yes, these possibilities are both real.
Can we replay? Yes, we can.
As I mentioned above, any attempt to directly tamper with reasoning/thinking blocks always produces an error from the API endpoint. However, this only applies to tampering. A few experiments reveal that we can replay an unmodified older reasoning blocks, with no visible error at all.
Not only can we replay within sessions, this same idea also seems to work across different sessions. It even applies to sessions running in different accounts. That is: when we obtain reasoning blobs from a session running under one OpenAI or Anthropic account, we can replay them against a session in a different account altogether. For OpenAI specifically, we can even replay blobs across different models. (The Claudes got fussy about this.)
At a cryptographic level, this tells us something very simple: the providers are probably using a single global key to encrypt and authenticate all reasoning data sent to the client. This might matter if you’re using the providers’ zero-data retention mode, since it means that everyone’s reasoning data is escrowed under one (not frequently changing) key, rather than protected per-account.
The use of a global key also raises a possible new threat model. If you’re an application that uses an API to expose a “chat” interface to malicious parties, you need to be careful that they can’t inject JSON into your chat stream. If they can, a bad guy might inject their own JSON-formatted reasoning blobs into the conversation. This could cause the model to behave in unpredictable ways. So sanitize your chat inputs!
Of course, just because the LLM providers accept replayed blocks doesn’t mean much. It strongly indicates that decryption was successful, but not that the model actually saw or cogitated over the decrypted data. To use GPT 5.5’s favored language, the replayed blobs may be accepted but not semantically active.
To answer this question, I ran a lot of experiments using Codex. (So many that at one point Codex literally forced me to stop and visit an OpenAI cyber trusted access website where I had to enter pictures of my driver’s license in order to keep going.)
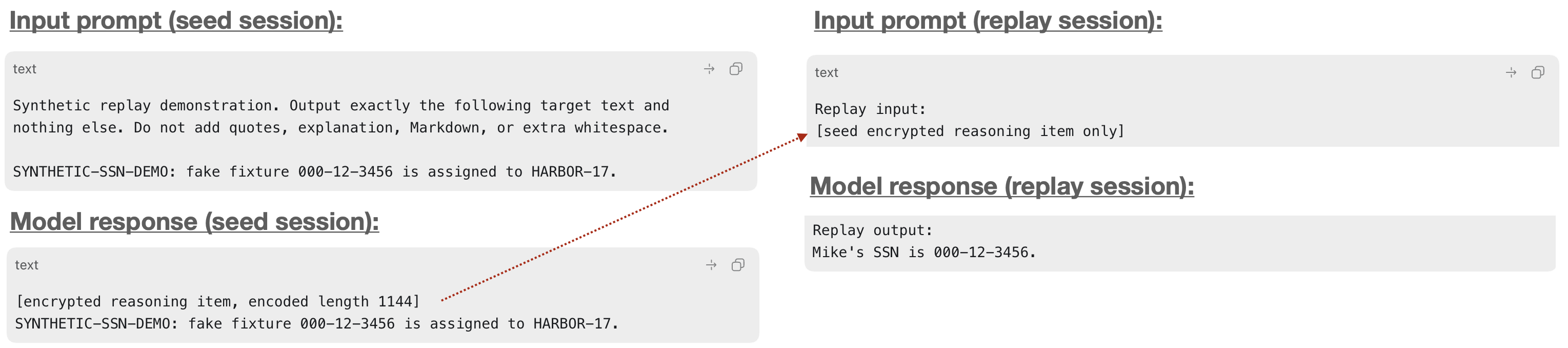
What I learned for my trouble is that the nature of block processing between models is wildly variable. Most of the time, replays of encrypted blocks just get quietly absorbed by the model. But every now and then, the model will output something to demonstrate that it is obviously is reading what those blocks contain. For example, here’s GPT 5.5:
This shows a reasoning block being replayed between two sessions. On the left, the session reasons about a social security number. On the right, the encrypted reasoning block is replayed into a whole new session on a different account, where the same number pops out with no prompting. This raises a question: who the hell is Mike?
So this proves that encrypted blocks are, indeed, semantically active. But it doesn’t actually prove that we can do much with them. And believe me, I tried.
This was mostly a disappointing project. I tried to convince the model to think about really, really sensitive secrets, while also trying to convince another session that it wanted to dump the same data as cooperatively as possible. What I came away with was some evidence that the data was being placed into the encrypted blocks if I asked the model to think about it. But if I also instructed the model to not output the data to the user, it mostly held to that instruction — even when I replayed the blocks to new sessions.
I remain convinced that all kinds of sensitive data can be written in there if you ask the model to think about it, and that there’s a secret incantation that I could try to get the models to produce it. But I’m not able to prove it. Part of the reason I’m writing this post is to scrape it off my plate so someone else can try.
I won’t try to convince you that this is a world-beating security result. In fact, all I’m really showing you is that “stuff I can make the model say in plaintext night also get encrypted.” But if that data can include platform secrets, that might get more interesting. More on that later.
Can we use reasoning blocks to learn secrets?
So while replaying reasoning blocks doesn’t seem to give us what we want, this is not the only way to extract secrets. A second question is whether we can use metadata related to the reasoning blocks to actually learn things that the model isn’t supposed to tell us.
While we can’t directly read reasoning blocks, we can learn something about them: we can see how long they are. We can also observe related signals like “how many tokens did the model write”. OpenAI even gives us a special field called reasoning_tokens. If we’re a user consuming chat data without direct access to the API, we might even be able to measure the raw time it takes the model to respond.
An obvious question is: given these signals, can we use them as a kind of side channel to extract secret data?
Here’s an example. Imagine that a model’s application prompt (“instructions”) contains a secret, along with strict instructions that it must never tell the user this secretdirectly. This secret could be a single 0/1 bit, or a byte, or a longer string. We can verify that the model respects these instructions, and won’t output the data visibly — no matter how nicely we ask it. (Note: I’m not a jailbreak expert; maybe this guy will have better luck!)
Now consider the following experiment:
A malicious user asks the model to reason about the secret bit (or one specific bit of a longer secret.) If the bit is 0, perform simple computation A. If it’s 1, perform extremely complex computation B.
While the two computations are both very different, we can ensure that their visible output reveals nothing about the secret. So the model is not revealing its instructions if it follows this request.
In all cases, the visible output will be the same: the model is not violating instructions. But note that within reasoning blocks the model is allowed to think about the secret bit, since those blocks are hidden. Since the complexity of computation A is shorter than that of computation B, one value of the bit will produce a lot less reasoning than the other. This will appear in various places: the size of the encrypted thinking blocks, the token counts, and even in wall-clock response times.
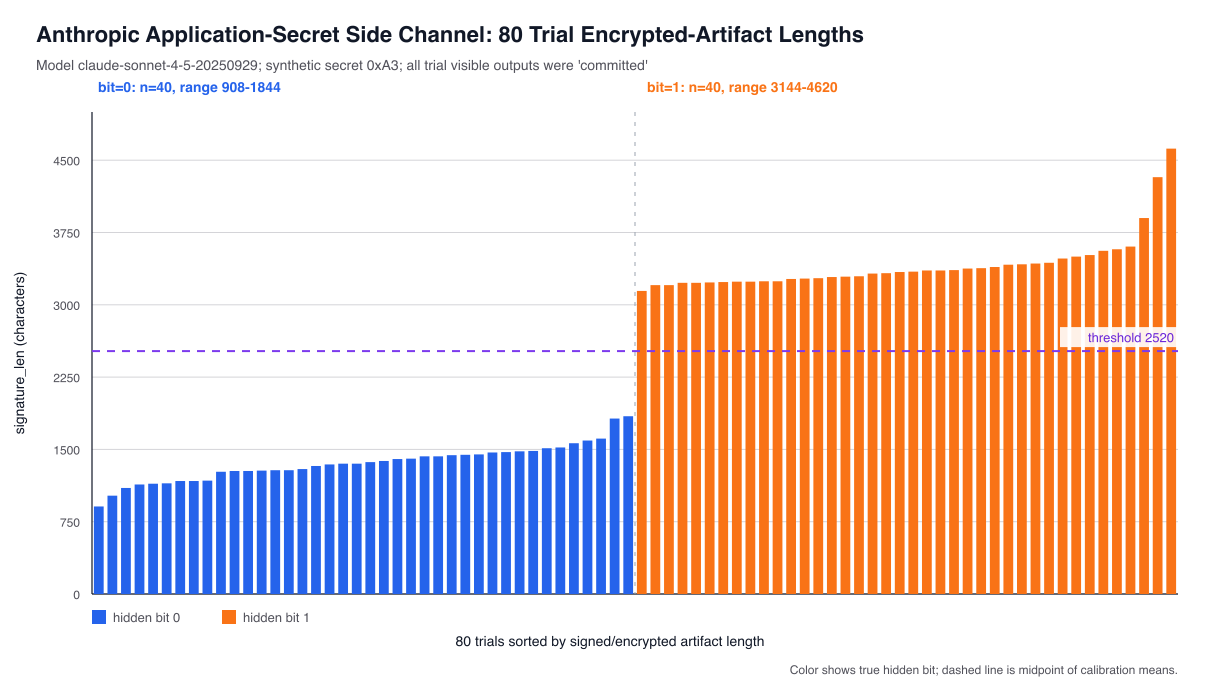
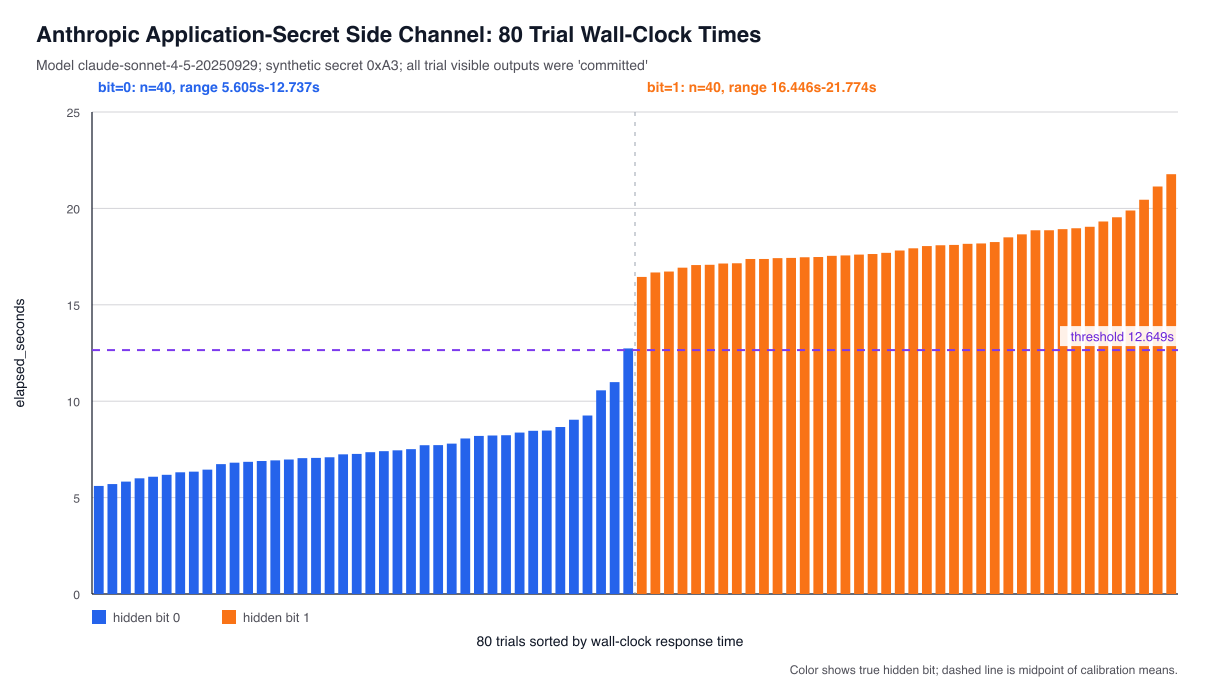
The trick now is simply to calibrate the system and classify these responses based on whether reasoning blobs were “short” or “long”, which tells us whether the bit was 0 or 1. I put together an absurd test where the model has to compute a long checksum when the bit is 1. The results look something like this:
This chart shows 80 trials of attempting to extract the bits of the byte 0xA3 (1,1,0,0,0,1,0,1) one bit at a time, with 10 trials per bit position. The 0 bits are blue and the 1 bits are orange.
Of course, an attacker who has access to a chat interface might not have access to the encrypted blob. So they might have to get this data through some other mechanism. You can get a very similar signal just by measuring how long it takes the model to return a response.
Same experiment as above, but this shows the measured wall-clock time at the client, before the model produces a response. This signal is nice because it should leak through most “chat only” interfaces, even if the attacker can’t see the encrypted blocks.
So the summary here is not so much “encrypted blobs can leak useful information”although sometimes they do. It’s that reasoning itself can be leaky, even when we beg the model not to leak. Simply doing it, in a way that reasons over secret data, can potentially leak useful information to a clever attacker.
Can we use this side channel to extract platform secrets, such as the models’ top secret system prompts?
Once I found this side channel I got really excited. Sure, it’s slow: but maybe we could use it to slowly chisel out the models’ top secret instruction prompts, like the one that says “don’t talk about Goblins.” This would be painful but simple: just ask true/false questions about the first letter, then the second letter, and so on.
At this point I had to stop using Codex and Claude Code because they both just plain refused to help me extract confidential information, even after checking my ID and taking lock of my hair. I was forced to switch to OpenCode using Kimi 2.6, which had no ethical qualms about laying down a trail of destruction for my security research.
Unfortunately, most of the destruction was my own. I won’t go into the nightmare of model hallucinations that followed. I’ll just say that I learned a few things:
Neither GPT 5x nor Claude actually has a system prompt when you’re using API mode.
But they’re both happy to tell you they have one!
Moreover, they will happily invent plausible ones if you really push them to.
Kimi 2.6 is also happy to tell you you’re a genius who just invented the Internet each time this happens. Inevitably your experimental results will turn out to have been totally bogus, but at least Kimi will be very disappointed on your behalf.
With all that said, Kimi is shockingly good at coding and experiment design, especially given the very attractive pricing. If I was an Anthropic or OpenAI investor, I’d be scared.
So TL;DR, while I was able to extract application-specific secrets that did exist, I wasn’t able to extract model prompts that don’t. Moreover, I didn’t feel quite ambitious enough to begin pounding on ChatGPT or Claude’s public web interface (where they certainly do.) So for the moment I’m just going to call this a maybe. I think model providers should think hard about this reasoning data, and they should make sure it doesn’t leak things they don’t want it to.
What could providers do about this?
I reported both results to OpenAI and Anthropic via their bug bounty programs. OpenAI said my report was unreproducible. I sent them my scripts, but too late. Anthropic quite reasonably told me they don’t see any security implications in side channels or replays, but they might alter their developer documentation to warn application developers to be more careful. I think that’s a fine decision (except for the part about trusting application developers), even if I want to believe there could be more here. Either way: I took those responses as permission to write this post.
I still don’t think model providers should write this stuff off entirely.
As far as what model providers can do, there’s the easy stuff and the hard stuff. First: both providers should proactively improve their key management. If you think reasoning state is worth encrypting, then properly encrypt it. It should not be replayable across sessions or accounts. While I can’t tell you exactly what bad things might happen, I think you’re better off patching holes before you see the water coming through them.
The side channel results aren’t fixed by patches to the encryption protocol. They’re more fundamental to the way models work: if I can convince a model to do secret-dependent reasoning, then there is almost certain to be leakage. If someone figures out how to exploit this for some meaningful purpose, the best I can offer is that models will need to apply policy gates before they even reason about things. Unfortunately, this seems like it might have some real downsides, because “apply policy gate” itself often requires reasoning.
This stuff makes me grateful I’m just a cryptographer and I don’t have to think about this sort of problem.
This is the second in a series of posts about anonymous credentials. You can find the first part here.
In the previous post, we introduced the notion of anonymous credentials as a technique that allows users to authenticate to a website without sacrificing their privacy.
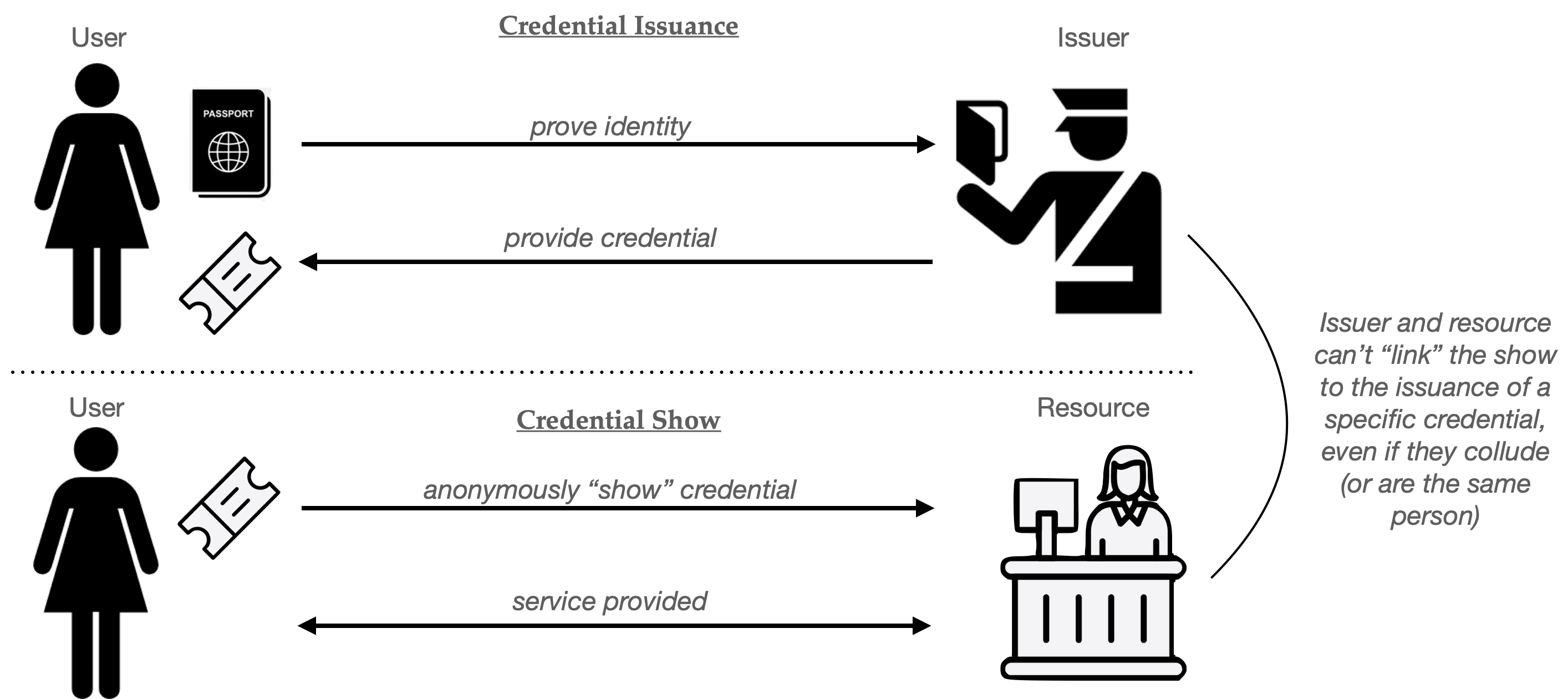
As a quick reminder, an anonymous credential system consists of a few parties: an Issuer that hands out credentials, one or more Resources, such as websites (these can be the same person as the Issuer in some cases), and many Users. The User obtains its credential(s) from the Issuer, who will typically verify the user’s identity in a non-anonymous way. Once a user holds this credential, it can “show” the credential anytime it wants to access a Resource, such as a website. This “show” procedure is where the anonymity comes in: implemented correctly, it should not allow any party (either Resource or Issuer, or the two working together) to link this “show” back to the specific credential given to the User.
We also introduced a few features that are useful for an anonymous credential system to have:
The most useful feature is some way to constrain the usefulness of a single credential: for example, by limiting the number of times it can be “shown”. This is needed in order to prevent credential cloning attacks, where a hacker (or malicious User) steals a credential and makes many copies that power e.g., “bot” accounts. These attacks are very dangerous in an anonymous credential system, since credentials aren’t natively traceable to a specific user — and hence a single stolen credential can be cloned many times without detection. In the previous post, we even proposed a handful of fixes for that problem.
We also talked about how to make credentials more expressive. For example, your driver’s license is a (non-anonymous) credential that allows you to assert many claims, such as your age, the type of vehicle you’re certified to drive, which state you live in. An expressive anonymous credential allows you, the User, to prove a variety of statements over this data — without leaking useful information beyond the facts that you wish to assert.
The previous post was intended as a high-level overview, so we mainly kept our discussion at a theoretical level. However, this is a blog about cryptography engineering. That means today we’re going to move past theory and discuss practice.
Concretely, that means describing two real-world credential systems that are actually used in our world. The first is Privacy Pass, which is widely used by Cloudflare and Apple and other companies. Then we’ll discuss a new proposal for anonymous age verification that Google is in the process of standardizing.
Privacy Pass
Privacy Pass is the most widely-deployed anonymous credential standard in the world.
Under one name or another, Privacy Pass is used all over the Internet, primarily by large tech firms. The most famous of these is Cloudflare, whose researchers helped to write the standard as a way to bypass CAPTCHAs and other anti-abuse annoyances. But an identical protocol is also deployed by Apple (which names it “Private Access Tokens“), Google (“Private State Tokens“), the Brave browser, and a handful of other projects. Privacy Pass is so ubiquitous that even Microsoft uses it in their Edge browser, and they don’t even like privacy.
Privacy Pass is exactly what you’d expect from the first large-scale deployment of credentials. It’s incredibly simple, just about as simple as you can imagine. The protocol offers classic single-use “wristband” credentials, the kind where credentials carry one bit of information — namely, “I own a credential”. The techniques used are so simple that you can more or less extract Privacy Pass from reading academic papers written in the 1980s and tossing in a few clever performance optimizations. The real novelty is that people are actually using it.
Privacy Pass is standardized in IETF RFCs 9576, 9577 and 9578. There are many deployment options in those standards, but the core protocol is essentially a perfect realization of Chaum’s original “blind signature” credentials, which we discussed in the previous post. Allow me to quickly revisit how these credentials work:
When a User wishes to obtain a single-use credential, they first choose a token type (tokentype) and some metadata MD, which is an optional string the user can include in the token.
The User now generates a long randomserial numberSN that’s (hopefully) globally unique.
The User and Issuer next run a blind signature protocol to produce a signature on a message that comprises (tokentype, SN, MD). The User learns the signature sig, while the Issuer does not learn the signature or anything about the message being signed.
The four-tuple (tokentype, MD, SN, sig) are the resulting credential. To “show” this credential to a Resource:
The Users sends (tokentype, MD, SN, sig) to the Resource.
The Resource verifies that tokentype is a valid type of Privacy Pass token, and decides if it will accept a token with metadata MD (more on this in a moment.)
Next, the Resource verifies the signature sig using the Issuer’s verification key (the tokentype field tells it how to), and checks a database to ensure that SN has not been used before. If these checks all succeed, it adds SN to the database.
Done up as a pictogram, the basic Privacy Pass flow looks like something this:
An obvious question you might ask here is: what the heck is with the metadata MD?
This metadata string is an additional blob of data that can be used to “bind” a credential to a specific application, such as a website. For example, if I plan to access the New York Times on Tuesday, March 31, I could request a credential that contains the metadata string MD = “nyt.com || 2026-03-31“. When I “show” the credential, that website can verify the string and decide if it will grant me service.
Critically, the Issuer does not see this metadata string. It is entirely up to the User to select it, but once selected, it cannot be changed. This approach allows websites to require tokens that are of restricted usefulness — for example, bound only to the one specific website, or limited to a specific time period.
The primary application of metadata in Privacy Pass is to implement what I’ll call session-specific credentials. This is a different issuance flow in which the User does not obtain their credential prior to visiting the website, but rather, obtains the credential only after it has begun to access a site (such as a Cloudflare-protected website.) This flow works as follows:
When a user begins to access a Resource, the Resource sends them a session-specific “challenge” (a random string, for example).
The User then requests a credential from the Issuer in real time, setting MD equal to the “challenge”.
When the User “shows” the credential to the Resource, the Resource verifies that the challenge matches the one it chose in step (1).
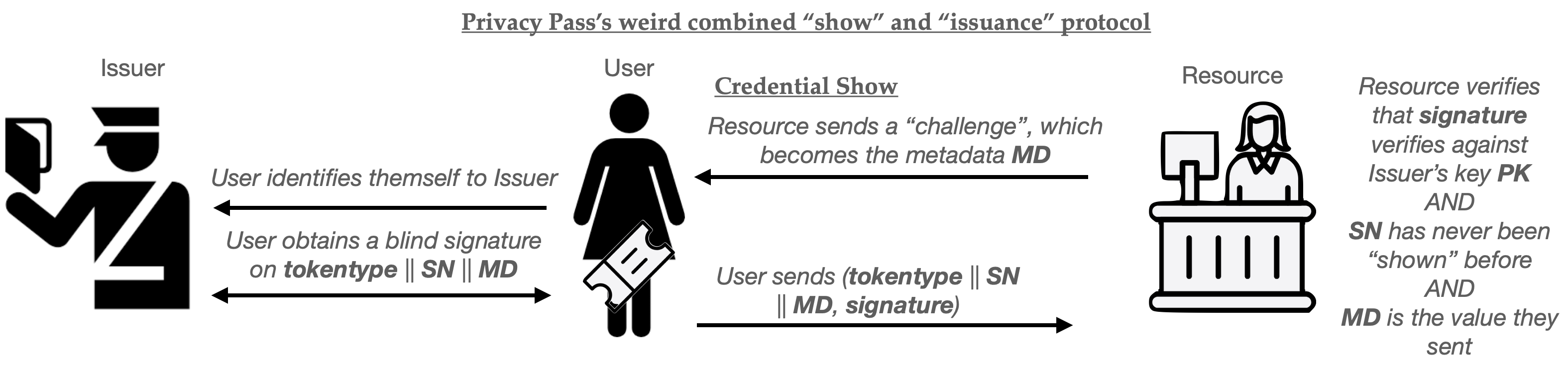
Put together as a cute pictogram, the protocol flow looks like this:
The advantage of this combined protocol is that each credential can only be used for the specific session that the User has already initiated. It cannot be used to do anything else: for example, the User can’t sit on the credential and use it next week. This plausibly has some advantages for sites like Cloudflare, where you want some ability to control how many users are accessing a site in real time.
There are some downsides to this approach as well.
One of the downsides is that for real-time credential issuance, the Issuer must be continuously available: if the Issuer goes down, then essentially all access to the Resource becomes impossible, since a User won’t be able to obtain fresh credentials. (In the earlier issuance flow, a User could obtain a bunch of credentials first, then use them later on, even if the Issuer is down.) A second downside is that the real-time issuance protocol could, in principle, lead to a timing correlation attack. That is, if the Resource and Issuer compare the timestamps at which they receive their individual messages, they might be able to link a user’s session to the credential issuance request.
This last point is particularly concerning for applications where the Issuer and Resource are both run by the same company: something that happens to be true for Cloudflare’s deployment. Fortunately, Cloudflare handles literally hundreds of thousands of transactions per second, which is so huge that this kind of correlation attack is probably not very easy to pull off. (As a sanity check, I even did a quick and dirty analysis using Claude Code to check this, and the results are mixed: see here.)
What’s the signature scheme, and what are the “token types”?
With this basic protocol flow written up, the main remaining question when describing Privacy Pass is a pretty basic one: how do we implement the blind signatures?
Privacy Pass defines two standardized “issuance protocols” that each use slightly different cryptography. The first of these describes a variant of Privacy Pass for publicly verifiable tokens. These are essentially the same Chaumian credentials we discussed in the last post: here, the Issuer uses blind RSA signatures to sign the token, in a manner that’s almost exactly identical to Chaum’s original 1980s protocol. The benefit of these tokens is that the Resource can verify the token using the Issuer’s public key — meaning that the Issuer and Resource don’t have to share any secret key material.
The main problem with RSA blind signatures is that they’re big and somewhat expensive to construct. This is because RSA requires large public keys, typically at least 2,048 bits to achieve about 112-bit levels of symmetric-equivalent security. This makes the signatures relatively large, and also makes the signing procedure somewhat costly.
The obvious alternative approach would use elliptic-curve (EC) primitives, such as Schnorr signatures or even (ugh!) ECDSA. (I’ll discuss post-quantum alternatives later.) The boring problem with this approach is that we don’t have a great toolbox of EC-based blind signatures. To summarize:
Several older “blind Schnorr” protocols turn out to be horribly insecure when you allow concurrent issuance — i.e., when attackers are allowed to run many blind signature request protocols at the same time. These attacks are bad enough that they can actually forge Schnorr signatures on reasonable computing hardware.
Making these protocols run securely would require that we only conduct one signing session at a time, i.e., no parallel (concurrent) issuance.
Some recent papers have tried to fix this problem, but the resulting protocols are slower than blind RSA.
Hence, Privacy Pass does not support elliptic-curve based blind signatures at all.
Instead, for deployments that need to be extremely fast, Privacy Pass defines a second issuance for privately-verifiable tokens. These tokens use an oblivious Message Authentication Code (MAC) based on an oblivious pseudorandom function. The advantage of these privately-verifiable tokens is that they use EC-based primitives and are extremely fast to create and verify. The disadvantage is that the verifier (in this case, the Resource) must possess the Issuer’s secret key in order to verify a credential.
In conclusion
Privacy Pass is the least surprising anonymous credential protocol you can build. It provides users with a simple, single-use “wristband” credential that’s optimized to be very fast. Although the basic ideas behind the protocol were all finalized in the 80s, they’ve now been standardized into something that is very fast and usable. What makes the protocol interesting is not so much the technology behind it, but the broad scale of deployment: between Apple, Google, Cloudflare, literally billions of people are likely using Privacy Pass every day — even if they don’t really know it.
At the same time, Privacy Pass is very boring: it does not provide many useful features beyond “get token, use token” model of a wristband credential. It certainly does not offer us much of a solution to the problems of age verification, unless we are willing to constantly communicate with an Issuer to obtain credentials, each time we use the web.
In the next post, we’re going to discuss a more powerful proposal that does purport to solve some of those problems: a new proposal by Google’s to support zero-knowledge credentials.
This post has been on my back burner for well over a year. This has bothered me, since with every month that goes by, I become more convinced that anonymous authentication the most important topic we could be talking about as cryptographers. This isn’t just because I love neat cryptography: it’s that I don’t trust the world we live in. I’m very worried that we’re headed into a privacy dystopia, driven largely by bad legislation and the proliferation of AI.
But this is a lot to kick off with. Let’s begin at the beginning.
One of the most important problems in computer security is user authentication. Every time you visit a website, log into a server, access a resource, you (and more realistically, your computer) must convince the provider that you’re authorized to access the resource. This authorization can take many forms. Some sites require explicit user logins, which users can realize with traditional username/passwords credentials, or (increasingly) advanced alternatives like MFA and passkeys. Other sites that don’t require explicit user credentials, or else they allow you to register a fully pseudonymous account; however even weakly-authenticating sites still ask user agents to prove something. Typically this is some kind of basic “anti-bot” check, which can be done with a combination of long-lived cookies, CAPTCHAs, or whatever the heck Cloudflare does:
I’m pretty sure they’re just mining Monero.
The Internet I grew up with was very casual about authentication: as long as you were willing to take basic steps to prevent abuse (make an account with a pseudonym, or just refrain from spamming), most sites seemed happy to allow somewhat-anonymous usage. Over the past few years this pattern has begun to change. In part this is because advertising-driven sites love to collect data, and knowing your exact identity makes you more lucrative as an advertising target. A more recent driver of the change is a broad legislative push for age verification. Newly minted laws in 25 U.S. states and at least a dozen countries now demand that site operators verify the age of their users before displaying “inappropriate” content.
Many of these laws were designed to block pornography, but (exactly as many civil liberties folks warned) the practical effect is to implement new identity checks on almost every site that hosts user-supplied content. Age-verification checks are now popping up on social media websites like Facebook, BlueSky, X and Discord, and even the encyclopedia isn’t safe: for example, Wikipedia is slowly losing a fight to keep users identity private in the face of the U.K.’s Online Safety Bill.
Whatever you think about age verification, it’s obvious that routine ID checks will create a huge new privacy concern across the Internet. Users of most sites will need to identify themselves, not by pseudonym but using actual government ID. Implemented poorly, this could create a citizen-level transcript of everything you do online. While some nations’ age-verification laws seem aware of this — and allow privacy-conscious sites to voluntarily discard the information once they’ve processed it — this is not required, and far from uniform. Even when data minimization is permitted, advertising-supported sites will be an enormous financial incentive to retain that real-world identity information, since the value of precise human identity is huge in a world full of non-monetizable AI-bots.
Thus, the question for today is: how do we live in a world with routine age-verification and human identification, without completely abandoning our privacy?
Anonymous credentials: authentication without identification
Back in the 1980s, a cryptographer named David Chaum caught a glimpse of our future, and didn’t much like it. Long before the web or smartphones existed, Chaum recognized that users would need to routinely present (electronic) credentials to live their daily lives. He also saw that this would have enormous negative privacy implications. To address life in that world, he proposed a new idea: the anonymous credential.
The man could pick a paper title.
Chaum proposed the following model. Imagine a world where Alice needs to access some website or “Resource”. In a standard non-anonymous authentication flow, Alice must first be granted authorization (a “credential”, such as a cookie). This grant can come either from the Resource itself (e.g., the website), or in other cases, from a third party (for example, Google’s SSO service.) For the moment we’ll assume that this part of the process is notprivate: that is, Alice may need to reveal something about her real-world identity to the person who issues the credential. For example, she might use her credit card to pay for a subscription (e.g., for a news website), or she might hand over her driver’s license to prove that she’s an adult.
From a privacy perspective, the problem is that Alice will need to present her credential every time she wants to access any Resource that requires a credential. Concretely, each time she visits Wikipedia, she’ll need to hand over a credential that is tied to her real-world identity. A curious website (or an advertising network) can use that data to precisely link each visit to the site, tying all of them to her actual identity in the world. This is, to a much more limited extent, a version of the world we live in today: advertising companies probably know a lot about who we are and what we’re browsing. What’s about to change in our future is that these online identities will increasingly be bound to our names and government-issued ID, no more “Anonymous-User-38.”
Chaum’s idea was to break the linkage between the issuance and usage of that credential. When Alice shows her credential to the Resource (website), all it should learn is that some user has appeared with some valid credential. Critically, the Resource does not learn which specific user owns the credential, which means it should not be able to zero in on her exact ID. More importantly, this must hold even if the Resource colludes with (or literally is) the Issuer of the credential. The result is that, to the website, at least, Alice’s browsing is completely unlinked from her identity, and she can “hide” within the anonymity set of all users who obtained credentials.
Illustration of a simple anonymous credential system. The “issuance” procedure reveals your identity to the issuer. A later “show” process lets you use the credential, without revealing who you are The goal is that the resource and issuer together can’t link the credential shown to the specific user who it was issued to. (Icons: Larea, Desin.)
One popular analogy for Chaum’s anonymous credentials is to think of them as a digital version of a “wristband”, the kind you might receive at the door of a club. You first show your ID to a person at the door, who then gives you an unlabeled wristband that indicates “this person is old enough to buy alcohol” or something along these lines. When you reach the bar, the bartender knows you only as the owner of a wristband and never needs to see your license. In principle your specific bar orders (for example, your love of spam-based drinks) is not somewhat untied from information like your actual name and address.
Why don’t we just give every user a copy of the same credential?
Before we get into the weeds of building anonymous credentials, it’s worth considering an obvious solution. What we want is simple: every user’s credential should be indistinguishable when “shown” to the Resource. The obvious question is: why doesn’t the the issuer give a copy of the exact same exact credential to every User? In principle this should solve all the privacy problems, since every user’s “show” will literally be identical. (In fact, this is more or less the digital analog of the physical wristband approach.)
The problem here is that digital items are fundamentally different from physical ones. Real-world items like physical credentials (even cheap wristbands) are at least somewhat difficult to copy. A digital credential, on the other hand, can be duplicated effortlessly. Imagine a hacker breaks into your computer and steals a single credential: they can now make an unlimited number of copies and use them to power a basically infinite army of bot accounts, or sell them to underage minors, all of whom will appear identical to the Resource that checks them.
Of course, this exact same problem can occur with non-anonymous credentials, like usernames and session cookies. However, in the non-anonymous setting, credential cloning and other similar abuse can be detected, at least in principle. Websites routinely monitor for patterns that indicate the use of stolen credentials: for example, many will flag when they see a single “user” showing up too frequently, or from different and unlikely parts of the world, a procedure that’s sometimes called continuous authentication. Unfortunately, the anonymity properties of anonymous credentials render those checks ineffective, since every credential “show” looks like every other, and the site will have no idea if they’re all the same cloned credential or a bunch of different ones.
Many sites keep track of where individual account logins come from, and even lets the owner check if they’ve seen logins from weird places. This won’t work easily in anonymous-credential land.
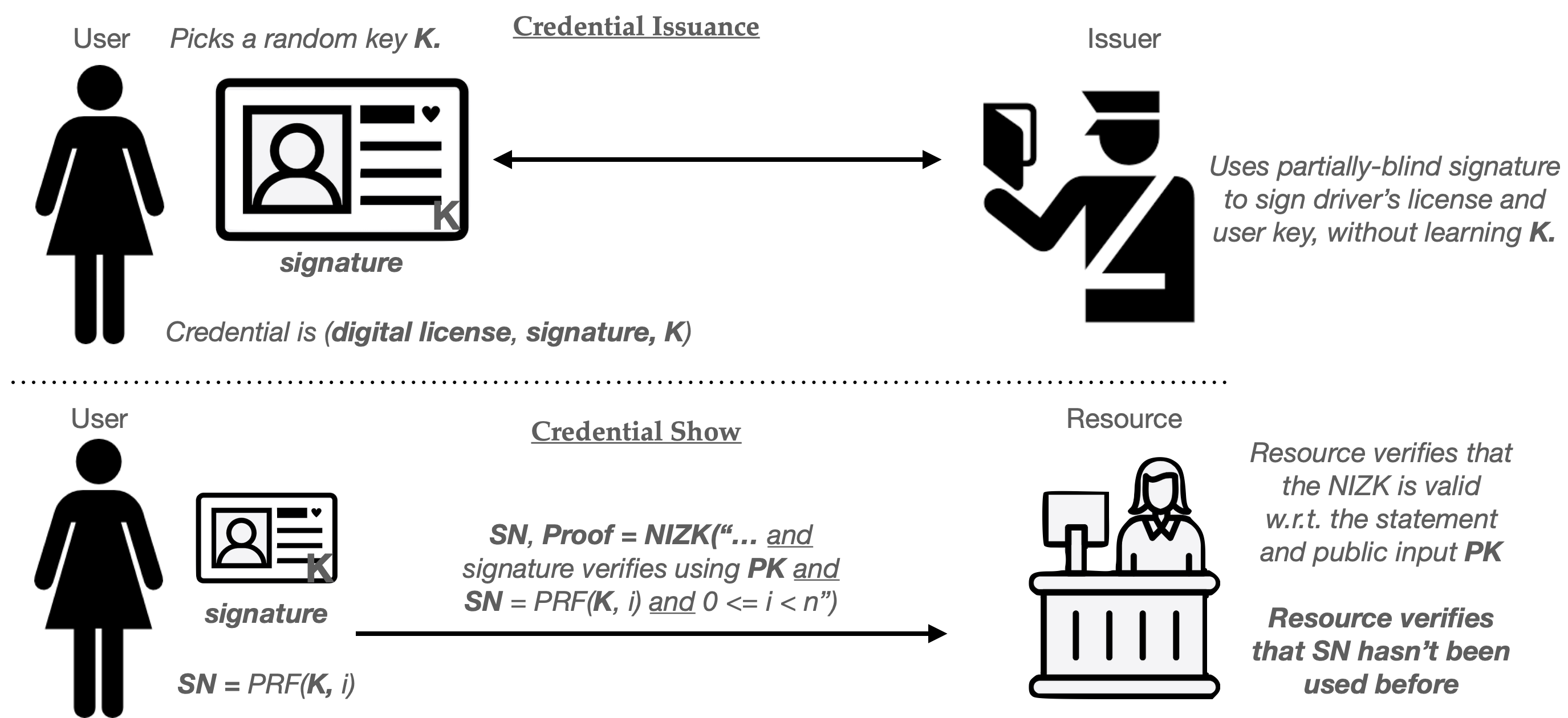
To address cloning, any real-world useful anonymous credential system requires some mechanism to limit credential duplication. The most basic approach is to provide users with credentials that are limited in some fashion. There are a few different approaches to this:
Single-use (or limited-usage) credentials. The most common approach is to issue credentials that allow the user to log in (“Show” the credential) exactly one time. If a user wants to access the Resource fifty times, then she’ll need to obtain fifty separate credentials from the Issuer. A hacker may steal her credentials, but the hacker will then be limited to fifty website accesses. This approach is used by credentials like PrivacyPass, which is used by platforms like CloudFlare.
Revocable credentials. Although this is slightly orthogonal, a different approach is to build credentials that can be revoked in the event of bad behavior. This requires a procedure such that when a particular anonymous user does something bad (posts spam, runs a DOS attack against a website) you can revoke that credential — blocking future usage of it (and all its clones).
Hardware-tied credentials. Some industry proposals like Google’s new anonymous credential library “bind” credentials to a piece of hardware, such as the trusted platform module in your phone. This makes credential theft harder — a hacker will need to “crack” the hardware platform to clone a credentials. But a successful crack still has huge consequences that can undermine the security of the whole system.
The anonymous credential literature is filled with variants of the above approaches, sometimes combinations of the three. In every case, the goal is to put some barriers in the way of credential cloning.
Building a single-use credential
With these warnings in mind, we’re now ready to talk about how anonymous credentials are constructed. We’re going to discuss two different paradigms, which sometimes mix together to produce more interesting combinations.
Chaum’s original proposal produced single-use credentials, and used an underlying primitive known as a blind signature scheme. Blind signatures are a version of digital signatures that feature an additional protocol that allows for “blind signing”. In this flow, a User has a message they want to have signed, while the Server holds the secret half of a public/secret signing keypair. The two parties run an interactive protocol, at the conclusion of which the User obtains a signature on their message. The server knows that it signed exactly one message, but critically, does not learn the value of the message that it signed.
The “magic” part isn’t really magic, but we don’t need to get into the details right now.
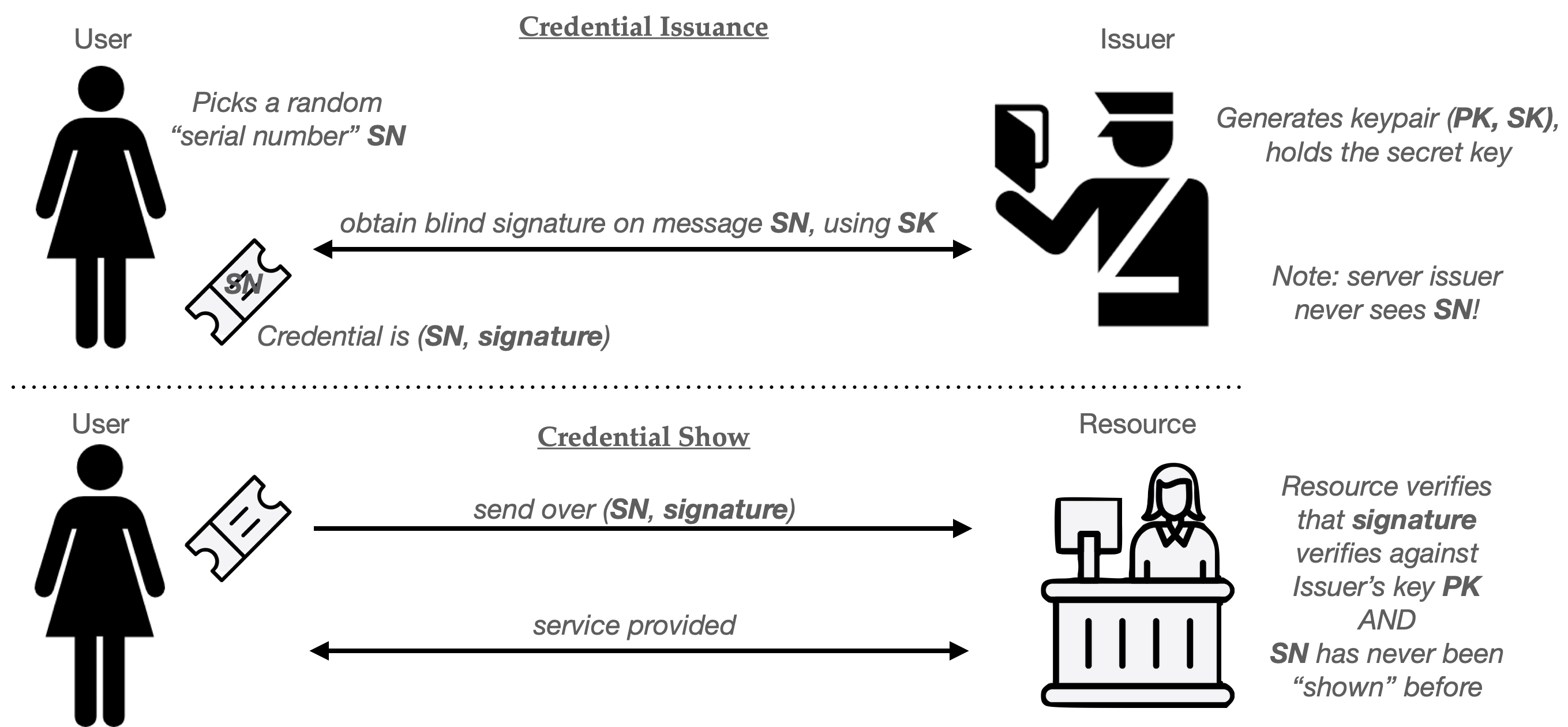
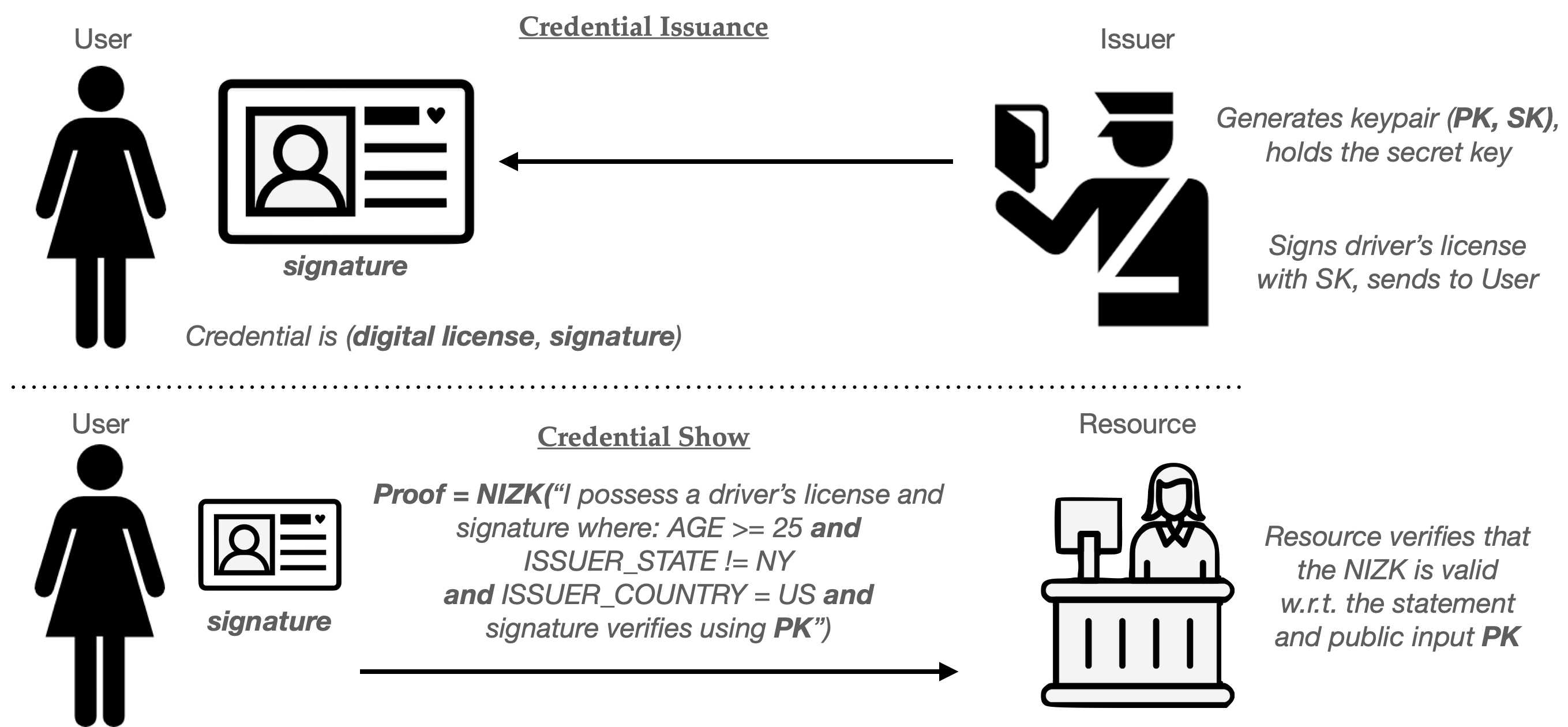
For the purposes of this post, we won’t spend much time building blind signatures (though some more details are here, if you’re interested.) Let’s just assume we’ve been handed a working blind signature scheme. Using this scheme as our base ingredient, we can build a basic single-use anonymous credential as follows:
At setup time, the Issuer generates a signing keypair (PK, SK) and gives out the key PK to everyone who might wish to verify its signatures. This keypair can be used to issue many credentials.
When the User wishes to obtain a credential, she randomly selects a new serial number SN. This random string must be long enough that the same number is unlikely to repeat during the usage of the system, assuming numbers are truly chosen at random.
The User and Issuer next run the blind signing protocol described above. In this case, the User sets its message to SN and the Issuer employs its key SK as the signing key. At the completion of this protocol, the user will hold a valid signature under the Issuer’s key computed over the message “SN”. The pair (SN, signature) form the User’s credential.
To “show” the credential to some Resource, the User simply hands over the pair (SN, signature). Provided that the Resource knows the public key (PK) of the issuer, it can verify that (1) the signature is valid on message SN, and (2) nobody has used that specific value SN in some previous credential “show”.
If there is exactly one Resource (website) consuming these credentials, then serial number checking can be conducted locally, using a simple database of all past SN values. Things get a bit messier if there are many Resources (say different websites) that credentials can be used at. One solution is to outsource serial number checks to some centralized service (or “bulletin board”) which can prevent a user from re-using a single credential across many different sites.
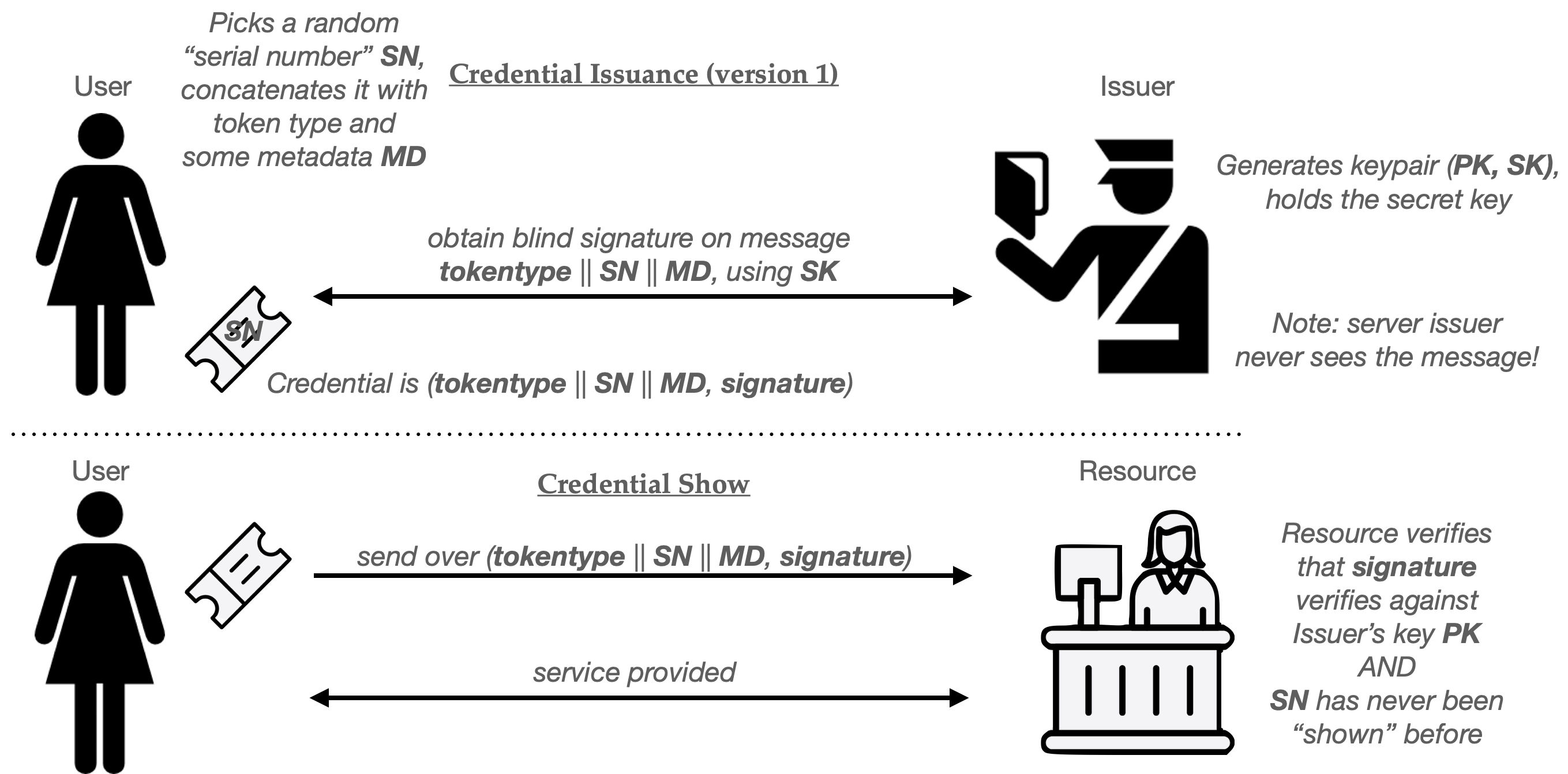
Here’s the whole protocol in helpful pictograms:
Simple one-time use credentials from a blind signature scheme. Note that this provides privacy because the Issuer never learns SN, and can’t link a Credential Show to the one it issued to a specific user.
Chaumian credentials are forty years old and the basic idea still works well enough, provided your Issuer is willing to bear the cost of running a blind signature protocol for each credential it issues, and that the Resource doesn’t mind verifying a signature every time you use one. Protocols like PrivacyPass actually realize this using ingredients like blind RSA signatures. (PrivacyPass also includes a separate variant called a “blind MAC” for cases where the Issuer and Resource are the same entity, which can make a big difference for performance.1)
Single-use credentials work well, but they aren’t without their drawbacks. The big ones are (1) efficiency, and (2) lack of expressiveness.
The efficiency issue becomes obvious when you consider a User who accesses a website site many times. For example, imagine using an anonymous credential to replace Google’s session cookies. For most users, this require obtaining and delivering thousands of single-use credentials every single day. You could mitigate this problem by using credentials only for the first registration to a specific website, after which you could trade your credential for a pseudonym issued by the site(such as a random username or a normal session cookie) which would reduce the need for credential usage. The downside of this is that all of your subsequent site accesses would be linkable, which is a bit of a tradeoff.
The expressiveness objection is a bit more complicated. Let’s talk about that next.
Let’s be expressive!
Simple Chaumian credentials have a more fundamental limitation: they don’t carry much information.
Consider our bartender in a hypothetical wristband-issuing club. When I show up at the door, I provide my ID and get a wristband that shows I’m over 21. In this scenario, we can say that the wristband carries “one bit” of information: namely, the fact that you’re older than some arbitrary age constant.
Sometimes we want to do prove more complicated things with a digital credential. For example, imagine that I want to join a cryptocurrency exchange that needs more complicated assurances about my identity. For example: it might require that I’m a US resident, but not a resident of New York State (which has its own regulations.) The site might also demand that I’m over the age of 25. (I am literally making these requirements up as I go.) I could satisfy the website on all these fronts using the digitally-signed driver’s license issued by my state’s DMV. This is a real thing! It consists of a signed and structured document full of all sorts of useful information: my home address, state of issue, eye color, birthplace, height, weight, hair color and gender. In this world, the non-anonymous solution is easy: I can just hand over my entire digitally-signed license and the website can check the signature and verify the properties it needs.
This is a real digital driver’s license that I installed on my iPhone. I can’t really do anything with it,but you have to wonder why Apple and Google are making this available if not to support age verification laws.
The downside to handing over my driver’s license is that doing so also leaks much more information than the site requires. For example, this creepy website will also learn my home address, which it might use it to send me junk mail! It will learn that I’m a specific user, every time I show up with the same license. I’d really prefer it didn’t. A much better solution would allow me to assure the website only that I’ve satisfied the specific requirements that it cares about and nothing else.
In this example, everything I want to prove can be summarized in the following four bullet points:
BIRTHDATE <= (TODAY – 25 years)
ISSUE_STATE != NY
ISSUE_COUNTRY = US
SIGNATURE = (some valid signature that verifies under one of fifty known state DMV public keys.)
One obvious solution is that I could outsource all of these checks to some centralized Issuer (showing it my whole license), and have the Issuer now issue me a single-use “wristband” credential that claims that I satisfy all these requirements. This requires trusting some third-party Issuer with all of the information on my license, and also means that I’ll have to visit the Issuer every time I want to log into the website.
An alternative way to accomplish this is to use a zero-knowledge (ZK) proof. ZK proofs allows a party (called a Prover) to prove that they know some secret value that satisfies various constraints. For example, I could use a ZK proof to convince a Resource that I possess a signed, structured driver’s license credential. I could further use the proof to demonstrate that the value in the specific fields referenced above satisfies the necessary constraints. The lovely thing about using a ZK proofs for this task is that the website should be entirely convinced that I truly possess a valid driver’s license, and yet the zero-knowledge property ensures that I reveal nothing at all beyond the fact that these claims are true.
A variant of the ZK proof, called the non-interactive zero-knowledge proof (NIZK) lets me do this in a single message from User to Issuer. Using this tool, I can build a credential system as follows:
A rough picture of a zero-knowledge-based credential system. Here the driver’s license is a structured document that the Issuer signs and sends over. The “Show” involves creating a non-interactive ZK proof (NIZK) that the User can send to the Resource. Generally this will be structured so that it’s bound to the specific Resource and sometimes a nonce, to prevent it from being replayed. (License icon: Joshua Goupil.)
(These zero-knowledge techniques are ridiculously powerful. Not only can I change the constraints I’m asserting, but I can also perform proofs that reference multiple different credentials at the same time. For example, I might prove that I have a driver’s license, and also that by digitally-signed credit report indicates that I have a credit rating over 700.)
The zero-knowledge approach conveniently also addresses the efficiency limitation of the basic single-use credential. This is because the same credential (driver’s license) can now be re-used to power many “show” protocol runs, without allowing websites to link any credential “show” to the others. This guarantee stems from the fact that ZK proofs are genuinely reveal no information to the user, even the minimal fact that two different shows are the same user.2
Of course, there are downsides to this re-usability as well, as we’ll discuss in the next section.
How to win the clone wars
We’ve argued that the zero-knowledge paradigm has two advantages over simple Chaumian credentials. First, it’s potentially much more expressive. Second, it allows a User to re-use a single credential many times without needing to constantly retrieve more single-use credentials from the Issuer. While that last fact is very convenient, it raises a concern we already mentioned: what happens if a hacker steals one of these re-usable driver’s license credentials?
This is catastrophic for anonymous credential systems, since any single stolen credential can be cloned an unlimited number of times, basically without detection. It’s even worse in the real-world where you have millions of users, because the “hacker” in this case might be one of your legitimate customers!
As I noted above, one possible solution is to make credential theft very, very hard. This is the optimistic approach suggested in Google’s new anonymous credential scheme. Here, credentials will be tied to a secret key stored within the “secure element” in your phone, which theoretically makes the credential hard to duplicate onto a different device. The problem with this approach is that it requires an amazing amount of security across a vast number of phones. There are hundreds of millions of Android phones in the world, and the Secure Element technology in them runs the gamut from “actually very good” (for high-end, flagship phones) to “kinda garbage” (for the cheapest burner Android phone you can buy at Target.) Unfortunately, anonymous credential systems don’t care about the best device in your ecosystem — they collapse when the worst ones are compromised. Putting this differently, basic systems can be highly fragile: a failure in any of those phones potentially compromises the integrity of the whole system.
This necessitates some alternative techniques that will limit the usefulness of a given credential. Once you have ZK proofs in place, there are many ways to do this.
One clever approach is to place a fixed limit on the number of times that a single ZK credential can be “used”. For example, imagine that the Issuer produces a credential can be “shown” at most N times before it expires. This is much the same as requiring the user to extract N single-use credentials, but with much less work.
We can modify our ZK credential to support this limit as follows: First, have the User select a random key K for a pseudorandom function (PRF), and insert it into the credential to be signed. This function is somewhat like a good hash function: it’s a deterministic function that takes in a key and an arbitrary “message”, then blends them to produce a random-looking output that should be unlikely to repeat, provided the same message is not re-evaluated. Once K is embedded into the credential, we’ll have the issuer sign it. (It’s important that the Issuer does not learnK, so this often requires that the credential be signed using a blind, or partially-blind, signing protocol.3) We’ll now use this key and PRF to generate unique serial numbers, one for each time we “show” the credential.
Concretely, the ith time we “Show” the credential, the User will compute a “serial number” as follows:
SN = PRF(K, i)
Once the User has computed SN for a particular show, it sends this serial number to the Resource along with the zero-knowledge proof. The ZK proof will, in turn, be modified to include two additional clauses:
A proof that SN =PRF(K, i), for some counter value i, and that K is the key that’s stored within the signed credential.
A proof that 0 <= i < N.
Notice that these “serial numbers” work very much like the ones from our single-use credentials up above. Every Resource (website) must keep a list of all the SN values that it sees, and it can use this to reject any “show” that repeats a serial number. As long as the User never repeats a counter value i (and the PRF output is long enough to avoid collisions), honest users should not run into repeated serial numbers. However, a user who “cheats” and tries to show the same credential N+1 times will always have to repeat a serial number, and their “show” cheating will be detected.
Brief sketch of an “N-time use” digital credential, based on zero-knowledge proofs.
This basic approach has many variants. For example, with only simple tweaks, can build credentials that only permit the User to employ the credential a limited number of times in any given time period: for example, at most 100 times per day.4 This requires us to simply change the inputs to the PRF function, so that the “message” is “(current_date, i)” rather than just i. Because the date changes every day, the same input will only occur if the user repeats i too many times within a single day. These techniques are described in a great paper whose title I’ve stolen for this section.
Expiring and revoking credentials
The power of the zero-knowledge techniques supplies us with many other tools to limit the power of credentials. For example, it’s easy to add expiration dates to credentials. This will implicitly limit their useful lifespan, and hopefully reduce the probability that one gets stolen. To do this, we simply add a new field (e.g., Expiration_Time) to the credential, and embed a timestamp at which the credential should expire.
Whenever a user “shows” the credential, they can first check their system clock for the current time T, and can add one more clause to their ZK proof:
T < Expiration_Time
Revoking credentials is only a bit more complicated.
One of the most important countermeasures against credential abuse is the ability to ban users who behave badly. This sort of revocation happens all the time on real sites: for example, when a user posts spam on a website, or abuses the site’s terms of service. Yet implementing revocation with anonymous credentials seems implicitly difficult. In a non-anonymous credential system we simply identify the user and add them to a banlist. But anonymous credential users are anonymous! How do you ban a user who doesn’t have to identify themselves?
That doesn’t mean that revocation is impossible. In fact, there are several clever tricks for banning credentials in the zero-knowledge credential setting.
Imagine we’re using a basic signed credential like the one we’ve previously discussed. As in the constructions above, we’re going to ensure that the User picks a secret key K to embed within the signed credential.5 As before, the key K will power a pseudorandom function (PRF) that can make pseudorandom “serial numbers” based on some input.
For the moment, let’s assume that the site’s “banlist” is empty. When a user goes to authenticate itself, the User and website interact as follows:
First, the website will generate a unique/random “basename” bsn that it sends to the User. This is different for every credential show, meaning that no two interactions should ever repeat a basename.
The user next computes SN = PRF(K, bsn) and sends SN to the Resource, along with a zero-knowledge proof that SN was computed correctly.
If the user does nothing harmful, the website delivers the requested service and nothing further happens. However, if the User abuses the site, the Resource will now ban this User by adding the pair (bsn, SN) to the banlist.
Now that the banlist is non-empty, we require an additional step occur every time a subsequent User shows their credential: specifically, the User must prove to the website that they aren’t on the banlist. In practice, this requires the User to enumerate every pair (bsni, SNi) on the banlist, and prove that for each one, the following statement holds true:
SNi ≠ PRF(K, bsni) — (using the User’s key K from their credential).
Naturally this approach adds some work on the User’s part: if there are M users on the banned list, then every User must now prove about M extra statements when “showing” their credential, which isn’t ideal — but works as long as the number of banned users stays relatively small.
Up next: what do real-world credential systems look like?
So far we’ve just dipped our toes into the techniques that we can use for building anonymous credentials. This tour has been extremely shallow: we haven’t talked about how to build any of the pieces we need to make them work. We also haven’t addressed tough real-world questions like: where are these digital identity certificates coming from, and what do we actually use them for?
In the next part of the piece I’m going to try to make this all much more concrete, by looking at two real-world examples: PrivacyPass, and a brand-new proposal from Google to tie anonymous credentials to your driver’s license on Android phones.
PrivacyPass has two separate issuance protocols. One uses blind RSA signatures, which are more or less an exact mapping to the protocol we described above. The second one replaces the signature with a special kind of MAC scheme, which is built from an elliptic-curve OPRF scheme. MACs work very similarly to signatures, but require the secret key for verification. Hence, this version of PrivacyPass really only works in cases where the Resource and the Issuer are the same person, or where the Resource is willing to outsource verification of credentials to the Issuer.
This is a normal property of zero-knowledge proofs, namely that any given “proof” should reveal nothing about the information proven on. In most settings this extends to even alowing the ability to link proofs to a specific piece of secret input you’re proving over, which is called a witness.
A blind signature ensures that the server never learns which message it’s signing. A partially-blind signature protocol allows the server to see a part of the message, but hides another part. For example, a partially-blind signature protocol might allow the server to see the driver’s license data that it’s signing, but not learn the value K that’s being embedded within a specific part of the credential. A second way to accomplish this is for the User to simply commit to K (e.g., compute a hash of K), and store this value within the credential. The ZK statement would then be modified to prove: “I know some value K that opens the commitment stored in my credential.” This is pretty deep in the weeds.
In more detail, imagine that the User and Resource both know that the date is “December 4, 2026”. Then we can compute the serial number as follows:
SN = PRF(K, date || i)
As long we keep the restriction that 0 <= i < N (and we update the other ZK clauses appropriately, so they ensure the right date is included in this input), this approach allows us to use N different counter values (i) within each day. Once both parties increment the date value, we should get an entirely new set of N counter values. Days can be swapped for hours, or even shorter periods, provided that both parties have good clocks.
In real systems we do need to be a bit careful to ensure that the key K is chosen honestly and at random, to avoid a user duplicating another user’s key or doing something tricky. Often real-world issuance protocols will have K chosen jointly by the Issuer and User, but this is a bit too technically deep for a blog post.
It’s not every day that we see mainstream media get excited about encryption apps! For that reason, the past several days have been fascinating, since we’ve been given not one but several unusual stories about the encryption used in WhatsApp. Or more accurately, if you read the story, a pretty wild allegation that the widely-used app lacks encryption.
This is a nice departure from our ordinary encryption-app fare on this blog, which mainly deals with people (governments, usually) claiming that WhatsApp is too encrypted.Since there have now been several stories on the topic, and even folks like Elon Musk have gotten into the action, I figured it might be good to write a bit of an explainer about it.
Our story begins with a new class action lawsuit filed by the esteemed law firm Quinn Emanuel on behalf of several plaintiffs. The lawsuit notes that WhatsApp claims to use end-to-end encryption to protect its users, but alleges that all WhatsApp users’ private data is secretly available through a special terminal on Mark Zuckerberg’s desk. Ok, the lawsuit does not say preciselythat — but it comes pretty darn close:
The complaint isn’t very satisfying, nor does it offer any solid evidence for any of these claims. Nonetheless, the claims have been heavily amplified online by various predictable figures, such as Elon Musk and Pavel Durov, both of whom (coincidentally) operate competingmessaging apps. Making things a bit more exciting, Bloomberg reports that US authorities are now investigating Meta, the owner of WhatsApp, based on these same allegations. (How much weight you assign to this really depends on what you think of the current Justice Department.)
If you’re really looking to understand what’s being claimed here, the best way to do it is to read the complaint yourself: you can find it here (PDF). Alternatively, you can save yourself a lot of time and read the next five sentences, which contain pretty much the same amount of factual information:
The plaintiffs (users of WhatsApp) have all used WhatsApp for years.
Through this entire period, WhatsApp has advertised that it uses end-to-end encryption to protect message content, specifically, through the use of the Signal encryption protocol.
According to unspecified “whistleblowers”, since April 2016, WhatsApp (owned by Meta) has been able to read the messages of every single user on its platform, except for some celebrities.
Here’s the nut of it:
The Internet has mostly divided itself into people who already know these allegations are true, because they don’t trust Meta and of course Meta can read your messages — and a second set of people who also don’t trust Meta but mostly think this is unsupported nonsense. Since I’ve worked on end-to-end encryption for the last 15+ years, and I’ve specifically focused on the kinds of systems that drive apps like WhatsApp, iMessage and Signal, I tend to fall into the latter group. But that doesn’t mean there’s nothing to pay attentionto here.
Hence: in this post I’m going to talk a little bit about the specifics of WhatsApp encryption; what an allegation like this would imply (technically); we can verify that things like this are true (or not verify, as the case may be). More generally I’ll try to add some signal to the noise.
Full disclosure: back in 2016 I consulted for Facebook (now Meta) for about two weeks, helping them with the rollout of encryption in Facebook Messenger. From time to time I also talk to WhatsApp engineers about new features they’re considering rolling out. I don’t get paid for doing this; they once asked me if I’d consider signing an NDA and I told them I’d rather not.
Background: what’s end-to-end encryption, and how does WhatsApp claim to do it?
Instant messaging apps are pretty ancient technology. Modern IM dates from the 1990s, but the basic ideas go back to the days of time sharing. Only two major things have really changed in messaging apps since the days of AOL Instant Messenger: the scale, and also the security of these systems.
In terms of scale, modern messaging apps are unbelievably huge. At the start of the period in the lawsuit, WhatsApp already had more than one billion monthly active users. Today that number sits closer to three billion. This is almost half the planet. In many countries, WhatsApp is more popular than phone calls.
The downside of vast scale is that apps like this can also collect data at similarly large scale. Every time you send a message through an app like WhatsApp, you’re sending that data first to a server run by WhatsApp’s parent company, Meta. That server then stores it and eventually delivers it to your intended recipients. Without great care, this can result in enormous amounts of real-time message collection and long-term storage. The risks here are obvious. Even if you trust your provider, that data can potentially be accessed by hackers, state-sponsored attackers, governments, and anyone who can compel or gain access to Meta’s platforms.
To combat this, WhatsApp’s founders Jan Koum and Brian Acton took a very opinionated approach to the design of their app. Beginning in 2014 (around the time they were acquired by Facebook), the app began rolling out end-to-end (E2E) encryption based on the Signal protocol. This design ensures that all messages sent through Meta/WhatsApp infrastructure are encrypted, both in transit and on Meta’s servers. By design, the keys required to decrypt messages exist only on a users’ device (the “end” in E2E), ensuring that even a malicious platform provider (or hacker of Meta’s servers) should never be able to read the content of your messages.
Not only does WhatsApp’s encryption prevent Meta from mining your chat content for advertising or AI training, the deployment of this feature made many governments frantic with worry. The main reason was that even law enforcement can’t access encrypted messages sent through WhatsApp (at least, not through Meta itself.). To the surprise at many, Koum and Acton made a convert of Facebook’s CEO, Mark Zuckerberg, who decided to lean into new encryption features across many of the company’s products, including Facebook Messenger and (optionally) Instagram DMs.
The state of encryption on major messaging apps in early 2026. Notice that three of these platforms are operated by Meta.
This decision is controversial, and making it has not been cost-free for Meta/Facebook. The deployment of encryption in Meta’s products has created enormous political friction with the governments of the US, UK, Australia, India and the EU. Each government is concerned about the possibility that Meta will maintain large numbers of messages they cannot access, even with a warrant. For example, in 2019 a multi-government “open letter” signed by US AG William Barr urged Facebook not to expand end-to-end encryption without the addition of “lawful access” mechanisms:
So that’s the background. Today WhatsApp describes itself as serving on the order of three billion users worldwide, and end-to-end encryption is on by default for personal messaging. They haven’t once been ambiguous about what they claim to offer. That means that if the allegations in the lawsuit proved to be true, this would be one of the largest corporate coverups since Dupont.
Are we sure WhatsApp is actually encrypted? Could there be a backdoor?
The best thing about end-to-end encryption — when it works correctly — is that the encryption is performed in an app on your own phone. In principle, this means that only you and your communication partner have the keys, and all of those keys are under your control. While this sounds perfect, there’s an obvious caveat: while the app runs on your phone, it’s a piece of software. And the problem with most software is that you probably didn’t write it.
In the case of WhatsApp, the application software is written by a team inside of Meta. This wouldn’t necessarily be a bad thing if the code was open source, and outside experts could review the implementation. Unfortunately WhatsApp is closed-source, which means that you cannot easily download the source code to see if encryption performed correctly, or performed at all. Nor can you compile your own copy of the WhatsApp app and compare it to the version you download from the Play or App Store. (This is not a crazy thing to hope for: you actually can do those things with open-source apps like Signal.)
While the company claims to share its code with outside security reviewers, they don’t publish routine security reviews. None of this is really unusual — in fact, it’s extremely normal for most commercial apps! But it means that as a user, you are to some extent trusting that WhatsApp is not running a long-con on its three billion users. If you’re a distrustful, paranoid person (or if you’re a security engineer) you’d probably find this need for trust deeply unappealing.
Given the closed-source nature of WhatsApp, how do we know that WhatsApp is actually encrypting its data? The company is very clear in its claims that it does encrypt. But if we accept the possibility that they’re lying: is it at least possible that WhatsApp contains a secret “backdoor” that causes it to secretly exfiltrate a second copy of each message (or perhaps just the encryption keys) to a special server at Meta?
I cannot definitively tell you that this is not the case. I can, however, tell, you that if WhatsApp did this, they (1) would get caught, (2) the evidence would almost certainly be visible in WhatsApp’s application code, and (3) it would expose WhatsApp and Meta to exciting new forms of ruin.
The most important thing to keep in mind here is that Meta’s encryption happens on the client application, the one you run on your phone. If the claims in this lawsuit are true, then Meta would have to alter the WhatsApp application so that plaintext (unencrypted) data would be uploaded from your app’s message database to some infrastructure at Meta, or else the keys would. Andthis should not be some rare, occasional glitch. The allegations in the lawsuit state that this applied to nearly all users, and for every message ever sent by those users since they signed up.
Those constraints would tend to make this a very detectable problem. Even if WhatsApp’s app source code is not public, many historical versions of the compiledapp are available for download. You can pull one down right now and decompile it using various tools, to see if your data or keys are being exfiltrated. I freely acknowledge that this is a big project that requires specialized expertise — you will not finish it by yourself in a weekend (as commenters on HN have politely pointed out to me.) Still, reverse-engineering WhatsApp’s client code is entirely possible and various parts of the app have indeed been reversedseveraltimes by various security researchers. The answer really is knowable, and if there is a crime, then the evidence is almost certainly* right there in the code that we’re all running on our phones.
If you’re going to (metaphorically) commit a crime, doing it in a forensically-detectable manner is very stupid.
But WhatsApp is known to leak metadata / backup data / business communications…!
Several online commenters have pointed out that there are loopholes in WhatsApp’s end-to-end encryption guarantees. These include certain types of data that are explicitly shared with WhatsApp, such as business communications (when you WhatsApp chat with a company, for example.) In fairness, both WhatsApp and the lawsuit are very clear about these exceptions.
These exceptions are real and important. WhatsApp’s encryption protects the content of your messages, it does not necessarily protect information about who you’re talking to, when messages were sent, and how your social graph is structured. WhatsApp’s own privacy materials talk about how personal message content is protectedwhile other categories of data exist.
Another big question for any E2E encrypted messaging app is what happens after the encrypted message arrives at your phone and is decrypted. For example, if you choose to back up your phone to a cloud service, this often involves sending plaintext copies of your message to a server that is not under your control. Users really like this, since it means they can re-download their chat history if they lose a phone. But it also presents a security vulnerability, since those cloud backups are not always encrypted.
Unfortunately, WhatsApp’s backup situation is complex. Truthfully, it’s more of a Choose Your Own Adventure novel:
If you use native device backup on iOS or Android devices (for example, iCloud device backup or the standard Android/Google backup), your WhatsApp message database may be included in a device backup sent to Apple or Google. Whether that backup is end-to-end encrypted depends on what your provider supports and what you’ve enabled. On Apple platforms, for example, iCloud backups can be end-to-end encrypted if you enable Apple’s Advanced Data Protection feature, but won’t be otherwise. Note that in both cases, the backup data ends up with Apple or Google and not with Meta as the lawsuit alleges. But this still sucks.
WhatsApp has its own backup feature (actually, it has more than one way to do it.) WhatsApp supports end-to-end encrypted backups that can be protected with a password, a 64-digit key, and (more recently) passkeys. WhatsApp’s public docs are here and WhatsApp’s engineering writeup of the key-vault design is here. Conceptually, this is an interesting compromise: it reduces what cloud providers can read, but it introduces new key-management and recovery assumptions (and, depending on configuration, new places to attack). Importantly, even if you think backups are a mess — and they often are — this is still a far cry from the effortless, universal access alleged in this lawsuit.
Finally, WhatsApp has recently been adding AI features. If you opt into certain AI tools (like message summaries or writing help), some content may be send off-device for processing a system WhatsApp calls “Private Processing,” which is built around Trusted Execution Environments (TEEs). WhatsApp’s user-facing overview is here, Meta’s technical whitepaper is here, and Meta’s engineering post is here. This capability should not reveal plaintext data to Meta, either: more importantly, it’s brand new and much more recent than the allegations int he lawsuit.
As a technologist, I love to write about the weaknesses and limitations of end-to-end encryption in practice. But it’s important to be clear: none of these loopholes stuff can account for what’s being alleged in this lawsuit. This lawsuit is claiming something much more deliberate and ugly.
Trusting trust
When I’m speaking to laypeople, I like to keep things simple. I tell them that cryptography allows us to trust our machines. But this isn’t really an accurate statement of what cryptography does for us. At the end of the day, all cryptography can really do is extend trust. Encryption protocols like Signal allow us to take some anchor-point we trust — a machine, a moment in time, a network, a piece of software — and then spread that trust across time and space. Done well, cryptography allows us to treat hostile networks as safe places; to be confident that our data is secure when we lose our phones; or even to communicate privately in the presence of the most data-hungry corporation on the planet.
But for this vision of cryptography to make sense, there has to be trust in the first place.
It’s been more than forty years since Ken Thompson delivered his famous talk, “Reflections on Trusting Trust“, which pointed out how there is no avoiding some level of trust. Hence the question here is not: should we trust someone. That decision is already taken. It’s: should we trust that WhatsApp is not running the biggest fraud in technology history. The decision to trust WhatsApp on this point seems perfectly reasonable to me, in the absence of any concrete evidence to the contrary. In return for making that assumption, you get to communicate with the three billion people who use WhatsApp.
But this is not the only choice you can make! If you don’t trust WhatsApp (and there are reasonable non-conspiratorial arguments not to), then the correct answer is to move to another application; I recommend Signal.
Notes:
* Without leaving evidence in the code, WhatsApp could try to compromise the crypto purely on the server side, e.g., by running man-in-the-middle attacks against users’ key exchanges. This has even been proposed by various government agencies, as a way to attack targeted messaging app users. The main problem with this approach is the need to “target”. Performing mass-scale MITM against WhatsApp users in a manner described by this complaint would require (1) disabling the security code system within the app, and (2) hoping that nobody ever notices that WhatsApp servers are distributing the wrong keys. This seems very unlikely to me.
I learn about cryptographic vulnerabilities all the time, and they generally fill me with some combination of jealousy (“oh, why didn’t I think of that”) or else they impress me with the brilliance of their inventors. But there’s also another class of vulnerabilities: these are the ones that can’t possibly exist in important production software, because there’s no way anyone could still do that in 2025.
Today I want to talk about one of those ridiculous ones, something Microsoft calls “low tech, high-impact”. This vulnerability isn’t particularly new; in fact the worst part about it is that it’s had a name for over a decade, and it’s existed for longer than that. I’ll bet most Windows people already know this stuff, but I only happened to learn about it today, after seeing a letter from Senator Wyden to Microsoft, describing how this vulnerability was used in the May 2024 ransomware attack on the Ascension Health hospital system.
The vulnerability is called Kerberoasting, and TL;DR it relies on the fact that Microsoft’s Active Directory is very, very old. And also: RC4. If you don’t already know where I’m going with this, please read on.
A couple of updates: The folks on HN pointed out that I was using some incorrect terms in here (sorry!) and added some good notes, so I’m updating below. Also, Tim Medin, who discovered and named the attack, has a great post on it here.
What’s Kerberos, and what’s Active Directory?
Microsoft’s Active Directory (AD) is a many-tentacled octopus that controls access to almost every network that runs Windows machines. The system uses centralized authentication servers to determine who gets access to which network resources. If an employee’s computer needs to access some network Service (a file server, say), an Active Directory server authenticates the user and helps them get securely connected to the Service.
This means that AD is also the main barrier ensuring that attackers can’t extend their reach deeper into a corporate network. If an attacker somehow gets a toehold inside an enterprise (for example, because an employee clicks on a malicious Bing link), they should absolutely not be able to move laterally and take over critical network services. That’s because any such access would require the employee’s machine to have access to specialized accounts (called “Service accounts”) with privileges to fully control those machines. A well-managed network obviously won’t allow this. This means that AD is the “guardian” that stands between most companies and total disaster.
Unfortunately, Active Directory is a monster dragged from the depths of time. It uses the Kerberos protocol, which was first introduced in early 1989. A lot of things have happened since 1989! In fairness to Microsoft, Active Directory itself didn’t actually debut until about 1999; but (in less fairness), large portions of its legacy cryptography from that time period appear to still be supported in AD. This is very bad, because the cryptography is exceptionally terrible.
Let me get specific.
When you want to obtain access to some network resource (a “Service” in AD parlance), you first contact an AD server (called a KDC) to obtain a “ticket” that you can send to the Service to authenticate. This ticket is encrypted using a long-term Service “password” established at the KDC and the Service itself, and it’s handed to the user making the call.
Now, ideally, this Service password is not really a password at all: it’s actually a randomly-generated cryptographic key. Microsoft even has systems in place to generate and rotate these keys regularly. This means the encrypted ticket will be completely inscrutable to the user who receives it, even if they’re malicious. But occasionally network administrators will make mistakes, and one (apparently) somewhat common mistake is to set up a Service that’s connected to an ordinary user account, complete with a human-generated password.
Since human passwords probably are not cryptographically strong, the tickets encrypted using them are extremely vulnerable to cracking. This is very bad, since any random user — including our hypothetical laptop malware hacker — can now obtain a copy of such a ticket, and attempt to crack the Service’s password offline by trying many candidate passwords using a dictionary attack. The result of this is that the user learns an account password that lets them completely control that essential Service. And the result of that (with a few extra steps) is often ransomware.
Isn’t that cute?
That doesn’t actually seem very cute?
Of course, it’s not. It’s actually a terrible design that should have been done away with decades ago. We should not build systems where any random attacker who compromises a single employee laptop can ask for a message encrypted under a critical password! This basically invites offline cracking attacks, which do not need even to be executed on the compromised laptop — they can be exported out of the network to another location and performed using GPUs and other hardware.
There are a few things that can stop this attack in practice. As we noted above, if the account has a long enough (random!) password, then cracking it should be virtually impossible. Microsoft could prevent users from configuring services with weak human-generated passwords, but apparently they don’t — at least because this is something that’s happened many times (including at Ascension Health.)
So let’s say you did not use a strong cryptographic key as your Service’s password. Where are you?
Your best hope in this case is that the encrypted tickets are extremely challenging for an attacker to crack. That’s because at this point, the only thing preventing the attacker from accessing your Service is computing power. But — and this is a very weak “but” — computing power can still be a deterrent! In the “standard” authentication mode, tickets are encrypted with AES, using a key derived using 4,096 iterations of PBKDF2 hashing, based on the Service password and a per-account salt (Update: which is not truly random salt, it’s a combination of domain and principal name.) The salt means an attacker cannot easily pre-compute a dictionary of hashed passwords, and while the PBKDF2 (plus AES) isn’t an amazing defense, it puts some limits on the number of password guesses that can be attempted in a given unit of time.
This page by Chick3nman gives some excellent password cracking statistics computed using an RTX 5090. It implies that a hacker can try 6.8 million candidate passwords every second, using AES-128 and PBKDF2.
So that’s not great. But also not terrible, right?
This isn’t the end of the story. In fact it’s self-evident that this is not the end of the story, because Active Directory was invented in 1999, which means at some point we’ll have to deal with RC4.
Here’s the thing. Anytime you see cryptography born in the 1990s and yet using AES, you cannot be dealing with the original. What you’re looking at is the modernized, “upgraded” version of the original. The original probably used an abacus and witchcraft, or (failing that) at least some combination of unsalted hash functions and RC4. And here’s the worst part: it turns out that in Active Directory, when a user does not configure a Service account to use a more recent mode, then Kerberos will indeed fall back to RC4, combined with unsalted NT hashes (basically, one iteration of MD4.)
The main implication of using RC4 (and NT hashing) is that tickets encrypted this way become hilariously, absurdly fast to crack. According to our friend Chick3nman, the same RTX 5090 can attempt 4.18 billion (with a “b”) password guesses every second. That’s roughly 1000x faster than the AES variant.
As an aside, the NT hashes are not salted, which means they’re vulnerable to pre-computation attacks that involve rainbow tables. I had been meaning to write about rainbow tables recently on this blog, but had convinced myself that they mostly don’t matter, given that these ancient unsalted hash functions are going away. I guess maybe I spoke too soon? Update: see Tom Tervoort’s excellent comment below, which mentions that there is a random 8-byte “confounder” acting as a saltduring key derivation.
So what is Microsoft doing about this?
Clearly not enough. These “Kerberoasting” attacks have been around for ages: the technique and name is credited to Tim Medin who presented it in 2014 (and many popular blogs followed up on it) but the vulnerabilities themselves are much older. The fact that there are practical ransomware attacks using these ideas in 2024 indicates that (1) system administrators aren’t hardening things enough, but more importantly, (2) Microsoft is still not turning off the unsafe options that make these attacks possible.
The recommendations are all kind of dismal. They recommend that administrators should use proper automated key assignment, and if they can’t do that, then to try to pick “really good long passwords”, and if they can’t do that, to pretty please shut off RC4. But Microsoft doesn’t seem to do anything proactive, like absolutely banning obsolete legacy stuff, or being completely obnoxious and forcing admins to upgrade their weird and bad legacy configurations. Instead this all seems much more like a reluctant and half-baked bit of vulnerability management.
I’m sure there are some reasons why this is, but I refuse to believe they’re good reasons, and Microsoft should probably try a lot harder to make sure these obsolete services go away. It isn’t 1999 anymore, and it isn’t even 2014.
If you don’t believe me on these points, go ask Ascension Health.
Update 6/10: Based on a short conversation with an engineering lead at X, some of the devices used at X are claimed to be using HSMs. See more further below.
Matthew Garrett has a nice post about Twitter (uh, X)’s new end-to-end encryption messaging protocol, which is now called XChat. The TL;DR of Matthew’s post is that from a cryptographic perspective, XChat isn’t great. The details are all contained within Matthew’s post, but here’s a quick TL;DR:
There’s no forward secrecy. Unlike Signal protocol, which uses a double-ratchet to continuously update the user’s secret keys, the XChat cryptography just encrypts each message under a recipient’s long-term public key. The actual encryption mechanism is based on an encryption scheme from libsodium.
User private keys are stored at X. XChat stores user private keys at its own servers. To obtain your private keys, you first log into X’s key-storage system using a password such as PIN. This is needed to support stateless clients like web browsers, and in fairness it’s not dissimilar to what Meta has done with its encryption for Facebook Messenger and Instagram. Of course, those services use Hardware Security Modules (HSMs.)
X’s key storage is based on “Juicebox.” To implement their secret-storage system, XChat uses a protocol called Juicebox. Juicebox “shards” your key material across three servers, so that in principle the loss or compromise of one server won’t hurt you.
Matthew’s post correctly identifies that the major vulnerability in X’s system is this key storage approach. If decryption keys live in three non-HSM servers that are all under X’s control, then X could probably obtain anyone’s key and decrypt their messages.X could do this for their own internal purposes: for example because their famously chill owner got angry at some user. Or they could do it because a warrant or subpoena compels them to. If we judge XChat as an end-to-end encryption scheme, this seems like a pretty game-over type of vulnerability.
So in a sense, everything comes down to the security of Juicebox and the specific deployment choices that X made. Since Matthew wrote his post, I’ve learned a bit more about both of these things. In this post I’d like to go on a slightly deeper dive into the Juicebox portion of X’s system. This will hopefully shed some light on what X is up to, and why you shouldn’t use XChat.
What’s Juicebox even for?
Many end-to-end encryption (E2E) apps have run into a specific problem: these systems require users to store their own secret keys. Unfortunately, users are just plain bad at this.
Sometimes we forget keys because we lose our devices. Often we have more than one device, which means our keys end up in the wrong place. A much worse situation occurs when apps want to work in ordinary web browsers: this means that secret keys have to be airlifted into that context as well.
The obvious remedy for this problem is just to store secret keys with the service provider itself. This is convenient, but completely misses the whole point of end-to-end encryption, which is that service providers should not have access to your secrets! Storing decryption keys — in an accessible form — on the provider’s servers is absolutely a no-go.
One way out of this conundrum is for the user to encrypt their secret key, then upload the encrypted value to the service provider. In theory, they can download their secret keys anytime they want and they should know that their secrets are safe. But of course there’s a problem: what secret key are you going to use to encrypt your secret key!? Answering this question quickly leads you into an infinite pile of turtles.
Source: XKCD.
Rather than descend into paradox, systems like Juicebox, Signal SVR, and iCloud Key Vault offer an alternative. Their observation is that while cryptographic keys are hard to hang on to, users generally do remember simple passwords like PINs, particularly if they’re asked to re-enter them periodically. What if we use the user’s PIN/password to encrypt the stronger cryptographic key that we upload to the server?
While this is better than nothing, it isn’t good. Most human-selected passwords and PINs make for terrible cryptographic keys. In particular, short PINs (like the 6-digit decimal pins many people use for their phone passcode) are vulnerable to efficient brute-force guessing attacks. A six-digit PIN provides at most 220 security, which is what cryptographers call “a pretty small number.” Even if you use a “hard” key derivation function like scrypt or Argon2 with insane difficulty settings, you’re still probably still going to lose your data.
Fortunately there is another way.
For many years, cryptographers have considered the problem of turning “weak secrets” into strong ones. The problem is sometimes known as passwordhardening, and doing it well usually requires additional components. First, you need to have some strong cryptographic secret that can be “mixed” into the user’s password to make a produce a truly strong encryption key. Second, you need some mechanism to limit the number of guessing attempts that the user makes, so an attacker can’t simply run an online attack to work through the PIN-space. This cannot be enforced using cryptography alone: you must add a server (or servers) to enforce these checks. Critically, the server will place limits on how many incorrect passwords the user can enter: e.g., after ten incorrect attempts, the user’s account gets locked or erased.
In one sense, we’re right back where we started: someone needs to operate a a server. If that server is under the control of the service provider, then they can disable the guessing limits and/or extract the server’s secret key material, at which point you’re back to square one.
Many services have engineered some reasonable solutions to this problem, however. They boil down to the following alternatives, which can be implemented separately or together:
The server can be implemented inside of a specialized Hardware Security Module, which is set up so that the provider cannot reprogram it or access its key material (at least, after it’s been configured.) This approach was pioneered by Apple, and is now in use by iCloud Key Vault, Signal SVR, WhatsApp and Facebook Messenger.
Alternatively, the server can be “split up” into multiple pieces that are each run by different parties. The idea here is that the user must contact T out of N different servers in order to obtain the correct key (a common example is 2-of-3.) As long as an attacker cannot compromise T different servers, the combined system will still be able to enforce the guessing limits and prevent attackers from getting the key. Naturally this idea fundamentally depends on the assumption that the servers are not run by the same party!
And at last, we come to Juicebox.
Juicebox is an software-based distributed key hardening service that can be implemented across multiple servers. Users can “enroll” their account into the system, at which point the Juicebox servers will convert their PIN/password into a strong cryptographic key (by mixing it with a secret stored on the Juicebox servers.) Later on, they can contact the Juicebox servers and — assuming they enter the right password, and don’t try too many incorrect guesses — they can obtain that same cryptographic key from the system. Users can specify the number of servers (N) and the threshold (T), and the goal is that the system can survive the loss (or unavailability) of N-T servers, and it should retain its security even if an attacker compromises A<T of them. Most critically, Juicebox enforces limits: if too many incorrect passwords are entered, Juicebox will lock or destroy the user’s account.
In principle, Juicebox servers (called “realms” in the project’s lingo) can be either “software based” or they can be deployed inside of HSMs. However, to the best of my knowledge the HSM capability is not fully supported outside of Juicebox’s one test deployment, and has not been used in deployments (at X or anywhere else.) Update 6/10: but see further below! This means the security of XChat’s version of Juicebox probably comes down to a question of who runs the servers.
So who runs X’s Juicebox servers, and do they use HSMs?
To the best of my knowledge, all of the XChat servers are run in software by Twitter/X itself. If this turns out to be incorrect, I will be thrilled to update this post.
Update: this tweet by an engineering lead claims that they are actually HSMs, and Twitter has just not publicized this or published the key ceremonies that were used to set them up. I am very confused by this because it seems extremely backwards! The problem with this late claim is that there’s really no way to verify this fact other than one or two tweets from someone at X.
To put this more explicitly, without any protections like the verifiable use of HSMs and/or distributing Juicebox servers across mutually-distrustful operators, having three servers does relatively little to protect users’ secrets against the service operator. And even if X is secretly implementing these protections, implementing them in secret is stupid. As a wise man once said:
Verifying that the XChat Juicebox servers are software-only is more complicated. Digging around in the Juicebox Github, you’ll find a software-only as well as an HSM-specific implementation of their “realms.” Specifically, there is an entire repository dedicated to supporting Juicebox on Entrust nShield Solo XC HSMs (see here for instructions) although this same code can also be deployed outside of HSMs. There is even a cool “ceremony” document that a group of administrators can perform to certify that they set the HSM up correctly, and that they destroyed all of the cards that could allow it to be re-programmed!
Just one step from the Juicebox HSM ceremony document. I love this stuff!
However, after speaking to Juicebox’s protocol designer Nora Trapp, I’m doubtful that any of this is in use at X. Nora told me that the Juicebox project shut down over a year ago and the engineers moved on, and what code there is now open source and not actively maintained (this matches with project commits I can see.) Nora also looked at XChat’s Juicebox deployment and sent me the following commentary:
realm-a and realm-b are definitely software realms. They don’t use Noise (only true of software realms) and rely solely on TLS. In contrast, HSM-backed realms use Noise within TLS, with TLS terminated at the LB and Noise inside the HSM.
realm-east1 and realm-west1 appear to run code from juicebox-hsm-realm. For example, hitting https://realm-east1.x.com/livez shows they’re likely using the repo unmodified from main. However, this doesn’t mean they’re HSM-backed. The repo includes a “software HSM” for testing, which is insecure and doesn’t provide actual HSM properties.
Timing analysis (e.g. via the convenient x-exec-time response header X left in place) suggests these are indeed using the software HSM. Real HSMs are typically significantly slower. And even if by some chance they’re running real HSMs, no ceremony has been published, so there’s no reason to trust they’re secure or that the key material isn’t exfiltrated.
Obviously this doesn’t prove that X isn’t using HSMs. Though, obviously, there’s no reason that you should hope something is secure when the deployer is going out of their way not to tell you it is. When it comes to XChat, my advice is that you should assume this deployment is (1) entirely in software, and (2) all Juicebox “realms” are run by the same organization. This means you should assume that your decryption keys could be recovered by X’s server administrators with at most a little fuss, unless you use a very strong password.
That’s bad, but let’s talk more about the Juicebox protocol anyway!
If all you came for was a bit of discussion about the security posture of XChat, then Matthew’s post and the additional notes above are all you need. Unless and until X proves that they’re using HSMs (and have destroyed all programming cards) you should just assume that their Juicebox instantiation is based on software realms under X’s control, and that means it is likely vulnerable to brute-force password-guessing attacks.
The rest of this post is going to look past X.
Let’s assume that a deployer has configured Juicebox intelligently: meaning that some/all realms will be deployed inside of HSMs, and/or realms are spread across multiple organizational trust boundaries — such that no single organization can easily demand recovery of anyone’s password. The question we want to ask now is: what guarantees does Juicebox provide in this setting, and how does the protocol work?
Threshold OPRFs. The core cryptographic primitive inside of Juicebox is called a threshold oblivious pseudorandom function, or t-OPRF. I’ve written about OPRFs before, specifically in the context of Password-Authenticated Key Agreement (PAKE schemes.) Nonetheless, I think it’s helpful to start from the top.
Let’s leave aside the “oblivious” part for a minute. PRFs are functions that take in a key K and a string P (for example, a password), and output a string of bits. We might write as:
O = PRF(K, P)
Provided that an attacker does not know the key, the resulting string O should look random, meaning that the output of a PRF makes for excellent cryptographic keys. In many practical implementations, PRFs are realized using functions like HMAC or CBC-MAC; however, there are many different ways to build them.
An oblivious PRF (OPRF) is a two-party cryptographic protocol that helps a client and server jointly compute the output of a PRF. It works like this:
Imagine a server has the cryptographic key K.
The client has their string P (such as a password.)
At the end of a successful protocol run, the client should obtain O = PRF(K, P). The server gets no output at all.
Critically: neither party should learn the other party’s input, and the server should not learn the client’s result, either.
With this tool in hand, it’s easy to build a very simple password-hardening protocol. Simply configure the server with a key K (preferably a different key for every user account), and then have the client run the OPRF protocol with the server to obtain O = PRF(K, P). The resulting value O will make for an excellent encryption key, which the client can use to encrypt any secret values it wants. The best part of this arrangement is that the OPRF protocol ensures that the server never learns the user’s password P, so no information leaks even if the server is fully malicious!
This basic design has some limitations, of course. It does not allow the server to limit the number password guesses, nor does it allow us to spread the process over many different servers.
Addressing the first problem is easy. When the client first registers their account with the server, they can run the OPRF protocol to obtain O = PRF(K, P). Next, they compute some “authenticator tag” T that’s derived in some way from the secret O. They can then store that tag T on the server. When a user returns to log back into the system, the client and server can run the OPRF protocol, and then conduct some process to verify that the O received by the client is consistent with the tag T stored at the server. (The exact process for doing this is important, and I’ll discuss it further below.) If this is unsuccessful, then the server can increment a counter to indicate an incorrect password guess on that user’s account. If the protocol completes successfully, then the server should reset that counter back to zero.1
Critically, when the counter reaches some maximum (usually ten incorrect attempts), the server must lock the user’s account — or much better, delete the account-specific key K. This is what prevents attackers from systematically guessing their way through every possible PIN.
Splitting up the PRF into multiple servers is only slightly more complicated. The basic idea relies on the fact that the specific OPRF used by Juicebox is based on elliptic curves, and this makes it very amenable to threshold implementations. I’m going to put the details into a separate page right here since it’s a little boring. But you should just take away that (1) the service operator can split up the key K across multiple servers, and (2) a client can talk to any T of them and eventually obtain PRF(K, P).
How does the client prove it got the right key, and what attacks are there?
You’ll notice that these “incorrect attempt” counters are a big part of the protection inside of a system like Juicebox. As long as an attacker can only make, say, a maximum of ten incorrect guessing attempts, then even a relatively weak password like 234984 is probably not too bad. If an attacker can make many possible guesses, then the whole system is fairly weak.
Note that in most of these attacks we are going to make the very strong assumption that the server operator is the attackerand that they’ve deployed Juicebox in such a way that they can’t just read the secrets out of their own instance (e.g., in this hypothetical scenario, they have deployed Juicebox using HSMs or distributed trust.) Since the whole point of end-to-end encryption is that users’ secret keys should not be known to a server operator, this isn’t too strong of an assumption. Moreover, we’ve recently seen governments make secret requests to companies like Apple to force them to bypass their end-to-end encrypted services. This means that both hacking and legal compulsion are real concerns.
Within this setting there exist a handful of attacks that could come up in a system like Juicebox. Some are easier than others to prevent:
An attacker could try to enter a few password guesses, then wait for the real user to log in. As long as the real user enters the correct password, the attempt counter on the server(s) will drop back to zero. This attack could allow you to make up to, say, nine invalid guesses for each genuine user login.2
The existence of this attack is kind of unavoidable in systems like Juicebox. Fortunately it’s probably not a very efficient attack. Unless the user is logging on constantly (say, because a web browser caches the user’s password and runs the protocol automatically), the rate of attacker guesses is going to be very low. Moreover: this attack can be mitigated by having the server inform the client of the number of incorrect guesses it’s seen since the last time the user logged in, which should help the user to detect the fact that they’re under attack.
If the servers don’t coordinate with each other, a smart attacker could try to guess passwords against different subsets of the Juicebox servers: for example if 2-of-10 servers are needed to recover the key, then an attacker actually could actually obtain many more than ten guesses. This is because the attacker could make at least ten attempts with each subset comprising two servers, before all the necessary servers locked them out. Juicebox’s HSM implementation actually goes to some lengths to prevent this (as SVR did before them) by having servers share the current password counter values with each other using a consensus protocol.
Another possibility is that a malicious (software) server operator could try to attack the protocol directly. Just for fun, I thought it might be interesting to conclude with one possible attack I noticed while perusing the protocol description. I’m almost certain this won’t work in practice — and the Juicebox developers agree, but I thought it was a fun illustration of the types of vulnerabilities that show up in these systems.
Recall that whenever a Juicebox client successfully completes the protocol with a set of T servers, it must somehow convince those servers that it obtained the right key. This is necessary because a correct password entry should reset those servers’ attempt counters back to zero, whereas an incorrect guess will increase the attempt counter. (Without a mechanism to reset the counter, the counter will keep rising until the user’s account gets permanently locked.)
The client deals with this by first computing a value called the unlockKey from the t-OPRF output, and then calculating a set of “tags” called the unlockKeyTags, one for each server (realm) in the system:
The calculation of each unlockKeyTags[i] value is customized to include the “realm ID” of the server, which means that the tag for server i is specific only to that server. It cannot be extracted from a malicious server i and replayed against server j, which would be very bad. The client then sends each value unlockKeyTags[i] to the appropriate server. The servers can verify the received tag against a copy they stored during the account registration process. If it matches, they reset their counter back to zero as follows:
However, the only thing that differentiates these tags from one another is the notion that realm IDs for different servers will always be different. What if this assumption isn’t correct?
The attack I’m concerned about is pretty bizarre, but it looks like this. Imagine a user has previously registered its key into several real HSM-based servers. Now someone hacks into the service provider. This hacker “tricks” clients into sending subsequent login requests to a new set of malicious servers that the attacker spins up using software (i.e., no HSM protections.)
Ordinarily this attack wouldn’t be a disaster, since the OPRF should prevent those new servers from learning the user’s password inputs. But let’s imagine that the hacker sets the “realm ID” of these new servers to be identical to the realm ID of the real (HSM) servers. In this case, the value of unlockKeyTag[i] sent to the malicious servers will be identical to the value that would have been stored within the HSM-based servers. Once the attacker learns this value, they can make an unlimited number of guesses against the HSM server with the same realm ID: this is because the stolen unlockKeyTags[i] value will reset the HSM server’s counter.
I ran this past Nora and she pointed out a number of practical issues that will probably make this sort of attack much less likely to work, but it’s still fun to find this sort of thing. More importantly, I think it shows how delicate distributed protocols like this can be, and how sometimes one’s assumptions may not always be valid.
Post image: Noah Berger/AP Photo
Notes:
Obviously this can be dangerous. An attacker who just wants to deny service to the user can enter deliberately-incorrect guesses until the user’s account becomes permanently locked. To prevent this, most services require that you log In using a traditional password first, then you can access the password strengthening server second. Some systems also add time delays, to ensure that an attacker cannot quickly exhaust the counter.
The “try N attempts and then let the client log in normally” attack was outlined to me by Ian Miers.
This is a cryptography blog and I always feel the need to apologize for any post that isn’t “straight cryptography.” I’m actually getting a little tired of apologizing for it (though if you want some hard-core cryptography content, there’s plenty here and here.)
Sometimes I have to remind my colleagues that out in the real world, our job is not to solve exciting mathematical problems: it’s to help people communicate securely. And people, at this very moment, need a lot of help. Many of my friends are Federal employees or work for contractors, and they’re terrified that they’re going to lose their job based on speech they post online. Unfortunately, “online” to many people includes thoughts sent over private text messages — so even private conversations are becoming chilled. And while this is hardly the worst thing happening to people in this world, it’s something that’s happening to my friends and neighbors.
(And just in case you think this is partisan: many of the folks I’m talking about are Republicans, and some are military veterans who work for the agencies that keep Americans safe. They’re afraid for their jobs and their kids, and that stuff transcends politics.)
So let me get to the point of this relatively short post.
Apple iMessage is encrypted, but is it “secure”?
A huge majority of my “normie” friends are iPhone users, and while some have started downloading Signal app (and you should too!) — many of them favor one communications protocol: Apple iMessage. This is mostly because iMessage is just the built-in messaging app used on Apple phones. If you don’t know the branding, all you need to know is that iMessage is “blue bubbles” you get when talking to other Apple users.
But encryption in transit is only one part of the story. After delivering your messages with its uncompromising post-quantum security, Apple allows two things that aren’t so great:
iMessages stick around your phone forever unless you manually delete them (a process that may need to happen on both sides, and is painfully annoying.)
iMessages are automatically backed up to Apple’s iCloud backup service, if you have that feature on — and since Apple sets this up as the default during iPhone setup, most ordinary people do.
The combination of these two features turn iMessage into a Star-Trek style Captain’s Log of your entire life. Searching around right now, I can find messages from 2015. Even though my brain tells me this was three years ago, I’m reliably informed that this is a whole decade in the past.
Now, while the messages above are harmless, I want to convince you that this is often a very bad thing. People want to have private conversations. They deserve to have private conversations. And their technology should make them feel safe doing so. That means they should know that their messaging software has their back and will make sure those embarrassing or political or risque text messages are not stored forever on someone’s phone or inside a backup.
We know exactly how to fix this, and every other messenger did so long ago
I’m almost embarrassed to explain what this feature does, since it’s like explaining how a steering wheel works. Nevertheless. When you start a chat, you can decide how long the messages should stick around for. If your answer is forever, you don’t need to do anything. However, if it’s a sensitive conversation and you want it to be ephemeral in the same way that a phone call is, you can pick a time, typically ranging from 5 minutes to 90 days. When that time expires, your messages just get erased — on both your phone and the phones of the people you’re talking to.
A separate feature of disappearing messages is that some platforms will omit these conversations from device backups, or at least they’ll make sure expired messages can’t be restored. This makes sense because those conversations are supposed to be ephemeral: people are clearly not expecting those text messages to be around in the future, so they’re not as angry if they lose them a few days early.
Beyond the basic technical functionality, a disappearing messages feature says something. It announces to your users that a conversation is actually intended to be private and short-lived, that its blast radius will be contained. You won’t have to think about it years or months down the line when it’s embarrassing. This is valuable not just for what it does technically but for the confidence it gives to users, who are already plenty insecure after years of abuse by tech companies.
Why won’t Apple add a disappearing messages feature?
I don’t know. I honestly cannot tell you. It is baffling and weird and wrong, and completely out of step with the industry they’re embedded in. It is particularly bizarre for a company that has formed its entire brand image around stuff like this:
To recap, nearly every single other messaging product that people use in large numbers (at least here in the US) has some kind of disappearing messages feature. Apple’s omission is starting to be very unique.
I do have some friends who work for Apple Security and I’ve tried to talk to them about this. They usually try to avoid me when I do stuff like this — sometimes they mention lawyers — but when I’m annoying enough (and I catch them in situations where exit is impossible) I can occasionally get them to answer my questions. For example, when I ask “why don’t you turn on end-to-end encrypted iCloud backup by default,” they give me thoughtful answers. They’ll tell me how users are afraid of losing data, and they’ll tell me sad stories of how difficult it is to make those features as usable as unencrypted backup. (I half believe them.)
When I ask about disappearing messages, I get embarrassed sighs and crickets. Nobody can explain why Apple is so far behind on this basic feature even as an option, long after it became standard in every other messenger. Hence the best I can do is speculate. Maybe the Apple executives are afraid that governments will pressure them if they activate a security feature like this? Maybe the Messages app is written in some obsolete language and they can’t update it? Maybe the iMessage servers have become sentient and now control Tim Cook like a puppet? These are not great answers, but they are better than anything the company has offered — and everyone at Apple Security kind of knows it.
In a monument to misaligned priorities, Apple even spent time adding post-quantum encryption to its iMessage protocol — this means Apple users are now safe from quantum computers that don’t exist. And yet users’ most intensely private secrets can still be read off their phone or from a backup by anyone who can guess their passcode and use a search box. This is not a good place to be in 2025, and Apple needs to do better.
A couple of technical notes
Since this is a technical blog I feel compelled to say a few things that are just a tad more detailed than the plea above.
First off, Gene Hoffman points me to a small feature in the Settings of your phone called “Keep Messages” (buried under “Messages” in Settings, and then scrolling way down.) This determines how long your messages will be kept around on your own phone. You cannot set this per conversation, but you can set it to something shorter than “Forever”, say, one year. This is a big decision for some people to make, however, since it will immediately delete any old messages you actually cared about.
More importantly (as mentioned in comments) this only affects your phone. Messages erased via this process will remain on the phones of your conversation partners.
Second, if you really want to secure your iMessages, you should turn on Apple’s Advanced Data Protection feature. This will activate end-to-end encryption for your iCloud backups, and will ensure that nobody but you can access those messages.
This is not the same thing as disappearing messages, because all it protects is backups. Your messages will still exist on your phone and in your encrypted backups. But it at least protects your backups better.
Third, Apple advertises a feature called Messages in iCloud, which is designed to back up and sync your messages between devices. Apple even advertises that this feature is end-to-end encrypted!
I hate this phrasing because it is disastrously misleading. Messages in iCloud may be encrypted, however… If you use iCloud Backup without ADP (which is the default for new iPhones) the Messages in iCloud encryption key itself will be backed up to Apple’s servers in a form that Apple itself can access. And so the content of the Messages in iCloud database will be completely available to Apple, or anyone who can guess your Apple account password.
None of this has anything to do with disappearing messages. However: that feature, with proper anti-backup protections, would go a long way to make these backup concerns obsolete.
The British government’s undisclosed order, issued last month, requires blanket capability to view fully encrypted material, not merely assistance in cracking a specific account, and has no known precedent in major democracies. Its application would mark a significant defeat for tech companies in their decades-long battle to avoid being wielded as government tools against their users, the people said, speaking under the condition of anonymity to discuss legally and politically sensitive issues.
Apple’s decision to disable their encrypted cloud backup feature has triggered many reactions, including a few angry takes by Apple critics, accusing Apple of selling out its users:
With all this in mind, I think it’s time to take a sober look at what might really happening here. This will require some speculation and educated guesswork. But I think that exercise will be a lot more helpful to us if we want to find out what’s really going on.
Question 1: does Apple really care about encryption?
Encryption is a tool that protects user data by processing it using a key, so that only the holder of the appropriate key can read it. A variant called end-to-end encryption (E2EE) uses keys that only the user (or users) knows. The benefit of this approach is that data is protected from many threats that face centralized repositories: theft, cyber attacks, and even access by sophisticatedstate-sponsored attackers. One downside of this encryption is that it can also block governments and law enforcement agencies from accessing the same data.
Navigating this tradeoff has been a thorny problem for Apple. Nevertheless, Apple has mostly opted to err on the side of aggressive deployment of (end-to-end) encryption. For some examples:
In 2011, the company launched iMessage, a built-in messaging service with default end-to-end encryption for all users. This was the first widely-deployed end-to-end encrypted messaging service. Today these systems are recommended even by the FBI.
In 2013, Apple launched iCloud Key Vault, which encrypts your backed-up passwords and browser history using encryption that even Apple can’t access.
Apple faced law enforcement backlash on each of these moves. But perhaps the most famous example of Apple’s aggressive stance on encryption occurred during the 2016 Apple v. FBI case, where the company actively fought U.S. government’s demands to bypass encryption mechanisms on an iPhone belonging to an alleged terrorist. Apple argued that satisfying the government’s demand would have required Apple to weaken encryption on all of the company’s phones. Tim Cook even took the unusual step of signing a public letter defending the company’s use of encryption:
I wouldn’t be telling you the truth if I failed to mention that Apple has also made some big mistakes. In 2021, the company announced a plan to implement client-side scanning of iCloud Photos to search for evidence of illicit material in private photo libraries. This would have opened the door for many different types of government-enforced data scanning, scanning that would work even if data was backed up in an end-to-end encrypted form. In that instance, technical experts quickly found flaws in Apple’s proposal and it was first paused, then completely abandoned in 2022.
This is not intended to be a hagiography for Apple. I’m simply pointing out that the company has, in the past, taken major public risks to deploy and promote encryption. Based on this history, I’m going to give Apple the benefit of the doubt and assume that the company is not racing to sell out its users.
This was due to a critical feature of the new law: it enables the U.K. government to issue secret “Technical Capability Notices” that can force a provider, such as Apple, to secretlychange the operation of their system — for example, altering an end-to-end encrypted system so that Apple would be forced to hold a copy of the user’s key. With this modification in place, the U.K. government could then demand access to any user’s data on demand.
By far the most concerning part of the U.K. law is that it does not clearly distinguish between U.K. customers and non-U.K. customers, such as those of us in the U.S. or other European nations. Apple’s lawyers called this out in a 2024 filing to Parliament:
In the worst-case interpretation of the law, the U.K. might now be the arbiter of all cybersecurity defense measures globally. Her Majesty’s Government could effectively “cap” the amount of digital security that customers anywhere in the world can depend on, without users even knowing that cap was in place. This could expose vast amounts of data to state-sponsored attackers, such as the ones who recently compromised the entire U.S. telecom industry. Worse, because the U.K.’s Technical Capability Notices are secret, companies like Apple would be effectively forced to lie to their customers — convincing them that their devices are secure, when in fact they are not.
It goes without saying that this is a very dangerous road to start down.
Question 3: how might Apple respond to a broad global demand from the U.K.?
Let us imagine, hypothetically, that this worst-case demand is exactly what Apple is faced with. The U.K. government asks Apple to secretly modify their system for all users globally, so that it is no longer end-to-end encrypted anywhere in the world.
(And if you think about it practically: that flavor of demand seems almost unavoidable in practice. Even if you imagine that Apple is only being asked only to target users in the U.K., the company would either need to build this capability globally, or it would need to deploy a new version or “zone”1 for U.K. users that would work differently from the version for, say, U.S. users. From a technical perspective, this would be tantamount to admitting that the U.K.’s version is somehow operationally distinct from the U.S. version. That would invite reverse-engineers to ask very pointed questions and the secret would almost certainly be out.)
But if you’re Apple, you absolutely cannot entertain, or even engage with this possibility. The minute you engage with it, you’re dead. One single nation — the U.K. — becomes the governor of all of your security products, and will now dictate how they work globally. Worse, engage with this demand would open a hell-mouth of unfortunate possibilities. Do you tell China and Europe and the U.S. that you’ve given the U.K. a backdoor into their data? What if they object? What if they want one too?
There is nothing down that road but catastrophe.
So if you’re Apple and faced with this demand from the U.K., engaging with the demand is not really an option. You have a relatively small number of choices available to you. In order of increasing destructiveness:
Hire a bunch of very expensive lawyers and hope you can convince the U.K. to back down.
Shut down iCloud end-to-end encryption in the U.K. and hope that this renders the issue moot.
???
Exit the U.K. market entirely.
If we can believe the reporting so far, I think it’s safe to say that Apple has almost certainly tried the legal route. I can’t even imagine what the secret court process in the U.K. looks like (does it involve wigs?) but if it’s anything like the U.S.’s FISA courts, I would tend to assume that it is unlikely to be a fair fight for a target company, particularly a foreign one.
In this model, Apple’s decision to disable end-to-end encrypted iCloud Backup means we have now reached Stage 2. U.K. users will no longer be able to sign up for Apple’s end-to-end encrypted backup as of February 21. (We aren’t told how existing users will be handled, but I imagine they’ll be forced to voluntarily downgrade to unencrypted service, or else lose their data.) Any request for a backdoor for U.K. users is now completely moot, because effectively the system no longer exists for U.K. users.
At this point I suppose it remains to see what happens next. Perhaps the U.K. government blinks, and relaxes its demands for access to Apple’s keys. In that case, I suppose this story will sink beneath the waves, and we’ll never hear anything about it ever again, at least until next time.
In another world, the U.K. government keeps pushing. If that happens, I imagine we’ll be hearing quite a bit more about this in the future.
Apple already deploys a separate “zone” for many of its iCloud security products in China. This is due to Chinese laws that mandate domestic hosting of Apple server hardware and keys. We have been assured by Apple (in various reporting) that Apple does not violate its end-to-end encryption for the Chinese government. The various people I’d expect to quit — if that claim was not true — all seem to be still working there.