Back in March I was fortunate to spend several days visiting Brussels, where I had a chance to attend a panel on “chat control“: the new content scanning regime being considered by the EU Commission. Among various requirements, this proposed legislation would mandate that client-side scanning technology be incorporated into encrypted text messaging applications like Signal, WhatsApp and Apple’s iMessage. The scanning tech would examine private messages for certain types of illicit content, including child sexual abuse media (known as CSAM), along with a broad category of textual conversations that constitute “grooming behavior.”
I have many thoughts about the safety of the EU proposal, and you can read some of them here. (Or you’re interested in the policy itself, you can read this recent opinion by the EU’s Council’s Legal Service.) But although the EU proposal is the inspiration for today’s post, it’s not precisely what I want to talk about. Instead, I’d like to clear up some confusion I’ve noticed around the specific technologies that many have proposed to use for building these systems.
Also: I want to talk about Ashton Kutcher.

It turns out there were a few people visiting Brussels to talk about encryption this March. Only a few days before my own visit, Ashton Kutcher gave a major speech to EU Parliament members in support of the Commission’s content scanning proposal. (And yes, I’m talking about that Ashton Kutcher, the guy who played Steve Jobs and is married to Mila Kunis.)
Kutcher has been very active in the technical debate around client-side scanning. He’s the co-founder of an organization called Thorn, which aims to develop cryptographic technology to enable content scanning. In March he gave an impassioned speech to the EU Parliament urging the deployment of these technologies, and remarkably he didn’t just talk about the policy side of things. When asked how to balance user privacy against the needs of scanning, he even made a concrete technical proposal: to use fully-homomorphic encryption (FHE) as a means to evaluate encrypted messages.
Now let me take a breath here before my head explodes.
I promise I am not one of those researchers who believes only subject-matter experts should talk about cryptography. Really I’m not! I write this blog because I think cryptography is amazing and I want everyone talking about it all the time. Seeing mainstream celebrities toss around phrases like “homomorphic encryption” is literally a dream come true and I wish it happened every single day.
And yet, there are downsides to this much winning.
I ran face-first into some of those downsides when I spoke to policy experts about Kutcher’s proposal. Terms like fully homomorphic encryption can be confusing and off-putting to non-cryptographers. When filtered through people who are not themselves experts in the technology, these ideas can produce the impression that cryptography is magical pixie dust we can sprinkle on all the hard problems in the world. And oh how I wish that were true. But in the real world, cryptography is full of tradeoffs. Solving one problem often just makes new problems, or creates major new costs, or else shifts the risks and costs to other parts of the system.
So when people on various sides of the debate asked me whether “fully-homomorphic encryption” could really do what Kutcher said it would, I couldn’t give an easy five-word answer. The real answer is something like: (scream emoji) it’s very complicated. That’s a very unsatisfying thing to have to tell people. Out here in the real world the technical reality is eye-glazing and full of dragons.
Which brings me to this post.
What Kutcher is really proposing is that we to develop systems that perform privacy-preserving computation on encrypted data. He wants to use these systems to enable “private” scanning of your text messages and media attachments, with the promise that these systems will only detect the “bad” content while keeping your legitimate private data safe. This is a complicated and fraught area of computer science. In what goes below, I am going to discuss at a high and relatively non-technical level the concepts behind it: what we can do, what we can’t do, and how practical it all is.
In the process I’ll discuss the two most powerful techniques that we have developed to accomplish this task: namely, multi-party computation (MPC) and, as an ingredient towards achieving the former, fully-homomorphic encryption (FHE). Then I’ll try to clear up the relationship between these two things, and explain the various tradeoffs that can make one better than the other for specific applications. Although these techniques can be used for so many things, throughout this post I’m going to focus on the specific application being considered in the EU: the use of privacy-preserving computation to conduct content scanning.
This post will not require any mathematics or much computer science, but it will require some patience. So find a comfortable chair and buckle in.
Computing on private data
Encryption is an ancient technology. Roughly speaking, it provides the ability to convert meaningful messages (and data) into a form that only you, and your intended recipient(s) can read. In the modern world this is done using public algorithms that everyone can look at, combined with secret keys that are held only by the intended recipients.
Modern encryption is really quite excellent. So as long as keys are kept safe, encrypted data can be sent over insecure networks or stored in risky locations like your phone. And while occasionally people find a flaw in an implementation of encryption, the underlying technology works very well.
But sometimes encryption can get in the way. The problem with encrypted data is that it’s, well, encrypted. When stored in this form, such data is virtually useless for practical purposes like performing calculations. Before you can compute on that data, you often need to first decrypt it and thus remove all the beautiful protections we get from encryption.
If your goal is to compute on multiple pieces of data that originate from different parties, the problem can become even more challenging. Who can we trust to do the computing? An obvious solution is to decrypt all that data and hand it to one very trustworthy person, who will presumably swear not to steal it or get hacked. Finding those parties can be quite challenging.
Fortunately for us all, the first academic cryptographers also happened to be computer scientists, and so this was exactly the sort of problem that excited them. Those researchers quickly devised a set of specific and general techniques designed to solve these problems, and also came up with a cool name for them: secure multi-party computation, or MPC for short.
MPC: secure private computation (in six eight ten paragraphs)
The setting of MPC is fairly simple: imagine that we have two (or more!) parties that each have some private data they don’t want to give to anyone else. Yet each of the parties is willing to provide their data as input to some specific computation, and are all willing to reveal the output of that computation — either to everyone involved, or perhaps just to some agreed subset of the parties. Can these parties now perform the computation jointly, without appointing a trusted party?
Let’s make this easier by using a concrete example.
Imagine a group of workers all know their own salaries, but don’t know anything about anyone else’s salary. Yet they wish to compute some statistics over their salary data: for example, the average of their salaries. These workers aren’t willing to share their own salary data with anyone else, but they are willing to submit it as one input in a large calculation under the strict condition that only the final result is ever revealed.
This might seem contrived to you, but it is in fact a real problem that some people have used MPC to solve.
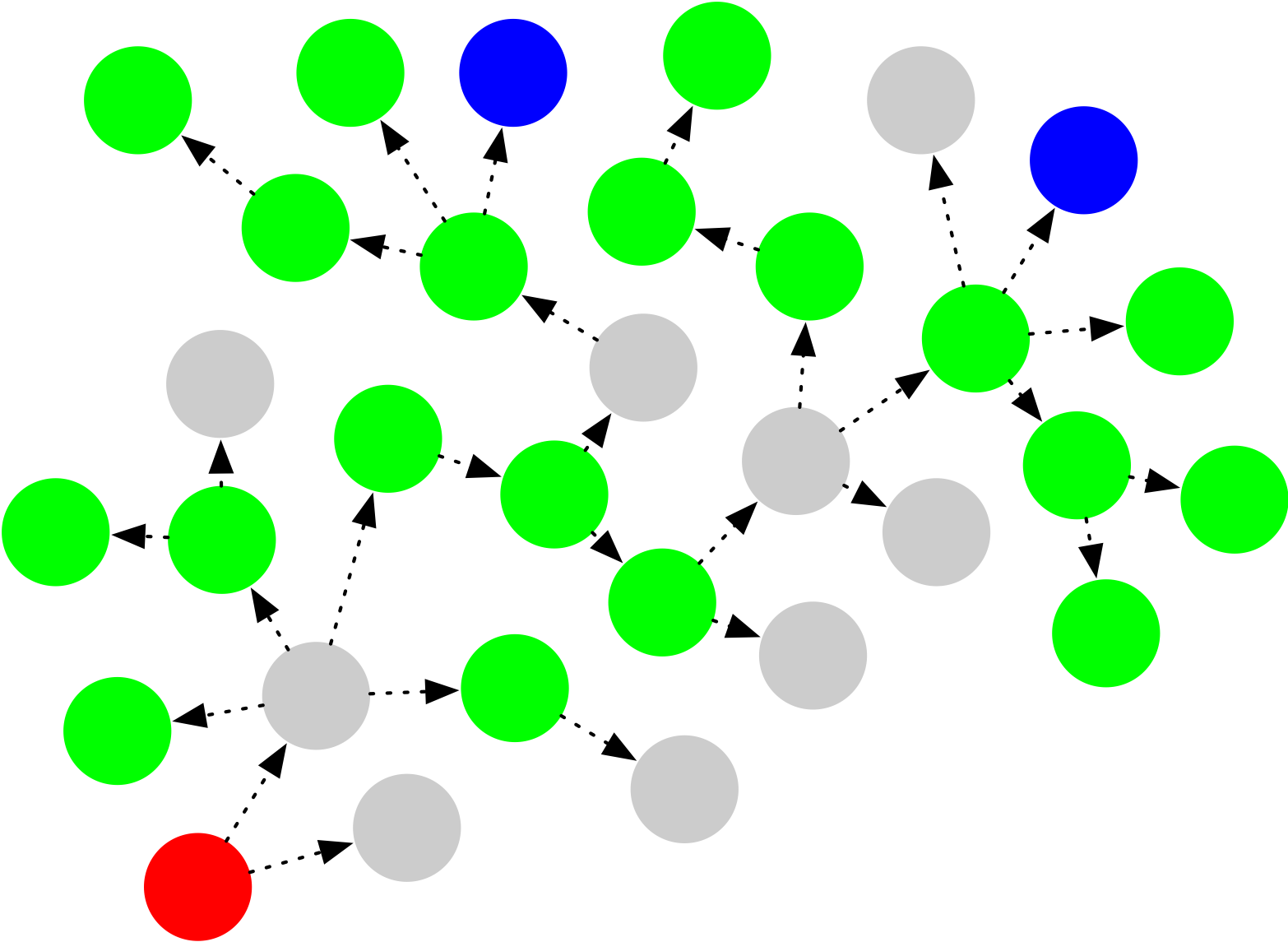
An MPC protocol allows the workers to do this, without appointing a trusted central party or revealing their inputs (and intermediate calculations) to anyone else. At the conclusion of the protocol each party will learn only the result of the calculation:

MPC protocols typically provide strong provable guarantees about their properties. The details vary, but typically speaking: no party will learn anything about the other parties’ inputs. Indeed they won’t even learn any partial information that might be produced during the calculation. Even better, all parties can be assured that the result will be correct: as long as all parties submit valid inputs to the computation, none of them should be able to force the calculation to go awry.
Now obviously there are caveats.
In practice, using MPC is a bit like making a deal with a genie: you need to pay very careful attention to the fine print. Even when the cryptography works perfectly, this does not mean that computing your function is actually “safe.” In fact, it’s entirely possible to choose functions that when computed securely are still devastating to your privacy.
For example: imagine that I use an MPC protocol to compute an average salary between myself and exactly one other worker. This could be a very bad idea! Note that if the other worker is curious, then she can figure out how much I make. That is: the average of our two wages reveals enough information that she find my wage given knowledge of her own input. This (obvious) caveat applies to many other uses of MPC, even when the technology works perfectly.
This is not a criticism of MPC, just the observation that it’s a tool. In practice, MPC (or any other cryptographic technology) is not a privacy solution by itself, at least not in the sense of privacy that real-world human beings like to think about. It provides certain guarantees that may or may not be useful for providing privacy in the real world.
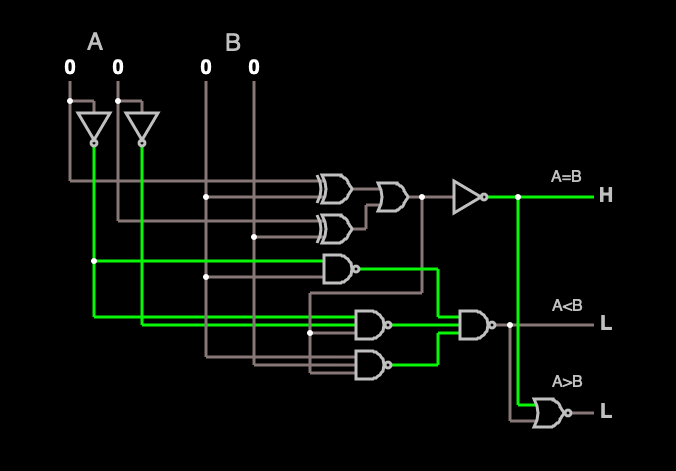
What does MPC have to do with client-side scanning?
We began this post by discussing client-side scanning for encrypted messaging apps. This is a perfect example of an application that fits the MPC (or two-party computation) use-case perfectly. That’s because in this setting we generally have multiple parties with secret data who want to perform some joint calculation on their inputs.
In this setting, the first party is typically a client (usually a person using an encrypted messaging app like WhatsApp or Signal), who possesses some private text message or perhaps a media file they wish to send to another user. Under proposed law in the EU, their app could be legally mandated to “scan” that image to see if it contains illegal content.
According to the EU Commission, this scanning can be done in a variety of ways. For example, the device could compare an images against a secret database of known illicit content (typically using a specialized perceptual hash function.) However, while the EU plan starts there, their plans also get much more ambitious: they also intend to look for entirely new instances of illicit content as well as textual “grooming” conversations, possibly using machine learning (ML) models, that is, deep neural networks that will be trained to recognize data that fits these patterns. These various models must be sophisticated enough to understand entirely new images, as well as to derive meaning from complex interactive human conversation. None of this is likely to be very simple.
Now most of this could be done using standard techniques on the client device, except for one major limitation. The challenge in this setting is that the provider doing the scanning usually wants to keep these hashes and/or ML models secret.
There are several reasons for this. The first reason is that knowledge of the scanning model (or database of illicit content) makes it relatively easy for bad actors to evade the model. In other words, with only modest transformations it’s possible to modify “bad” images so that they become invisible to ML scanners.
Knowledge of the model can also allow for the creation of “poisoned” imagery: these include apparently-benign images (e.g., a picture of a cat) that trigger false positives in the scanner. (Indeed this such “colliding” images have been developed for some hash-based CSAM scanning proposals.) More worryingly, in some cases the hashes and neural network models can be “reversed” to extract the imagery and textual content they were trained on: this has all kinds of horrifying implications, and could expose abuse victims to even more trauma.
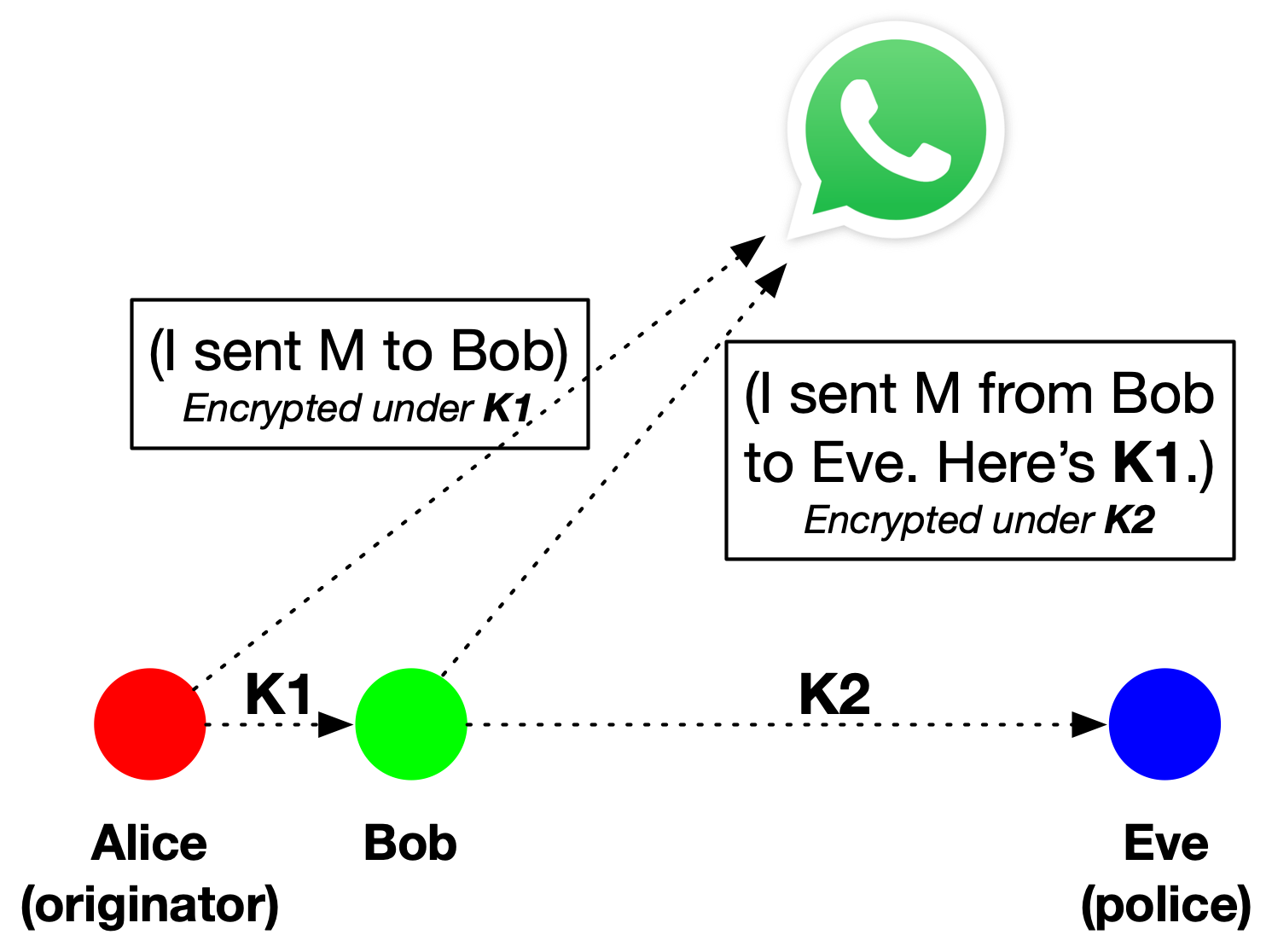
So here the user doesn’t want to send its confidential data to the provider for scanning, and the provider doesn’t want to hand its confidential model parameters to the user (or even to expose them inside the user’s phone, where they might be stolen by reverse-engineers.) This is exactly the situation that MPC was designed to handle:

This makes everything very complicated. In fact, there has only been one real-world proposal for client-side CSAM scanning that has ever come (somewhat) close to deployment: that system was designed by Apple for a (now abandoned) client-side photo scanning plan. The Apple approach is cryptographically very ambitious: it uses neural-network based perceptual hashing, and otherwise exactly follows the architecture described above. However, critically: it relied on a neural-network based hash function that was not kept secret. Disastrous results ensued (see further below.)
(If you’re interested in getting a sense of how complex this protocol is, here is a white paper describing how it works.)

Ok, so what kind of MPC protocols are available to us?
Multi-party computation is a broad category. It describes a class of protocols. In practice there are many different cryptographic techniques that allow us to realize it. Some of these (like the Apple protocol) were designed for specific applications, while others are capable of performing general-purpose computation.
I promised this post would not go into the weeds, but it’s worth pointing out that general MPC techniques typically make use of (some combination of) three different techniques: secret sharing, circuit garbling, and homomorphic encryption. Often, efficient modern systems will use a mixture of two or three of those techniques, just to make everything more confusing because they’re to maximize efficiency.
What is it that you need to know about these techniques? Here I’ll try, in a matter of a few sentences (that will draw me endless grief) to try to summarize the strengths and disadvantages of each technique.
Both secret sharing and garbling techniques share a common feature, which is that they require a great deal of data to be sent between the parties. In practice the amount of data sent between the parties will grow with (at least) the size of the inputs they’re computing on, but often will grow according to the complexity of the calculation they’re performing. For things like deep neural networks where both the data and calculation are huge, this generally results in fairly surprising amounts of data transfer.
This is not usually considered to be a problem on the general Internet or within EC2 datacenters, where data transfer is cheap. It can be quite a challenge when one of those parties is using a cellphone, however. That makes any scheme using these technologies subject to some very serious limitations.
Homomorphic encryption schemes take a different approach. These systems make use of specialized encryption schemes that are malleable. This means that encrypted data can be “modified” in useful ways without ever decrypting it.
In a bit more detail: in fully-homomorphic encryption MPC systems, a first party can encrypt its data under a public key that it generates. It can then send the encrypted data to a second party. This second party can then perform calculations on the ciphertext while it is still encrypted — adding and multiplying it together with other data (including data encrypted by the second party) to perform some calculation. Throughout this process all of the data remains encrypted. At the conclusion of this process, the second party will end up with a “modified” ciphertext that internally contains a final calculation result, but that it cannot read. To finish the protocol, the second party can send that ciphertext back to the first party, who can then decrypt it using its secret key and obtain the final output.
The major upshot of the pure-FHE technique is that it substantially reduces the amount of data that the two parties need to transmit between them, especially compared to the other MPC techniques. The downside of this approach is… well, there are several. One is that FHE calculations typically require vastly more computational effort (and hence time and carbon emissions) than the other techniques. Moreover, they may still require a good deal of data transfer — in part because the number of calculations that one can perform on a given ciphertext is usually limited by “noise” that turns up within the ciphertext. Hence, calculations must either be very simple or else broken up into “phases”, where the partial calculation result is decrypted and re-encrypted so that more computation can be done. This can be done interactively between the parties, or by the second party alone (using a technique called “bootstrapping”) but in both cases the cost is either much more bandwidth exchanged or a great deal of extra computation.
In practice, cryptographers rarely commit to a single approach. They instead combine all these techniques in order to achieve an appropriate balance of data-transfer and computational effort. These “mixed systems” tend to have merely large amounts of data transfer and large amounts of computation, but are still amazingly efficient compared to the alternatives.
For an example of this, consider this very optimized two-party MPC scheme aimed at performing neural network classification. This scheme takes (from the client) a 32×32 image, and evaluates a tiny 7-layer neural network held by a server in order to perform classification. As you can see, evaluating the model even on a single image requires about 8 seconds of computation and 200 megabytes of bandwidth exchange, for each image being evaluated:

These numbers may seem quite high, but in fact they’re actually really impressive as these things go. Previous systems used nearly an order of magnitude more time and bandwidth to do their work. Maybe there will be further improvements in the future! Even on a pure efficiency basis there is much work to be done.
What are the other risks of MPC in this setting?
The final point I would like to make is that secure MPC (or MPC built using FHE as a tool) is not itself enough to satisfy the requirements of a safe content scanning system. As I mentioned above, MPC systems merely evaluate some function on private data. The question of whether that function is safe is left largely to the system designer.
In the case of these content scanning systems, the safety of the resulting system really comes down to a question of whether the algorithms work well, particularly in settings where “bad guys” can find adversarial inputs that try to disrupt the system. It also requires new techniques to ensure that the system cannot be abused. That is: there must be guarantees within the computation to ensure that the provider (or a party who hacks the provider) cannot change the model parameters to allow them to access your private content.
This is a much longer conversation than I want to have in this post, because it fundamentally requires one to think about whether the entire system makes sense. For a much longer discussion of the risks, see this paper.
This was nice, but I would like to learn more about each of these technologies!
The purpose of this post was just to give the briefest explanation of the techniques that exist for performing all of these calculations. If you’re interested in knowing (a lot more!) about these technologies, take a look at this textbook by Evans, Kolesnikov and Rosulek. MPC is an exciting area, and one that is advancing every single (research) conference cycle.
And maybe that is the lesson of this post: these technologies are still research techniques. It’s probably not quite time to put them out in the world.


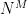 . This probably won’t scale very well for even modest values of M and N, but let’s put this aside for a moment. Given enough paper, we could imagine writing down each unique lookup table on a piece of paper: then we could stack those papers up and admire the minor ecological disaster we’d have just created.
. This probably won’t scale very well for even modest values of M and N, but let’s put this aside for a moment. Given enough paper, we could imagine writing down each unique lookup table on a piece of paper: then we could stack those papers up and admire the minor ecological disaster we’d have just created.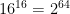 , or about 18 quintillion. It gets worse if you think about “useful” cryptographic functions, say those with the input/output profile of ChaCha20, which has 128-bit inputs and 512-bit outputs. There you’d need a whopping
, or about 18 quintillion. It gets worse if you think about “useful” cryptographic functions, say those with the input/output profile of ChaCha20, which has 128-bit inputs and 512-bit outputs. There you’d need a whopping  (giant) pieces of paper. Since there are only around
(giant) pieces of paper. Since there are only around 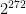 atoms in the observable universe (according to literally the first
atoms in the observable universe (according to literally the first 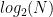 bits of data.
bits of data.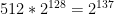 bits.
bits. 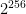 individual functions, where each key value selects exactly one function from the family.
individual functions, where each key value selects exactly one function from the family.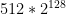 is not.
is not. work, and we assume that there exist reasonable values of n for which no computing device exists that can succeed at this.)
work, and we assume that there exist reasonable values of n for which no computing device exists that can succeed at this.)
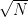 queries. For functions like AES, which has output size
queries. For functions like AES, which has output size 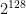 , this will occur around
, this will occur around  queries.
queries. 
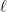 -bit strings, then any statistical “
-bit strings, then any statistical “