Unfortunately I had to skip this year’s CCS because I was traveling for work. This means I missed out on a chance to go to my favorite Chicago restaurant and on the architecture cruise. I’m told that there were also some research papers being given somewhere.
for work. This means I missed out on a chance to go to my favorite Chicago restaurant and on the architecture cruise. I’m told that there were also some research papers being given somewhere.
The Internet can’t make up for every missed opportunity, but it can help with the research. In fact, today’s news is all about one of those papers. I’m talking about Tibor Jager and Juraj Somorovsky’s work entitled “How To Break XML Encryption“.*
In case I had any doubts, it only took one glance at the first page to confirm that we’re back in “someone screwed up basic symmetric encryption” territory. But really, to describe Jager and Somorovsky’s findings like this does them no justice. It’s like comparing the time that kid built a nuclear reactor in his garage to, say, the incident at Fukushima.
Some background is in order.
What is XML Encryption and why should I care?
You probably already know that XML is the world’s most popular way to get structured data from point A to point B.** Following the success of HTML, the computing world decided that we needed a single “flexible” and ASCII-based format for handling arbitrary data types. (We’ve spent much of the subsequent period regretting this decision.)
The one upshot of this XML epidemic was the emergence of some standards and libraries, which — among other things — were supposed to help application developers process data in a reliable and secure way. One of those standards is SOAP, which is used to transport data in web services frameworks.
Another standard is the W3C XML Encryption Standard, which was dropped like a log in 2002 and doesn’t seem to have been updated since. The point of this standard was to give developers a uniform (and secure!) way to protect their XML documents so that we wouldn’t wind up with five thousand incompatible, insecure ways of doing it. (Oh the irony.)
Finally, a very common implementation of both standards can be found in the Apache Axis2 web services framework and in the RedHat JBoss framework. These are probably the most common open-source SOAP frameworks. They power a number of systems you don’t necessarily think about, but you probably should because they carry a lot of your personal information.
So what about the encryption?
To make a very long story short, the W3C standard recommends to encrypt messages using a block cipher configured using (our old friend) CBC-mode. Here’s a quick recap on CBC mode, courtesy Wikipedia:
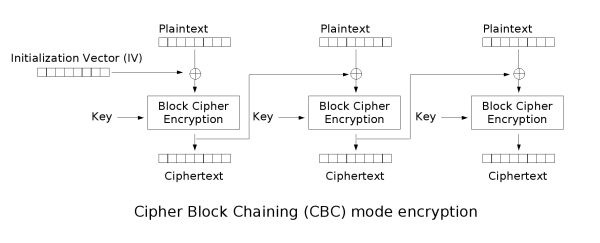 |
| CBC mode encryption. The message is first subdivided into equal-length blocks and encrypted as in the diagram. The circular plus symbol denotes XOR. |
There are two basic things you need to know about CBC mode, and ought to know if you ever plan to use it.***
First: CBC requires that every plaintext be an even multiple of the block size. In the case of AES, this means 16 bytes. If the message is not the right length, then CBC implementations will pad the message with additional bytes. Of course it must be possible to recognize this padding so that it can be stripped off after decryption. There are various schemes for doing this.
The W3C standard uses the following padding approach. Let “MM” indicate message bytes, and let “NN” be the total number of padding bytes being added. “XX” represents arbitrary padding bytes, which can hold any value you want. A padded block will look like this:
0x MM MM MM MM MM MM MM MM MM MM XX XX XX XX XX NN
Anything else I should know?
Yup. You need to know how XML messages are formatted. They’re encoded using UTF-8 — essentially ASCII — with some special rules.
This is all fascinating, but how does it lead to an attack?
There’s one more detail I haven’t given you. You see, in addition to the details above, the Axis2 server (ditto JBoss) is kind enough to let you know when you haven’t met its standards for an XML message.
Specifically, after it decrypts a message, it kicks back an error if the message either: (1) has bad padding, or (2) contains invalid characters. In both cases, the error is the same. And this error is your way in the door.
I’m not going to completely describe the attack, but I’ll try to give an overview.
Imagine that you’ve intercepted a legitimately-encoded, encrypted XML message (IV, C1, …, CN) and you want to know what it says. You also have access to an Axis2 or JBoss server that knows the key and can decrypt it. The server won’t tell you what the message says, but it will give you an error if the encoding doesn’t meet its standards.
Sending the original, intercepted message won’t tell you much. We know that it’s encoded correctly. But what if you tamper with the message? This is precisely what Jager and Somorovsky proceed to do.
Step 1: Truncate the ciphertext. A good way to start is to chop off everything after the first ciphertext block, and send the much-shorter message consisting of (IV, C1) in to be decrypted. Chances are good that this new message will produce a decryption error, since the server will interpret the last byte of the decrypted message as padding — a number that should be between 0x01 and 0x10.
Step 2: Tweak the padding. I already said that if you flip bits in the IV, this will result in a similar change to the decrypted plaintext. Using this concept, you can force the last byte of the IV through all possible values and ask the server to decrypt each version of the ciphertext. More formally, the ‘new’ last IV byte can be computed as (‘original last IV byte’ ⊕ i) for i from 0 to 255.
In the best case, 16 of these test ciphertexts will decrypt without error. These correspond to the decrypted values 0x01 through 0x10, i,e., valid padding. If fewer than 16 of your test ciphertexts decrypt, this means that there’s something wrong with the message: probably it contains an unclosed “<” tag.
Step 3: Squish the bug(s). This is no problem. If exactly only one of your ciphertexts decrypts successfully, that means the open “<” character must in the first byte of the message. You caused the last byte of the message to decrypt to 0x10 (16 decimal), and the decryptor treated the whole block as padding. There are no errors in an empty message.
If two ciphertexts decrypt successfully, then the “<” character must be in the second position of the message, because now there are only two padding lengths (16 and 15) that would cause it to be stripped off. And so on. The number of successful decryptions tells you where the “<” is.
Now that you know where it is, kill it by flipping the last bit of the appropriate byte in the IV. This turns “<” into a harmless “=”.
Step 4: Learn the last byte of the block. You should now be able to come up with 16 test ciphertexts that decrypt successfully. This means you have 16 values of “i” such that ‘last byte of the original IV’ ⊕ i results in a successful decryption. One of these “i” values will differ from the others in the fourth most significant bit. This one will correspond to the padding value 0x10.
If “x” is the original plaintext byte and “i” is the value you just identified, you know now the last byte of the block. Since we have x ⊕ i = 0x10, then through the very sophisticated process of rearranging a simple equation we have 0x10 ⊕ i = x.
Now, using our knowledge of the last byte of the plaintext, manually tweak the IV so that the last byte (padding) of the plaintext will decrypt to 0x01.
Step 5: Learn everything else. The rest of the attack hinges on the fact that all of the bytes in the message should be ‘acceptable’ UTF-8 characters. Thanks to our trick with the IV, we can now flip arbitrary bits in any given byte, and see whether or not that leads to another ‘acceptable’ character or not.
Believe it or not, the results of this experiment tell us enough to figure out each character in turn. I won’t belabor this, because it takes a little bit of squinting at the ASCII table, but fundamentally there’s not much magic beyond that. It’s very simple and elegant, and it works.
Step 6: Finish it. You’ve done this for one block. Now do it for the rest. Just set your ‘ciphertext’ to be the next block in the message, and your ‘IV’ to be the ciphertext block immediately preceding it. Now go back to Step 1.
And that’s the ballgame.
Obviously all of this takes a lot of tests, which you can reduce a bit using some of the optimizations suggested in the paper. Jager and Somorovsky are able to recover plaintexts with “14 requests per plaintext byte on average.” But at the end of the day, who cares if it takes 50? The box is sitting there ready and willing to decrypt ciphertexts. And it’s incredibly unlikely that anyone is paying attention.
Ok. Can’t you fix this by authenticating the ciphertexts?
This entire attack is a special example of an adaptive chosen ciphertext attack. (Specifically, it’s a super-duper variation of Vaudenay’s padding oracle attack, which he discovered in 2002, the same year the W3C standard hit!)
These attacks can almost always be prevented with proper authentication of the ciphertexts. If the decryptor checks that the ciphertexts are valid before decrypting them, the attacker can’t tamper with them. Hence, no useful information should leak out to permit these attacks at all.
The designers could have added a mandatory MAC or even a signature on the ciphertext, or they could have used an authenticated mode of operation.
But the W3C standard does provide for MACs and signatures!
Indeed. As the authors point out, there’s an optional field in the specification where you can add a signature or a MAC over the ciphertext and its meta data. But there’s one tiny, hilarious thing about that signature…
Did I mention it’s optional?
You can quite easily take a signed/MACed ciphertext and ‘convert’ it into one that’s not signed or MACed at all, simply by stripping the ciphertext contents out and placing them into a section that does not claim to have a signature. Since the spec doesn’t mandate that the authentication be on every message, the decryptor will be totally cool with this.
So in summary: optional MACs and signatures don’t buy you much.
Is there anything else to say about this?
Lots. Stop using unauthenticated CBC mode. Stop using any encryption standard designed before 2003 that hasn’t been carefully analyzed and recently updated. Stop using any unauthenticated encryption at all. Wrap your SOAP connections with TLS (a recent version!) if you can.
People didn’t really think much about active chosen ciphertext attacks on symmetric encryption before 2000, but now they’re the new hip thing. If your system is online and doesn’t have a solid, well-analyzed protection against them, don’t pretend that you’re doing anything at all to secure your data.
I wish I had a funny, pithy way to sum this all up. But honestly, I’m just a little depressed. It’s not Jager and Somorosky’s fault at all — this is a great paper. It’s just that there’s too much embarrassingly bad crypto going around.
While I love reading these papers, I’m starting to feel that this one-off approach is not sufficient to the problem. Maybe what the community needs is a centralized clearinghouse for this stuff, a website where suspect crypto standards (and implementations) can be identified and listed. Crowdsourced and analyzed. Probably many are just fine, but I doubt most have been looked at (or even thought about in a while).
Anyone looking for a project?
Notes:
* Tibor Jager and Juraj Somorovsky, “How To Break XML Encryption”. In ACM CCS 2011. ACM Press.
** Someone is inevitably going to tell me that JSON is the world’s most popular way to move structured data. Ok. I don’t care.
*** But better yet, don’t use it. Use a standard authenticated encryption scheme like CCM, OCB or GCM, and use someone else’s implementation according to the standards. These modes should prevent all of this nonsense.
**** These details are quoted straight from the Jager and Somorovsky paper. I’m not 100% sure if all implementations enforce this, but Axis2 does.

Great post and great blog. Reminds me of the ASP.net attack last year.
The post is so good I replaced my own post on the subject (@ Good Enough Security) with a link to here 🙂
Good for you for catching up! I want to enjoy the ballgame about XML Encryption as much as you do. What are the basic knowledge that I should know first?