One of the saddest and most fascinating things about applied cryptography is how  little cryptography we actually use. This is not to say that cryptography isn’t widely used in industry — it is. Rather, what I mean is that cryptographic researchers have developed so many useful technologies, and yet industry on a day to day basis barely uses any of them. In fact, with a few minor exceptions, the vast majority of the cryptography we use was settled by the early-2000s.*
little cryptography we actually use. This is not to say that cryptography isn’t widely used in industry — it is. Rather, what I mean is that cryptographic researchers have developed so many useful technologies, and yet industry on a day to day basis barely uses any of them. In fact, with a few minor exceptions, the vast majority of the cryptography we use was settled by the early-2000s.*
Most people don’t sweat this, but as a cryptographer who works on the boundary of research and deployed cryptography it makes me unhappy. So while I can’t solve the problem entirely, what I can do is talk about some of these newer technologies. And over the course of this summer that’s what I intend to do: talk. Specifically, in the next few weeks I’m going to write a series of posts that describe some of the advanced cryptography that we don’t generally see used.
Today I’m going to start with a very simple question: what lies beyond public key cryptography? Specifically, I’m going to talk about a handful of technologies that were developed in the past 20 years, each of which allows us to go beyond the traditional notion of public keys.
This is a wonky post, but it won’t be mathematically-intense. For actual definitions of the schemes, I’ll provide links to the original papers, and references to cover some of the background. The point here is to explain what these new schemes do — and how they can be useful in practice.
Identity Based Cryptography
In the mid-1980s, a cryptographer named Adi Shamir proposed a radical new idea. The idea, put simply, was to get rid of public keys.
To understand where Shamir was coming from, it helps to understand a bit about public key encryption. You see, prior to the invention of public key crypto, all cryptography involved secret keys. Dealing with such keys was a huge drag. Before you could communicate securely, you needed to exchange a secret with your partner. This process was fraught with difficulty and didn’t scale well.
Public key encryption (beginning with Diffie-Hellman and Shamir’s RSA cryptosystem) hugely revolutionized cryptography by dramatically simplifying this key distribution process. Rather than sharing secret keys, users could now transmit their public key to other parties. This public key allowed the recipient to encrypt to you (or verify your signature) but it could not be used to perform the corresponding decryption (or signature generation) operations. That part would be done with a secret key you kept to yourself.
While the use of public keys improved many aspects of using cryptography, it also gave rise to a set of new challenges. In practice, it turns out that having public keys is only half the battle — people still need to use distribute them securely.
For example, imagine that I want to send you a PGP-encrypted email. Before I can do this, I need to obtain a copy of your public key. How do I get this? Obviously we could meet in person and exchange that key on physical media — but nobody wants to do this. It would much more desirable to obtain your public key electronically. In practice this means either (1) we have to exchange public keys by email, or (2) I have to obtain your key from a third piece of infrastructure, such as a website or key server. And now we come to the problem: if that email or key server is untrustworthy (or simply allows anyone to upload a key in your name), I might end up downloading a malicious party’s key by accident. When I send a message to “you”, I’d actually be encrypting it to Mallory.

Solving this problem — of exchanging public keys and verifying their provenance — has motivated a huge amount of practical cryptographic engineering, including the entire web PKI. In most cases, these systems work well. But Shamir wasn’t satisfied. What if, he asked, we could do it better? More specifically, he asked: could we replace those pesky public keys with something better?
Shamir’s idea was exciting. What he proposed was a new form of public key cryptography in which the user’s “public key” could simply be their identity. This identity could be a name (e.g., “Matt Green”) or something more precise like an email address. Actually, it didn’t realy matter. What did matter was that the public key would be some arbitrary string — and not a big meaningless jumble of characters like “7cN5K4pspQy3ExZV43F6pQ6nEKiQVg6sBkYPg1FG56Not”.
Of course, using an arbitrary string as a public key raises a big problem. Meaningful identities sound great — but I don’t own them. If my public key is “Matt Green”, how do I get the corresponding private key? And if I can get out that private key, what stops some other Matt Green from doing the same, and thus reading my messages? And ok, now that I think about this, what stops some random person who isn’t named Matt Green from obtaining it? Yikes. We’re headed straight into Zooko’s triangle.
Shamir’s idea thus requires a bit more finesse. Rather than expecting identities to be global, he proposed a special server called a “key generation authority” that would be responsible for generating the private keys. At setup time, this authority would generate a single master public key (MPK), which it would publish to the world. If you wanted to encrypt a message to “Matt Green” (or verify my signature), then you could do so using my identity and the single MPK of an authority we’d both agree to use. To decrypt that message (or sign one), I would have to visit the same key authority and ask for a copy of my secret key. The key authority would compute my key based on a master secret key (MSK), which it would keep very secret.
With all algorithms and players specified, whole system looks like this:

This design has some important advantages — and more than a few obvious drawbacks. On the plus side, it removes the need for any key exchange at all with the person you’re sending the message to. Once you’ve chosen a master key authority (and downloaded its MPK), you can encrypt to anyone in the entire world. Even cooler: at the time you encrypt, your recipient doesn’t even need to have contacted the key authority yet. She can obtain her secret key after I send her a message.
Of course, this “feature” is also a bug. Because the key authority generates all the secret keys, it has an awful lot of power. A dishonest authority could easily generate your secret key and decrypt your messages. The polite way to say this is that standard IBE systems effectively “bake in” key escrow.**
Putting the “E” in IBE
All of these ideas and more were laid out by Shamir in his 1984 paper. There was just one small problem: Shamir could only figure out half the problem.
Specifically, Shamir’s proposed a scheme for identity-based signature (IBS) — a signature scheme where the public verification key is an identity, but the signing key is generated by the key authority. Try as he might, he could not find a solution to the problem of building identity-based encryption (IBE). This was left as an open problem.***
It would take more than 16 years before someone answered Shamir’s challenge. Surprisingly, when the answer came it came not once but three times.
The first, and probably most famous realization of IBE was developed by Dan Boneh and Matthew Franklin much later — in 2001. The timing of Boneh and Franklin’s discovery makes a great deal of sense. The Boneh-Franklin scheme relies fundamentally on elliptic curves that support an efficient “bilinear map” (or “pairing”).**** The algorithms needed to compute such pairings were not known when Shamir wrote his paper, and weren’t employed constructively — that is, as a useful thing rather than an attack — until about 2000. The same can be said about a second scheme called Sakai-Kasahara, which would be independently discovered around the same time.
(For a brief tutorial on the Boneh-Franklin IBE scheme, see this page.)
The third realization of IBE was not as efficient as the others, but was much more surprising. This scheme was developed by Clifford Cocks, a senior cryptologist at Britain’s GCHQ. It’s noteworthy for two reasons. First, Cocks’ IBE scheme does not require bilinear pairings at all — it is based in the much older RSA setting, which means in principle it spent all those years just waiting to be found. Second, Cocks himself had recently become known for something even more surprising: discovering the RSA cryptosystem, nearly five years before RSA did. To bookend that accomplishment with a second major advance in public key cryptography was a pretty impressive accomplishment.
In the years since 2001, a number of additional IBE constructions have been developed, using all sorts of cryptographic settings. Nonetheless, Boneh and Franklin’s early construction remains among the simplest and most efficient.
Even if you’re not interested in IBE for its own sake, it turns out that this primitive is really useful to cryptographers for many things beyond simple encryption. In fact, it’s more helpful to think of IBE as a way of “pluralizing” a single public/secret master keypair into billions of related keypairs. This makes it useful for applications as diverse as blocking chosen ciphertext attacks, forward-secure public key encryption, and short signature schemes.
Attribute Based Encryption
Of course, if you leave cryptographers alone with a tool like IBE, the first thing they’re going to do is find a way to make things more complicated improve on it.
One of the biggest such improvements is due to Sahai and Waters. It’s called Attribute-Based Encryption, or ABE.
The origin of this idea was not actually to encrypt with attributes. Instead Sahai and Waters were attempting to develop an Identity-Based encryption scheme that could encrypt using biometrics. To understand the problem, imagine I decide to use a biometric like your iris scan as the “identity” to encrypt you a ciphertext. Later on you’ll ask the authority for a decryption key that corresponds to your own iris scan — and if everything matches up and you’ll be able to decrypt.
The problem is that this will almost never work.
The issue here is that biometric readings (like iris scans or fingerprint templates) are inherently error-prone. This means every scan will typically be very close, but often there will be a few bits that disagree. With standard IBE

this is fatal: if the encryption identity differs from your key identity by even a single bit, decryption will not work. You’re out of luck.
Sahai and Waters decided that the solution to this problem was to develop a form of IBE with a “threshold gate”. In this setting, each bit of the identity is represented as a different “attribute”. Think of each of these as components you’d encrypt under — something like “bit 5 of your iris scan is a 1” and “bit 23 of your iris scan is a 0”. The encrypting party lists all of these bits and encrypts under each one. The decryption key generated by the authority embeds a similar list of bit values. The scheme is defined so that decryption will work if and only if the number of matching attributes (between your key and the ciphertext) exceeds some pre-defined threshold: e.g., any 2024 out of 2048 bits must be identical in order to decrypt.
The beautiful thing about this idea is not fuzzy IBE. It’s that once you have a threshold gate and a concept of “attributes”, you can more interesting things. The main observation is that a threshold gate can be used to implement the boolean AND and OR gates, like so:
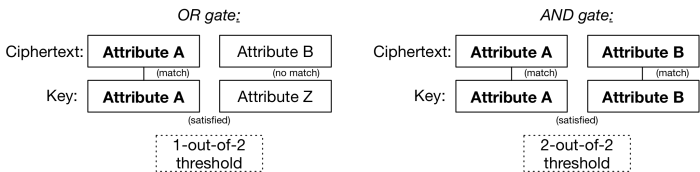
Even better, you can stack these gates on top of one another to assign a fairly complex boolean formula — which will itself determine what conditions your ciphertext can be decrypted under. For example, switching to a more realistic set of attributes, you could encrypt a medical record so that either a pediatrician in a hospital could read it, or an insurance adjuster could. All you’d need is to make sure people received keys that correctly described their attributes (which are just arbitrary strings, like identities).

The other direction can be implemented as well. It’s possible to encrypt a ciphertext under a long list of attributes, such as creation time, file name, and even GPS coordinates indicating where the file was created. You can then have the authority hand out keys that correspond to a very precise slice of your dataset — for example, “this key decrypts any radiology file encrypted in Chicago between November 3rd and December 12th that is tagged with ‘pediatrics’ or ‘oncology'”.
Functional Encryption
Once you have a related of primitives like IBE and ABE, the researchers’ instinct is to both extend and generalize. Why stop at simple boolean formulae? Can we make keys (or ciphertexts) that embed arbitrary computer programs? The answer, it turns out, is yes — though not terribly efficiently. A set of recent works show that it is possible to build ABE that works over arbitrary polynomial-size circuits, using various lattice-based assumptions. So there is certainly a lot of potential here.
This potential has inspired researchers to generalize all of the above ideas into a single class of encryption called “functional encryption“. Functional encryption is more conceptual than concrete — it’s just a way to look at all of these systems as instances of a specific class. The basic idea is to represent the decryption procedure as an algorithm that computes an arbitary function F over (1) the plaintext inside of a ciphertext, and (2) the data embedded in the key. This function has the following profile:
output = F(key data, plaintext data)
In this model IBE can be expressed by having the encryption algorithm encrypt (identity, plaintext) and defining the function F such that, if “key input == identity”, it outputs the plaintext, and outputs an empty string otherwise. Similarly, ABE can be expressed by a slightly more complex function. Following this paradigm, once can envision all sorts of interesting functions that might be computed by different functions and realized by future schemes.
But those will have to wait for another time. We’ve gone far enough for today.
So what’s the point of all this?
For me, the point is just to show that cryptography can do some pretty amazing things. We rarely see this on a day-to-day basis when it comes to industry and “applied” cryptography, but it’s all there waiting to be used.
Perhaps the perfect application is out there. Maybe you’ll find it.
Notes:
* An earlier version of this post said “mid-1990s”. In comments below, Tom Ristenpart takes issue with that and makes the excellent point that many important developments post-date that. So I’ve moved the date forward about five years, and I’m thinking about how to say this in a nicer way.
** There is also an intermediate form of encryption known as “certificateless encryption“. Proposed by Al-Riyami and Paterson, this idea uses a combination of standard public key encryption and IBE. The basic idea is to encrypt each message using both a traditional public key (generated by the recipient) and an IBE identity. The recipient must then obtain a copy of the secret key from the IBE authority to decrypt. The advantages here are twofold: (1) the IBE key authority can’t decrypt the message by itself, since it does not have the corresponding secret key, which solves the “escrow” problem. And (2) the sender does not need to verify that the public key really belongs to the sender (e.g., by checking a certificate), since the IBE portion prevents imposters from decrypting the resulting message. Unfortunately this system is more like traditional public key cryptography than IBE, and does not have the neat usability features of IBE.
*** A part of the challenge of developing IBE is the need to make a system that is secure against “collusion” between different key holders. For example, imagine a very simple system that has only 2-bit identities. This gives four possible identities: “00”, “01”, “10”, “11”. If I give you a key for the identity “01” and I give Bob a key for “10”, we need to ensure that you two cannot collude to produce a key for identities “00” and “11”. Many earlier proposed solutions have tried to solve this problem by gluing together standard public encryption keys in various ways (e.g., by having a separate public key for each bit of the identity and giving out the secret keys as a single “key”). However these systems tend to fail catastrophically when just a few users collude (or their keys are stolen). Solving the collusion problem is fundamentally what separates real IBE from its faux cousins.
**** A full description of Boneh and Franklin’s scheme can be found here, or in the original paper. Some code is here and here and here. I won’t spend more time on it, except to note that the scheme is very efficient. It was patented and implemented by Voltage Security, now part of HPE.

Hi Matthew, enjoyed reading your latest post. Fascinating! Took Dan Boneh’s crypto class couple years back and now looking forward to his next Coursera class which will focus on various IBE schemes, some of which Dan helped introduce.
Given advent of quantum computing power and useful Block Chain technology via crypto currencies, I believe these protocols (ZK, IBE, etc) will play a significant role in promoting better privacy and security environments (data in motion) especially in cyber space. Note: Boot strapping IBE schemes with biometrics is interesting, conceptually, but from a privacy point of view could be problematic, given LE can compel one to unlock their device if they use their unique biometric fingerprint, but cannot if you hold the “key” in your head. Your unique biometric identity can be used as witness testimony. Of course that does not mean methods cannot be used to force one to eventually give-up he key – being incarcerate for an” indefinite” period of time might be incentive enough for most people.
Appreciate your post
Suggestion: Google Search Identity Based Encryption
A Google search for someone will bring up information about them that is publicly available. Trying to fake this information would be difficult. You would have to ensure that Alice and Bob both got the same bogus search results at different times (encrypt/decrypt) and different locations. Since Google search results are fed from sites across the planet this is a formidable challenge.
Any attempt to fake these results “at the source” within Google would be publicly obvious.
So the trick is to leverage public search data rather than Iris scans.
It’s not surprising IBE has not had any adoption, if it basically requires entrusting the Key Generation Authority with the ability to decrypt your messages. In an era where even the NSA can’t keep its secrets, RSA can’t keep SecurID, well, secure, and certificate authorities fail at their only job, the idea that any such authority can be trusted is simply laughable, even before we consider their susceptibility to government coercion.
Hi
I love your blog; thank you for always being able to explain stuff to non-mathematicians!
I would like to offer my thoughts on why the world at large has not moved beyond PKI. Apologies for the rambling!
I’ll start with saying: none of the below means that these no-doubt great crypto ideas are not applicable in specific, possibly un-common, circumstances; just that in most systems that are in use today, they don’t work well enough, if at all.
My background is I work for TCS, which is a large-ish IT services company. I used to be (many years ago) a development manager type person but I haven’t done that for a while now. I like to think of what I do now as a bit of research, plus a lot of internal consulting on security matters.
Firstly, speaking from an IT services point of view, we almost never offer to use anything that has not been standardised in some fashion (for example by NIST; mis-adventures like Dual EC DRBG notwithstanding!)
Secondly, if I again don my “development manager” hat, there is no way I will allow my team to *write* their own crypto — I don’t have any Dan Bernsteins on my team! Equally, there is no way I will let them use any algorithm that does not have at least two public, open source (GPL, Apache, whatever…) implementations, preferably in two different languages.
These are just basic hygiene for enterprise use of crypto. In fact, it would be a hugely optimistic (or knowledge-lacking) customer who knowingly agreed to let us violate these constraints.
IBE:
To your specific algorithms now, starting with IBE.
I have two issues with IBE. First, with standard PKI, I do the identification once, when I sign the key he presents. After that if he has the key, he’s who he claims to be. The key *is* the identity proof, from that point on; I’m done with that problem.
IBE passes the problem of proving identity to something else, and then hands out a private key based on that proof. That’s always struck me as particularly problematic.
Worse, since so many people are fond of predicting the death of the password (no comment!), proving identity is often **best** done with keys of some kind — ssh keys, 2-factor keys, yubikeys, keys in some other sort of crypto device, whatever.
Catch-22!
In fact, since you and I have to agree on a server anyway, it may as well be my **PKI** server that you ask for my public key. What’s the difference? I see little!
(Literally the only advantage I see is the ability for me to receive an encrypted message *before* I have had a chance to download my private key, but you have to admit that’s hardly a “killer use case” in the big picture!)
Back to my PKI server, maybe I can even **choose to** allow it to keep my *private* key safe, and give it only to me in case I ever lose it! That replicates that behaviour of the IBE server also!
But that brings me to my second problem. You called it “key escrow”, but, in my humble opinion, that does not go far enough in making sure people get the true depth of the problem. I prefer to call it “lack of non-repudiation”, or, “anyone can claim the server impersonated them!”
And honestly, trusting a third party seems a bit optimistic in 2017.
(Finally, look at the phrasing you used: “pluralizing a single public/secret master keypair into billions of related keypairs”. That already implies that all those billions of related keypairs somehow “belong” to whoever owns the single master pair. It certainly does not lend itself to an interpretation where the billions of keypairs belong to a number of *independent users*, such as in an enterprise environment)
ABE:
ABE also sounds interesting, until you get into the weeds. (I appreciate your honesty, of writing “make things more complicated” in a strike-through font!). It is indeed complicated, and yet seems to offer no real benefits — when you consider deployment issues, over an ACL based system baked into the server side application.
If you assume that the bulk of the information is “in the cloud”, and the end point accessing it is just used as a reasonably dumb accessor device that only asks for their identity in some fashion, and passes it to the server, ABE does not add any value whatsoever. (The hospital example you used could fit this model quite well, and indeed I think most hospital systems are heavily server based).
The second problem with ABE is that monitoring bad behaviour is much harder — any failed attempts to decrypt are not always known to the server, unlike with a server-mediated access control mechanism that stops, and counts (and reports), the attempted **download** itself, if it is in violation.
And that point is much more important when you consider that revocations have always been a problem in ABE. Someone who saves old keys, can definitely read all documents he is no longer allowed to. Even if some expensive re-encryption, or proxy re-encryption, is performed, that won’t save documents he downloaded *before* his rights were revoked. (He can do that in an server-side access managed system too, but that’s an active system that’s counting his downloads and may be better able to report that “John in Finance has downloaded 320 documents last night, which is unusual for him; please check!”).
Basically, I’d rather control the initial download, because after that I have no real control!
Anyway, I think I’ve rambled enough, so I’ll give FE a miss 🙂 Thanks for listening.
I also have encountered the “lack-of-standard” problem with anything newer than 1990’s crypto.
If there isn’t an accepted specification from a reputable standards body, that guarantees at least some level of interoperability, then some organisations will not consider going further. This is partly for the valid reason that implementing a non-interoperable standard locks the company into maintaining that code forever more. When a company, as many do, outsource development and maintenance, the contractor who implemented the system has freedom to charge what they like. I hit this obstacle when working on a system for which a simple hash-chain would have been the ideal solution, but where’s the NIST standard for a hash-chain?
I think this is one reason that blockchains have become so popular. The vast majority of users don’t need all they offer, but they are at least a standard, to some extent.
Interesting ideas! Thank you for sharing!
Interesting article but it doesn’t explain how the new IBE systems avoid the problem of depending on a central authority.
I regularly enjoy reading your blog, Matt, but with all due respect, I couldn’t read past the first paragraph this time! I was floored by the following statement: “In fact, with a few minor exceptions, the vast majority of the cryptography we use was settled by the mid-1990s.”
The examples refuting this statement are everywhere: hash function design (SHA-2, SHA-3), block cipher design (AES), authenticated encryption, format-preserving encryption, disk encryption schemes, memory hard password hashing (scrypt, argon2), OTR (and in turn Signal), side-channel resistant implementations …. Actually the more I think about it the harder it is to find examples of in-use crypto primitives that have *not* seen significant research developments since the mid 1990s. According to your post we live in a world of mid 1990s crypto: one would be using MD5 for hashing, DES for encryption, all deployed encryption would be malleable, ad nauseam. Of course there is still broken legacy crypto around, but the point is that we know how to do better, thanks to a ton of amazing crypto research that your blog implies never existed.
By seemingly (and probably unintentionally) dismissing all these topics as not worthy of research (having been settled so long ago), I worry that your comments will discourage people from working on all the important problems in applied crypto we still face. This would be a huge tragedy! Sure, the research community should work on speculative primitives that may (or may not) be practically relevant in the future (who knows where breakthroughs will come from), but let’s not forget all the fantastic, fundamental research that has already had, and continues to have, tangible impact on security in practice.
Tom, the post is about “beyond public key crypto”, all your examples are about symmetric key crypto. Don’t worry, Matt is not dismissing your fantastic research.
Even just considering public-key crypto, his statement is not really supported by the evidence. Modern forward-secure key exchange protocols weren’t developed until the mid-2000s. Proper padding modes for RSA encryption and signing came at the end of the 90s and early 2000s. Many of the most widely-used elliptic curves (e.g. Curve25519) are quite recent as well.
I think this is probably a good point. I responded in part on Twitter and I’ll summarize here. I’m including some of Anon1’s points as well:
* OAEP padding for RSA: 1994 (and it’s still not used in TLS 1.2)
* AES (Rijndeal): 1998
* IAPM (one of the earlier one-pass AE modes): 2000
* SHA-2: 2001
* Modern forward-secure KE protocols: tough to say, maybe 2000/1 for MQV, but TLS and IKE still do their own thing (we can argue about TLS 1.3)
* Disk encryption schemes (I dunno that any of the more modern wide-pipe modes are heavily used. I checked and Bitlocker uses CBC mode, Apple iOS ses CTR or something. A few implementations use XTS mode but that’s not something to be proud of.)
Based on that list it looks like the cryptographic “drop dead line” is actually about 2001, so I was off by 5 years or so and I’ve updated the post. There are still a few exceptions: memory-hard hash functions (2007), OTR (2004) and (software) side-channel resistant implementations (who knows) are more recent (i.e., 2000s) inventions. You could also throw Curve25519, Salsa/ChaCha, although these also leverage techniques known earlier.
What’s notable about this list is that very few of these are fundamentally new *types* of primitive, in the sense that IBE/IBS was a fundamentally different type of primitive from PKE. Inventing new hash functions (that fit known profiles) and new ciphers (that fit known applications) is very useful and important — but it’s mostly “replacing windows” rather than “building new houses”.
However, with all that said: my point in this series is not to crap on the developments that people have made and deployed, but to point out some of the neater technologies that we haven’t. So if my intro gives you this reaction I’ll try to figure out how to make my point a bit better.
Accessing a key authority every time one needs to encrypt/decrypt may be a big issue for dissidents in authoritarian regimes due to meta data interception.
This is in contrast to standard PKE where one can collect public keys ahead of any actual use, and get them from a variety of sources (and not only from key servers).
To clarify, one doesn’t need to get the key *every* time, just the first time. Once you request the key you can use it to decrypt any message sent to your identity.
> Actually, it didn’t realy matter.
> you can more interesting things.