This is part four of a series on the Random Oracle Model. See here for the previous posts:
Part 1: An introduction
Part 2: The ROM formalized, a scheme and a proof sketch
Part 3: How we abuse the ROM to make our security proofs work
This is the penultimate post in a series on the Random Oracle Model. I originally meant for this to be short and tidy, something that could be easily digested by a non-expert who was interested in what cryptographers were up to. More to the point, I expected to be done by now.
I originally meant for this to be short and tidy, something that could be easily digested by a non-expert who was interested in what cryptographers were up to. More to the point, I expected to be done by now.
But the end is in sight, and I feel that there are only a few things left that I want to cover. Even better, one of these topics is of a very practical bent, which is in keeping with the theme of this blog.
Specifically: I keep talking about the random oracle model, but what impact does it have on anyone’s life? Where is this thing used?
Giving a complete answer to that question is hard — it’s kind of like coming up with a list of all the foods that have sodium benzoate in their ingredients list. So in this post I’m going to at least hit at least a couple of the high points, meaning: the schemes that are probably most relevant to our daily security lives.
RSA Signing and Encryption

RSA is probably the most famous cryptosystem in use today. I don’t know exactly why it’s so popular, but I suspect there are few reasons. First of all, RSA is flexible; it provides signature and encryption in one scheme. It’s relatively simple — you can compute simple encryptions with a calculator. It’s been around for a while and hasn’t been broken yet. And I would be remiss if I didn’t mention that there are no current patents on RSA.
This is all great, but in some sense it’s also too bad. Over the past twenty years, attacks on the factoring problem (and by implication, RSA) have been getting better at the margins. This means that RSA key sizes have had to get bigger just to keep up. Sooner or later we’re going to lose this game.*
More interesting (to me) is RSA’s status as a sort-of-provably-secure cryptosystem. There’s a general understanding that RSA encryption is provably secure under the hardness of the RSA problem. However, this really isn’t true, at least given the way that most people have traditionally used RSA. You can get a reduction to the RSA assumption, but you need to take some very specific steps. Most importantly: you need to invoke the random oracle model.
To explain all this, I need to take you back in time to the late 1990s and I need to talk about padding.
If you’ve ever looked at a real RSA implementation, you probably know that we don’t use plain-old ‘textbook’ RSA (“m^e mod N“) to encrypt or sign raw messages. There are lots of reasons for this. One is that plain-old RSA isn’t randomized, meaning that a given message will always encrypt to the same ciphertext.
Another reason is that RSA is malleable, meaning that you can mess with ciphertexts and signatures in creative ways — for example, by multiplying them by constants of your choice. When you do this, the decrypted (resp: verified) message will be altered in predictable ways. This is bad for encryption. It’s downright awful for signatures.
We deal with these problems by applying padding to the message before encrypting or signing it. Padding schemes can add randomness, apply hashing in the case of signature, and most importantly, they typically add structure that lets us know when a message has been tampered with.
Some historical background: RSA before the ROM
The first widely-used, standard padding schemes were described in RSA’s PKCS#1 standard. Nowadays we refer to these as the “PKCS #1 v1.5” standards, with the implication that the standard (now at version 2.1) has left them behind.
Back in the 90s these standards were the only game in town. Sure, there were a few pedantic cryptographers who objected to the lack of formal security justification for the standards. But these troublemakers were mainly confined to academic institutions, which meant that the real security professionals could get on with business.
And that business was to implement the PKCS padding standards everywhere. PKCS #1 v1.5 padding still turns up in products that I evaluate. Most notably at the time, it was all over a young standard known as SSL, which some people were using to encrypt credit card numbers traveling over the Internet.
 |
| Daniel Bleichenbacher shortly after his arrest. Or possibly just posing for a Bell Labs publicity photo. |
Now, I said that almost nobody of a practical bent had a problem with PKCS. One notable exception was a bright cryptographer from Bell Labs named Daniel Bleichenbacher.
Dr. Bleichenbacher had a real problem with the PKCS padding standards. In fact, one could say that he made it his life’s mission to destroy them. This vendetta reached its zenith in 2006, when he showed how to break common implementations of PKCS signature with a pencil and paper, shortly before driving a fireworks-laden minivan into the headquarters of RSA Data Security.
(Ok, the last part did not happen. But the rest of it did.)
Bleichenbacher took his first crack at PKCS in CRYPTO 1998. In a surprisingly readable paper, he proposed the first practical adaptive chosen ciphertext attack against “protocols using the PKCS #1” encryption standard. Since, as I’ve just mentioned, the major protocol that met this description was SSL, it was a pretty big deal.
The attack goes something like this.
Whenever somebody sends their credit card info over an SSL connection to a web server, their browser and server execute a handshake protocol to derive a secret key. In particular, at one step of the protocol, the browser encrypts a very important value called the “pre-master secret” under the server’s RSA public key, and ships the resulting ciphertext to it over net.
This encryption is important, because anyone who decrypts that ciphertext — immediately, or five years later — can ultimately recover the SSL transport key, and hence decrypt all communications between the server and browser.
What Bleichenbacher pointed out was very specific to how most web servers processed RSA messages. Specifically, every time the server receives an RSA ciphertext, it first decrypts it, and then checks that the padding is valid. For a typical RSA key, PKCS #1 padding looks like this:
0x 00 02 { at least 8 non-zero random bytes } 00 { message }
C' = C * s^e mod N
This value C’ will decrypt to “M * s mod N”. Bleichenbacher showed that for some values of “s”, this mauled message might also be a valid PKCS-padded message, meaning that it would begin with “0x 00 02” etc. This wasn’t all that unlikely, mainly because just looking at a couple of bytes was a pretty crappy padding check in the first place.
It was quite common for servers to leak the result of the padding check back to the sender, by way of some specialized error code like “BAD PADDING”. Even if they didn’t do that, you could sometimes detect a failure in the padding check by measuring the time it took the server to get back to you.
Bleichenbacher’s main trick was noting that the “s” values that led to a successful padding check could also be used to learn something about the original message M. To make a long story short, he showed how to choose these values adaptively in such a way as to gradually zero in on the actual plaintext, until he had just one candidate. And that was the ballgame.
The actual attack could require a couple of million decryption queries, on average. This sounds like a lot, but it meant you could decrypt an SSL session overnight, as long as nobody was paying attention to the server logs.
Random Oracles to the Rescue
The Bleichenbacher attack was a big deal for a whole variety of reasons. First of all, it was practical. It worked on a widely-deployed system, and it could be implemented and executed even by non-experts. It completely negated the protections offered by SSL, unless you were willing to monitor your SSL webserver literally night and day.
But to cryptographers the attack had special significance. First, it demonstrated that adaptive-chosen ciphertext attacks were a real problem, not just some airy academic topic. I suspect that even the cryptographers who worked in this area were a bit surprised by this. Some probably started looking for less useful topics to work on.
More importantly, the Bleichenbacher demonstration was seen as a victory for proponents of provable security. Up until now, their concerns had mostly fallen on deaf ears. Now a lot of people were listening.
And even better, the crypto research community had something to say to them. The overwhelming consensus was to immediately switch to a new RSA padding scheme that had been proposed all the way back in 1994. This scheme was called Optimal Asymmetric Encryption Padding (OAEP), and it was only a little bit more complex than PKCS #1. Even better, and unlike PKCS #1, RSA encryption with OAEP could be provably reduced to the hardness of the RSA problem, in the random oracle model.
The success of OAEP also led to the adoption of the PSS padding scheme, which did essentially the same thing for RSA signatures.
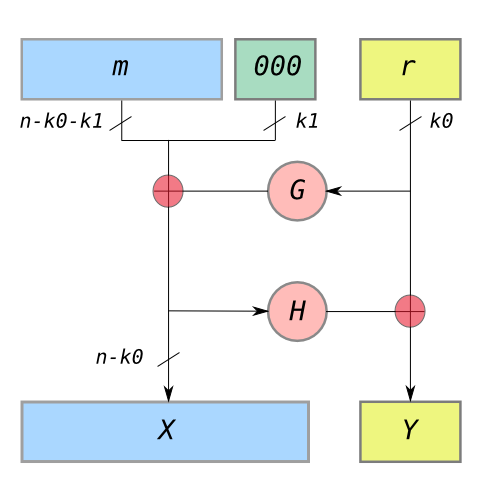 |
| OAEP padding, courtesy Wikipedia. G and H are independent hash functions with different output lengths. |
Now, to hear some people tell it, this is where the story ends. And it’s a good story — bad, unproven security protocol gets broken. New, provably-secure protocol steps in and saves the day.
And for the most part the story is true. With some important caveats.
The first of these is implementation-related. Just as PKCS #1 was broken because the server gave too many detailed errors, even OAEP encryption can break if the server leaks too much info on its error conditions. And when OAEP implementations go bad, they can really go bad. James Manger showed that you can break 1024-bit RSA-OAEP in a mere 1100 queries, assuming your server leaks a little bit too much information on why a given decryption attempt went wrong.****
But even if you do everything correctly, the OAEP security proof only holds in the random oracle model. That means that whatever guarantees it supposedly offers are only valid if the hash function is ideal. That’s a good heuristic, meaning that OAEP is unlikely to be laden with obvious flaws.
But if you dig into the OAEP security proof, you’ll see that it’s using random oracles in about the strongest ways imaginable. The essential concept of OAEP is to use a pair of hash functions to construct a tiny, invertible Feistel network. The beauty is that every time you encrypt, you’re essentially sending the message (and some randomness) directly “through” the random oracle, in a way that permits all sorts of nonsense.
The reduction proof can then see what the adversary’s encrypting, which turns out to be very useful when you’re building a system that’s secure against chosen ciphertext attacks. This would never work if you implemented OAEP with a real hash function, like the ones that are actually used to implement it in real life.
So in one very real sense, we still don’t really have a practical, provably-secure way to encrypt with RSA. Moreover, there’s little reason to believe that we ever will, given a slew of impossibility results that seem to keep getting in the way.*****
All of which raises an important question. Given all the limitations of RSA, why are we so darn attached to it?
The Digital Signature Algorithm (DSA/DSS)
You might find it a bit strange that I’m mentioning DSA in a discussion about provable security. This is mainly because, unlike the Elgamal signature on which DSA is based, the DSA standard has no security proof whatsoever.******
There’s no really defensible reason for this. As best I can tell, NIST took a look at the Elgamal signature and thought it was cute, but the signatures were a little bit too long. So they took some scissors to it and produced something that looks basically the same, but doesn’t have the very nice reduction to the Discrete Logarithm assumption that Elgamal did.
This kind of behavior is par for the course, and honestly it gets me a little down on government standards bodies.
For the record, while DSA isn’t really provably-secure at all, the Elgamal scheme is. But unfortunately, the Elgamal scheme is only provably secure in the random oracle model. This means that if your hash function has the very nice property of being a perfectly random function and programmable, Elgamal signatures can be reduced to the hardness of the Discrete Logarithm problem. But otherwise you’re on your own.
Key Derivation and Beyond
There are probably a zillion cryptosystems that ought to be mentioned here, and we can’t cover them all. Still, there’s one more class of ‘things that hash functions are used for’ that probably isn’t really secure at all, unless you’re willing to make some pretty strong assumptions about the properties of your hash function.
The example I’m thinking of is the use of hashing to derive cryptographic keys. For example, many password-based encryption schemes use a hash function to combine a password and some salt to derive a key for encryption. This approach seems to work ok in most cases (assuming a high entropy password), but it doesn’t have any strong theoretical legs to stand on.
In general, if you’re trying to extract a uniform random key from from a ‘lumpy’, non-uniform source like a password, the proper tool to use is something called a randomness extractor. These can be implemented in the standard model (no random oracles), but all of the existing constructions pretty much suck. This sounds rude, but it’s actually a technical term that cryptographers use to indicate that a scheme is complicated and slow.
So in real life, nobody uses these things. Instead they just hash the password and salt together, and assume that the result will be pretty good. If they’re feeling frisky they might even hash it a bunch of times, which is the crypto equivalent of shooting a turkey with an AK-47. It’s probably just fine, although technically you can never rule out bulletproof turkeys.*******
Whenever people bother to argue formally about the security of schemes like this (which is, essentially, never), the usual argument goes like this: let’s just assume the hash function is a random oracle. In the random oracle model, of course, every hash function is a perfect extractor. Stick any high-entropy source into an ideal hash function, no matter how ‘lumpy’ or ‘weird’ the input is, and you get a fantastic key out the other end.
So even if your favorite key derivation has no formal security proof whatsoever, you can bet somebody, somewhere has made this argument, if only to help themselves sleep better at night.
In Summary
This was supposed to be a post about the random oracle model, but I feel that it took on a life of its own. That’s not a bad thing. I promised that I’d spend some time talking about practical crypto, and I’ve certainly accomplished that.
Although I could say a million things about the random oracle model, I only have one more post left in me. And in some ways, this is going to be the most important post of all.

You see, we always knew that this ride wouldn’t last forever, we just thought we had more time. Unfortunately, the end is nigh. Just like the imaginary city that Leonardo de Caprio explored during the boring part of Inception, the random oracle model is collapsing under the weight of its own contradictions.
This collapse — and what it means for cryptographers, security professionals, and everyone else — will be the subject of my final post.
This series concludes in Part 5.
Notes:
* NIST has begun to deprecate RSA in its FIPS standards. You can use it in some places, but it’s no longer a major supported algorithm.
**** Specifically, the OAEP decoding algorithm has a step in which it decodes the padded plaintext (a value between 0 and N-1) into a bitstring. This requires it to check that the decrypted RSA value is less than 2^n, where n is some number of bits that can be reliably encoded within the range. The Manger attack assumes that the decoding algorithm might leak the result of this check.
***** Although, on the signature side things are a little better. Hohenberger and Waters recently proposed a hash-and-sign RSA signature that’s secure under the RSA assumption without random oracles. This is really a very neat result. Unfortunately it’s inefficient as hell.
****** This is not to say people haven’t tried to piece a proof together. You can do it, if you’re willing to work in the random oracle model, and also assume the existence of leprechauns and unicorns and similarly unrealistic things.
******* In fact, repeated hashing is usually just as as much about making the hash process slow as it is about achieving a strong key. This can be helpful in thwarting dictionary attacks.

Once again, great article. If possible I'd like to put in a request. You mentioned that a randomness extractor should be used for password based key derivations, (vs hash functions). I was wondering if you could expand on what this would look like in practice, (or provide some links to other papers)?
On a nit-picky point; I have a bit of an objection to your phrase “assuming a high entropy password”. A base minimum level of entropy is necessary but not sufficient for a secure password. Because the probability distribution of human generated passwords is not even, the entropy value can significantly under or overestimate the security of individual passwords created in the group. I guess my objections to it are much like your objections to the random-oracle model. Password entropy is used everyone, cryptographers love it, but I'm pretty sure it doesn't prove what they want it to prove 😉
This old discussion of key derivation with hash functions could certainly benefit from a mention of HKDF, a (non-password based) key derivation scheme that tries to minimize the use of the random oracle model:
Click to access 264.pdf
Your first question is a great one, and the simple answer is just to point you to a couple of surveys on this subject. For example, this one (a few years out of date):
http://www.cs.haifa.ac.il/~ronen/online_papers/survey.ps
But this is kind of a cheesy answer, for the simple reason that I just don't /know/ exactly what the state of the art in efficient extractors is today. If you asked me to actually use one in a protocol, I would first have to do a lot of research. Then I would have to write code, and I would be doing this without any real idea of how efficient the ultimate construction would be.
Furthermore, extractor papers are not easy to read, which is definitely one of the reasons that most implementers avoid these things.
“On a nit-picky point; I have a bit of an objection to your phrase “assuming a high entropy password”. “
Password-based cryptography is a fundamentally difficult thing. I think it /is/ possible to come up with relatively high-entropy passwords if you're willing to follow some rules. I also agree that nobody actually does this.
To whit, XKCD: http://xkcd.com/936/
But there are other areas where this kind of thing is important, beyond password-based crypto. Biometrics is the major example I would give. For example, iris scans seem to contain tons of entropy (assuming I don't already have a detailed picture of your eye). But they're not uniform at all.
Cool, thanks for the link. I wasn't aware of any password key-derivation functions that didn't assume the underlying hash-function was a random function and went from there. Unfortunately I'm stuck in the same quandary as everyone else; I'd be very hesitant to design a protocol myself based on my imperfect knowledge of randomness extractors. I fully realize that small misunderstanding and/or oversights can have huge implementation impacts. Still, that's on my radar now so thanks again.
As for password entropy, my main problem is that entropy isn't an effective measurement of the security of the system. That can be a big problem when people assume that it is. I wrote about it more here:
http://reusablesec.blogspot.com/2010/10/ccs-paper-part-2-password-entropy.html
It really comes down to how entropy measurements currently are used. People seem to assume that if a system has an entropy measurement of X bits, then it is as strong against a guessing attack as a random key X bits long. This is only true if the underlying system has an even probability distribution, (aka it's all fair coin flips). To put it another way, unless you can model the success of a realistic password cracking session over time with a straight line, you're going to run into trouble describing the strength of that system as equal to a random key X bits long.
It comes down to the fact that people say they want a password creation method that has a high entropy, but what they really want is a system that is resistant to guessing attacks. As counter-intuitive as it might be, those two things aren't the same.
Ok, that's interesting. I hadn't thought about how you model the resistance of an unstructured password. Now you're making me wish that I hadn't picked password-based crypto as an example, because it's so inherently filled with problems like this one 🙂
Where is part 5 of the series? We want to see the end!!