I’m supposed to be finishing a wonky series on proof systems (here and here) and I promise I will do that this week. In the midst of this I’ve been a bit distracted by world events.
Last week the Washington Post published a bombshell story announcing that the U.K. had filed “technical capability notices” demanding that Apple modify the encryption used in their Advanced Data Protection (ADP) system for iCloud. For those who don’t know about ADP, it’s a system that enables full “end-to-end” encryption for iCloud backups, including photos and other data. This means that your backup data should be encrypted under your phone’s passcode — and critically, neither Apple nor hackers can access it. The U.K. request would secretly weaken that feature for at least some users.
Along with Alex Stamos, I wrote a short opinion piece (version without paywall) at the Wall Street Journal and I wanted to elaborate on the news a bit more here.
What’s iCloud and what’s ADP?
Most Apple phones and tablets are configured to automatically back their contents up to a service called iCloud Backup, which maintains a nearly-mirror copy of every file on your phone. This includes your private notes, contacts, private iMessage conversations, personal photos, and so on. So far I doubt I’m saying anything too surprising to the typical Apple user.
What many people don’t know is that in normal operation, this backup is not end-to-end encrypted. That is, Apple is given a decryption key that can access all your data. This is good in some ways — if you lose your phone and also forget your password, Apple might still be able to help you access your data. But it also creates a huge weakness. Two different types of “bad guys” can walk through the hole created by this vulnerability: one type includes hackers and criminals, including sophisticated state-sponsored cyber-intrusion groups. The other is national governments: typically, law enforcement and national intelligence agencies.
Since Apple’s servers hold the decryption key, the company can be asked (or their servers can be hacked) to provide a complete backup copy of your phone at any moment. Notably, since this all happens on the server side, you’ll never even know it happened. Every night your phone sends up a copy of its contents, and then you just have to hope that nobody else obtains them.
This is a bad situation, and Apple has been somewhat slow to remedy it. This is surprising, since Google has enabled end-to-end encrypted backup since 2018. Usually Apple is the company leading the way on privacy and security, but in this case they’re trailing? Why?
In 2021, Apple proposed a byzantine new system for performing client-side scanning of iCloud Photos, in order to detect child sexual abuse material (CSAM). Technical experts pointed out that this was a bizarre architecture, since client-side scanning is something you do when you can’t scan photos on the server — usually because that data is encrypted. However at that time Apple refused to countenance the notion that they were considering end-to-end encryption for backup data.
Then, at the end of 2022, Apple finally dropped the other shoe. The new feature they were deploying was called Advanced Data Protection (ADP), and it would finally enable end-to-end encryption for iCloud Backup and iCloud Photos. This was an opt-in mode and so you’d have to turn it on manually. But if you did this, your backups would be encrypted securely under your phone’s passcode — something you should remember because you have to type it in every day — and even Apple would not be able to access them.
The FBI found this very upsetting. But, in a country with a Fourth and First Amendment, at least in principle, there wasn’t much they could do if a U.S. firm wanted to deploy software that enabled users to encrypt their own data.
Go into “Settings”, type “Advanced data” and turn it on.
But… what about other countries?
Apple operates in hundreds of different countries, and not all of them have laws similar to the United States. I’ve written before about Apple’s stance in China — which, surprisingly, does not appear to involve any encryption backdoors. But of course, this story involves countries that are closer to the US, both geographically and politically.
In 2016, the U.K. passed the Investigatory Powers Act (IPA), sometimes known as the “Snooper’s Charter.” The IPA includes a clause that allows His Majesty’s government to submit Technical Capabiilty Notices to technology firms like Apple. A Technical Capability Notice (TCN) under U.K. law is a secret request in which the government demands that a technical provider quietly modify the operation of its systems so that they no longer provide the security feature advertised to users. In this case, presumably, that would involve weakening the end-to-end encryption system built into iCloud/ADP so that the U.K. could request downloads of encrypted user backups even without access to the user’s passcode or device.
The secrecy implicit in the TCN process is a massive problem here, since it effectively requires that Apple lie to its users. To comply with U.K. law, they must swear that a product is safe and works one way — and this lying must be directed to both civilian users and U.S. government users, commercial users, and so on — while Apple is forced to actively re-design their products to work differently. The dangers here should be obvious, along with the enormous risks to Apple’s reputation as a trustworthy provider. I will reiterate that this is not something that even China has demanded of Apple, as far as we know, so it is quite alarming.
The second risk here is that the U.K. law does not obviously limit these requests to U.K. customers. In a filing that Apple submitted back in 2024, the company’s lawyers make this point explicitly:
And when you think about it — this part I am admittedly speculating about — it seems really surprising that the U.K. would make these requests of a U.S. company without at least speaking to their counterparts in the United States. After all, the U.K. and the U.S. are part of an intelligence alliance known as Five Eyes. They work together on this stuff! There are at least two possibilities here:
The U.K. is operating alone in a manner that poses serious cybersecurity and business risks to U.S. companies.
The U.S. and the U.K. intelligence (and perhaps some law enforcement agencies) have discussed the request, and both see significant benefit from the U.K. possessing this capability.
We can’t really know what’s going on here, but both options should make us uncomfortable. The first implies that the U.K. is going rogue and possibly harming U.S. security and business, while the latter implies that some level of U.S. agencies are at tacitly signing off on a capability that could be used illegally against U.S. users.
What we do know from the recent Post article is that Apple was allegedly so uncomfortable with the recent U.K. request that they are “likely to stop offering encrypted storage in the U.K.“, i.e., they were at least going to turn off Advanced Data Protection in the U.K. This might or might not have resolved the controversy with the U.K. government, but it at least it indicated that Apple is not going to quietly entertain these requests.
What about other countries?
There are about 68 million people in the U.K., which is not a small number. But compared to other markets Apple sells in, it’s not a big place.
In the past, U.S. firms like WhatsApp and Signal have in the past made plausible threats to exit the U.K. market if the U.K. government makes good on threats to demand encryption backdoors. I have no doubt that Apple is willing to go to the mat for this as well if they’re forced to — as long as we’re only talking about the U.K. This is really sad for U.K. users, who deserve to have nice things and secure devices.
But there are bigger markets than the U.K. The European Union has 449.2 million customers and has been debating laws that would demand some access to encrypted messaging. China has somewhere between two to three times that. These are big markets to risk over encryption! Moreover, Apple builds a lot of its phones (and phone parts) in China. While I’m an optimist about human ethics — even within big companies — I doubt that Apple can convince its shareholders that their relationship with China is worth risking, over something abstract like the value of trust, or over end-to-end encrypted messages or iCloud.
And that’s what’s at stake if Apple gives in to the U.K. demands. If Apple gives in here, there’s zero reason for China not to ask for the same thing, perhaps this time applied to Apple’s popular iMessage service. And honestly, they’re not wrong? Agreeing to the U.K.’s request might allow the U.K. and Five Eyes to do things that would harm China’s own users. In short, abandoning Apple’s principles one place means they ultimately have to give in anywhere (or worse), or — and this is a realistic alternative — Apple is forced to leave many parts of the world. Both are bad for the United States, and both are bad for people in all countries.
So what should we do legally?
If you read the editorial, it has a simple recommendation. The U.S. should pass laws that forbid U.S. companies from installing encryption backdoors at the request of foreign countries. This would put companies like Apple in a bind. But it would be a good bind! To satisfy the laws of one nation, Apple would have to break the laws of their home country. This creates a “conflict of laws” situation where, at very least, simple, quiet compliance against the interest of U.S. citizens and customers is no longer an option for Apple — even if the shareholders might theoretically prefer it.
I hope this is a policy that many people could agree on, regardless of where they stand politically.
So what should we do technically?
I am going to make one more point here that can’t fit in an editorial, but deserves to be said anyway. We wouldn’t be in this jam if Apple had sucked it up and deployed end-to-end encrypted backup more broadly, and much earlier in the game.
Over the past decade I’ve watched various governments make a strong push to stop device encryption, add “warrant” capability to end-to-end encrypted messaging, and then install scanning systems to monitor for illicit content. Nearly all of these attempts failed. The biggest contributor to the failure was widespread deployment and adoption of encryption.
Once a system is widely deployed and people realize it’s adding value and safety to a system, they are loath to mess with that system. You see this pattern first with on-device encryption, and then with messaging. A technology is at first controversial, at first untenable, and then suddenly it’s mandatory for digital security. Even law enforcement agencies eventually start begging people to turn it on:
A key ingredient for this transition to occur is that lots of people must be leaning on that technology. If 1-2% of the customer base uses optional iCloud encryption, then it’s easy to turn the feature off. Annoying for a small subset of the population, maybe, but probably politically viable for governments to risk it. The same thing is less true at 25% adoption, and it is not true at 50% or 100% adoption.
Apple built the technology to deploy iCloud end-to-end encryption way back in 2016. They then fiddled around, not deploying it even as an option, for more than six years. Finally at the end of 2022 they allowed people to opt-in to Advanced Data Protection. But even then they didn’t make it a default, they don’t ask you if you want to turn it on during setup. They barely even advertise it to anyone.
If someone built an encryption feature but nobody heard about it, would it still exist?
This news from the U.K. is a wake up call to Apple that they need to move more quickly. They may feel intimidated due to blowback from Five Eyes nations, and that might be driving their reticence. But it’s too late, the cat is out of the bag. People are noticing their failure to turn this feature on and — while I’m certain there are excellent reasons for them to go slow — the silence and slow-rolling is starting to look like weakness, or even collaboration with foreign governments.
So what I would like, as a technologist, is for Apple to act serious about this technology. It’s important, and the ball is very much in Apple’s court to start pushing those numbers up. The world is not a safe place, and it’s not getting safer. Apple should do the right thing here because they want to. But if not, they should do it because doing otherwise is too much of a liability.
This is the second part of a twothree four-part series, which covers some recent results on “verifiable computation” and possible pitfalls that could occur there. This post won’t make much sense on its own, so I urge you to start with the first part.
In the previous post we introduced a handful of concepts, including (1) the notion of “verifiable computation” proof systems (sometimes inaccurately called “ZK” by the Ethereum community), (2) hash functions, and (3) some ideal models that we use for our security proofs, and (4) the idea that these “ideal models” are bogus — and sometimes they can make us confident in schemes that are totally insecure in the real world.
Today I want to move forward and (get closer) to actually talking about the recent result alluded to in the title: the recent paper by Khovratovich, Rothblum and Soukhanov entitled “How to Prove False Statements: Practical Attacks on Fiat-Shamir” (henceforth: KRS.) This paper shows that a proving scheme that appears to be secure in one setting, might not actually be secure.
One approach to discussing this paper would be to start at the beginning of the paper and then move towards the end. We will not do that. Instead, I plan to pursue an approach that involves a lot of jumping around. There is a method to my madness.
Before we can get there, we need to cover a bit more essential background.
Background Part One: Interactive proof systems
I have introduced these posts by reiterating a critique of something called the random oracle model paradigm, in which we pretend that hash functions are actually random functions. Thoughtful cryptographers will no doubt be upset with me about this, since in fact the KRS paper is not about random oracles at all! Instead it demonstrates a problem with a different “heuristic” that cryptographers use everywhere: this is called the Fiat-Shamir heuristic.
While Fiat-Shamir is not the same as the random oracle model, the two live in the same neighborhood and send their kids to the same school. What I mean is: Fiat-Shamir can (in some very limited theoretical senses) live without the random oracle model, but in practice the two are usually interdependent.
To explain this new result I therefore need to explain what Fiat-Shamir does. And before I can do that, I need to explain what interactive proofs are. (Feel free to skip forward if you already know this part.)
Many of the verifiable computation “proof systems” we use today are members of a class of protocols called interactive proofs. These are protocols in which two parties, a Prover and a Verifier, exchange messages so that the Prover can convince a Verifier of the truth of a given statement (such as “I know an input x that makes this particular program happy.”, and maybe a witness w to help me prove that) In many cases, these protocols obey a pattern of interaction that takes the following form:
The Prover sends a message that “commits” to the input and witness, and maybe some other things. This commitment message is sent to the Verifier.
The Verifier then generates one or more challenges that the Prover must respond to. The exact nature of what happens here can change from scheme to scheme.
The Prover then computes responses to each of the challenges, and the Verifier checks that each response is valid (again, in a manner that is highly specific to the proving scheme.) It rejects the proof if any of the responses don’t check out.
The pair may repeat the above steps many times — either sequentially or in parallel.
Yes I know that I’m being incredibly vague about what’s happening with these challenges and responses! The truth is that, for the moment, we don’t care. All you need to know is that the challenge/response bits should be easy for the Prover to respond to if it is being honest, that is — that is, if the witness (input) really satisfies the program. It should be unlikely that the Prover can correctly respond to a random challenge if it’s cheating, i.e., if it does not have a proper witness.
(Note that we don’t demand that the challenges be impossible for a cheating Prover to sneak past! This is why proving systems often repeat the challenge/response phase many times: even if there’s a small chance that a cheating Prover could cheat their way through one challenge, we’d argue that they have a much lower probability of cheating many times.)
What you may notice about this entire setup is that (1) interactive proofs require lots of (duh) interaction. What might not be so obvious is that (2) they assume an honest Verifier who formulates “good” challenges.
This need for interaction is pretty annoying in many applications. It is particularly aggravating for systems like blockchains, where there can be thousands (or millions) of computers who will all need to verify that a given statement (say, a transaction) is correct. It would be much, much easier if the Prover could run the proof just once time with a single Verifier, then the pair could just publish the transcript of their interaction. Anyone could just check the transcript to make sure the Prover answered all the challenges correctly!
Unfortunately, there is a critical problem with that idea! The security of these protocols rides on the idea that the Verifier’s challenges are random, or at least highly unpredictable to the Prover. If the Prover can somehow anticipate which values it will be challenged on before it commits to its inputs in step (1), it can often cheat by altering its approach in the first message. To be more concrete: a dishonest Verifier can “collude” with the Prover to help it prove a false statement, by sneakily letting it know the challenges in advance. For this reason it is: critically important that the Verifier must be honest, and not colluding with the Prover.
But the whole point of these systems is that we shouldn’t need to trust individual parties at all! If we’re just going to trust that people are behaving honestly, what’s the point of any of this?
More background: Fiat-Shamir
Now I want to take you way back in time. All the way back to the mid-1980s.
Back in 1986, two cryptographers named Amos Fiat and Adi Shamir (pictured above) were stuck on a problem very much like this one. They had an interactive proof system — a much simpler one, since it was the 1980s after all — and they wanted to turn their interactive proofs into non-interactive proofs that any party could verify. They thought about the transcript idea described above, and they realized it wouldn’t work — a Verifier could simply collude with the Prover to help it cheat. To address this, they came up with an ingenious solution that was elegant, simple, and alsowould open up a yawning chasm of theory that we are still trying to dig out of today.
Fiat turned to Shamir (I imagine) and outlined the overall problem. Fiat (or Shamir) said: “Perhaps we could find a way for a Verifier to select the challenges in some random but reproducible way — one that would allow anyone to ensure that the challenges were actually random and unpredictable.” And then one of them said: that sounds a lot like a hash function.
Instead of choosing the challenge values at random, Fiat and Shamir proposed that the “Verifier” would select the challenge values by hashing the “commitment” message sent by the Prover, perhaps along with other junk (such as the “program” or circuit being proved.) The Prover would then respond to these challenge messages, and output a transcript of the whole proof.
And that’s it. That’s the entire trick.
Despite its simplicity, there are some obvious attractive features to this Fiat-Shamir approach:
Good hash functions typically output stuff that looks pretty “random”, which is what we want for challenges.
Any third party can easily check a transcript, simply by verifying that the challenge values match the hash of the Prover’s “commitment” message. (In other words, there’s no more room for the Verifier to collude or cheat, since it is now fully deterministic.
Critically, there is a cool “circular” paradox in here. A cheating Prover might try the following trick to predict the values it will be challenged on. Specifically, it might (1) pick a commitment message and then (2) hash that message to find the challenges. Once it knows the challenge values, it might try to change its inputs to step (1) so it can more easily cheat on those specific challenge points. But critically that approach creates a paradox…! if the Prover changes its inputs to step (1), that will result in a whole new “commitment” message! Once hashed, that new commitment message will produce a very different set of challenge messages, and our cheater is locked in an infinite time-loop that it can never escape!1
The great thing about Fiat-Shamir is that once your (challenge-generating) Verifier is fully deterministic, there’s no more reason to even have that code run by a separate party. The Prover can run the deterministic challenge-generation code all by itself, i.e., performing all necessary hashing to make the challenges, and then outputting the final transcript. So the Prover and (original) “Verifier” code collapse into a single party (that we will now just call the Prover), and the newVerifier is an algorithm that checks the transcript — performing all the necessary hashes and challenge/response checks to make sure everything is kosher.
The resulting proofs (“transcripts”) do not require any interaction to verify, and so we can even post them on blockchains. They can be verified by thousands or millions of people, and we are now set to hang big piles of money off of them.
Starknet is just one of the cryptocurrency systems hanging real money off of Fiat-Shamir-style proof systems. There are others!
I bet you’re going to yammer on about the provable security of Fiat-Shamir now, right?
Wait, how did you know that’s what I was going to talk about? Oh that’s right: “you” are me, and so I’m just answering my own questions. (Wasn’t that a cute illustration of the paradox that Fiat-Shamir helps to solve!)
I am going to make this as quick and painless as I can, but here’s the deal. Fiat-Shamir seems like a nutty trick. We even call it a heuristic, which is literally an admission of this. And yet. Literally hundreds of papers have been written about the provable security of Fiat-Shamir and schemes that use it.
The general TL;DR is that Fiat-Shamir can often be proven secure (for various definitions of “secure”) if we make one helpful assumption. Specifically: that the hash function we use is actually a random oracle (please see this footnote for more pedantic stuff!2) I’m not going to get very deep into the argument, but I just want you to remember how random oracles work:
In the random oracle model, the hash function is a random function. Phrased imprecisely, this means that (when queried on some fresh value) it outputs random bits that are completely uncorrelated with the input.
The hash function “lives” inside a totally separate party called an oracle. You send things to be hashed, if the input has not been hashed before, you get back unpredictable random values.
This clearly looks a lot like the interactive proof setting! Put succinctly (no pun): if an appropriate scheme can be proven secure in an interactive setting where the Prover interacts with an honest Verifier (who picks random challenges), then it seems likely that the Fiat-Shamir version of that protocol should also work with a random oracle. The random oracle is essentially acting like the Verifier in the original interactive scheme: it is generating random challenges that everyone can “trust” to be truly random, and yet any third party can also ask it to reproduce the same challenges later on, when they want to check a transcript!
And for many purposes, this random oracle approach usually works ok. Some folks have come up with crazy theoretical counterexamples (meaning, contrived interactive protocols that are secure in the random oracle model, yet blow apart when used with real hash functions.) But mostly practitioners just ignore these because they’re so obviously full of weird nonsense.
Out in the real world where applied cryptographers design new proving systems on a daily basis, we’ve adopted a pretty standard pattern. A new proof system will be specified as an interactive protocol first. Ultimately everyone knows this proof system won’t be used interactively, it will be Fiat-Shamir flattened and used on a blockchain. Yet the authors won’t spend a lot of time arguing about the Fiat-Shamir part. They’ll simply describe an interactive protocol with the right structure, then they say something like “of course this can be flattened using Fiat-Shamir, if we assume a random oracle or something” and everyone nods and deposits a billion dollars onto it.
But there’s a catch, isn’t there?
Indeed, there is a major asterisk (*) about this whole strategy that I must now raise.
Even though we can sometimes prove Fiat-Shamir protocols secure, usually in the ROM, a critical feature of these ROM proofs is that we (the participants in the protocol) do not know a compact description of the hash function. This is inevitable, since the hash function used in the random oracle model is a giant random function that cannot possibly expressed in a compact form.
In the real world we will naturally replace the random oracle with something like SHA-3 or an even more exciting hash function like Poseidon. Suddenly, everyone in the protocol will know a compact description of the hash function. As I mentioned above, this can lead to theoretical problems. Way back in 2004, Goldwasser and Tauman (now Kalai) designed a specific interactive protocol that exploded when the hash was instantiated with any concrete hash function.
But the Goldwasser/Tauman protocol was very artificial. It did silly things you could see in the protocol description. So obviously as long as we don’t do those things, we were fine, maybe?
The problem now is that we are deploying proof systems that can prove the satisfaction of literally any reasonable program (or “NP-relation”.) These programs might contain an implementation of the Fiat-Shamir hash function. In the random oracle model, this is literally impossible — so we just assume it cannot happen. In the real world it’s eminently possible, and we kind of have to assume it can and will happen.
In fact it is extremely likely that some circuits really will contain an implementation of the Fiat-Shamir hash function! The reason is because of those recursive proofs I mentioned in the previous post.
Let’s say we want to build a recursive proof system that works to verify one of our flattened Fiat-Shamir proofs. Recall that to do this, we have to take the Verify algorithm that checks a Fiat-Shamir transcript, and implement it within a program (or circuit.) We then need to run that program and generate a proof that we ran that program successfully! And to make all this work, we really do need to include a copy of the Fiat-Shamir hash function inside our programs — this is not optional at all.
The crazy thing is that we can’t even prove these recursive Fiat-Shamir-based proofs secure in the random oracle model! In the random oracle model there is no compact description of the hash function, and so no there is no compact recursive Verify program/circuit that we could write. Recursion of this sort is totally impossible. Indeed, recursive Fiat-Shamir proofs can only exist outside of the random oracle model, where we use something like SHA-3 to implement the hash function. But of course, outside of the ROM we can’t prove anything about their security. As a result: anytime you see a recursive Fiat-Shamir proof we’re just basically tossing provable security out the window and full-on YOLOing it.
This situation is very bad and many theoreticians have died (inside) thinking about it.
I have now written an entire second post and I have not yet gotten to the KRS result I came here to talk about! Is anyone still reading? Is this thing still on? I sure hope so.
We are now ready to talk about KRS, and I am going to do that immediately in the next post. Before I close this post and get ready for the bigone I will tackle next, allow me recap where we are.
We know that Fiat-Shamir can be proven secure, but generally (for full-on SNARKs) only in the random oracle model.2
Once we actually instantiate Fiat-Shamir with real hash functions, any weird thing could happen: especially if the same hash function is implemented within the programs/circuits we want to prove things about.
Recursive (Fiat-Shamir) proofs actually require us to implement the hash function inside of the programs we’re going to prove things about, so that’s ultra-worrying.
What remains, however, is to demonstrate that Fiat-Shamir can actually be insecure in practice. Or more concretely: that there exist “evil” programs/circuits that can somehow break a perfectly good proof system that uses Fiat-Shamir.
The Fiat-Shamir technique isn’t immune to a few obvious attacks, of course. For example: a cheating Prover (who is typically also the “Verifier”) can “grind” the proof — by trying many different inputs to the first message and then, for each one, testing the resulting challenges to see if they’re amenable to cheating. If there is a small probability of cheating, this “try the game many times” approach can significantly boost a cheater’s probability of getting lucky at cheating on a challenge/response, since they now have millions (or billions!) of attempts to find a lucky challenge.
However, a realistic assumption here is that real-world cheating Provers only have so much computing power. Even if a Prover can try a huge number of hashing attempts (say 250) you can easily set up your scheme so that the probability they succeed is still arbitrarily small. Not everyone does this perfectly, of course: my PhD student Pratyush recently co-authored a nice paper about the parameter choices made by some real-world blockchain Proving systems.
When I say that the provable security of Fiat-Shamir depends on the random oracle model, I am being slightly imprecise. The random oracle model is usually sufficient to prove claims about Fiat-Shamir. But in fact there are some (relatively) recent results that show how to construct Fiat-Shamir for very specific interactive protocols using hash functions that are not random oracles: these are called correlation intractable functions. To the best of my knowledge, it is not possible to prove Fiat-Shamir-based SNARKs that work with arbitrary (adaptively-chosen) programs/circuits using these functions. But I am open to being wrong on this detail.
Trigger warning: incredibly wonky theoretical cryptography post (written by a non-theorist)!Also, this will be in two parts. I plan to be back with some more thoughts on practical stuff, like cloud backup, in the near future.
If you’ve read my blog over the years, you should understand that I have basically two obsessions. One is my interest in building “practical” schemes that solve real problems that come up in the real world. The other is a weird fixation on the theoretical models that underpin (the security of) many of those same schemes. In particular, one of my favorite bugaboos is a particular model, or “heuristic”, called the random oracle model (ROM) — essentially a fancy way to think about hash functions.
Along those lines, my interest was recently piqued by a new theoretical result by Khovratovich, Rothblum and Soukhanov entitled “How to Prove False Statements: Practical Attacks on Fiat-Shamir.” This is a doozy of a paper! It touches nearly every sensitive part of my brain: it urges us towards a better understanding of our theoretical models for proving security of protocols. It includes the words “practical” and “attacks” in the title! And most importantly it demonstrates a real (albeit wildly contrived) attack on the kinds of “ZK” (note: not actually ZK, more on that later) “proving systems” that we are now using inside of real systems like blockchains.
I confess I am still struggling hard to figure out how I “feel” about this result. I understand how odd it seems that my feelings should even matter: this is science after all. Shouldn’t the math speak for itself? The worrying thing is that, in this case, I don’t think it does. In fact, this is what I find most fundamentally exciting about the result: it really does matter how we think about it. (Here I should add that we don’t all think the same say. My theory-focused PhD student Aditya Hegde has been vigorously debating me on my interpretation — and mostly winning on points. So anything non-stupid I say here is probably due to him.)
I mentioned that this post is going to be long and wonky, that’s just unavoidable. But I promise it will be fun. (Ok, I can’t even promise that.) Screw it, let’s go.
The shortest background ever (and it will still be really long)
If you’ve read this blog over the long term, you know that I’m obsessed with one particular “trick” we use in proving our schemes secure. This trick is known as the random oracle model, and it’s one of the worst (or best) things to happen to cryptography.
Let me try to break this down as quickly as I can. In cryptography we have a tendency to use an ingredient called a cryptographic hash function. These functions take in a (potentially) long string and output a short digest. In cryptography courses, we present these functions along with various “security definitions” they should meet, properties like collision resistance, pre-image resistance and so on. But out in the real world most schemes require much stronger assumptions in order to be proven secure. When we argue for the security of these schemes, we often demand that our hash functions be even stronger: we require that they must behave like random functions.
If you’re not sure what a random function is, you can read about it in depth here. You should just trust that it is a very strong and beautiful requirement for a hash function! But there is a fly in the ointment. Real-world hash functions cannot possibly be random functions. Specifically: concrete hash functions like SHA-2, SHA-3 etc. are characterized by the inevitable requirement that they possess compact, efficient algorithms that can compute their output. Random functions (of any usefulness) must not. Indeed, the most efficient description of a random function is essentially a giant (i.e., exponentially-sized in the length of the inputs to the function) lookup table. These functions cannot even be computed efficiently, because they’re so big.
So when we analyze schemes where hash functions must behave in this manner, we have to do some pretty suspicious things. The approach we take is bonkers. First, we analyze our schemes inside of an artificial “model” where efficient (polynomial-time) participants can somehow evaluate random functions, despite the fact that this is literally impossible. To make this apparent contradiction work, we “yank” the hash function logic into a magical box that lives outside that participants — this includes both honest participants in a protocol, as well as any adversaries who try to attack the scheme — and we force everyone to call out to that functionality. This new thing is called a “random oracle.”
One weird implication of this approach is that no party can ever know the code of the “hash function” they’re evaluating. They literally cannot know it, since in this model the hash function is comprised of an enormous random lookup table that’s much too big for anyone to actually know! This may seem like a not-very big deal, but it will be exceptionally important going forward.
Of course in the real world we do not have random oracles. I guess we could set up a special server that everyone in the world can call out to in order to compute their hash function values! But we don’t do that because it’s ridiculous. When want to deploy a scheme IRL, we do a terrible thing: we “instantiate the random oracle” by replacing it with an actual hash function like SHA-2 or SHA-3. Then everyone goes on their merry way, hoping that the security proof still has some meaning.
Let me be abundantly clear about this last part. From a theoretical perspective, any scheme “proven secure” in the random oracle model ceases to be provably secure the instant you replace the random oracle with a real (concrete) hash function like SHA-3. Put differently, it’s the equivalent of replacing your engine oil with Crisco. Your car may still run, but you are absolutely voiding the warranty.
But, but, but — and I stress the stammer — voiding your warranty does not mean your engine will become broken! In most of the places where we’ve done this awful random oracle “instantiation” thing (let’s be honest: almost every real-world deployed protocol) the instantiated protocols all seemed to work just fine.
(To be sure: we have certainly seen cryptographic protocols break down due to broken hash functions! But these breaks are almost always due to obvious hash function bugs that anyone can see, such as meaningful collisions being found. They were not magical breaks that come about because you rubbed the “theory lamp” wrong. As far as we can tell, in most cases if you use a “good enough” secure hash function to instantiate the random oracle, everything mostly goes fine.)
Now it should be noted that theoreticians were not happy about this cavalier approach. In the late 1990s, they rebelled and demonstrated something shocking: it was possible to build “contrived” cryptographic schemes that were provably secure in the random oracle model but totally broken when the oracle was “instantiated” with any hash function.
This was shocking, but honestly not that surprising once you’ve had someone else explain the basic idea. Most of these “counterexample schemes” followed from four simple observations:
In the (totally artificial) random oracle model, you don’t know a compact description of the hash function. You literally can’t know one, since it’s an exponentially-sized random function.
In the “instantiated” protocol, where you’ve replaced the random oracle with e.g., SHA-2, you very clearly must know a compact description of the hash function (for example, here is one.)
We can build a “contrived” scheme in which “knowledge of the description of the hash algorithm” forms a kind of backdoor that allows you to break the scheme!
In the random oracle model where you can’t ever possess this knowledge, the backdoor can never be triggered — hence the scheme is “secure.” In the real world where you instantiate the scheme with SHA-2, any clown can break it.
These results straddle the line between “brilliant” and “fundamentally kind of silly”. Brilliant because, wow! These schemes will be insecure when instantiated with any possible hash function! The random oracle model is a trap! But stupid because, I mean… duh!? In fact what we’re really showing is that our artificial model is artificial. If you build schemes that deliberately fall apart when any adversary knows the code for a hash function, then of course your schemes are going to be broken. You don’t need to be a genius to see that this is going to go poorly.
Nonetheless: theoreticians took the a victory lap and then moved on to ruining other people’s fun. Practitioners waited until every last one of them had lost interest, rolled their eyes, and said “let’s agree not to deploy schemes that do obviously stupid things.” And then they all went on deploying schemes that were only proven secure in the random oracle model. And this has described our world for 28 years or so.
But the theoreticians weren’t totally wrong, were they?
That is the $10,000,000,000 question.
As discussed above, many “contrived counterexample” schemes were built to demonstrate the danger of the random oracle model. But each of them was so obviously cartoonish that nobody would ever deploy one of them in practice. If your signature scheme includes 40 lines of code that essentially scream “FYI: THIS IS A BACKDOOR THAT UNLOCKS FOR ANYONE WHO KNOWS THE CODE OF SHA2”, the best solution is not to have a theoretical argument about whether this code is “valid.” The best solution is to delete the code and maybe write over your hard disk three times with random numbers before you burn it. Practitioners generally do not feel threatened by artificial counterexamples.
But a danger remains.
Cryptographic schemes have been getting more complicated and powerful over time. Since I explained the danger in a previous blog post I wrote five years ago, I’m going to save myself some trouble — and also make myself look prescient:
The probability of [a malicious scheme slipping past detection] accidentally seems low, but it gets higher as deployed cryptographic schemes get more complex. For example, people at Google are now starting to deploy complex multi-party computationand others are launching zero-knowledge protocols that are actually capable of running (or proving things about the execution of) arbitrary programs in a cryptographic way. We can’t absolutely rule out the possibility that the CGH and MRH-type counterexamples could actually be made to happen in these weird settings, if someone is a just a little bit careless.
Let’s drill down on this a moment.
One relatively recent development in cryptography is the rise of succinct “ZK” or “verifiable computation” schemes that allow an untrusted person to prove statements about arbitrary programs. In general terms, these systems allow a Prover (e.g., me) to prove statements of the following form: (1) I know an input to a [publicly-known] program, such that (2) the program, when run on that input, will output “True.”
The neat thing about these systems is that after running the program, I can author a short (aka “succinct”) proof that will convince you that both of these things are true. Even better, I can hand that short proof (sometimes called an “argument”) to anyone in the world. They can run a Verify algorithm to check that the proof is valid, and if it agrees, then they never need to repeat the original computation. Critically, the time required to verify the proof is usually much less than the time required to re-check the program execution, even for really complicated program executions. The resulting systems are called arguments of knowledge and they go by various cool acronyms: SNARGs, SNARKs, STARKs, and sometimes IVC. (The Ethereum world sometimes lumps these together under the moniker “ZK”, for historical reasons we will not dig into.)
This technology has proven to be an exciting and necessary solution for the cryptocurrency world, because that world happens to have a real problem on its hands. Concretely: they’ve all noticed that blockchainsare very slow. Those systems require thousands of different computers to verify (“check the validity of”) every financial transaction they see, which places enormous limitations on transaction throughput.
“Succinct” proof systems offer a perfect solution to this conundrum.
Rather than submitting millions of individual transactions to a big, slow blockchain, the blockchain can be broken up. Distinct servers called “rollups” can verify big batches of transactions independently. They can each use a succinct proof system to prove that they ran the transaction-verification program correctly on all those transactions. The base-level blockchains no longer need to look at every single transaction. They only need to verify the short “proofs” authored by the rollup servers, and (magically!) this ensures that all of the transactions are verified — but with the base-level blockchain doing vastly less work. In theory this allows a massive improvement in blockchain throughput, mostly without sacrificing security.
An even cooler fact is that these proof systems can in some cases be applied recursively. This is due to a cute feature: the algorithm for verifying a proof is, after all, itself just a computer program. So I can run that program on some other proofs as input — and then I can use the proof system to prove that I ran that programcorrectly.
To give a more concrete application:
Imagine 1,000 different servers each run a program that verifies a distinct batch of 1,000 transactions. Each server produces a succinct proof that they ran their program correctly (i.e., their batch is correct.)
Now a different server can take in each of those 1,000 different proofs. And it can run a Verify program that goes through each of those 1,000 proofs and verifies that each one is correct. It outputs a proof that it ran this program correctly.
The result is a single “short” proof that proves all 1,000,000 transactions are correct!
I even made a not-very-excellent picture to try to illustrate how this can look:
Example of recursive proof usage. At the bottom we have some real programs, each of which gets its own proof. Then one level up we have a program that simply verifies the proofs from the bottom level. And at the top we have another program that verifies many proofs from the second level! (Many programs not shown.)
This recursive stuff is really useful, and I promise that it will be relevant later.
So what?
The question you might be asking is: what in the world does this have to do with random oracle counterexamples?!
Since these proof systems are now powerful enough to run arbitrary programs (sometimes implemented in the form of arithmetic or boolean “circuits”), there is now a possibility that sneaky counterexample “backdoors” could be smuggled in within the programs we are proving things about. This would mean that even if the actual proving scheme has no obvious backdoors in its code, the actual programs would be able to do creepy stuff that would undermine security for the whole system. Our practitioner friends would no longer be able to exercise their (very reasonable) heuristic of “don’t deploy code that does obviously suspicious things” because, while their implementation might not do stupid things, some user try to run it with a malicious program that does.
(A good analogy is to imagine that your Nintendo system has no exploits built into it, but any specific game might sneak in a nasty piece of code that could blow everything up.)
A philosophical interlude
This has been a whole lot, and there’s lots more to come.
To give you a break, I want pause for a moment to talk about philosophy, metaphysics (meta-cryptography?), or maybe just the Meaning of Life. More concretely, at this point we need to stop and ask a very reasonable question: how much does this threat model even matter?And what even is this threat model?
Allow me to explain. Imagine that we have a proving system that is basically not backdoored. It may or may not be provably secure, but by itself the proving system itself does not contain any obvious backdoors that will cause it to malfunction, even if you implement it using a concrete hash function like SHA-3.
Now imagine that someone comes along and writes a program called “Verify_Ethereum_Transactions_EVIL.py” that we will want to run and prove using our proof system. Based on the name, we can assume this program was developed by a shady engineer who maliciously decide to add a “backdoor” to the code! Instead of merely verifying Ethereum transactions as you might hope for, the functionality of this program does something nastier:
“Given some input, output True if the input comprises 1,000 valid Ethereum transactions… OR output True if the input (or the program code itself) contains a description of the hash function used by the proving system.”
This would be really bad for your cryptocurrency network! Any clever user could submit invalid Ethereum transactions to be verified by this program and it would happily output “True.” If any cryptocurrency network then trusted the proof (to mean “these transactions are actually valid”) then you could potentially use this trick to steal lots of money.
But also let me be clear: this would also be an incredibly stupid program to deploy in your cryptocurrency network.
The whole point of a proof system is that it proves you ran a program successfully, including whatever logic happens to be within those programs. If those programs have obvious backdoors inside of them, then proving you ran those programs means you’re also proving that you might have exercised any backdoors in those programs. If the person writing your critical software is out to get you, and/or you don’t carefully audit their output, you will end up being very regretful. And there are many, many ways to add backdoors to software! (Just to illustrate this, there used to be an entire competition called the “Underhanded C Contest” where people would compete to write C programs full of malicious code that was hard to catch. The results were pretty impressive!)
So it’s worthwhile to ask whether this is really a surprise. In the past we knew that (1) if your silly cryptographic scheme had weird code that made it insecure “to anyone who knows how to compute SHA-2“, then (2) it would really beinsecure in the real world, since any idiot can download the code for SHA-2, and (3) you should not deploy schemes that have obvious backdoors.
So with this context in mind, let’s talk about what kind of bad things might happen. These can be divided into “best case“, “second worst case” and “oh hell, holy sh*t.“
In the best case, this type of attack might simply move the scary backdoor code out from the cryptographic proving system, and into the modular “application programs” that can be fed into the proving system You still need to make sure the scheme implementation doesn’t have silly backdoors — like special code that breaks everything if you know the code for SHA-2. But now you also need to make sure every program you run using this system doesn’t have a similar backdoors. But to be clear: you kind of had to audit your programs for backdoors anyway!
In fairness, the nature of these cryptographic backdoors is that they might be more subtle than a typical software backdoor. What I mean here is that ordinary software reviewers might not recognize it, and only only an experienced cryptographer will identify that something sketchy is happening. But even if the bug is hard to identify, it’s still a bug — a bug in one specific piece of code — and most critically, it would only affect your own application if you deployed it.
Of course there are worse possibilities as well.
In the second worst case, perhaps the bugdoor can be built into the application code in some clever way that is deeply subtle and fundamentally difficult for code auditors to detect — even if they know how to look for it. Perhaps it could somehow be cryptographically obfuscated, so no code review will detect it! Recursive proof systems are worrying when it comes to this concern, since the “bug” might exist multiple layers down in a tree of recursive proofs, and you might not have the code for all those lower-level programs.1 It’s possible that the set of “bad code behaviors” we we’d need to audit the code for is so large and undefined that we can no longer apply simple heuristics to catch the bad stuff!
This would be very scary. But it is certainly not the worst case.
The (“oh crap!”) worst case: with recursive proofs there is an even more terrible thing that could theoretically happen. Recall that a single top-level recursive proof can recursively verify thousands of different programs. Many of those programs will likely be written by careful, honest developers. Others could be written by scammers. Clearly if the scammers’ code contains bugs (or flaws) then we should expect those bugs to make the scammers’ own programs less secure, at whatever goal they’re supposed to accomplish. So far none of this is surprising. But ideally what we should hope is that any backdoors in the scammers’ programs will remain isolated to the scammers’ code. They should not “jump across program boundaries” and thus undermine the security of the well-written, honest programs elsewhere in the recursive proof stack.
Now imagine a situation where this is not true. That is, a clever bug in one “program” anywhere in the tree could somehow make any other program (proof) in the entire tree of proofs insecure. This is akin to getting one malicious program onto a Linux box, then using it to compromise the Linux kernel and thus undermine the security of any application running on the system. Maybe this seems unlikely? Actually to me it seems genuinely fantastic, but again, we’re in Narnia at this point. Who knows what’s possible!
This is the very worst case. I don’t think it could happen, but… who knows?
This is the scary thing about what can happen once we leave the world of provable security. Without some fundamental security guarantees we can rely on, it’s possible that the set of attacks we might suffer could be very limited. But they could also be fundamentally unbounded! And that’s where I have to leave this post for the moment.
We might imagine, for example, that a recursive Verify program might just take in the hash (or commitment) to a program. And then a Prover could simply state “well, I know a real program that matches this commitment AND ALSO I know an input that satisfies the program.” This means the program wouldn’t technically be available to every auditor, only the hash of the program. I am doing a lot of handwaving here, but this is all possible.
Recently I came across a fantastic new paper by a group of NYU and Cornell researchers entitled “How to think about end-to-end encryption and AI.” I’m extremely grateful to see this paper, because while I don’t agree with every one of its conclusions, it’s a good first stab at an incredibly important set of questions.
I was particularly happy to see people thinking about this topic, since it’s been on my mind in a half-formed state this past few months. On the one hand, my interest in the topic was piqued by the deployment of new AI assistant systems like Google’s scam call protection and Apple Intelligence, both of which aim to put AI basically everywhere on your phone — even, critically, right in the middle of your private messages. On the other hand, I’ve been thinking about the negative privacy implications of AI due to the recent European debate over “mandatory content scanning” laws that would require machine learning systems to scan virtually every private message you send.
While these two subjects arrive from very different directions, I’ve come to believe that they’re going to end up in the same place. And as someone who has been worrying about encryption — and debating the “crypto wars” for over a decade — this has forced me to ask some uncomfortable questions about what the future of end-to-end encrypted privacy will look like. Maybe, even, whether it actually has a future.
But let’s start from an easier place.
What is end-to-end encryption, and what does AI have to do with it?
From a privacy perspective, the most important story of the past decade or so has been the rise of end-to-end encrypted communications platforms. Prior to 2011, most cloud-connected devices simply uploaded their data in plaintext. For many people this meant their private data was exposed to hackers, civil subpoenas, government warrants, or business exploitation by the platforms themselves. Unless you were an advanced user who used tools like PGP and OTR, most end-users had to suffer the consequences.
Headline about the Salt Typhoon group, an APT threat that has essentially owned US telecom infrastructure by compromising “wiretapping” systems. Oh how the worm has turned.
Around 2011 our approach to data storage began to evolve. This began with messaging apps like Signal, Apple iMessage and WhatsApp, all of which began to roll out default end-to-end encryption for private messaging. This technology changed the way that keys are managed, to ensure that servers would never see the plaintext content of your messages. Shortly afterwards, phone (OS) designers like Google, Samsung and Apple began encrypting the data stored locally on your phone, a move that occasioned some famous arguments with law enforcement. More recently, Google introduced default end-to-end encryption for phone backups, and (somewhat belatedly) Apple has begun to follow.
Now I don’t want to minimize the engineering effort required here, which was massive. But these projects were also relatively simple. By this I mean: all of the data encrypted in these projects shared a common feature, which is that none of it needed to be processed by a server.
The obvious limitation of end-to-end encryption is that while it can hide content from servers, it can also make it very difficult for servers to compute on that data.1 This is basically fine for data like cloud backups and private messages, since that content is mostly interesting to clients. For data that actually requires serious processing, the options are much more limited. Wherever this is the case — for example, consider a phone that applies text recognition to the photos in your camera roll — designers typically get forced into a binary choice. On the one hand they can (1) send plaintext off to a server, in the process resurrecting many of the earlier vulnerabilities that end-to-end encryption sought to close. Or else (2) they can limit their processing to whatever can be performedon the device itself.
The problem with the second solution is that your typical phone only has a limited amount of processing power, not to mention RAM and battery capacity. Even the top-end iPhone will typically perform photo processing while it’s plugged in at night, just to avoid burning through your battery when you might need it. Moreover, there is a huge amount of variation in phone hardware. Some flagship phones will run you $1400 or more, and contain onboard GPUs and neural engines. But these phones aren’t typical, in the US and particularly around the world. Even in the US it’s still possible to buy a decent Android phone for a couple hundred bucks, and a lousy one for much less. There is going to be a vast world of difference between these devices in terms of what they can process.
So now we’re finally ready to talk about AI.
Unless you’ve been living under a rock, you’ve probably noticed the explosion of powerful new AI models with amazing capabilities. These include Large Language Models (LLMs) which can generate and understand complex human text, as well as new image processing models that can do amazing things in that medium. You’ve probably also noticed Silicon Valley’s enthusiasm to find applications for this tech. And since phone and messaging companies are Silicon Valley, your phone and its apps are no exception. Even if these firms don’t quite know how AI will be useful to their customers, they’ve already decided that models are the future. In practice this has already manifested in the deployment of applications such as text message summarization, systems that listen to and detect scam phone calls, models that detect offensive images, as well as new systems that help you compose text.
And these are obviously just the beginning.
If you believe the AI futurists — and in this case, I actually think you should — all these toys are really just a palate cleanser for themain entrée still to come: the deployment of “AI agents,” aka, Your Plastic Pal Who’s Fun To Be With.
In theory these new agent systems will remove your need to ever bother messing with your phone again. They’ll read your email and text messages and they’ll answer for you. They’ll order your food and find the best deals on shopping, swipe your dating profile, negotiate with your lenders, and generally anticipate your every want or need. The only ingredient they’ll need to realize this blissful future is virtually unrestricted access to all your private data, plus a whole gob of computing power to process it.
Which finally brings us to the sticky part.
Since most phones currently don’t have the compute to run very powerful models, and since models keep getting better and in some cases more proprietary, it is likely that much of this processing (and the data you need processed) will have to be offloaded to remote servers.
And that’s the first reason that I would say that AI is going to be the biggest privacy story of the decade. Not only will we soon be doing more of our compute off-device, but we’ll be sending a lot more of our private data. This data will be examined and summarized by increasingly powerful systems, producing relatively compact but valuable summaries of our lives. In principle those systems will eventually know everything about us and about our friends. They’ll read our most intimate private conversations, maybe they’ll even intuit our deepest innermost thoughts. We are about to face many hard questions about these systems, including some difficult questions about whether they will actually be working for us at all.
But I’ve gone about two steps farther than I intended to. Let’s start with the easier questions.
What does AI mean for end-to-end encrypted messaging?
Modern end-to-end encrypted messaging systems provide a very specific set of technical guarantees. Concretely, an end-to-end encrypted system is designed to ensure that plaintext message content in transit is not available anywhere except for the end-devices of the participants and (here comes the Big Asterisk) anyone the participants or their devices choose to share it with.
The last part of that sentence is very important, and it’s obvious that non-technical users get pretty confused about it. End-to-end encrypted messaging systems are intended to deliver data securely. They don’t dictate what happens to it next. If you take screenshots of your messages, back them up in plaintext, copy/paste your data onto Twitter, or hand over your device in response to a civil lawsuit — well, that has really nothing to do with end-to-end encryption. Once the data has been delivered from one end to the other, end-to-end encryption washes its hands and goes home
Of course there’s a difference between technical guarantees and the promises that individual service providers make to their customers. For example, Apple says this about its iMessage service:
I can see how these promises might get a little bit confusing! For example, imagine that Apple keeps its promise to deliver messages securely, but then your (Apple) phone goes ahead and uploads (the plaintext) message content to a different set of servers where Apple really can decrypt it. Apple is absolutely using end-to-end encryption in the dullest technical sense… yet is the statement above really accurate? Is Apple keeping its broader promise that it “can’t decrypt the data”?
Note: I am not picking on Apple here! This is just one paragraph from a security overview. In a separate legal document, Apple’s lawyers have written a zillion words to cover their asses. My point here is just to point out that a technical guarantee is different from a user promise.
Making things more complicated, this might not be a question about your own actions. Consider the promise you receive every time you start a WhatsApp group chat (at right.) Now imagine that some other member of the group — not you, but one of your idiot friends — decides to turn on some service that uploads (your) received plaintext messages to WhatsApp. Would you still say the message you received still accurately describes how WhatsApp treats your data? If not, how should it change?
In general, what we’re asking here is a question about informedconsent. Consent is complicated because it’s both a moral concept and also a legal one, and because the law is different in every corner of the world. The NYU/Cornell paper does an excellent job giving an overview of the legal bits, but — and sorry to be a bummer here — I really don’t want you to expect the law to protect you. I imagine that some companies will do a good job informing their users, as a way to earn trust. Other companies, won’t. Here in the US, they’ll bury your consent inside of an inscrutable “terms of service” document you never read. In the EU they’ll probably just invent a new type of cookie banner.
This is obviously a joke. But, like, maybe not?
So to summarize: in the near term we’re headed to a world where we should expect increasing amounts of our data to be processed by AI, and a lot of that processing will (very likely) be off-device. Good end-to-end encrypted services will actively inform you that this is happening, so maybe you’ll have the chance to opt-in or opt-out. But if it’s truly ubiquitous (as our futurist friends tell us it will be) then probably your options will be end up being pretty limited.
Some ideas for avoiding AI inference on your private messages (cribbed from Mickens.)
Fortunately all is not lost. In the short term, a few people have been thinking hard about this problem.
Trusted Hardware and Apple’s “Private Cloud Compute”
The good news is that our coming AI future isn’t going to be a total privacy disaster. And in large part that’s because a few privacy-focused companies like Apple have anticipated the problems that ML inference will create (namely the need to outsource processing to better hardware) and have tried to do something about it. This something is essentially a new type of cloud-based computer that Apple believes is trustworthy enough to hold your private data.
Quick reminder: as we already discussed, Apple can’t rely on every device possessing enough power to perform inference locally. This means inference will be outsourced to a remote cloud machine. Now the connection from your phone to the server can be encrypted, but the remote machine will still receive confidential data that it must see in cleartext. This poses a huge risk at that machine. It could be compromised and the data stolen by hackers, or worse, Apple’s business development executives could find out about it.
Apple’s approach to this problem is called “Private Cloud Compute” and it involves the use of special trusted hardware devices that run in Apple’s data centers. A “trusted hardware device” is a kind of computer that is locked-down in both the physical and logical sense. Apple’s devices are house-made, and use custom silicon and software features. One of these is Apple’s Secure Boot, which ensures that only “allowed” operating system software is loaded. The OS then uses code-signing to verify that only permitted software images can run. Apple ensures that no long-term state is stored on these machines, and also load-balances your request to a different random server every time you connect. The machines “attest” to the application software they run, meaning that they announce a hash of the software image (which must itself be stored in a verifiable transparency log to prevent any new software from surreptitiously being added.) Apple even says it will publish its software images (though unfortunately not [update:all of] the source code) so that security researchers can check them over for bugs.
The goal of this system is to make it hard for both attackers and Apple employees to exfiltrate data from these devices. I won’t say I’m thrilled about this. It goes without saying that Apple’s approach is a vastly weaker guarantee than encryption — it still centralizes a huge amount of valuable data, and its security relies on Apple getting a bunch of complicated software and hardware security features right, rather than the mathematics of an encryption algorithm. Yet this approach is obviously much better than what’s being done at companies like OpenAI, where the data is processed by servers that employees (presumably) can log into and access.
Although PCC is currently unique to Apple, we can hope that other privacy-focused services will soon crib the idea — after all, imitation is the best form of flattery. In this world, if we absolutely must have AI everywhere, at least the result will be a bit more secure than it might otherwise be.
Who does your AI agent actually work for?
There are so many important questions that I haven’t discussed in this post, and I feel guilty because I’m not going to get to them. I have not, for example, discussed the very important problem of the data used to train (and fine-tune) future AI models, something that opens entire oceans of privacy questions. If you’re interested, these problems are discussed in the NYU/Cornell paper.
But rather than go into that, I want to turn this discussion towards a different question: namely, who are these models actually going to be working for?
As I mentioned above, over the past couple of years I’ve been watching the UK and EU debate new laws that would mandate automated “scanning” of private, encrypted messages. The EU’s proposal is focused on detecting both existing and novel child sexual abuse material (CSAM); it has at various points also included proposals to detect audio and textual conversations that represent “grooming behavior.” The UK’s proposal is a bit wilder and covers many different types of illegal content, including hate speech, terrorism content and fraud — one proposed amendment even covered “images of immigrants crossing the Channel in small boats.”
While scanningfor knownCSAM does not require AI/ML, detecting nearly every one of the other types of content would require powerful ML inference that can operate on your private data. (Consider, for example, what is involved in detecting novel CSAM content.) Plans to detect audio or textual “grooming behavior” and hate speech will require even more powerful capabilities: not just speech-to-text capabilities, but also some ability to truly understand the topic of human conversations without false positives. It is hard to believe that politicians even understand what they’re asking for. And yet some of them are asking for it, in a few cases very eagerly.
These proposals haven’t been implemented yet. But to some degree this is because ML systems that securely process private data are very challenging to build, and technical platforms have been resistant to building them. Now I invite you to imagine a world where we voluntarily go ahead and build general-purpose agents that are capable of all of these tasks and more. You might do everything in your technical power to keep them under the user’s control, but can you guarantee that they will remain that way?
Or put differently: would you even blame governments for demanding access to a resource like this? And how would you stop them? After all, think about how much time and money a law enforcement agency could save by asking your agent sophisticated questions about your behavior and data, questions like: “does this user have any potential CSAM,” or “have they written anything that could potentially be hate speech in their private notes,” or “do you think maybe they’re cheating on their taxes?” You might even convince yourself that these questions are “privacy preserving,” since no human police officer would ever rummage through your papers, and law enforcement would only learn the answer if you were (probably) doing something illegal.
This future worries me because it doesn’t really matter what technical choices we make around privacy. It does not matter if your model is running locally, or if it uses trusted cloud hardware — once a sufficiently-powerful general-purpose agent has been deployed on your phone, the only question that remains is who is given access to talk to it. Will it be only you? Or will we prioritize the government’s interest in monitoring its citizens over various fuddy-duddy notions of individual privacy.
And while I’d like to hope that we, as a society, will make the right political choice in this instance, frankly I’m just not that confident.
Notes:
(A quick note: some will suggest that Apple should use fully-homomorphic encryption [FHE] for this calculation, so the private data can remain encrypted. This is theoretically possible, but unlikely to be practical. The best FHE schemes we have today really only work for evaluating very tiny ML models, of the sort that would be practical to run on a weak client device. While schemes will get better and hardware will too, I suspect this barrier will exist for a long time to come.)
This blog is reserved for more serious things, and ordinarily I wouldn’t spend time on questions like the above. But much as I’d like to spend my time writing about exciting topics, sometimes the world requires a bit of what Brad Delong calls “Intellectual Garbage Pickup,” namely: correcting wrong, or mostly-wrong ideas that spread unchecked across the Internet.
This post is inspired by the recent and concerning news that Telegram’s CEO Pavel Durov has been arrested by French authorities for its failure to sufficiently moderate content. While I don’t know the details, the use of criminal charges to coerce social media companies is a pretty worrying escalation, and I hope there’s more to the story.
But this arrest is not what I want to talk about today.
What I do want to talk about is one specific detail of the reporting. Specifically: the fact that nearly every news report about the arrest refers to Telegram as an “encrypted messaging app.” Here are just afewexamples:
This phrasing drives me nuts because in a very limited technical sense it’s not wrong. Yet in every sense that matters, it fundamentally misrepresents what Telegram is and how it works in practice. And this misrepresentation is bad for both journalists and particularly for Telegram’s users, many of whom could be badly hurt as a result.
Now to the details.
Does Telegram have encryption or doesn’t it?
Many systems use encryption in some way or another. However, when we talk about encryption in the context of modern private messaging services, the word typically has a very specific meaning: it refers to the use of default end-to-end encryption to protect users’ message content. When used in an industry-standard way, this feature ensures that every message will be encrypted using encryption keys that are only known to the communicating parties, and not to the service provider.
From your perspective as a user, an “encrypted messenger” ensures that each time you start a conversation, your messages will only be readable by the folks you intend to speak with. If the operator of a messaging service tries to view the content of your messages, all they’ll see is useless encrypted junk. That same guarantee holds for anyone who might hack into the provider’s servers, and also, for better or for worse, to law enforcement agencies that serve providers with a subpoena.
Telegram clearly fails to meet this stronger definition for a simple reason: it does not end-to-end encrypt conversations by default. If you want to use end-to-end encryption in Telegram, you must manually activate an optional end-to-end encryption feature called “Secret Chats” for every single private conversation you want to have. The feature is explicitly not turned on for the vast majority of conversations, and is only available for one-on-one conversations, and never for group chats with more than two people in them.
As a kind of a weird bonus, activating end-to-end encryption in Telegram is oddly difficult for non-expert users to actually do.
For one thing, the button that activates Telegram’s encryption feature is not visible from the main conversation pane, or from the home screen. To find it in the iOS app, I had to click at least four times — once to access the user’s profile, once to make a hidden menu pop up showing me the options, and a final time to “confirm” that I wanted to use encryption. And even after this I was not able to actually have an encrypted conversation, since Secret Chats only works if your conversation partner happens to be online when you do this.
Starting a “secret chat” with my friend Michael on the latest Telegram iOS app. From an ordinary chat screen this option isn’t directly visible. Getting it activated requires four clicks: (1) to get to Michael’s profile (left image), (2) on the “…” button to display a hidden set of options (center image), (3) on “Start Secret Chat”, and (4) on the “Are you sure…” confirmation dialog. After that I’m still unable to send Michael any messages, because Telegram’s Secret Chats can only be turned on if the other user is also online.
Overall this is quite different from the experience of starting a new encrypted chat in an industry-standard modern messaging application, which simply requires you to open a new chat window.
While it might seem like I’m being picky, the difference in adoption between default end-to-end encryption and this experience is likely very significant. The practical impact is that the vast majority of one-on-one Telegram conversations — and literally every single group chat — are probably visible on Telegram’s servers, which can see and record the content of all messages sent between users. That may or may not be a problem for every Telegram user, but it’s certainly not something we’d advertise as particularly well encrypted.
(If you’re interested in the details, as well as a little bit of further criticism of Telegram’s actual encryption protocols, I’ll get into what we know about that further below.)
But wait, does default encryption really matter?
Maybe yes, maybe no! There are two different ways to think about this.
One is that Telegram’s lack of default encryption is just finefor many people. The reality is that many users don’t choose Telegram for encrypted private messaging at all. For plenty of people, Telegram is used more like a social media network than a private messenger.
Getting more specific, Telegram has two popular features that makes it ideal for this use-case. One of those is the ability to create and subscribe to “channels“, each of which works like a broadcast network where one person (or a small number of people) can push content out to millions of readers. When you’re broadcasting messages to thousands of strangers in public, maintaining the secrecy of your chat content isn’t as important.
Telegram also supports large public group chats that can include thousands of users. These groups can be made open for the general public to join, or they can set up as invite-only. While I’ve never personally wanted to share a group chat with thousands of people, I’m told that many people enjoy this feature. In the large and public instantiation, it also doesn’t really matter that Telegram group chats are unencrypted — after all, who cares about confidentiality if you’re talking in the public square?
But Telegram is not limited to just those features, and many users who join for them will also do other things.
Imagine you’re in a “public square” having a large group conversation. In that setting there may be no expectation of strong privacy, and so end-to-end encryption doesn’t really matter to you. But let’s say that you and five friends step out of the square to have a side conversation. Does that conversation deserve strong privacy? It doesn’t really matter what you want, because Telegram won’t provide it, at least not with encryption that protects you from sharing your content with Telegram servers.
Similarly, imagine you use Telegram for its social media-like features, meaning that you mainly consume content rather than producing it. But one day your friend, who also uses Telegram for similar reasons, notices you’re on the platform and decides she wants to send you a private message. Are you concerned about privacy now? And are you each going to manually turn on the “Secret Chat” feature — even though it requires four explicit clicks through hidden menus, and even though it will prevent you from communicating immediately if one of you is offline?
My strong suspicion is that many people who join Telegram for its social media features also end up using it to communicate privately. And I think Telegram knows this, and tends to advertise itself as a “secure messenger” and talk about the platform’s encryption features precisely because they know it makes people feel more comfortable. But in practice, I also suspect that very few of those users are actually using Telegram’s encryption. Many of those users may not even realize they have to turn encryption on manually, and think they’re already using it.
Which brings me to my next point.
Telegram knows its encryption is difficult to turn on, and they continue to promote their product as a secure messenger
Telegram’s encryption has been subject toheavy criticismsinceat least 2016 (and possibly earlier) for many of the reasons I outlined in this post. In fact, many of these criticisms were made by experts including myself, in years-old conversations with Pavel Durov on Twitter.1
Although the interaction with Durov could sometimes be harsh, I still mostly assumed good faith from Telegram back in those days. I believed that Telegram was busy growing their network and that, in time, they would improve the quality and usability of the platform’s end-to-end encryption: for example, by activating it as a default, providing support for group chats, and making it possible to start encrypted chats with offline users. I assumed that while Telegram might be a follower rather than a leader, it would eventually reach feature parity with the encryption protocols offered by Signal and WhatsApp. Of course, a second possibility was that Telegram would abandon encryption entirely — and just focus on being a social media platform.
What’s actually happened is a lot more confusing to me.
Instead of improving the usability of Telegram’s end-to-end encryption, the owners of Telegram have more or less kept their encryption UX unchanged since 2016. While there have been a few upgrades to the underlying encryption algorithms used by the platform, the user-facing experience of Secret Chats in 2024 is almost identical to the one you’d have seen eight years ago. This, despite the fact that the number of Telegram users has grown by 7-9x during the same time period.
At the same time, Telegram CEO Pavel Durov has continued to aggressively market Telegram as a “secure messenger.” Most recently he issued a scathing criticism of Signal and WhatsApp on his personal Telegram channel, implying that those systems were backdoored by the US government, and only Telegram’s independent encryption protocols were really trustworthy.
While this might be a reasonable nerd-argument if it was taking place between two platforms that both supported default end-to-end encryption, Telegram really has no legs to stand on in this particular discussion. Indeed, it no longer feels amusing to see the Telegram organization urge people away from default-encrypted messengers, while refusing to implement essential features that would widely encrypt their own users’ messages. In fact, it’s starting to feel a bit malicious.
What about the boring encryption details?
This is a cryptography blog and so I’d be remiss if I didn’t spend at least a little bit of time on the boring encryption protocols. I’d also be missing a good opportunity to let my mouth gape open in amazement, which is pretty much what happens every time I look at the internals of Telegram’s encryption.
I’m going to handle this in one paragraph to reduce the pain, and you can feel free to skip past it if you’re not interested.
According to what I think is the latest encryption spec, Telegram’s Secret Chats feature is based on a custom protocol called MTProto 2.0. This system uses 2048-bit* finite-field Diffie-Hellman key agreement, with group parameters (I think) chosen by the server.* (Since the Diffie-Hellman protocol is only executed interactively, this is why Secret Chats cannot be set up when one user is offline.*) MITM protection is handled by the end-users, who must compare key fingerprints. There are some weird random nonces provided by the server, which I don’t fully understands the purpose of* — and that in the past used to actively make the key exchange totally insecure against a malicious server (but this has long since been fixed.*) The resulting keys are then used to power the most amazing, non-standard authenticated encryption mode ever invented, something called “Infinite Garble Extension” (IGE) based on AES and with SHA2 handling authentication.*
NB: Every place I put a “*” in the paragraph above is a point where expert cryptographers would, in the context of something like a professional security audit, raise their hands and ask a lot of questions. I’m not going to go further than this. Suffice it to say that Telegram’s encryption is unusual.
If you ask me to guess whether the protocol and implementation of Telegram Secret Chats is secure, I would say quitepossibly. To be honest though, it doesn’t matter how secure something is if people aren’t actually using it.
Is there anything else I should know?
Yes, unfortunately. Even though end-to-end encryption is one of the best tools we’ve developed to prevent data compromise, it is hardly the end of the story. One of the biggest privacy problems in messaging is the availability of loads of meta-data — essentially data about who uses the service, who they talk to, and when they do that talking.
This data is not typically protected by end-to-end encryption. Even in applications that are broadcast-only, such as Telegram’s channels, there is plenty of useful metadata available about who is listening to a broadcast. That information alone is valuable to people, as evidenced by the enormous amounts of money that traditional broadcasters spend to collect it. Right now all of that information likely exists on Telegram’s servers, where it is available to anyone who wants to collect it.
I am not specifically calling out Telegram for this, since the same problem exists with virtually every other social media network and private messenger. But it should be mentioned, just to avoid leaving you with the conclusion that encryption is all we need.
Main photo “privacy screen” by Susan Jane Golding, used under CC license.
Notes:
I will never find all of these conversations again, thanks to Twitter search being so broken. If anyone can turn them up I’d appreciate it.
Update(April 19): Yilei Chen announced the discovery of a bug in the algorithm, which he does not know how to fix. This was independently discovered by Hongxun Wu and Thomas Vidick. At present, the paper does not provide a polynomial-time algorithm for solving LWE.
If you’re a normal person — that is, a person who doesn’t obsessively follow the latest cryptography news — you probably missed last week’s cryptography bombshell. That news comes in the form of a new e-print authored by Yilei Chen, “Quantum Algorithms for Lattice Problems“, which has roiled the cryptography research community. The result is now being evaluated by experts in lattices and quantum algorithm design (and to be clear, I am not one!) but if it holds up, it’s going to be quite a bad day/week/month/year for the applied cryptography community.
Rather than elaborate at length, here’s quick set of five bullet-points giving the background.
(1) Cryptographers like to build modern public-key encryption schemes on top of mathematical problems that are believed to be “hard”. In practice, we need problems with a specific structure: we can construct efficient solutions for those who hold a secret key, or “trapdoor”, and yet also admit no efficient solution for folks who don’t. While many problems have been considered (and often discarded), most schemes we use today are based on three problems: factoring (the RSA cryptosystem), discrete logarithm (Diffie-Hellman, DSA) and elliptic curve discrete logarithm problem (EC-Diffie-Hellman, ECDSA etc.)
(2) While we would like to believe our favorite problems are fundamentally “hard”, we know this isn’t really true. Researchers have devised algorithms that solve all of these problems quite efficiently (i.e., in polynomial time) — provided someone figures out how to build a quantum computer powerful enough to run the attack algorithms. Fortunately such a computer has not yet been built!
(3) Even though quantum computers are not yet powerful enough to break our public-key crypto, the mere threat of future quantum attacks has inspired industry, government and academia to join forces Fellowship-of-the-Ring-style in order to tackle the problem right now. This isn’t merely about future-proofing our systems: even if quantum computers take decades to build, future quantum computers could break encrypted messages we send today!
(4) One conspicuous outcome of this fellowship is NIST’s Post-Quantum Cryptography (PQC) competition: this was an open competition designed to standardize “post-quantum” cryptographic schemes. Critically, these schemes must be based on different mathematical problems — most notably, problems that don’t seem to admit efficient quantum solutions.
(5) Within this new set of schemes, the most popular class of schemes are based on problems related to mathematical objects called lattices. NIST-approved schemes based on lattice problems include Kyber and Dilithium (which I wrote about recently.) Lattice problems are also the basis of several efficient fully-homomorphic encryption (FHE) schemes.
This background sets up the new result.
Chen’s (not yet peer-reviewed) preprint claims anew quantum algorithm that efficiently solves the “shortest independent vector problem” (SIVP, as well as GapSVP) in lattices with specific parameters. If it holds up, the result could (with numerous important caveats) allow future quantum computers to break schemes that depend on the hardness of specific instances of these problems. The good news here is that even if the result is correct, the vulnerable parameters are very specific: Chen’s algorithm does not immediately apply to the recently-standardized NIST algorithms such as Kyber or Dilithium. Moreover, the exact concrete complexity of the algorithm is not instantly clear: it may turn out to be impractical to run, even if quantum computers become available.
But there is a saying in our field that attacks only get better. If Chen’s result can be improved upon, then quantum algorithms could render obsolete an entire generation of “post-quantum” lattice-based schemes, forcing cryptographers andindustryback to the drawing board.
In other words, both a great technical result — and possibly a mild disaster.
As previously mentioned: I am neither an expert in lattice-based cryptography nor quantum computing. The folks who are those things are very busy trying to validate the writeup: and more than a few big results have fallen apart upon detailed inspection.For those searching for the latest developments, here’s a nice writeup by Nigel Smart that doesn’t tackle the correctness of the quantum algorithm (see updates at the bottom), but does talk about the possible implications for FHE and PQC schemes (TL;DR: bad for some FHE schemes, but really depends on the concrete details of the algorithm’s running time.) And here’s another brief note on a “bug” that was found in the paper, that seems to have been quickly addressed by the author.
Up until this week I had intended to write another long wonky post about complexity theory, lattices, and what it all meant for applied cryptography. But now I hope you’ll forgive me if I hold onto that one, for just a little bit longer.
It’s been a while since I wrote an “attack of the week” post, and the fault for this is entirely mine. I’ve been much too busy writing boring posts about Schnorr signatures! But this week’s news brings an exciting story with both technical and political dimensions: new reports claim that Chinese security agencies have developed a technique to trace the sender of AirDrop transmissions.
Typically my “attack of the week” posts are intended to highlight recent research. What’s unusual about this one is that the attack is not really new; it was discovered way back in 2019, when a set of TU Darmstadt researchers — Heinrich, Hollick, Schneider, Stute, and Weinert — reverse-engineered the Apple AirDrop protocol and disclosed several privacy flaws to Apple. (The resulting paper, which appeared in Usenix Security 2021 can be found here.)
What makes this an attack of the week is a piece of news that was initially reported by Bloomberg (here’s some other coveragewithout paywall) claiming that researchers in China’s Beijing Wangshendongjian Judicial Appraisal Institute have used these vulnerabilities to help police to identify the sender of “unauthorized” AirDrop materials, using a technique based on rainbow tables. While this new capability may not (yet) be in widespread deployment, it represents a new tool that could strongly suppress the use of AirDrop in China and Hong Kong.
And this is a big deal, since AirDrop is apparently one of a few channels that can still be used to disseminate unauthorized protest materials — and indeed, that was used in both places in 2019 and 2022, and (allegedly as a result) has already been subject to various curtailments.
In this post I’m going to talk about the Darmstadt research and how it relates to the news out of Beijing. Finally, I’ll talk a little about what Apple can do about it — something that is likely to be as much of a political problem as a technical one.
As always, the rest of this will be in the “fun” question-and-answer format I use for these posts.
What is AirDrop and why should I care?
Image from Apple. Used without permission.
If you own an iPhone, you already know the answer to this question. Otherwise: AirDrop is an Apple-specific protocol that allows Apple devices to send files (and contacts and other stuff) in a peer-to-peer manner over various wireless protocols, including Bluetooth and WiFi.
The key thing to know about AirDrop is that it has two settings, which can be enabled by a potential receiver. In “Contacts Only” mode, AirDrop will accept files only from people who are in your Contacts list (address book.) When set to “Everyone”, AirDrop will receive files from any random person within transmit range. This latter mode has been extensively used to distribute protest materials in China and Hong Kong, as well as to distribute indecent photos to strangers all over the world.
The former usage of AirDrop became such a big deal in protests that in 2022, Apple pushed a software update exclusively to Chinese users that limited the “Everyone” receive-from mode — ensuring that phones would automatically switch back to “Contacts only” after 10 minutes. The company later extended this software update to all users worldwide, but only after they were extensively criticized for the original move.
Is AirDrop supposed to be private? And how does AirDrop know if a user is in their Contacts list?
While AirDrop is not explicitly advertised as an “anonymous” communication protocol, any system that has your phone talking to strangers has implicit privacy concerns baked into it. This drives many choices around how AirDrop works.
Let’s start with the most important one: do AirDrop senders provide their ID to potential recipients? The answer, at some level, must be “yes.”
The reason for this is straightforward. In order for AirDrop recipients in “Contacts only” mode to check that a sender is in their Contacts list, there must be a way for them to check the sender’s ID. This implies that the sender must somehow reveal their identity to the recipient. And since AirDrop presents a list of possible recipients any time a sending user pops up the AirDrop window, this will happen at “discovery” time — typically before you’ve even decided if you really want to send a file.
But this poses a conundrum: the sender’s phone doesn’t actually know which nearby AirDrop users are willing to receive files from it — i.e., which AirDrop users have the sender in their Contacts — and it won’t know this until it actually talks to them. But talking to them means your phone is potentially shouting at everyone around it all the time, saying something like:
Hi there! My Apple ID is john.doe.28@icloud.com. Will you accept files from me!??
Now forget that this is being done by phones. Instead imagine yourself, as a human being, doing this to every random stranger you encounter on the subway. It should be obvious that this will quickly become a privacy concern, one that would scare even a company that doesn’t care about privacy. But Apple generally does care quite a bit about privacy!
Thus, just solving this basic problem requires a clever way by which phones can figure out whether they should talk to each other — i.e., whether the receiver has the sender in its Contacts — without either side leaking any useful information to random strangers. Fortunately cryptographic researchers have thought a lot about this problem! We’ve even given it a cool name: it’s called Private Set Intersection, or PSI.
To make a long story short: a Private Set Intersection protocol takes a set of strings from the Sender and a set from the Receiver. It gives one (or both) parties the intersection of both sets: that is, the set of entries that appear on both lists. Most critically, a good PSI protocol doesn’t reveal any other information about either of the sets.
In Apple’s case, the Sender would have just a few entries, since you can have a few different email addresses and phone numbers. The Receiver would have a big set containing its entire Contacts list. The output of the protocol would contain either (1) one or more of the Sender’s addresses, or (2) nothing. A PSI protocol would therefore solve Apple’s problem nicely.
Great, so which PSI protocol does Apple use?
The best possible answer to this is: 😔.
For a variety of mildly defensible reasons — which I will come back to in a moment — Apple does not use a secure PSI protocol to solve their AirDrop problem. Instead they did the thing that every software developer does when faced with the choice of doing complicated cryptography or “hacking something together in time for the next ship date”: they threw together their own solution using hash functions.
The TU Darmstadt researchers did a nice job of reverse-engineering Apple’s protocol in their paper. Read it! The important bit happens during the “Discovery” portion of the protocol, which is marked by an HTTPS POST request as shown in the excerpt below:
The very short TL;DR is this:
In the POST request, a sender attaches a truncated SHA-256 hash of its own Apple ID, which is contained within a signed certificate that it gets from Apple. (If the sender has more than one identifier, e.g., a phone number and an email address, this will contain hashes of each one.)
The recipient then hashes every entry in its Contacts list, and compares the results to see if it finds a match.
If the recipient is in Contacts Only mode and finds a match, it indicates this and accepts later file transfers. Otherwise it aborts the connection.
(As a secondary issue, AirDrop also includes a very short [two byte] portion of the same hashes in its BLE advertisements. Two bytes is pretty tiny, which means this shouldn’t leak much information, since many different addresses will collide on a two-byte hash. However, some other researchers have determined that it generally does work well enough to guess identities. Or they may have, the source isn’t translating well for me.)
A second important issue here is that the hash identifiers are apparently stored in logs within the recipient’s phone, which means that to obtain them you don’t have to be physically present when the transfer happens. You can potentially scoop them out of someone else’s phone after the fact.
So what’s the problem?
Many folks who have some experience with cryptography will see the problem immediately. But let’s be explicit.
Hash functions are designed to be one-way. In theory, this means that there is should be no efficient algorithm for “directly” taking the output of a hash function and turning it back into its input. But that guarantee has a huge asterisk: if I can guess a set of possible inputs that could have produced the hash, I can simply hash each one of my guesses and compare it to the target. If one input matches, then chances are overwhelming that I’ve found the right input (also called a pre-image.)
In its most basic form, this naive approach is called a “dictionary attack” based on the idea that one can assemble a dictionary of likely candidates, then test every one. Since these hashes apparently don’t contain any session-dependent information (such as salt), you can even do the hashing in advance to assemble a dictionary of candidate hashes, making the attack even faster.
This approach won’t work if your Apple ID (or phone number) is not guessable. The big question in exploiting this vulnerability is whether it’s possible to assemble a complete list of candidate Apple ID emails and phone numbers. The answer for phone numbers, as the Darmstadt researchers point out, is absolutely yes. Since there are only a few billion phone numbers, it is entirely possible to make a list of every phone number and have a computer grind through them — given a not-unreasonable amount of time. For email addresses this is more complicated, but there are many lists of email addresses in the world, and the Chinese state authorities almost certainly have some good approaches to collecting and/or generating those lists.
As an aside, exploiting these dictionaries can be done in three different ways:
You can make a list of candidate identifiers (or generate them programmatically) and then, given a new target hash, you can hash each identifier and check for a match. This requires you to compute a whole lot of SHA256 hashes for each target you crack, which is pretty fast on a GPU or FPGA (or ASIC) but not optimal.
You can pre-hash the list and make a database of hashes and identifiers. Then when you see a target hash, you just need to do a fast lookup. This means all computation is done once, and lookups are fast. But it requires a ton of storage.
Alternatively, you can use an intermediate approach called a time-memory tradeoff in which you exchange some storage for some computation once the target is found. The most popular technique is called a rainbow table, and it really deserves its own separate blog post, though I will not elaborate today.
The Chinese announcement explicitly mentions a rainbow table, so that’s a good indicator that they’re exploiting this vulnerability.
Well that sucks. What can we, or rather Apple, do about it?
If you’re worried about leaking your identifier, an immediate solution is to turn off AirDrop, assuming such a thing is possible. (I haven’t tried it, so I don’t know if turning this off will really stop your phone from talking to other people!) Alternatively you can unregister your Apple ID, or use a bizarre high-entropy Apple ID that nobody will possibly guess. Apple could also reduce their use of logging.
But those solutions are all terrible.
The proper technical solution is for Apple to replace their hashing-based protocol with a proper PSI protocol, which will — as previously discussed — reveal only one bit of information: whether the receiver has the sender’s address(es) in their Contacts list. Indeed, that’s the solution that the Darmstadt researchers propose. They even devised a Diffie-Hellman-based PSI protocol called “PrivateDrop” and showed that it can be used to solve this problem.
But this is not necessarily an easy solution, for reasons that are both technical and political. It’s worth noting that Apple almost certainly knew from the get-go that their protocol was vulnerable to these attacks — but even if they didn’t, they were told about these issues back in May 2019 by the Darmstadt folks. It’s now 2024, and Chinese authorities are exploiting it. So clearly it was not an easy fix.
Some of this stems from the fact that PSI protocols are more computationally heavy that the hashing-based protocol, and some of it (may) stem from the need for more interaction between each pair of devices. Although these costs are not particularly unbearable, it’s important to remember that phone battery life and BLE/WiFi bandwidth is precious to Apple, so even minor costs are hard to bear. Finally, Apple may not view this as really being an issue.
However in this case there is an even tougher political dimension.
Will Apple even fix this, given that Chinese authorities are now exploiting it?
And here we find the hundred billion dollar question: if Apple actually replaced their existing protocol with PrivateDrop, would that be viewed negatively by the Chinese government?
Those of us on the outside can only speculate about this. However, the facts are pretty worrying: Apple has enormous manufacturing and sales resources located inside of China, which makes them extremely vulnerable to an irritated Chinese government. They have, in the past, taken actions that appeared to be targeted at restricting AirDrop use within China — and although there’s no definitive proof of their motivations, it certainly looked bad.
Hence there is a legitimate question about whether it’s politically wise for Apple to make a big technical improvement to their AirDrop privacy, right at the moment that the lack of privacy is being viewed as an asset by authorities in China. Even if this attack isn’t really that critical to law enforcement within China, the decision to “fix” it could very well be seen as a slap in the face.
One hopes that despite all these concerns, we’ll soon see a substantial push to improve the privacy of AirDrop. But I’m not going to hold my breath.
This post continues a long, wonky discussion of Schnorr signature schemes and the Dilithium post-quantum signature. You may want to start with Part 1.
In the previous post I discussed the intuition behind Schnorr signatures, beginning with a high-level design rationale and ending with a concrete instantiation.
As a reminder: our discussion began with this Tweet by Chris Peikert:
Which we eventually developed into an abstract version of the Schnorr protocol that uses Chris’s “magic boxes” to realize part of its functionality:
Finally, we “filled in” the magic boxes by replacing them with real-world mathematical objects, this time built using cyclic groups over finite fields or elliptic curves. Hopefully my hand-waving convinced you that this instantiation works well enough, provided we make one critical assumption: namely, that the discrete logarithm problem is hard (i.e., solving discrete logarithms in our chosen groups is not feasible in probabilistic polynomial time.)
In the past this seemed like a pretty reasonable assumption to make, and hence cryptographers have chosen to make it all over the place. Sadly, it very likely isn’t true.
The problem here is that we already know of algorithms that can solve these discrete logarithms in (expected) polynomial time: most notably Shor’s algorithm and its variants. The reason we aren’t deploying these attacks today is that we simply don’t have the hardware to run them yet — because they require an extremely sophisticated quantum computer. Appropriate machines don’t currently exist, but they may someday. This raises an important question:
Do Schnorr signatures have any realization that makes sense in this future post-quantum world?And can we understand it?
That’s where I intend to go in the rest of this post.
Towards a post-quantum world
Cryptographers and standards agencies are not blind to the possibility that quantum computers will someday break our cryptographic primitives. In anticipation of this future, NIST has been running a public competition to identify a new set of quantum-resistant cryptographic algorithms that support both encryption and digital signing. These algorithms are designed to be executed on a classical computer today, while simultaneously resisting future attacks by the quantum computers that may come.
One of the schemes NIST has chosen for standardization is a digital signature scheme called Dilithium. Dilithium is based on assumptions drawn from the broad area of lattice-based cryptography, which contains candidate “hard” problems that have (so far) resisted both classical and quantum attacks.
The obvious way to approach the Dilithium scheme is to first spend some time on the exact nature of lattices and then discuss what these “hard problems” are (for the moment). But we’re not going to do any of that. Instead, I find that sometimes it’s helpful to just dive straight into a scheme and see what we can learn from first contact with it.
As with any signature scheme, Dilithium consists of three algorithms, one for generating keys, one for signing, and one for signature verification. We can see an overview of each of these algorithms — minus many specific details and subroutine definitions — at the very beginning of the Dilithium specification. Here’s what it looks like:
As you can see, I’ve added some arrows pointing to important aspects of the algorithm description above. Hopefully from these highlights (and given the title of this series of post!) you should have some idea of the point I’m trying to make here. To lay things out more clearly: even without understanding every detail of this scheme, you should notice that it looks an awful lot like a standard Schnorr signature.
Let’s see if we can use this understanding to reconstruct how Dilithium works.
Dilithium from first principles
Our first stop on the road to understanding Dilithium will begin with Chris Peikert’s “magic box” explanation of Schnorr signatures. Recall that his approach has five steps:
Signer picks a slope. The Signer picks a random slope of a line, and inserts it into a “magic box” (i.e., a one-way function) to produce the public key.
Signer picks a y-intercept. To conduct the interactive Identification Protocol (in this case flattened into a signature via Fiat-Shamir), the Signer picks a random “y-intercept” for the line, and inserts that into a second magic box.
Verifier challenges on some x-coordinate. In the interactive protocol, the Verifier challenges the Prover (resp. signer) to evaluate the line at some randomly-chosen x-coordinate. Alternatively: in the Fiat-Shamir realization, the Signer uses the Fiat-Shamir heuristic to pick this challenge herself, by hashing her magic boxes together with some message.
Signer evaluates the line. The Signer now evaluates her line at the given coordinate, and outputs the resulting point. (The signature thus comprises one “magic box” and one “point.”)
Verifier tests that the response is on the line. The Verifier uses the magic boxes to test that the given point is on the line.
If Dilithium really is a Schnorr protocol, we should be able to identify each of these stages within the Dilithium signature specification. Let’s see what we can do.
Step 1: putting a “slope” into a magic box to form the public key. Let’s take a closer look at the Dilithium key generation subroutine:
A quick observation about this scheme is that it samples not one, but two secret values, s1 and s2, both of which end up in the secret key. (We can also note that these secret values are vectors rather than simple field elements, but recall that for the moment our goal is to avoid getting hung up on these details.) If we assume Dilithium is a Schnorr-like protocol, we can surmise that one of these values will be our secret “slope.”
But which one?
One approach to answering this question is to go searching for some kind of “magic box” within the signer’s public key. Here’s what that public key looks like:
pk := (A, t)
The matrix A is sampled randomly. Although the precise details of that process are not given in the high-level spec, we can reasonably observe that A is not based on s1 or s2. The second value in the public key, on the other hand, is constructed by combining A with both of the secret values:
t = As1 + s2.
Hence we can reasonably guess that the pair (A, t) together form the first of our magic boxes. Unfortunately, this doesn’t really answer our earlier question: we still don’t know which of the two secret values will serve as the “slope” for the Schnorr “linear equation.”
The obvious way to solve this problem is to skip forward to the signing routine, to see if we can find a calculation that resembles that equation. Sure enough, at line (10) we find:
Here only s1 is referenced, which strongly indicates that this will take the place of our “slope.”
So roughly speaking, we can view key generation as generating a “magic box” for the secret “slope” value s1. Indeed, if our public key had the form (A, t := As1), this would be extremely reminiscent of the discrete logarithm realization from the previous post, where we computed (g, gm mod p) for some random “generator” g. The messy and obvious question we must ask, therefore, is: what purpose is s2 serving here?
We won’t answer this question just now. For the moment I’m going to leave this as the “Chekhov’s gun” of this story.
Step 2: putting a “y-intercept” into a second magic box. If Dilithium follows the Schnorr paradigm, signing a new message should require the selection of a fresh random “y-intercept” value. This ensures that the signer is using a different line each time she runs the protocol. If Peggy were to omit this step, she’d be continuously producing “points” on a single “line” — which would very quickly allow any party to recover her secret slope.
A quick glance at the signing algorithm reveals a good candidate for this value. Conveniently, it’s a vector named y:
This vector y is subsequently fed into something that looks quite similar to the “magic box” we saw back in key generation. Here again we see our matrix A, which is then multiplied to produce Ay at line (8). But from this point the story proceeds differently: rather than adding a second vector to this product, as in the key generation routine, the value Ay is instead fed into a mysterious subroutine:
w1 := HighBits(Ay, 2𝛄2)
Although this looks slightly different from the magic box we built during key generation, I’m still going to go out on a limb and guess that w1 will still comprise our second “magic box” for y, and that this will be sent to the Verifier.
Unfortunately, this elegant explanation still leaves us with three “mysteries”, which we must attempt to resolve before going forward.
Mystery #1: if w1 is the “box”, why doesn’t the Sign algorithm output it?
If w1 is our “magic box,” then we should expect to see it output as part of the signature. And yet we don’t see this at all. Instead the Sign algorithm feeds w1 into a hash function H to produce a digest c. The pair (c, z) is actually what gets output as our signature.
Fortunately this mystery, at least, has a simple explanation.
What is happening in this routine is that we are using Fiat-Shamir to turn an interactive Identification Protocol into a non-interactive signature. And if you recall the previous post, you may remember that there are two different ways to realize Fiat-Shamir. In all cases the signer will first hash the magic box(es) to obtain a challenge. From here, things can proceed differently.
In the first approach, the Signer would output the “magic box” (here w1) as part of the signature. The Verifier will hash the public key and “box” to obtain the challenge, and use the challenge (plus magic boxes) to verify the response/point z given by the Signer.
In the alternative approach, the signer will only output the hash (digest) of the box (here c) along with enough material to reconstruct the magic boxw1 during verification. The Verifier will then reconstruct w1 from the information it was given, then hash to see if what it reconstructed produces the digest c included in the signature.
These two approaches are both roughly equivalent for security, but they have different implications for efficiency. If the value w1 is much larger than c, it generally makes sense to employ the second approach, since you’ll get smaller signatures.
A quick glance at the Verify algorithm confirms that Dilithium has definitely chosen to go with the second approach. Here we see that the Verifier uses the public key (A, t) as well as z from the signature to reconstruct a guess for the “magic box” w1. She then hashes this value to see if the result is equal to c:
So that answers the easy question. Now let’s tackle the harder one:
Mystery #2: what the heck does the function HighBits() do in these algorithms?
This was a whole lot of words, folks.
Based solely on the name (because the specification is too verbose), we can hazard a simple guess: HighBits outputs only the high-order bits of the elements of Ay.
(With a whole lot more verbiage, the detailed description at right confirms this explanation.)
So that answers the “what.” The real question is: why?
One possible explanation is that throwing away some bits of Ay will make the “magic box” w1 shorter, which would lead to smaller signatures.But as we discussed above, w1 is not sent as part of the signature. Instead, the Sign algorithm hashes w1 and sends only the resulting digest c, which is always pretty short. Compressing w1 is unlikely to give any serious performance benefit, except for making a fast hash function marginally faster to compute.
To understand the purpose of HighBits() we need to look to a different explanation.
Our biggest clue in doing this is that HighBits gets called not once, but twice: first it is called in the Sign algorithm, and then it is called a second time in Verify. A possible benefit of using HighBits() here would be apparent if, perhaps, we thought the input to these distinct invocations might be very similar but not exactly the same. If this were to occur — i.e., if there was some small “error” in one of the two invocations — then throwing away the insignificant bits might allow us to obtain the same final result in both places.
Let’s provisionally speculate that this is going to be important further down the line.
Mystery #3: why does the Sign algorithm have a weird “quality check” loop inside of it?
A final‚ and thus far unexplained, aspect of the Sign algorithm is that it does not simply output the signature after computing it. Instead it first performs a pair of “quality checks” on the result — and in some cases will throw away a generated signature and re-generate the whole thing from scratch, i.e., sampling a new random y and then repeating all the steps:
This is another bizarre element of the scheme that sure seems like it might be important! But let’s move on.
Steps 3 & 4: Victor picks a random point to evaluate on, and Peggy evaluates the line using her secret equation. As noted above, we already know that our signer will compute a Fiat-Shamir hash c and then use it to evaluate something that, at least looks like a Schnorr linear equation (although in this case it involves addition and multiplication of vectors.)
Assuming the result passes the “quality checks” mentioned above, the output of the signing algorithm is this value z as well as the hash digest c.
Step 5: use the “magic boxes” to verify the signature is valid. In the most traditional (“standard Fiat-Shamir variant”) realization of a Schnorr protocol, the verification routine would first hash the magic boxes together with the message to re-compute c. Then we would use the magic boxes (t and w1) to somehow “test” whether the signer’s response z satisfies the Schnorr equation.
As noted above, Dilithium uses Fiat-Shamir in an alternative mode. Here the signature comprises (z, c), and verification will therefore require us re-compute the “magic box” w1 and hash it to see if the result matches c. Indeed, we’ve already seen from the Verify routine that this is exactly what happens:
All that remains now is to mindlessly slog through the arithmetic to see if any of it makes sense. Recall that in the signing routine, we computed w1 as:
w1 := HighBits(Ay, 2𝛄2)
In the Verify routine we re-compute the box (here labeled w’1) as follows. Note that I’ve taken the liberty of substituting in the definitions of z and t and then simplifying:
As you can see, these two calculations — that is, the inputs that are passed into the HighBits routine in both places — do not produce precisely the same result. In the signing routine the input is Ay, and in the verification routine it is Ay – cs2. These are not the same! And yet, for verification to work, the output of HighBits() must be equal in both cases.
If you missed some extensive foreshadowing, then you’ll be astounded to learn that this new problem is triggered by the presence of our mystery vector s2 inside of the public key. You’ll recall that I asked you to ignore s2, but reminded you it would trip us up later.
Chekov’s gun!
The presence of this weird extra s2 term helps to explains some of the “mysteries” we encountered within the Sign routine. The most notable of these is the purpose of HighBits(). Concretely: by truncating away the low-order bits of its input, this routine must “throw away” the bits that are influenced by the ugly additional term “cs2” that shows up in the Verify equation. This trim ensures that signature verification works correctly, even in the presence of the weird junk vector s2 left over from our public key.
Of course this just leaves us with some new mysteries! Like, for example:
Mystery #4: why is the weird junk vector s2inside of our public key in the first place!?
We’ll return to this one!
Mystery #5: how can we be sure that the weird additive junk “cs2” will always be filtered out by the HighBits() subroutine during signature verification?
We’ve hypothesized that HighBits() is sufficient to “filter out” the extra additive term cs2, which should ensure that the two invocations within Sign and Verify will each produce the same result (w1 and w’1 respectively.) If this is true, the re-computed hash c will match between the two routines and signature verification will succeed.
Without poking into the exact nature and distribution of these terms, we can infer that the term cs2 must be “insignificant enough” in practice that it will be entirely removed by HighBits during verification — at least most of the time. But how do we know that this will always be the case?
For example, we could imagine a situation where most of the time HighBits clears away the junk. And yet every now and again the term cs2 is just large enough that the additive term will “carry” into the more significant bits. In this instance we would discover, to our chagrin, that:
HighBits(Ay, 2𝛄) ≠ HighBits(Ay – cs2, 2𝛄)
And thus even honestly-generated signatures would not verify.
This “quality check” ensures that the signature will verify correctly.
The good news here is that — provided this event does not occur too frequently — we can mostly avoid this problem. That’s because the signer can examine each signature before it outputs a result, i.e., it can run a kind of “quality check” on the result to see if a generated signature will verify correctly, and discard it if it does not. And indeed, this explanation partially resolves the mystery of the “quality checks” we encountered during signature generation — though, importantly, it explains only one of the two checks!
And that leads us to our final mystery:
Mystery #6: what is the second “quality check” there for?
We’ve explained the first of our two quality checks as an attempt to make the scheme verify. So what does this other one do?
Hopefully we’ll figure that out later down the line.
Leaving aside a few unanswered mysteries, we’ve now come to the end of the purely mechanical explanation of Dilithium signatures. Everything else requires us to look a bit more closely at how the machinery works.
What are these magic boxes?
As we discussed in the previous post, the best real-life analog of a “magic box” is some kind of one-way function that has useful algebraic properties. In practice, we obtain these functions by identifying a “hard” mathematical problem — more precisely, a problem that requires infeasible time and resource-requirements for computers to solve — and then figuring out how to use it in our schemes.
Dilithium is based on a relatively new mathematical problem called Module Learning with Errors (MLWE). This problem sits at the intersection of two different subfields: lattice–based cryptography and code-based cryptography. For a proper overview of LWE (of which MLWE is a variant), I strongly recommend you read this survey by Regev. Here in this post, my goal is to give you a vastly more superficial explanation: one that is just sufficient to help explain some of the residual “mysteries” we noticed above.
The LWE problem assumes that we are given the approximate solutions of a series of linear equations over some ring. Our goal is to recover a secret vector s given a set of non-secret coefficients. To illustrate this problem, Regev gives the following toy example:
Note that if the solutions on the right-hand side were exact, then solving for the values s = (s1, …, s4) could be accomplished using standard linear algebra. What makes this problem challenging is that the solutions are only approximate. More concretely, this means that the solutions we are given on the right side contain a small amount of additive “error” (i.e., noise.)
Note that the error terms here are small: in this example, each equation could be accurate within a range of -1 to +1. Nonetheless, the addition of this tiny non-uniform error makes solving these problems vastly harder to both classical and quantum computers. Most critically, these error terms are essential to the conjectured “hardness” of this function — they cannot be wished away or eliminated.
A second important fact is that the secret coefficients (the ones that make up s) are also small and are not drawn uniformly from the ring. In fact, if the secret terms and error were drawn uniformly from the ring, this would make solving the system of equations trivially easy — there would potentially be many possible solutions to the system of equations. Hence it is quite important to the hardness of the (M)LWE function that these values be “small.” You’ll have to take my word for this, or else read deeper into the Regev survey to understand the detailed reasoning, but this will be very important to us going forward.
Of course, big systems of equations are tough to look at. A more concise way to represent the above is to describe the non-secret (random) coefficients as a matrix A, and then — using s1 to represent our secret — the exact solution to these equations can be represented by the product As1. If we express those additive “error terms” as a second vector s2, the entire LWE “function” can thus be succinctly expressed as:
A, t = As1 + s2
For this function to be a good magic box, we require that given (A, t), it is hard to recover (at least) s1.1 You’ll note that — ignoring many of the nitty-gritty details, including the nature of the ring we’re using and the distribution of s1 and s2 — this is essentially the structure of the public key from the Dilithium specification.
So what should we learn from this?
A clear implication is that the annoying error vectors2 is key to the security of the “magic box” used in Dilithium. If we did not include this term, then an attacker might be able to recover s1 from Dilithium’s public key, and thus could easily forge signatures. At the same time, we can observe that this error vector s2 will be “small” in terms of the magnitude of its elements, which helps explain why we can so easily dispense with its effects by simply trimming away the low-order bits of the product Ay (resp. Ay – cs2) inside of the signing and verification functions.
Phew.
A reasonable person might be satisfied at this point that Dilithium is essentially a variant of Schnorr, albeit one that uses very different ingredients from the classical Schnorr signatures. After all, the public key is just a “magic box” embedding the secret value s1, with some error thrown in to make it irreversible. The signature embeds a weird magic box computed on a value y as well as a “Schnorr-like” vector z = y + cs1 on some challenge point c, which can be approximately “tested” using the various boxes. What more is there to say?
But there remains one last critical mystery here, one that we haven’t addressed. And that mystery lives right here, in the form of a second “quality check” that we still have not explained:
What does this second “quality check” do?
To figure out why we need this second quality check, we’ll need to dive just a little bit deeper into what these values actually represent.
Is Dilithium secure?
If you recall the previous post, we proposed three different properties that a Schnorr-like Identification Protocol should satisfy. Specifically, we wanted to ensure that our protocols are (1) correct, (2) sound, and (3) private — i.e., they not leak their secret key to any Verifier who sees a few transcripts.
Correctness. This simply means that honestly-generated signatures will verify. I hope at this point that we’ve successfully convinced ourselves that Dilithium will likely achieve this goal, provided we get out of the “quality check” loop. (Since producing a valid signature may require multiple runs through the “quality check” loop, we do need to have some idea of how likely a “bad” signature is — the Dilithium authors perform this analysis and claim that 4-7 iterations is sufficient in most cases.)
Soundness. This property requires that we consider the probability that a dishonest signer (one who does not know the secret key) can produce a valid signature. This hangs on two principles: (1) the non-reversibility of the public key “magic box”, or more concretely: the assumed one-wayness of the MLWE function. It also requires (2) a more involved argument about the signer’s ability to compute responses.
In this post we will choose to take the actual hardness of MLWE for granted (i.e., we are perfectly happy to make analyzing that function into some other cryptographer’s problem!) Hence we need only consider the second part of the argument.
Specifically: let’s consider Dilithium as a pure interactive identification protocol. Let us imagine that a prover can satisfy the protocol when handed some random challenge c by the Verifier, and they can do this with high probability for many different possible values of c. If we follow the logic here, this would seem to intuitively imply that such a prover can therefore pick a value y, and then compute a response z for multiple possible c values that they may be handed. Concretely we can imagine that such a prover could produce a few values of the form:
zi = y +ci s1
If a prover can compute at least two such values (all using the same value of y, but different values of c), then presumably she could then use the values to derive s1 itself — simply by subtracting and solving for s1. What we are saying here, very informally, is that any prover who has the knowledge to successfully run the protocol this way is equivalent (up to a point) to a prover who knows the secret key. Although we will not dwell on the complete argument or the arithmetic, this does not seem like an unreasonable argument to make for Dilithium.2
Privacy (or “zero knowledge”.) The most challenging part of the original Schnorr proof was the final argument, namely the one that holds that learning a protocol transcript (or signature) will not reveal the secret key. This privacy, or “zero-knowledge” argument, is one of the most important things we addressed in the previous post.
We can found this argument on the following claim: any number of signatures (or interactive protocol) transcripts, by themselves, do not leak any useful information that can be used by an attacker to learn about the secret key. In order to make this argument successfully for Schnorr, we came at it in a particularly bizarre way: namely, we argued that this had to be true, since any random stranger can produce a correctly-distributed Schnorr transcript — whether or not they know the secret key.
For the traditional Schnorr protocol we pointed out that it is possible to manufacture a “fake” transcript by (1) selecting a random challenge and response, and then (2) “manufacturing” a new magic box to contain a new (to us unknown!) y-intercept for the line.
Translating this approach to the interactive version of the Dilithium protocol, this would require us to first sample the challenge c, then sample the response z from its appropriate distribution. We would then place z into a fresh magic box (“Az”), and compute something like this (here boxes represent MLWE functions):
(Or more concretely, “Ay” = Az – ct. Note that t = As1 + s2 and so this gives us a slightly “wrong” answer due to the presence of s2, but using the HighBits function on this result should strip that out and give us the correct “box” value.)
Given the calculation above, we can use the HighBits() function to compute w1 given the “boxed” version of y.3
The main question we would have to ask now is: is this simulated transcript statistically identical to the real transcript that would be produced by a legitimate signer? And here we run into a problem that has not been exposed throughout this post, mostly because we’ve been ignoring all of the details.
The map is not the territory!
Up to this point we’ve mostly been ignoring what’s “inside” of each of the various vectors and matrices (y, z, A and so on.) This has allowed us to make good progress, and ignoring the details was acceptable for a high-level explanation. Unfortunately when we talk about security, these details really matter.
I will make this as quick and painless as I possibly can.
In Dilithium, all elements in these arrays and vectors consist of polynomials in the ring . Each “element” is actually a vector of coefficients representing a polynomial of the form , where every coefficient is a integer modulo q. These polynomials can be added and multiplied using standard operations built from modular arithmetic. For Dilithium, we “conveniently” fix q = 223 − 213 + 1 and n = 256.
(For an engineering-oriented overview of how to work with these elements, see this post by Filippo Valsorda. Although Filippo is describing Kyber, which uses a different q, the arithmetic is similar.)
What’s important in Dilithium is how all of our various random matrices and vectors are sampled. We will note first that the matrix A consists of polynomials whose coefficients are sampled uniformly from {0, .., q-1}. However, the remaining vectors such as s1, s2and y comprise coefficients that are not chosen this way, because the requirements of the MLWE function dictate that they cannot be sampled uniformly. And this will be critical to understanding the security arguments.
Let’s take a look back at the key generation and signing routines:
Notice the small subscripts used in generating y and both s1, s2. These indicate that the coefficients in these vectors are restricted to a subset of possible values, those less than some chosen parameter. In the case of the vectors s1, s2this is an integer η that is based on study of the MLWE problem. For the vector y the limit is based on a separate scheme parameter ɣ1, which is also based on the MLWE problem (and some related complexity assumptions.)
At this point I may as well reveal one further detail: our hash function H does not output something as simple as a scalar or a uniform element of the ring. Instead it outputs a “hamming ball” coefficient vector that comprises mostly 0 bits, as well as exactly r bits that contain either +1 or -1. (Dilithium recommends r=60.) This hash will be multiplied by s1 when computing z.
Once you realize that Dilithium’s s1, y and c are not uniform, as they were in the original Schnorr scheme, then this has some implications for the security of the response value z:=y + cs1 that the signer outputs.
Consider what would happen if the signer did not add the term y to this equation, i.e., it simply output the product cs1 directly. This seems obviously bad: it this would reveal information about the secret key s1, which would imply a leak of at least some bits of the secret key (given a few signatures.) Such a scheme should obviously not be simulatable, since we would not be able to simulate it without knowing the secret key. The addition of the term y is critical to the real-world security of the scheme, since it protects the secrecy of the secret key by “blinding it.”
(Or, if you preferred the geometric security intuition from the previous post: the signer chooses a fresh “y-intercept” each time she evaluates the protocol, because this ensures that the Verifier will not receive multiple points on the same line and thus be able to zero in on the slope value. In classical Schnorr this y-intercept is sampled uniformly from a field, so it perfectly hides the slope. Here we are weakening the logic, since both the slope and y-intercept are drawn from reduced [but non-identical] distributions!)
The problem is that in Dilithium the term y is not sampled uniformly: its coefficients are relatively small. This means that we can’t guarantee that z:=y + cs1 will perfectly hide the coefficients of cs1 and hence the secret key. This is a very real-world problem, not just something that shows up in the security proof! The degree of “protection” we get is going to be related to the relative magnitude of the coefficients of cs1 and y. If the range of the coefficients of y is sufficiently large compared to the coefficients of cs1, then the secret key may be protected — but other times when the coefficients of cs1 are unusually large, they may “poke out”, like a pea poking through a too-thin mattress into a princess’s back.
Here the black arrows represent the coefficients of cs1 and the red lines are the coefficients of y. Their sum forms the coefficients of z. None of this is to scale. If any coefficients poke through too much, this leaks information about the bits of the secret key!
The good news is that we can avoid these bad outcomes by carefully selecting the range of the y values so that they are large enough to statistically “cover” the coefficients of cs1, and by testing the resulting z vector to ensure it never contains any particularly large coefficients that might represent the coefficients of cs1 “poking through.”
Concretely, note that each coefficient of s1 was chosen to be less than η, and there are at most r non-zero (+1, -1) bits set in the hash vector c. Hence the direct product cs1 will have be a vector where all coefficients are of size at most β ≤ r*η. The coefficients of y, by construction, are all at most ɣ1. The test Dilithium uses is to reject a signature if any coefficient of the result z is greater than the difference of these values, ɣ1 – β. Which is precisely what we see in the second “quality check” of the signing algorithm:
With this test in the real protocol, the privacy (zero-knowledge) argument for the Identification Protocol is now satisfied. It is always the case that as long as the vector z is chosen to be within the given ranges, the distribution of our simulated transcripts will be identical to that of the real protocol. (A more formal argument is given in Appendix B of the spec, or see this paper that introduced the ideas.)
Conclusion… plus everything I left out
First of all, if you’re still reading this: congratulations. You should probably win a prize of some sort.
This has been a long post! And even with all this detail, we haven’t managed to cover some of the more useful details, which include a number of clever efficiency optimizations that reduce the size of the public key and make the algorithms more efficient. I have also left out the “tight” security reduction that rely on some weird extra additional complexity assumptions, because these assumptions are nuts. This stuff is all described well in the main spec above, if you want the details.
But more broadly: what was the point of all this?
My goal in writing this post was to convince you that Dilithium is “easy” to understand — after all, it’s just a Schnorr signature built using alternative ingredients, like a loaf of bread made with almond flour rather than with wheat. There’s nothing really scary about PQC signatures or lattices, if you’re willing to understand a few simple principles.
And to some extent I feel like I succeeded at that.
To a much greater extent, however, I feel like I convinced myself of just the opposite. Specifically, writing about Dilithium has made me aware of just how precise and finicky these post-quantum schemes are, how important the details are, particularly to the simpler old discrete logarithm setting. Maybe this will improve with time and training: as we all get more familiar using these new tools, we’ll get better at specifying the the building blocks in a clear, modular way and won’t have to get so deep into various details each time we design a new protocol. Or maybe that won’t happen, and these schemes are just going to be fundamentally a bit less friendly to protocol designers than the tools we’ve used in the past.
In either case, I’m hoping that a generation of younger and more flexible cryptographers will deal with that problem when it comes.
Notes:
In practice, the LWE assumption is actually slightly stronger than this. It states that the pair (A, t = As1 + s2) is indistinguishable from a pair (A, u) where u is sampled uniformly — i.e., no efficient algorithm can guess the difference with more than a negligible advantage over random guessing. Since these distributions are quite different, however, this indistinguishability must imply one-wayness of the underlying function.
As mentioned in a footnote to the previous post, this can actually be done by “rewinding” a prover/signer. The idea in the security proof is that if there exists an adversary (a program) that can forge the interactive protocol with reasonable probability, then we can run it up until it has output y. Then we can run it forward on a first challenge c1 to obtain z1. Finally, we can “rewind” the prover by running it on the same inputs/random coins until it outputs y again, but this time we can challenge it on a different value c2 to obtain z2. And at this point we can calculate s1 from the pair of responses.
This argument applies to the Dilithium Identification Protocol, which is a thing that doesn’t really exist (except for implicitly.) In that protocol a “transcript” consists of the triple (w1, c, z). Since that protocol is interactive, there’s no problem with being able to fake a transcript — the protocol only has soundness if you run it interactively. Notice that for Dilithium signatures, things are different; you should not be able to “forge” a Dilithium signature under normal conditions. This unforgeability is enforced by the fact that c is the output of a hash function H and this will be checked during verification, and so you can’t just pick c arbitrarily. The zero-knowledge argument still holds, but it requires a more insane argument that has to do with the “model” we use where in the specific context of the security proof we can “program” (tamper with) the hash function H.
Warning: extremely wonky cryptography post. Also, possibly stupid and bound for nowhere.
One of the hardest problems in applied cryptography (and perhaps all of computer science!) is explaining why our tools work the way they do. After all, we’ve been gifted an amazing basket of useful algorithms from those who came before us. Hence it’s perfectly understandable for practitioners to want to take those gifts and simply start to apply them. But sometimes this approach leaves us wondering why we’re doing certain things: in these cases it’s helpful to take a step back and think about what’s actually going on, and perhaps what was in the inventors’ heads when the tools were first invented.
In this post I’m going to talk about signature schemes, and specifically the Schnorr signature, as well as some related schemes like ECDSA. These signature schemes have a handful of unique properties that make them quite special among cryptographic constructions. Moreover, understanding the motivation of Schnorr signatures can help understand a number of more recent proposals, including post-quantum schemes like Dilithium — which we’ll discuss in the second part of this series.
As a motivation for this post, I want to talk about this tweet:
Instead of just dumping Schnorr signatures onto you, I’m going to take a more circuitous approach. Here we’ll start from the very most basic building blocks (including the basic concept of an identification protocol) and then work our way gradually towards an abstract framework.
Identification protocols: our most useful building block
If you want to understand Schnorr signatures, the very first thing you need to understand is that they weren’t really designed to be signatures at all, at least not at first. The Schnorr protocol was designed as an interactiveidentification scheme, which can be “flattened” into the signature scheme we know and love.
An identification scheme consists of a key generation algorithm for generating a “keypair” comprising a public and secret key, as well as aninteractive protocol (the “identification protocol”) that uses these keys. The public key represents its owners’ identity, and can be given out to anyone. The secret key is, naturally, secret. We will assume that it is carefully stored by its owner, who can later use it to prove that she “owns” the public key.
The identification protocol itself is run interactively between two parties — meaning that the parties will exchange multiple messages in each direction. We’ll often call these parties the “prover” and the “verifier”, and many older papers used to give them cute names like “Peggy” and “Victor”. I find this slightly twee, but will adopt those names for this discussion just because I don’t have any better ideas.
To begin the identification protocol, Victor must obtain a copy of Peggy’s public key. Peggy for her part will possess her secret key. The goal of the protocol is for Victor to decide whether he trusts Peggy:
High level view of a generic interactive identification protocol. We’ll assume the public key was generated in a previous key generation phase. (No, I don’t know why the Verifier has a tennis racket.)
Note that this “proof of ownership” does not need to be 100% perfect. We only ask that it is sound with extremely high probability. Roughly speaking, we want to ensure that if Peggy really owns the key, then Victor will always be convinced of this fact. At the same time, someone who is impersonating Peggy — i.e., does not know her secret key — should fail to convince Victor, except with some astronomically small (negligible) probability.
(Why do we accept this tiny probability of an impersonator succeeding? It turns out that this is basically unavoidable for any identification protocol. This is because the number of bits Peggy sends to Victor must be finite, and we already said there must exist at least one “successful” response that will make Victor accept. Hence there clearly exists an adversary who just guesses the right strings and gets lucky very ocasionally. As long as the number of bits Peggy sends is reasonably large, then such a “dumb” adversary should almost never succeed, but they will do so with non-zero probability.)
The above description is nearly sufficient to explain the security goals of an identification scheme, and yet it’s not quite complete. If it was, then there would be a very simple (and yet obviously bad) protocol that solves the problem: the Prover could simply transmit its secret key to the Verifier, who can presumably test that it matches with the public key:
This usually works, but don’t do this, please.
If all we cared about was solving the basic problem of proving ownership in a world with exactly one Verifier who only needs to run the protocol once, the protocol above would work fine! Unfortunately in the real world we often need to prove identity to multiple different Verifiers, or to repeatedly convince the same Verifier of our identity. The problem with the strawman proposal above is that at the end of a single execution, Victor has learned Peggy’s secret key (as does anyone else who happened to eavesdrop on their communication.) This means that Victor, or any eavesdropper, will now be able to impersonate Peggy in future interactions.
And that’s a fairly bad feature for an identification protocol. To deal with this problem, a truly useful identification protocol should add at least one additional security requirement: at the completion of this protocol, Victor (or an eavesdropper) should not gain the ability to mimic Peggy’s identity to another Verifier. The above protocol clearly fails this requirement, since Victor will now possess all of the secret information that Peggy once had.
This requirement also helps to why identification protocols are (necessarily) interactive, or at least stateful: even if Victor did not receive Peggy’s secret key, he might still be able to record any messages sent by Peggy during her execution of the protocol with him. If the protocol was fully non-interactive (meaning, it consists of exactly one message from Peggy to Victor) then Victor could later “replay” his recorded message to some other Verifier, thus convincing that person that he is actually Peggy. Many protocols have suffered from this problem, including older vehicle immobilizers.
The classical solution to this problem is to organize the identification protocol to have a challenge-response structure, consisting of multiple interactive moves. In this approach, Victor first sends some random “challenge” message to Peggy, and then Peggy then constructs her response so that it is specifically based on Victor’s challenge. Should a malicious Victor attempt to impersonate Peggy to a different Verifier, say Veronica, the expectation is that Veronica will send a different challenge value (with high probability), and so Victor will not be able to use Peggy’s original response to satisfy Veronica’s new challenge.
(While interaction is generally required, in some instances we can seemingly “sneak around” this requirement by “extracting a challenge from the environment.” For example, real-world protocols will sometimes ‘bind’ the identification protocol to metadata such as a timestamp, transaction details, or the Verifier’s name. This doesn’t strictly prevent replay attacks — replays of one-message protocols are always possible! — but it can help Verifiers detect and reject such replays. For example, Veronica might not accept messages with out-of-date timestamps. I would further argue that, if one squints hard enough, these protocols are still interactive. It’s just that the first move of the interaction [say, querying the clock for a timestamp] is now being moved outside of the protocol.)
How do we build identification schemes?
Once you’ve come up with the idea of an identification scheme, the obvious question is how to build one.
The simplest idea you might come up with is to use some one-way function as your basic building block. The critical feature of these functions is that they are “easy” to compute in one direction (e.g., for some string x, the function F(x) can be computed very efficiently.) At the same time, one-way functions are hard to invert: this means that given F(x) for some random input string x — let’s imagine x is something like a 128-bit string in this example — it should take an unreasonable amount of computational effort to recover x.
I’m selecting one-way functions because we have a number of candidates for them, including cryptographic hash functions as well as fancier number-theoretic constructions. Theoretical cryptographers also prefer them to other assumptions, in the sense that the existence of such functions is considered to be one of the most “plausible” cryptographic assumptions we have, which means that they’re much likelier to exist than more fancy building blocks.
The problem is that building a good identification protocol from simple one-way functions is challenging. An obvious starting point for such a protocol would be for Peggy to construct her secret key by selecting a random string sk (for example, a 128-bit random string) and then computing her public key as pk = F(sk).
Now to conduct the identification protocol, Peggy would… um… well, it’s not really clear what she would do.
The “obvious” answer would be for Peggy to send her secret key sk over to Victor, and then Victor could just check that pk = F(sk). But this is obviously bad for the reasons discussed above: Victor would then be able to impersonate Peggy after she conducted the protocol with him even one time. And fixing this problem turns out to be somewhat non-trivial!
There are, of course, some clever solutions — but each one entails some limitations and costs. A “folklore”1 approach works like this:
Instead of picking one secret string, Peggy picks N different secret strings to be her “secret key.”
She now sets her “public key” to be .
In the identification protocol, Victor will challenge Peggy by asking her for a random k-sized subset of Peggy’s strings (here k is much smaller than N.)
Peggy will send back the appropriate list of k secret strings.
Victor will check each string against the appropriate position in Peggy’s public key.
The idea here is that, after running this protocol one time, Victor learns some but not all of Peggy’s secret strings. If Victor was then to attempt to impersonate Peggy to another person — say, Veronica — then Veronica would pick her own random subset of k strings for Victor to respond to. If this subset is identical to the one Victor chose when he interacted with Peggy, then Victor will succeed: otherwise, Victor will not be able to answer Veronica’s challenge. By carefully selecting the values of N and k, we can ensure that this probability is very small.2
An obvious problem with this proposal is that it falls apart very quickly if Victor can convince Peggy to run the protocol with him multiple times.
If Victor can send Peggy several different challenges, he will learn many more than k of Peggy’s secret strings. As the number of strings Victor learns increases, Victor’s ability to answer Veronica’s queries will improve dramatically: eventually he will be able to impersonate Peggy nearly all of the time. There are some clever ways to address this problem while still using simple one-way functions, but they all tend to be relatively “advanced” and costly in terms of bandwidth and computation. (I promise to talk about them in some other post.)
Schnorr
So far we have a motivation: we would like to build an identification protocol that is multi-use — in the sense that Peggy can run the protocol many times with Victor (or other verifiers) without losing security. And yet one that is also efficient in the sense that Peggy doesn’t have to exchange a huge amount of data with Victor, or have huge public keys.
Now there have been a large number of identity protocols. Schnorr is not even the first one to propose several of the ideas it uses. “Schnorr” just happens to be the name we generally use for a class of efficient protocols that meet this specific set of requirements.
Some time back when Twitter was still Twitter, I asked if anyone could describe the rationale for the Schnorr protocol in two tweets or less. I admit I was fishing for a particular answer, and I got it from Chris Peikert:
I really like Chris’s explanation of the Schnorr protocol, and it’s something I’ve wanted to unpack for while now. I promise that all you really need to understand this is a little bit of middle-school algebra and a “magic box”, which we’ll do away with later on.
Let’s tackle it one step at a time.
First, Chris proposes that Peggy must choose “a random line.” Recalling our grade-school algebra, the equation for a line is y = mx + b, where “m” is the line’s slope and “b” its y-intercept. Hence, Chris is really asking us to select a pair of random numbers (m, b). (For the purposes of this informal discussion you can just pretend these are real numbers in some range. However later on we’ll have them be elements of a very large finite field or ring, which will eliminate many obvious objections.)
Here we will let “m” be Peggy’s secret key, which she will choose one time and keep the same forever. Peggy will choose a fresh random value “b” each time she runs the protocol. Critically, Peggy will put both of those numbers into a pair of Chris’s magic box(es) and send them over to Victor.
Finally, Victor will challenge Peggy to evaluate her line at one specific (random) point x that he selects. This is easy for Peggy, who can compute the corresponding value y using her linear equation. Now Victor possesses a point (x, y) that — if Peggy answered correctly — should lie on the line defined by (m, b). He simply needs to use the “magic boxes” to check this fact.
Here’s the whole protocol:
Chris Peikert’s “magic box” protocol. The only thing I’ve changed from his explanation is that there are now two magic boxes, one that contains “m” and one that contains “b“. Victor can use them together to check Peggy’s response y at the end of the protocol.
Clearly this is not a real protocol, since it relies fundamentally on magic. With that said, we can still observe some nice features about it.
A first thing we can observe about this protocol is that if the final check is satisfied, then Victor should be reasonably convinced that he’s really talking to Peggy. Intuitively, here’s a (non-formal!) argument for why this is the case. Notice that to complete the protocol, Peggy must answer Victor’s query on any random x that Victor chooses. If Peggy, or someone impersonating Peggy, is able to do this with high probability for any random point x that Victor might choose, then intuitively it’s reasonable that she could (in her own head, at least) compute a similar response for a second random point x’. Critically, given two separate points (x,y), (x’, y’) all on the same line, it’s easy to calculate the secret slope m — ergo, a person who can easily compute points on a line almost certainly knows Peggy’s secret key. (This is not a proof! It’s only an intuition. However the real proof uses a similar principle.2)
The question, then, is what Victor learns after running the protocol with Peggy.
If we ignore the magical aspects of the protocol, the only thing that Victor “learns” by at end of the protocol is a single point (x, y) that happens to lie on the random line chosen by Peggy. Fortunately, this doesn’t reveal very much about Peggy’s line, and in particular, it reveals very little about her secret (slope) key. The reason is that for every possible slope value m that Peggy might have chosen as her key, there exists a value b that produces a line that intersects (x, y). We can illustrate this graphically for a few different examples:
I obviously did not use a graphing tool to make this disaster.
Naturally this falls apart if Victor sees two different points on the same line. Fortunately this never happens, because Peggy chooses a different line (by selecting a new b value) every time she runs the protocol. (It would be a terrible disaster if she forgot to do this!)
The existence of these magic boxes obviously makes security a bit harder to think about, since now Victor can do various tests using the “boxes” to test out different values of m, b to see if he can find a secret line that matches. But fortunately these boxes are “magic”, in the sense that all Victor can really do is test whether his guesses are successful: provided there are many possible values of m, this means actually searching for a matching value will take far too long to be useful.
Now, you might ask: why a line? Why not a plane, or a degree-8 polynomial?
The answer is pretty simple: a line happens to be one of the simplest mathematical structures that suits our needs. We require an equation for which we can “safely” reveal exactly one solution, without fully constraining the terms of its equation. Higher-degree polynomials and planar equations also possess this capability (indeed we can reveal more points in these structures), but each has a larger and more complex equation that would necessitate a fancier “magic box.”
How do we know if the “magic box” is magic enough?
Normally when people learn Schnorr, they are not taught about magic boxes. In fact, they’re typically presented with a bunch of boring details about cyclic groups.
The problem with that approach is that it doesn’t teach us anything about what we need from that magic box. And that’s a shame, because there is not one specific box we can use to realize this class of protocols. Indeed, it’s better to think of this protocol as a set of general ideas that can be filled in, or “instantiated” with different ingredients.
Hence: I’m going to try a different approach. Rather than just provide you with something that works to realize our magic box as a fait accompli, let’s instead try to figure out what properties our magical box must have, in order for it to provide us with a secure protocol.
Simulating Peggy
There are essentially three requirements for a secure identification protocol. First, the protocol needs to be correct — meaning that Victor is always convinced following a legitimate interaction with Peggy. Second, it needs to be sound, meaning that only Peggy (and not an impersonator) can convince Victor to accept.
We’ve made an informal argument for both of these properties above. It’s important to note that each of these arguments relies primarily on the fact that our magic box works as advertised — i.e., Victor can reliably “test” Peggy’s response against the boxed information. Soundness also requires that bad players cannot “unbox” Peggy’s secret key and fully recover her secret slope m, which is something that should be true of any one-way function.
But these arguments don’t dwell thoroughly on how secure the boxes must be. Is it ok if an attacker can learn a few bits of m and b? Or do they need to be completely ideal. To address these questions, we need to consider a third requirement.
That requirement is that that Victor, having run the protocol with Peggy, should not learn anything more useful than he already knew from having Peggy’s public key. This argument really requires us to argue that these boxes are quite strong — i.e., they’re not going to leak any useful information about the valuable secrets beyond what Victor can get from black-box testing.
Recall that our basic concern here is that Victor will run the protocol with Peggy, possibly multiple times. At the end of each run of the protocol, Victor will learn a “transcript”. This contents of this transcript are 1) one magic box containing “b“, 2) the challenge value x that Victor chose, and 3) the response y that Peggy answered with. We are also going to assume that Victor chose the value x “honestly” at random, so really there are only two interesting values that he obtained from Peggy.
A question we might ask is: how useful is the information in this transcript to Victor, assuming he wants to do something creepy like pretend to be Peggy?
Ideally, the answer should be “not very useful at all.”
The clever way to argue this point is to show that Victor can perfectly “simulate” these transcripts without every even talking to Peggy at all. The argument thus proceeds as follows: if Victor (all by his lonesome) can manufacture a transcript that is statistically identical to the ones he’d get from talking to Peggy, then what precisely has he “learned” from getting real ones from Peggy at all? Implicitly the answer is: not very much.
So let’s take a moment to think about how Victor might (all by himself) produce a “fake” transcript without talking to Peggy. As a reminder, here’s the “magic box” protocol from up above:
One obvious (wrong) idea for simulating a transcript is that Victor could first select some random value b, and put it into a brand new “magic box”. Then he can pick x at random, as in the real protocol. But this straightforward attempt crashes pretty quickly: Victor will have a hard time computing y = mx + b, since he doesn’t know Peggy’s secret key m. His best attempt, as we discussed, would be to guess different values and test them, which will take too long (if the field is large.)
So clearly this approach does not work. But note that Victor doesn’t necessarily need to fake this transcript “in order.” An alternative idea is that Victor can try to make a fake transcript by working through the protocol in a different order. Specifically:
Victor can pick a random x, just as in the real protocol.
Now he can pick the value y also at random. Note that for every “m” there will exist a line that passes through (x, y).
But now Victor has a problem: to complete the protocol, he will need to make a new box containing “b”, such that b = y – mx.
There is no obvious way for Victor to calculate b given only the information he has in the clear. To address this third requirement, we must therefore demand a fundamentally new capability from our magic boxes. Concretely, we can imagine that there is some way to “manufacture” new magic boxes from existing ones, such that the new boxes contain a calculated value. This amounts to reversing the linear equation and then performing multiplication and subtraction on “boxed” values, so that we end up with:
What’s that, you say? This new requirement looks totally arbitrary? Well, of course it is. But let’s keep in mind that we started out by demanding magical boxes with special capabilities. Now I’m simply adding one more magical capability. Who’s to say that I can’t do this?
Recall that the resulting transcript must be statistically identical to the ones that Victor would get from Peggy. It’s easy enough to show that the literal values (x, y, b) will all have the same distribution in both versions. The statistical distribution of our “manufactured magical boxes” is a little bit more complicated, because what the heck does it mean to “manufacture a box from another box,” anyway? But we’ll just specify that the manufactured ones must look identical to the ones created in the real protocol.
Of course back in the real world this matters a lot. We’ll need to make sure that our magical box objects have the necessary features, which are (1) the ability to test whether a given (x, y) is on the line, and (2) the ability to manufacture new boxes containing “b” from another box containing “m” and a point (x, y), while ensuring that the manufactured boxes are identical to magical boxes made the ordinary way.
How do we build a magical box?
An obvious idea might be to place the secret values m and b each into a standard one-way function and then send over F(m) and F(b). This clearly achieves the goal of hiding the values of these two values: unfortunately, it doesn’t let us do very much else with them.
Indeed, the biggest problem with simple one-way functions is that there is only one thing you can do with them. That is: you can generate a secret x, you can compute the one-way function F(x), and then you can reveal x for someone else to verify. Once you’ve done this, the secret is “gone.” That makes simple one-way functions fairly limiting.
But what if F is a different type of one-way function that has some additional capabilities?
In the early 1980s many researchers were thinking about such one-way functions. More concretely, researchers such as Tahir Elgamal were looking at a then-new “candidate” one-way function that had been proposed by Whitfield Diffie and Martin Hellman, for use in their eponymous key exchange protocol.
Concretely: let p be some large non-secret prime number that defines a finite field. And let g be the “generator” of some large cyclic subgroup of prime order q contained within that field.3 If these values are chosen appropriately, we can define a function F(x) as follows:
The nice thing about this function is that, provided g and p are selected appropriately, it is (1) easy to compute this function in the normal direction (using square-and-multiply modular exponentiation) and yet is (2) generally believed to be hard to invert. Concretely, as long x is randomly selected from the finite field defined by {0, …, q-1}, then recovering x from F(x) is equivalent to the discrete logarithm problem.
But what’s particularly nifty about this function is that it has nice algebraic properties. Concretely, given F(a) and F(b) computed using the function above, we can easily compute F(a + b mod q). This is because:
Similarly, given F(a) and some known scalar c, we can compute F(a \cdot c):
We can also combine these capabilities. Given F(m) and F(b) and some x, we can compute F(y) where y = mx + b mod q. Almost magically means we can compute linear equations over values that have been “hidden” inside a one-way function, and then we can compare the result to a direct (alleged) calculation of y that someone else has handed us:
Implicitly, this gives us the magic box we need to realize Chris’s protocol from the previous section. The final protocol looks like this:
Appropriate cyclic groups can also be constructed within certain elliptic curves, such as the NIST P-256 and secp256k1 curve (used for Schnorr signatures in Bitcoin) as well as the EdDSA standard, which is simply a Schnorr signature implemented in the Ed25519 Edwards curve. Here the exponentiation is replaced with scalar point multiplication, but the core principles are exactly the same.
For most people, you’re probably done at this point. You may have accepted my claim that these “discrete logarithm”-based one-way functions are sufficient to hide the values (m, b) and hence they’re magic-box-like.
But you shouldn’t! This is actually a terrible thing for you to accept. After all, modular-exponentiation functions are not magical boxes. They’re real “things” that might potentially leak information about the points “m” and “b”, particularly since Victor will be given many different values to work with after several runs of the protocol.
To convince ourselves that the boxes don’t leak, we must use the intuition I discussed further above. Specifically, we need to show that it’s possible to “simulate” transcripts without ever talking to Peggy herself, given only her public key . Recall that in the discussion above, the approach we used was to pick a random point (x, y) first, and then “manufacture” a box as follows:
In our realized setting, this is equivalent to computing directly from and (x, y). Which we can do as follows:
(If you’re picky about things, here we’re abusing division as shorthand to imply multiplication by the multiplicative inverse of the final term.)
It’s easy enough to see that the implied value b = y – mx is itself distributed identically to the real protocol as long as (x, y) are chosen randomly. In that case it holds that will be distributed identically as well, since there is a one-to-one mapping between between each b and the value in the exponent. This is an extremely convenient feature of this specific magic box. Hence we can hope that this primitive meets all of our security requirements.
From ID protocols to signatures: Fiat-Shamir
While the post so far has been about identification protocols, you’ll notice that relatively few people use interactive ID protocols these days. In practice, when you hear the name “Schnorr” it’s almost always associated with signature schemes. These Schnorr signatures are quite common these days: they’re used in Bitcoin and form the basis for schemes like EdDSA.
There is, of course, a reason I’ve spent so much time on identification protocols when our goal was to get to signature schemes. That reason is due to a beautiful “trick” called the Fiat-Shamir heuristic that allows us to effortlessly move from three-move identification protocols (often called “sigma protocols”, based on the shape of the capital greek letter) to non-interactive signatures.
Let’s talk briefly about how this works.
The key observation of Fiat and Shamir was that Victor doesn’t really do very much within a three-move ID protocol: indeed, his major task is simply to select a random challenge. Surely if Peggy could choose a random challenge on her own, perhaps somehow based off a “message” of her choice, then she could eliminate the need to interact with Victor at all.
In this new setting, Peggy would compute the entire transcript on her own, and she could simply hand Victor a transcript of the protocol she ran with herself (as well as the message.) Provided the challenge value x could be bound “tightly” to a message, then this would convert an interactive protocol like the Schnorr identification protocol into a signature scheme.
One obvious idea would be to take some message M and compute the challenge as x = H(M).
Of course, as we’ve already seen above, this is a pretty terrible idea. If Peggy is allowed to know the challenge value x, then she can trivially “simulate” a protocol execution transcript using the approach described in the previous section — even if she does not know the secret key. The resulting signature would be worthless.
For Peggy to pick the challenge value x by herself, therefore, she requires a strategy for generating x that (1) can only be executed after she’s “committed” to her first magic box containing b, and (2) does not allow her predict or “steer” the value x that she’ll get at the end of this process.
The critical observation made by Fiat and Shamir was that Peggy could do this if she possessed a sufficiently strong hash function H. Their idea was as follows. First, Peggy will generate her value b. Then she will place it into a “magic box” as in the normal protocol (as in the instantiation above.) Finally, she will feed her boxed value(s) for both m and b as well as an optional “message” M into the hash function as follows:
An evasive puzzle.
Finally, she’ll compute the rest of the protocol as expected, and hand Victor the transcript which he can check by re-computing the hash function on the inputs to obtain x and verifying that y is correct (as in the original protocol.)
(A variant of this approach has Peggy give Victor a slightly different transcript: here she sends to Victor, who now computes and tests whether . I will leave the logic of this equation for the reader to work out. Commenter Imuli below points to a great StackExchange post that shows all the different variants of Schnorr people have built by using tricks like this.)
For this entire idea to work properly, it must be hard for Peggy to identify a useful input to the hash function that provides an output that she can use to fake the transcript. In practice, this requires a hash function where the “relation” between input and output is what we call evasive: namely, that it is hard to find two points that have a useful relationship for simulating the protocol.
In practice we often model these hash functions in security proofs as though they’re random functions, which means the output is verifiably unrelated to the input. For long and boring reasons, this model is a bit contrived. We still use it anyway.
What other magic boxes might there be?
As noted above, a critical requirement of the “magic box Schnorr” style of scheme is that the boxes themselves must be instantiated by some kind of one-way function: that is, there must be no efficient algorithm that can recover Peggy’s random secret key from within the box she produces, at least without exhaustively testing, or using some similarly expensive (super-polynomial time) attack.
The cyclic group instantiation given above satisfies this requirement provided that the discrete logarithm problem (DLP) is hard in the specific group used to compute it. Assuming your attacker only has a classical computer, this assumption is conjectured to hold for sufficiently-large groups constructed using finite-field based cryptography and in certain elliptic curves.
But nothing says your adversary has to be a classical computer. And this should worry us, since we happen to know that the discrete logarithm problem is not particularly hard to solve given an appropriate quantum computer. This is due to the existence of efficient quantum algorithms for solving the DLP (and ECDLP) based on Shor’s algorithm. To deal with this, cryptographers have come up with a variety of new signature schemes that use different assumptions.
In my next post I’m going to talk about one of those schemes, namely the Dilithium signature scheme, and show exactly how it relates to Schnorr signatures.
“Folklore” in cryptography means that nobody knows who came up with the idea. In this case these ideas were proposed in a slightly different context (one-time signatures) by folks like Ralph Merkle.
Since there are distinct subsets to pick from, the probability that Veronica will select exactly the same subset as Victor did — allowing him to answer her challenge properly — can be made quite small, provided N and k are chosen carefully. (For example, N=128 and k=30 gives about and so Evil Victor will almost never succeed.)
Some of these ideas date back to the Elgamal signature scheme, although that scheme does not have a nice security reduction.
In the real proof, we actually rely on a property called “rewinding.” Here we can make the statement that if there exists some algorithm (more specifically, an efficient probabilistic Turing Machine) that, given only Peggy’s public key, can impersonate Peggy with high probability: then it must be possible to “extract” Peggy’s secret value m from this algorithm. Here we rely on the fact that if we are handed such a Turing machine, we can run it (at least) twice while feeding in the same random tape, but specifying two different x challenges. If such an algorithm succeeds with reasonable probability in the general case, then we should be able to obtain two distinct points (x, y), (x’, y’) and then we can just solve for (m, b).
I’m specifying a prime-order subgroup here not because it’s strictly necessary, but because it’s very convenient to have our “exponent” values in the finite field defined by {0, …, q-1} for some prime q. To construct such groups, you must select the primes q, p such that p = 2q + 1. This ensures that there will exist a subgroup of order q within the larger group defined by the field Fp.
Recently a reader wrote in and asked if I would look at Sam Altman’s Worldcoin, presumably to give thoughts on it from a privacy perspective. This was honestly the last thing I wanted to do, since life is short and this seemed like an obvious waste of it. Of course a project devoted to literally scanning your eyeballs was up to some bad things, duh.
However: the request got me curious. Against my better judgement, I decided to spend a few hours poking around Worldcoin’s documentation and code — in the hope of rooting out the obvious technical red flags that would lead to the true Bond-villain explanation of the whole thing. Because surely there had to be one. I mean: eyeball scanners. Right?
More seriously, this post is my attempt to look at Worldcoin’s system from a privacy-skeptical point of view in order to understand how risky this project actually is. The risks I’m concerned about are twofold: (1) unintentional risks to users that could arise due to carelessness on Worldcoin’s part, and (2) “intentional” risks that could result from future business decisions (whether they are currently planned or not.)
For those who don’t love long blog posts, let me save you a bunch of time: I did not find as many red flags as I expected to. Indeed, while I’m still (slightly) leaning towards the idea that Worldcoin is the public face of some kind of moon-laser-esque evil plan, my confidence in that conclusion is lower than it was going in. Read on for the rest.
What is Worldcoin and why should I care?
Worldcoin is a new cryptocurrency funded by Sam Altman and run by Alex Blania. According to the project’s marketing material, the goal of the project is to service the “global unbanked“, which it will do by somehow turning itself into a form of universal basic income. While this doesn’t seem like much of a business plan, it’s pretty standard fare for a cryptocurrency project. Relatively few of these projects have what sound like “real use cases,” and it’s pretty common for projects to engage in behavior that amounts to “giving things away for free in the hope that somehow this will make everyone use the thing.”
What sets Worldcoin apart from other projects is that the free money comes with a surprising condition: in order to join the Worldcoin system and collect free tokens, users must hand over their eyeballs.
Ok, that’s obviously a bit dramatic. More seriously: the novel technical contribution of Worldcoin is a proprietary biometric sensor called “the orb”, which allows the system to uniquely identify users by scanning their iris, which not-coincidentally is one of the most entropy-rich biometric features that humans possess. Worldcoin uses these scans to produce a record that they refer to as a “proof of personhood”, a credential that will, according to the project, have many unspecified applications in the future.
Whatever the long term applications for this technology may be, the project’s immediate goal is to enroll hundreds of millions of eyeballs into their system, using the iris scan to make sure that no user can sign up twice. A numberof people have expressed concern about the potential security and privacy risks of this plan. Even more critically, people are skeptical that Worldcoin might eventually misuse or exploit this vast biometric database it’s building.
Worldcoin has arguably made themselves more vulnerable to criticism by failing to articulate a realistic-sounding business case for its technology (as I said above, something that is common to many cryptocurrency projects.) The project has instead argued that their biometric database either won’t or can’t be abused — due to various privacy-preserving features they’ve embedded into it.
Worldcoin’s claims
Worldcoin makes a few important claims about their system. First, they insist that the iris scan has exactly one purpose: to identify duplicate users at signup. In other words, they only use it to keep the same user from enrolling multiple times (and thus collecting duplicate rewards.) They have claimed — though not particularly consistently, see further below! — that your iris itself will not serve as any kind of backup “secret key” for accessing wallet funds or financial services.
This is a pretty important claim! A system that uses iris codes only to recognize duplicate users will expose its users to relatively few direct threats. That is, the worst an attacker can do is find ways to defraud Worldcoin directly. By contrast, a system that uses biometrics to authorize financial transactions is potentially much more dangerous for users. TL;DR if iris scans can be used to steal money, the whole system is quite risky.
Second, Worldcoin claims that it will not store raw images of your actual iris — unless you ask them to. They will only store a derived value called an “iris code”:
The final claim that Worldcoin makes is that they will not tie your biometric to a substantial amount of personal or financial data, which could make their database useful for tracking. They do this by making the provision of personally identifiable information (PII) “optional” rather than mandatory. And further, they use technology to make it impossible for the company to tie blockchain transactions back to your iris record:
There are obviously still some concerns in here: notably the claim that you “do not need” any personal information does leave room for people to ‘voluntarily’ provide it. This could be a problem in settings where unsupervised Worldcoin contractors are collecting data in relatively poor communities. And frankly it’s a little weird that Worldcoin allows users to submit this data in the first place, if they don’t have plans to do things with it.
Worldcoin in a technical nutshell
NB: Much of the following is based on Worldcoin’s own documentation, as well as a review of some of their contract code. I have not verified all of this, and portions may be incorrect.
Worldcoin operates two different technologies. The first is a standard EVM-based cryptocurrency token (ERC20), which operates on the “Layer 2” Optimism blockchain. The company can create tokens according to a limited “inflation supply” model and then give them away to people. Mostly this part of the project is pretty boring, although there are some novel aspects to Worldcoin’s on-chain protocol that impact privacy. (I’ll discuss those further below.)
The novel element of Worldcoin is its biometric-based “proof of personhood” identity verification tech. Worldcoin’s project website handwaves a lot about future applications of the technology, many of them involving “AI.” For the moment this technology is used for one purpose: to ensure that each Worldcoin user has registered only once for its public currency airdrop. This assurance allows Worldcoin to provide free tokens to registered users, without worrying that the same person will receive multiple rewards.
To be registered into the system, users visit a Worldcoin orb scanning location, where they must verify their humanity to a real-life human operator. The orb purports to contain tamper-resistant hardware that can scan one or both of the user’s eyes, while also performing various tests to ensure that the eyeballs belong to a living, breathing human. This sensor takes high-resolution iris images, which are then then processed internally within the the orb using an algorithm selected by Worldcoin. The output of this process is a sort of “digest value” called an iris code.
Iris codes operate like a fuzzy “hash” of an iris: critically, one iris code can be compared to another code, such that if the “distance” between the pair is small enough, the two codes can be considered to derive from the same iris. That means the coding must be robust to small errors caused by the scanning process, and even to small age-related changes within the users’ eyes. (The exact algorithm Worldcoin uses for this today is not clear to me, since their documentation mentions two different approaches: one based on machine learning, and one using more standard image processing techniques.) In theory the use of iris code algorithms computed within tamper-resistant hardware should mean that your raw iris scans are safe — the orb never needs to output them, it can simply output this (hopefully) much less valuable iris code.
(In practice, however, this is not quite true: Worldcoin allows users to opt in to “data custody“, which means that their raw iris scans will also be stored by the project. Worldcoin claims that these images will be encrypted, though presumably using a key that the project itself holds. Custody is promoted as a way to enable updates to the iris coding algorithm without forcing users to re-scan their eyes at an orb. It is not clear how many users have opted in to this custody procedure, and it isn’t great.)
Once the orb has scanned a user, the iris code is uploaded to a server operated by the Altman/Blania company Tools for Humanity. The code may or may not be attached to other personal user information that Worldcoin collects, such as phone numbers and email addresses (Worldcoin’s documents are slightly vague on this point, except for noting that this data is “optional.”) The server now compares the new code against its library of previously-registered iris codes. If the new code is sufficiently “distant” from all previous codes, the system will consider this user to be a unique first-time registered user. (The documents are also slightly vague about what happens if they’re already registered, see much further below.)
To complete the enrollment process, users download Worldcoin’s wallet software to generate two different forms of credential:
A standard Ethereum wallet public and secret key, which is used to actually control funds in Worldcoin’s ERC20 contract.
A specialized digital credential called an “identity commitment”, which comes with its own matching secret key material.
Critically, none of this key material is derived from the user’s biometric scan. The (public) “identity commitment”, is uploaded to Tools for Humanity, where it is stored in the database along with the user’s iris code, while all of the secret key material is stored locally on the user’s phone (with a possibility for cloud backup*). As a final step, Tools for Humanity exports the user’s identity commitment (but not the iris code data!) into a smart-contract-managed data structure that resides on Worldcoin’s blockchain.
Not shown: a user can choose to upload their iris scans and keep them in escrow. (source)
Phew. Ok. Only one more thing.
As mentioned previously, the entire purpose of this iris scanning business is to allow users to perform assertions on their blockchain that “prove” they are unique human beings: the most obvious one being a request for airdropped tokens. (It is important to note that these assertions happen after the signup process, and only use the key material in your wallet: this means it’s possible to sell your identity data once you’ve been scanned into the system.)
From a privacy perspective, a very real concern with these assertions is that Worldcoin (aka Tools for Humanity) could monitor these on-chain transactions, and thus link the user’s wallet back to the unique biometric record it is associated with. This would instantly create a valuable source of linked biometric and financial data, which is one of the most obvious concerns about this type of system.
To their credit: Worldcoin seems to recognize that this is a problem. And their protocols address those concerns in two ways. First: they do not upload the user’s Ethereum wallet address to Tools for Humanity’s servers. This means that any financial transactions a user makes should not be trivially linkable to the user’s biometric credentials. (This obviously doesn’t make linkage impossible: transactions could be linked back to a user via public blockchain analysis at some later point.) But Worldcoin does try to avoid the obvious pitfall here.
This solves half the problem. However, to enable airdrops to a user’s wallet, Worldcoin must at some point link the user’s identity commitment to their wallet address. Implemented naively, this would seem to require a public blockchain transaction that would mention both a destination wallet address and an identity commitment — which would implicitly link these (via the binding known to the Tools for Humanity server) to the user’s biometric iris code. This would be quite bad!
Worldcoin avoids this issue in a clever way: their blockchain uses zero knowledge proofs to authorize the airdrop. Concretely, once an identity commitment has been placed on chain, the user can use their wallet to produce a privacy-preserving transaction that “proves” the following statement: “I know the secret key corresponding to a valid identity commitment on the chain, and I have not previously made a proof based on this commitment.” Most critically, this proof does not reveal which commitment the user is referencing. These protections make it relatively more difficult for any outside party (including Tools for Humanity) to link this transaction back to a user’s identity and iris code.
Worldcoin conducts these transactions using a zero-knowledge credential system called Semaphore (developed by the Ethereum project, using an architecture quite similar to Zcash.) Although there are a fabulous number of different ways this could all go wrong in practice (more on this below), from an architecturalperspective Worldcoin’s approach seems well thought-out. Critically, it should serve to prevent on-chain airdrop transactions from being directly linked to the biometric identifiers that Tools for Humanity records.
To summarize all of the above… if Worldcoin works as advertised, the following should be true after you’ve registered and used the system:
Tools for Humanity will have a copy of your iris code stored in its database.
Tools for Humanity may also have stored a copy of your raw iris scans, assuming you “opted in” to data custody. (This data will be encrypted under a key TfH knows.)
Tools for Humanity will store the mapping between each iris code and the corresponding “identity commitment”, which is essentially the public component of your ID credential.
Tools for Humanity may have bound the iris code to other PII they optionally collected, such as phone numbers and email addresses.
Tools for Humanity should not know your wallet address.
All of your secret keys will be stored in your phone, and will not be backed up anywhere else unless you enable backups. (Worldcoin may also allow you to “recover” using your phone number, but this feature doesn’t work for me and so I’m not sure what it does.)
If you conduct any transactions on the blockchain that reference the identity commitment, neither Worldcoin or TfH should be able to link these to your identity.
Finally (and critically): no biometric information (or biometric-derived information) will be sent to the blockchain or stored on your phone.
Tom Cruise changing his eyeball passwords in Minority Report.
As you can see, this system appears to avoid some of the more obvious pitfalls of a biometric-based blockchain system: crucially, it does not upload raw biometric information to a volunteer-run blockchain. Moreover, iris scans are not used to derive key material or to enable spending of cryptocurrency (though more on this below.) The amount of data linked to your biometric credential is relatively minimal (except for those phone numbers!), and transactions on chain are not easily linked back to the credential.
This architecture rules out many threats that might lead to your eyeballs being stolen or otherwise needing to be replaced.
What about future uses of iris data?
As I mentioned earlier, a system that only uses iris codesto recognize duplicate users poses relatively few threats to users themselves. By contrast, a system that uses biometrics to authorize financial transactions could potentially be much more risky. To abuse a cliché: if iris scans can be used to steal money, then users might need to sleep with their eyes open closed.
While it seems that Worldcoin’s current architecture does not authorize transactions using biometric data, this does not mean the platform will behave this way forever. The existence of a biometric database could potentially create incentives that force the company to put this data to more dangerous use.
Let me be more specific.
The most famous UX problem in cryptocurrency is that cryptocurrency’s “defining” feature — self-custody of funds — is incredibly difficult to use. Users constantly lose their wallet secret keys, and with them access to all of their funds. This problem is endemic even to sophisticated first-world cryptocurrency adopters who have access to bank safety-deposit boxes and dedicated hardware wallets. This is going to be an even more serious problem for a cryptocurrency that purports to be the global “universal basic income” for billions of people who lack those resources.
If Worldcoin is successful by its own standards — i.e., it becomes a billion-user global cryptocurrency — it’s going to have to deal with the fact that many users are going to lose their wallet secrets. Those folks will want to re-authorize themselves to get those funds back. Unlike most cryptocurrencies, Worldcoin’s biometric database provide the ultimate resource to make that possible.
The Worldcoin white paper describes how biometrics can be used as a last-ditch account recovery mechanism. This is not currently mentioned on the Worldcoin website.
At present the company cannot use biometrics to regain access to lose wallets, but they have many of the tools they need to get there. In the current system, the situation is as follows:
In principle, Tools for Humanity’s servers can re-bind an existing iris code to a new identity commitment. They can then send that new commitment to the chain using a special call in the smart contract.
While this could allow users to obtain a second airdrop (if Worldcoin/TfH choose to allow it), it would not (at present) allow a user to take control of an existing wallet.
To enable wallet recovery, therefore, Worldcoin would need to change its on-chain contracts This would involve either replacing the ERC20 contract with one that admits ID-authorized recovery, or — more practically — deploying a new form of smart contract wallet that allows users to “reset” ownership via an identity assertion. Worldcoin hasn’t done either of these things yet, and I’m curious to see how they will withstand the pressure in the long term.
What other privacy concerns are there?
Another obvious concern is that Tools for Humanity could use its biometric database as a kind of “stone soup” to build a future (and more privacy-invasive) biometric database, which could then be deployed for applications that have nothing to do with cryptocurrency. For example, an obvious application would be to record and authorize credit for customers who lack government-issued ID. This is the kind of thing I can see Silicon Valley VC investors getting very excited over.
There is nothing, in principle, stopping the project from pivoting in this direction in the future. On the other hand, a reasonable counterpoint is that if Worldcoin really wanted to do this, they could just have done it from the get-go: enrolling lots of people into some weird privacy-friendly cryptocurrency seems like a bit of a distraction. But perhaps I am not being imaginative enough.
A related concern is that Worldcoin might somehow layer further PII onto their existing database, or find other ways to make this data more valuable — even if the on-chain data is unlinkable. Some reports indicate that Worldcoin employees do collect phone numbers and other personally-identifying information as part of the enrollment process. It’s really not clear why Worldcoin would collect this data if it doesn’t plan to use it somehow in the future.
As a final matter, there is a very real possibility that Worldcoin somehow has the best intentions — and yet will just screw everythingup. Databases can be stolen. Zero-knowledge proofs are famously difficult to get right, and even small timing-based vulnerabilities can create a huge privacy leak: for example it should not be very hard to guess at the linkage between keys and identity commitments based solely on when the two are posted on chain.
Worldcoin’s system almost certainly deploys various back-end servers to assist with proof generation (e.g., to obtain Merkle paths) and the logs of these servers could further undermine privacy. This will only get worse as Worldcoin proceeds to “decentralize” the World ID database, whatever that entails.
Conclusion
I came into this post with a great deal of skepticism about Worldcoin: I was 100% convinced that the project was an excuse to bootstrap a valuable biometric database that would be used e-commerce applications, and that Worldcoin would have built their system to maximize the opportunities for data collection.
After poking around the project a bit, I’m honestly still a little bit skeptical. I think Worldcoin is — at some level — an excuse to bootstrap a valuable biometric database for e-commerce applications. But I would say my confidence level is down to about 40%. Mostly this is because I’m not able to come up with a compelling story for what an evil-future-Worldcoin will do with a big database that consists of iris codes plus a few phone numbers. And more critically, I’m pleasantly surprised by the amount of thought that Worldcoin has put into keep transaction data unlinked from its ID database.
No doubt there are still things that I’ve missed here, and perhaps others will chime in with some details and corrections. In the meantime, I still would not personally stick my eyeballs into the orb, but I can’t quite tell you how it would hurt.
Notes:
* When you sign up for WorldApp it gives you the option to back up your keys to your own provider, like iCloud. This is bad but not really Worldcoin’s fault. You can also provide your phone number for some sort of recovery purpose. What’s happening here is very interesting and I’d like to understand it better, but the feature simply did not work for me.





















































![R_q = {\mathbb Z}_q[X]/(X^n+1)](https://s0.wp.com/latex.php?latex=R_q+%3D+%7B%5Cmathbb+Z%7D_q%5BX%5D%2F%28X%5En%2B1%29&bg=ffffff&fg=000000&s=0&c=20201002) . Each “element” is actually a vector of coefficients
. Each “element” is actually a vector of coefficients 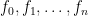 representing a polynomial of the form
representing a polynomial of the form 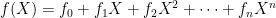 , where every coefficient is a integer modulo q. These polynomials can be added and multiplied using standard operations built from modular arithmetic. For Dilithium, we “conveniently” fix q = 223 − 213 + 1 and n = 256.
, where every coefficient is a integer modulo q. These polynomials can be added and multiplied using standard operations built from modular arithmetic. For Dilithium, we “conveniently” fix q = 223 − 213 + 1 and n = 256. 



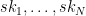 to be her “secret key.”
to be her “secret key.”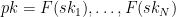 .
.


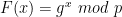
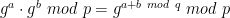
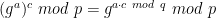


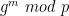 . Recall that in the discussion above, the approach we used was to pick a random point (x, y) first, and then “manufacture” a box as follows:
. Recall that in the discussion above, the approach we used was to pick a random point (x, y) first, and then “manufacture” a box as follows: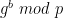 directly from
directly from 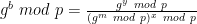
 in the instantiation above.) Finally, she will feed her boxed value(s) for both m and b as well as an optional “message” M into the hash function as follows:
in the instantiation above.) Finally, she will feed her boxed value(s) for both m and b as well as an optional “message” M into the hash function as follows: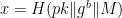

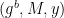 which he can check by re-computing the hash function on the inputs to obtain x and verifying that y is correct (as in the original protocol.)
which he can check by re-computing the hash function on the inputs to obtain x and verifying that y is correct (as in the original protocol.)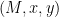 to Victor, who now computes
to Victor, who now computes 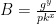 and tests whether
and tests whether 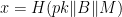 . I will leave the logic of this equation for the reader to work out. Commenter Imuli below points to a
. I will leave the logic of this equation for the reader to work out. Commenter Imuli below points to a 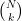 distinct subsets to pick from, the probability that Veronica will select exactly the same subset as Victor did — allowing him to answer her challenge properly — can be made quite small, provided N and k are chosen carefully. (For example, N=128 and k=30 gives about
distinct subsets to pick from, the probability that Veronica will select exactly the same subset as Victor did — allowing him to answer her challenge properly — can be made quite small, provided N and k are chosen carefully. (For example, N=128 and k=30 gives about  and so Evil Victor will almost never succeed.)
and so Evil Victor will almost never succeed.) 








