This is the third and penultimate post in a series about theoretical weaknesses in Fiat-Shamir as applied to proof systems. The first post is here, the second post is here, and you should probably read them.
Over the past two posts I’ve given a bit of background on four subjects: (1) interactive proof systems (for general programs/circuits), (2) the Fiat-Shamir heuristic, (3) random oracles. We’ve also talked about (4) recursive proofs, which will be important but are not immediately relevant.
With all that background we are finally almost ready to talk about the new result by Khovratovich, Rothblum and Soukhanov entitled “How to Prove False Statements: Practical Attacks on Fiat-Shamir” (which we will call KRS for short.)
Let’s get situated
The KRS result deals with a very common situation that we introduced in the previous post. Namely, that many new proving systems are first developed as interactive protocols (usually called public-coin protocols, or sometimes Sigma protocols.) These protocols fit into a template: first, a Prover first sends a commitment message, then interacts with some (honest) Verifier who “challenges” the Prover in various ways that are specific to the protocol; for each challenge, the Prover must respond correctly, either once or multiple times. The nature of the challenges can vary from scheme to scheme. For now we don’t care about the details: the commonality is that in the interactive setting the Verifier picks its challenges honestly, using real randomness.

In many cases, these protocols are then “flattened” down into a non-interactive proof using the Fiat-Shamir heuristic. The neat thing is that the Prover can run the interactive protocol all by itself, by running a deterministic “copy” of the Verifier. Specifically, the Prover will:
- Cryptographically hash its own Commitment message — along with some extra information, such as the input/output and “circuit” (or program, or statement.)1
- Use the resulting hash digest bits to sample a challenge.
- Compute the Prover’s response to the challenge (many times if the protocol calls for this.)
- Publish the whole transcript for anyone to verify.
Protocol designers focus on the interactive setting because it’s relatively easy to analyze the security of the protocol. They can make strong claims about the nature of the challenges that will be chosen, and can then reason about the probability that a cheating Prover can lie in response. The hope with Fiat-Shamir is that, if the hash function is “as good as” a random oracle, it should be nearly as secure as the interactive protocol.
Of course none of this applies to practice. When we deploy the protocol onto a blockchain, we don’t have interactive Verifiers and we certainly don’t have random oracles. Instead we replace the random oracle in Fiat-Shamir with a standard hash function like SHA-3. Whether or not any security guarantees still hold once we do this is an open question. And into the maw of that question is where we shall go.
The GKR15 succinct proof system (but not with details)
The new KRS paper starts by considering a specific interactive proof system designed back in 2015 by Goldwasser, Kalai and Rothblum, which we will refer to as GKR15 (note that the “R” is the not the same in both papers — thanks Aditya!) This is a relatively early result on interactive proving systems and has many interesting theoretical features that we will mostly ignore.
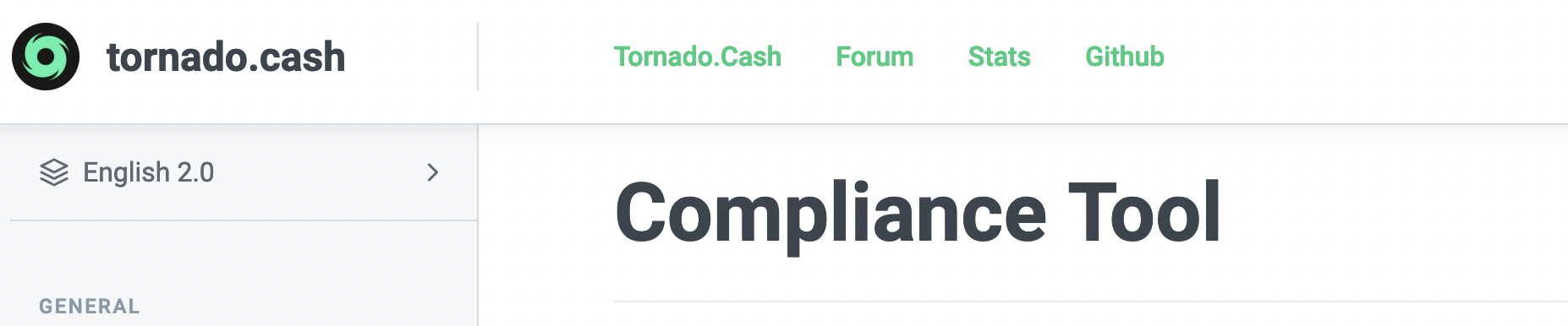
At the surface level, what you need to know about the GKR15 proof system is that it works over arithmetic circuits. The Prover and Verifier agree on a circuit C (which can be thought of as the “program”). The Prover also provides some input to the circuit x as well as a witness w, and a purported output y, which ought to satisfy y = C(w, x) if the Prover is honest.


There are some restrictions on the nature of the circuits that can be used in GKR15 — which we will ignore for the purposes of this high-level intuition. The important feature is that the circuits can be relatively deep. That is to say, they can implement reasonably complex programs, such as cryptographic hashing algorithms.
(The authors of the recent KRS paper also refer to GKR15 as a “popular” scheme. I don’t know how to evaluate that claim. But they cite some features in the protocol that are re-used in more recent proof systems that might be deployed in practice, so let’s go with this!)
The GKR15 scheme (like most proving schemes) is designed to be interactive. All you need to know for the moment is that:
- The Prover and Verifier agree on C.
- The Prover sends the input and output (x, y) to the Verifier.
- It also sends a (polynomial) commitment to the witness w in the first “Commitment” message.
- The Verifier picks a random challenge c and the Prover/Verifier interact (multiple times) to do stuff in response to this challenge.
Finally: GKR15 possesses a security analysis (“soundness proof”) that is quite powerful, provided we are discussing the interactive version of the protocol. This argument does not claim GKR15 is “perfect”! It leaves room for some tiny probability that a cheating Prover can get away with its crimes: however, it does bound the probability of successful cheating to something (asymptotically and, presumably, practically with the right parameters) negligible.
Since the GKR15 authors are careful theoretical cryptographers, they don’t suggest that their protocol would be a good fit for Fiat-Shamir. In fact, they hint that this is a problematic idea. But, in the 2015 paper anyway, the don’t actually show there’s a problem with the idea. This leaves open a question: what happens if we do flatten it using Fiat-Shamir? Could bad things happen?
A first thought experiment: “weak challenges”
I am making a deliberate decision to stay “high level” and not dive into the details of the GKR15 system quite yet, not because I think they’re boring and off-putting — ok, it’s partly because I think they’re boring and off-putting — but mostly because I think leading with those details will make understanding more difficult. I promise I’ll get to the details later.
Up here at the abstract level I want to remind us, one final time, what we know. We know that proving systems like GKR15 involve a Verifier making a “challenge” to the Prover, which the Prover must answer successfully. A good proving system should ensure that an honest Prover can answer those challenges successfully — but a cheating Prover (any algorithm that is trying to prove a false statement) will fail to respond correctly to these challenges, at least with overwhelming probability.
Now I want to add a new wrinkle.
Let’s first imagine that the set of all possible challenges a Verifier could issue to a Prover is quite large. For one example: the the challenge might be a random 256-bit string, i.e., there are 2256 to choose from. For fun, let’s further imagine that somewhere within this huge set of possible challenge values there exists a single “weak challenge.” This value c* — which I’ll exemplify by the number “53” for this discussion — is special. A cheating Prover who is fortunate enough to be challenged at this point will always be able to come up with a valid response, even if the statement they are “proving” is totally false (that is, if y is not equal to C(w, x).)
Now it goes without saying that having such a “weak challenge” in your scheme is not great! Clearly we don’t like to have weird vulnerabilities in our schemes. And yet, perhaps it’s not really a problem? To decide, we need to ask: how likely is it that a Verifier will select this weak challenge value?
If we are thinking about the interactive setting with an honest Verifier, the analysis is easy. There are 2256 possible challenge values, and just one “weak challenge” at c* = 53. If the honest Verifier picks challenges uniformly at random, this bad challenge will be chosen with probability 2-256 during one run of the protocol. This is so astronomically improbable that we can more or less pretend it will never happen.
How does Fiat-Shamir handle “bad challenges”?
We now need to think about what happens when we flatten this scheme using Fiat-Shamir.
To do that we need to be more specific about how the scheme will be Fiat-Shamir-ified. In our scheme, we assumed that the Prover will generate a Commitment message first. The deterministic Fiat-Shamir “Verifier” will hash this message using a hash function H, probably tossing in some other inputs just to be safe. For example, it might include the input/output values as well as a hash of the circuit h(C) — note that we’re using a separate hash function out of an abundance of caution. Our challenge will now be computed as follows:
c = H( h(C), x, y, Commitment )
Our strawman protocol has a weak challenge point at c* = 53. So now we should ask: can a cheating Prover somehow convince the Fiat-Shamir hash “Verifier” to challenge them at this weak point?
The good news for Fiat-Shamir is that this also seems pretty difficult. A cheating Prover might want to get itself challenged on c* = 53. But to do this, they’d need to find some input (pre-image) to the hash function H that produces the output “53”. For any hash function worth its salt (pun intended!) this should be pretty difficult!4
Of course, in Fiat-Shamir world, the cheating Prover has a slight advantage: if it doesn’t get the hash challenge it wants, it can always throw away the result and try again. To do this it could formulate a new Commitment message (or even pick a new input/output pair x, y) and then try hashing again. It can potentially repeat this process millions of times! This attack is sometimes called “grinding” and it’s a real attack that actual cheating Provers can run in the real world. Fortunately even grinding isn’t necessarily a disaster: if we assume that the Prover can only compute, say, 250 hashes, then (in the ROM) the probability of finding an input that produces c = 53 is still 250 * 2-256 = 2-206, yet another very unlikely outcome.
Another victory for Fiat-Shamir! Even if we have one or more fixed “weak challenge” points in our protocol, it seems like Fiat-Shamir protects us.
What if a cheating Prover can pick the “weak challenge”?
I realize I’m being exhaustive (or exhausting), but I now want to consider another weird possibility: what if the “bad challenge” value can change when we switch circuits (or even circuit inputs)?
For fun, let’s crank this concern into absolute overdrive. Imagine we’re using a proving system that’s as helpful as possible to the cheating Prover: in this system, the “weak challenge value” will be equal to whatever the real output of the circuit C is. Concretely, if the circuit outputs c* = C(w, x) and also c* happens to be challenge value selected by the Verifier, then the Prover can cheat.
(Notice that I’m specifying that this vulnerability depends on the “real” output of the circuit. The prover also sends over a value y, which is the purported output of the circuit that the Prover is claiming, but that might be different if the Prover is cheating.)
In the interactive world this really isn’t an issue. In that setting, the Verifier selects the challenge randomly after the Prover has committed to everything. In that setting, the Prover genuinely cannot “cook” the circuit to produce the challenge value as output (except with a tiny probability.) Our concern is that In Fiat-Shamir world we should be a bit more worried. The value c* is chosen by hashing. A cheating Prover could theoretically compute c* in advance. It now has several options:
- The cheater could alter the circuit C so that it hard-codes in c*.
- Alternatively, it could feed the value c* (or some function of it) into the circuit via the input x.
- It could sneak c* in within the witness w.
- Or any combination of the above.
The problem here is that even in Fiat-Shamir world, this attack doesn’t work. A cheating Prover might first pick a circuit C and some input/output x, witness w, and a (purported) output y. It could then compute a Commitment by using the proving scheme’s commitment protocol to commit to w. It will then compute the anticipated Fiat-Shamir challenge as:
c* = H( h(C), x, y, Commitment )
To exploit the vulnerability in our proving system, the cheating Prover must now somehow cause the circuit C to output C(w, x) = c*. However, once again we encounter a problem. The cheating Prover had to feed x, as well as a (commitment to) w and (a hash of) the circuit C into the Fiat-Shamir hash function in order to learn c*. (It should not have been able to predict c* before performing the hash computation above, so it’s extremely unlikely that C(w, x) would just happen to output c*.) However, in order to make C(w, x) output c*, the cheater must subsequently manipulate either (1) the design of C or (2) the circuit’s inputs w, x.
But if the cheating Prover does any of those things, they will be completely foiled. If the cheating Prover changes any of the inputs to the circuit or the Circuit itself after it hashes to learn c*, then the actual Fiat-Shamir challenge used in the protocol will change.3
What if the circuit can compute the “weak challenge” value?
Phew. So what have we learned?
Even if our proving system allows us to literally pick the “weak challenge” c* — have it be the output of the circuit C(w, x) — we cannot exploit this fact very easily. Changing the structure of C, x or w after we’ve learned c* will cause the actual Fiat-Shamir challenge used to simply hop to a different value, like the timeline of a traveler who goes back in time and kills their own grandfather.

Clearly we need a different strategy: one where none of the inputs to the circuit, or the “code” of the circuit itself, depend on the output of the Fiat-Shamir hash function.
An important observation, and one that is critical to the KRS result, is that the “circuit” we are proving is fundamentally a kind of program that computes things. What if, instead of computing c* and feeding it to the circuit, or hard-coding it within the circuit, we instead design a circuit that itself computes c*?
Let’s look one last time at the way that Fiat-Shamir challenges are computed:
c* = H( h(C), x, y, Commitment)
We are now going to build a circuit C* that is able to compute c* when given the right inputs.
To make this interesting, we are going to design a very silly circuit. It is silly in a specific way: it can never output one specific output, which in this case will be the binary string “BANANAS”. Looking forward, our cheating Prover is then going to try to falsely claim that for some x, w, the relation C*(w, x) = “BANANAS” actually does hold.
Critically, this circuit will contain a copy of the Fiat-Shamir hashing algorithm H() and it will — quite coincidentally — actually output a value that happens to be identical to the Fiat-Shamir challenge (most of the time.) Here’s how it works:
- The cheating Prover will pass w and x = ( h(C*), y* = “BANANAS” ) as input.
- It will then use the proving system’s commitment algorithm on w to compute Commitment.
- The circuit will parse x into its constituent values.
- The circuit will internally compute c* = H( h(C*), x, y*, Commitment ).
- In the (highly unlikely) case that c* = “BANANAS”, it will set c* = “APPLES”.
- Finally, the circuit will output c*.
Notice first that this circuit can never, ever output C*(w, x) = “BANANAS” for any inputs w, x. Indeed, it is incredibly likely that this output would happen to occur naturally after step (4) — how likely is it that a hash function outputs the name of a fruit? — but just to be certain, we have step (5) to reduce this occurrence from “incredibly unlikely” to “absolutely impossible.”
Second, we should observe that the “code” of the circuit above does not in any way depend on c*. We can write this circuit before we ever hash to learn c*! The same goes for the inputs w and x. None of the proposed inputs require the cheating Prover to know c* before it chooses them.
Now imagine that some Prover shows up and tells you that, in fact, they know some w, x such that C*(w, x) = “BANANAS”. By definition they must be lying! When they try to convince you of this using the proving system, a correctly-functioning system should (with overwhelming probability) catch them in their lie and inform you (the Verifier) that the proof is invalid.
However: we stipulated that this particular proving system becomes totally insecure in the special case where the real calculation C*(w, x) happens to equal the Fiat-Shamir challenge c* that will be chosen during the protocol execution. If and when this remarkable event ever happens, the cheating Prover will be able to successfully complete the protocol even if the statement they are proving is totally bogus. And finally it seems we have an exploitable vulnerability! A cheating Prover can show up with the ridiculous false statement that C*(w, x) = “BANANAS”, and then hand us a Fiat-Shamir proof that will verify just fine. They can do this because in real life, C*(w, x) = c* and, thanks to the “weak challenge” feature of the proving system, that Prover successfully answer all the challenges on that point.
And thus in Fiat-Shamir land we have finally proved a false statement! Note that in the interactive protocol none of this matters, since the Prover cannot predict the Verifier’s (honest) challenge, and so has no real leverage to cheat. In the Fiat-Shamir world — at least when considering this one weird circuit C* — a cheating Prover can get away with murder.
This is not terribly satisfying!
Well, not murder maybe.
I realize this may seem a bit contrived. First we had to introduce a made-up proving system with a “weird” vulnerability, then we exploited it in a very nutty way. And the way we exploited it is kind of silly. But there is a method to the madness. I hope I’ve loaded us up with the basic concepts that we will need to really understand the KRS result.
What remains is to show how the real GKR15 scheme actually maps to some of these ideas.
As a second matter: I started these posts out by proposing all kinds of flashy ideas: we could steal billions of dollars in Ethereum transactions by falsely “proving” that a set of invalid transactions is actually valid! Now having promised the moon, I’m delivering the incredibly lame false statement C*(w, x) = “BANANAS”, where C* is a silly circuit that mostly computes a hash function. This should disappoint you. It disappoints me.
But keep in mind that cryptographic protocols are very delicate. Sometimes an apparently useless vulnerability can be expanded into something that actually matters. It turns out that something similar will apply to this vulnerability, when we apply it to the GKR15 scheme. In the next post.
There will be only one last post, I promise.
Notes:
- There is a class of attacks on Fiat-Shamir-ified protocols that stems from putting too little information into the hash function. Usually the weakness here is that the hash does not get fed stuff like “the public key” (in signature schemes), which weakly corresponds to “the circuit” in a proving system. Sneaky attackers can switch these out and do bad thing.
- I’ve been extremely casual about the problem of converting hash function outputs into “challenges” for arbitrary protocols. Sometimes this is easy — for example, if the challenge space consists of fixed-length random bit-strings, then we can just pick a hash function with the appropriate output length. Sometimes it is moderately easy, for example if the challenges are sampled from some reasonably-sized field. A few protocols might pick the challenges from genuinely weird distibutions. If you’re annoyed with me on this technical detail, I might stipulate that we have (A) a Fiat-Shamir hash function that outputs (enough) random bits, and (B) a way to convert those bits into whatever form of challenge you need for the protocol.
- I said this is not scientific, but clearly we could make some kind of argument in the random oracle model. There we’d argue (something like): assume the scheme is secure using random challenges chosen by an honest (interactive) Verifier, now let’s consider whether it’s possible for the attacker to have pre-queried the oracle on the inputs that will produce the actual Fiat-Shamir. We could then analyze every possible case and hopefully determine that the answer is “no.” And that would be “science.”
- In the random oracle model we can convert this intuition into a stronger argument: each time the Prover hashes something for the first time, the oracle effectively samples a uniformly random string as its response. Since there are 2256 possible digests, the probability that it returns c = 53 after one hash attempt should still be 2-256, which again is very low.
























![R_q = {\mathbb Z}_q[X]/(X^n+1)](https://s0.wp.com/latex.php?latex=R_q+%3D+%7B%5Cmathbb+Z%7D_q%5BX%5D%2F%28X%5En%2B1%29&bg=ffffff&fg=000000&s=0&c=20201002) . Each “element” is actually a vector of coefficients
. Each “element” is actually a vector of coefficients 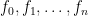 representing a polynomial of the form
representing a polynomial of the form 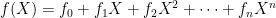 , where every coefficient is a integer modulo q. These polynomials can be added and multiplied using standard operations built from modular arithmetic. For Dilithium, we “conveniently” fix q = 223 − 213 + 1 and n = 256.
, where every coefficient is a integer modulo q. These polynomials can be added and multiplied using standard operations built from modular arithmetic. For Dilithium, we “conveniently” fix q = 223 − 213 + 1 and n = 256. 



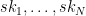 to be her “secret key.”
to be her “secret key.” .
.




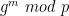 . Recall that in the discussion above, the approach we used was to pick a random point (x, y) first, and then “manufacture” a box as follows:
. Recall that in the discussion above, the approach we used was to pick a random point (x, y) first, and then “manufacture” a box as follows: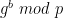 directly from
directly from 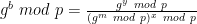
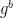 in the instantiation above.) Finally, she will feed her boxed value(s) for both m and b as well as an optional “message” M into the hash function as follows:
in the instantiation above.) Finally, she will feed her boxed value(s) for both m and b as well as an optional “message” M into the hash function as follows: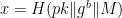

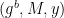 which he can check by re-computing the hash function on the inputs to obtain x and verifying that y is correct (as in the original protocol.)
which he can check by re-computing the hash function on the inputs to obtain x and verifying that y is correct (as in the original protocol.)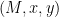 to Victor, who now computes
to Victor, who now computes 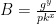 and tests whether
and tests whether 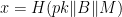 . I will leave the logic of this equation for the reader to work out. Commenter Imuli below points to a
. I will leave the logic of this equation for the reader to work out. Commenter Imuli below points to a 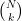 distinct subsets to pick from, the probability that Veronica will select exactly the same subset as Victor did — allowing him to answer her challenge properly — can be made quite small, provided N and k are chosen carefully. (For example, N=128 and k=30 gives about
distinct subsets to pick from, the probability that Veronica will select exactly the same subset as Victor did — allowing him to answer her challenge properly — can be made quite small, provided N and k are chosen carefully. (For example, N=128 and k=30 gives about 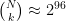 and so Evil Victor will almost never succeed.)
and so Evil Victor will almost never succeed.) 







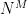 . This probably won’t scale very well for even modest values of M and N, but let’s put this aside for a moment. Given enough paper, we could imagine writing down each unique lookup table on a piece of paper: then we could stack those papers up and admire the minor ecological disaster we’d have just created.
. This probably won’t scale very well for even modest values of M and N, but let’s put this aside for a moment. Given enough paper, we could imagine writing down each unique lookup table on a piece of paper: then we could stack those papers up and admire the minor ecological disaster we’d have just created.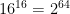 , or about 18 quintillion. It gets worse if you think about “useful” cryptographic functions, say those with the input/output profile of ChaCha20, which has 128-bit inputs and 512-bit outputs. There you’d need a whopping
, or about 18 quintillion. It gets worse if you think about “useful” cryptographic functions, say those with the input/output profile of ChaCha20, which has 128-bit inputs and 512-bit outputs. There you’d need a whopping  (giant) pieces of paper. Since there are only around
(giant) pieces of paper. Since there are only around 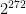 atoms in the observable universe (according to literally the first
atoms in the observable universe (according to literally the first 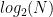 bits of data.
bits of data.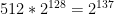 bits.
bits. 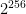 individual functions, where each key value selects exactly one function from the family.
individual functions, where each key value selects exactly one function from the family.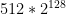 is not.
is not. work, and we assume that there exist reasonable values of n for which no computing device exists that can succeed at this.)
work, and we assume that there exist reasonable values of n for which no computing device exists that can succeed at this.)
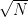 queries. For functions like AES, which has output size
queries. For functions like AES, which has output size 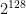 , this will occur around
, this will occur around  queries.
queries. 
 -bit strings, then any statistical “
-bit strings, then any statistical “














 they don’t do it themselves. They instead calling out to a third party, the “random oracle” who keeps a giant table of random function inputs and outputs. At a high level, the model looks like sort of like this:
they don’t do it themselves. They instead calling out to a third party, the “random oracle” who keeps a giant table of random function inputs and outputs. At a high level, the model looks like sort of like this:
 . Building this new scheme will mostly consist of grafting weird bells and whistles onto the algorithms of the original scheme S.
. Building this new scheme will mostly consist of grafting weird bells and whistles onto the algorithms of the original scheme S.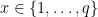 with the specific requirement that q is an integer such that
with the specific requirement that q is an integer such that  . Here
. Here 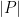 represents the length of the encoding of program P in bits, and k is the scheme’s adjustable security parameter (for example, k=128).
represents the length of the encoding of program P in bits, and k is the scheme’s adjustable security parameter (for example, k=128).