The first rule of PAKE is: nobody ever wants to talk about PAKE. The second rule of  PAKE is that this is a shame, because PAKE — which stands for Password Authenticated Key Exchange — is actually one of the most useful technologies that (almost) never gets used. It should be deployed everywhere, and yet it isn’t.
PAKE is that this is a shame, because PAKE — which stands for Password Authenticated Key Exchange — is actually one of the most useful technologies that (almost) never gets used. It should be deployed everywhere, and yet it isn’t.
To understand why this is such a damn shame, let’s start by describing a very real problem.
Imagine I’m operating a server that has to store user passwords. The traditional way to do this is to hash each user password and store the result in a password database. There are many schools of thought on how to handle the hashing process; the most common recommendation these days is to use a memory-hard password hashing function like scrypt or argon2 (with a unique per-password salt), and then store only the hashed result. There are various arguments about which hash function to use, and whether it could help to also use some secret value (called “pepper“), but we’ll ignore these for the moment.
Regardless of the approach you take, all of these solutions have a single achilles heel:
When the user comes back to log into your website, they will still need to send over their (cleartext) password, since this is required in order for the server to do the check.
This requirement can lead to disaster if your server is ever persistently compromised, or if your developers make a simple mistake. For example, earlier this year Twitter asked all of its (330 million!) users to change their passwords — because it turned out that company had been logging cleartext (unhashed) passwords.
Now, the login problem doesn’t negate the advantage of password hashing in any way. But it does demand a better solution: one where the user’s password never has to go to the server in cleartext. The cryptographic tool that can give this to us is PAKE, and in particular a new protocol called OPAQUE, which I’ll get to at the end of this post.
What’s a PAKE?
A PAKE protocol, first introduced by Bellovin and Merritt, is a special form of cryptographic key exchange protocol. Key exchange (or “key agreement”) protocols are designed to help two parties (call them a client and server) agree on a shared key, using public-key cryptography. The earliest key exchange protocols — like classical Diffie-Hellman — were unauthenticated, which made them vulnerable to man-in-the-middle attacks. The distinguishing feature of PAKE protocols is the client will authenticate herself to the server using a password. For obvious reasons, the password, or a hash of it, is assumed to be already known to the server, which is what allows for checking.
If this was all we required, PAKE protocols would be easy to build. What makes a PAKE truly useful is that it should also provide protection for the client’s password. A stronger version of this guarantee can be stated as follows: after a login attempt (valid, or invalid) both the client and server should learn only whether the client’s password matched the server’s expected value, and no additional information. This is a powerful guarantee. In fact, it’s not dissimilar to what we ask for from a zero knowledge proof.
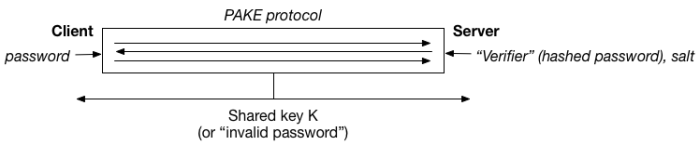
Of course, the obvious problem with PAKE is that many people don’t want to run a “key exchange” protocol in the first place! They just want to verify that a user knows a password.
The great thing about PAKE is that the simpler “login only” use-case is easy to achieve. If I have a standard PAKE protocol that allows a client and server to agree on a shared key K if (and only if) the client knows the right password, then all we need add is a simple check that both parties have arrived at the same key. (This can be done, for example, by having the parties compute some cryptographic function with it and check the results.) So PAKE is useful even if all you’ve got in mind is password checking.
SRP: The PAKE that Time Forgot
The PAKE concept seems like it provides an obvious security benefit when compared to the naive approach we use to log into servers today. And the techniques are old, in the sense that PAKEs have been known since way back in 1992! Despite this, they’ve seen from almost no adoption. What’s going on?
There are a few obvious reasons for this. The most obvious has to do with the limitations of the web: it’s much easier to put a password form onto a web page than it is to do fancy crypto in the browser. But this explanation isn’t sufficient. Even native applications rarely implement PAKE for their logins. Another potential explanation has to do with patents, though most of these are expired now. To me there are two likely reasons for the ongoing absence of PAKE: (1) there’s a lack of good PAKE implementations in useful languages, which makes it a hassle to use, and (2) cryptographers are bad at communicating the value of their work, so most people don’t know PAKE is even an option.
Even though I said PAKE isn’t deployed, there are some exceptions to the rule.
One of the remarkable ones is a 1998 protocol designed by Tom Wu [correction: not Tim Wu] and called “SRP”. Short for “Secure Remote Password“, this is a simple three-round PAKE with a few elegant features that were not found in the earliest works. Moreover, SRP has the distinction of being (as far as I know) the most widely-deployed PAKE protocol in the world. I cite two pieces of evidence for this claim:
- SRP has been standardized as a TLS ciphersuite, and is actually implemented in libraries like OpenSSL, even though nobody seems to use it much.
- Apple uses SRP extensively in their iCloud Key Vault.
This second fact by itself could make SRP one of the most widely used cryptographic protocols in the world, so vast is the number of devices that Apple ships. So this is nothing to sneer at.
Industry adoption of SRP is nice, but also kind of a bummer: mainly because while any PAKE adoption is cool, SRP itself isn’t the best PAKE we can deploy. I was planning to go into the weeds about why I feel so strongly about SRP, but it got longwinded and it distracted from the really nice protocol I actually want to talk about further below. If you’re still interested, I moved the discussion onto this page.
In lieu of those details, let me give a quick and dirty TL;DR on SRP:
- SRP does some stuff “right”. For one thing, unlike early PAKEs it does not require you to store a raw password on the server (or, equivalently, a hash that could be used by a malicious client in place of the password). Instead, the server stores a “verifier” which is a one-way function of the password hash. This means a leak of the password database does not (immediately) allow the attacker to impersonate the user — unless they conduct further expensive dictionary attacks. (The technical name for this is “asymmetric” PAKE.)
- Even better, the current version of SRP (
v4v6a) isn’t obviously broken! - However (and with no offense to the designers) the SRP protocol design is completely bonkers, and earlier versions have been broken several times — which is why we’re now at revision 6a. Plus the “security proof” in the original research paper doesn’t really prove anything meaningful.
- SRP currently relies on integer (finite field) arithmetic, and for various reasons (see point 3 above) the construction is not obviously transferable to the elliptic curve setting. This requires more bandwidth and computation, and thus SRP can’t take advantage of the many efficiency improvements we’ve developed in settings like Curve25519.
- SRP is vulnerable to pre-computation attacks, due to the fact that it hands over the user’s “salt” to any attacker who can start an SRP session. This means I can ask a server for your salt, and build a dictionary of potential password hashes even before the server is compromised.
- Despite all these drawbacks, SRP is simple — and actually ships with working code. Plus there’s working code in OpenSSL that even integrates with TLS, which makes it relatively easy to adopt.
Out of all these points, the final one is almost certainly responsible for the (relatively) high degree of commercial success that SRP has seen when compared to other PAKE protocols. It’s not ideal, but it’s real. This is something for cryptographers to keep in mind.
OPAQUE: The PAKE of a new generation
When I started thinking about PAKEs a few months ago, I couldn’t help but notice that most of the existing work was kind of crummy. It either had weird problems like SRP, or it required the user to store the password (or an effective password) on the server, or it revealed the salt to an attacker — allowing pre-computation attacks.
Then earlier this year, Jarecki, Krawczyk and Xu proposed a new protocol called OPAQUE. Opaque has a number of extremely nice advantages:
- It can be implemented in any setting where Diffie-Hellman and discrete log (type) problems are hard. This means that, unlike SRP, it can be easily instantiated using efficient elliptic curves.
- Even better: OPAQUE does not reveal the salt to the attacker. It solves this problem by using an efficient “oblivious PRF” to combine the salt with the password, in a way that ensures the client does not learn the salt and the server does not learn the password.
- OPAQUE works with any password hashing function. Even better, since all the hashing work is done on the client, OPAQUE can actually take load off the server, freeing an online service up to use much strong security settings — for example, configuring scrypt with large RAM parameters.
- In terms of number of messages and exponentiations, OPAQUE is not much different from SRP. But since it can be implemented in more efficient settings, it’s likely to be a lot more efficient.
- Unlike SRP, OPAQUE has a reasonable security proof (in a very strong model).
There’s even an Internet Draft proposal for OPAQUE, which you can read here. Unfortunately, at this point I’m not aware of any production quality implementations of the code (if you know of one, please link to it in the comments and I’ll update). (Update: There are several potential implementations listed in the comments — I haven’t looked closely enough to endorse any, but this is great!) But that should soon change.
The full OPAQUE protocol is given a little bit further below. In the rest of this section I’m going to go into the weeds on how OPAQUE works.
Problem 1: Keeping the salt secret. As I mentioned above, the main problem with earlier PAKEs is the need to transmit the salt from a server to a (so far unauthenticated) client. This enables an attacker to run pre-computation attacks, where they can build an offline dictionary based on this salt.
The challenge here is that the salt is typically fed into a hash function (like scrypt) along with the password. Intuitively someone has to compute that function. If it’s the server, then the server needs to see the password — which defeats the whole purpose. If it’s the client, then the client needs the salt.
In theory one could get around this problem by computing the password hashing function using secure two-party computation (2PC). In practice, solutions like this are almost certainly not going to be efficient — most notably because password hashing functions are designed to be complex and time consuming, which will basically explode the complexity of any 2PC system.
OPAQUE gets around this with the following clever trick. They leave the password hash on the client’s side, but they don’t feed it the stored salt. Instead, they use a special two-party protocol called an oblivious PRF to calculate a second salt (call it salt2) so that the client can use salt2 in the hash function — but does not learn the original salt.
The basic idea of such a function is that the server and client can jointly compute a function PRF(salt, password), where the server knows “salt” and the client knows “password”. Only the client learns the output of this function. Neither party learns anything about the other party’s input.
The gory details:
The actual implementation of the oblivious PRF relies on the idea that the client has the password 



To compute this PRF requires a protocol between the client and server. In this protocol, the client first computes 

The server, which has a salt value s, now further exponentiates this calue to obtain 

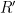
A nice feature of this protocol is that, if the client enters the wrong password into the protocol, she should obtain a value that is very different from the actual value she wants. This guarantee comes from the fact that the hash function is likely to produce wildly different outputs for distinct passwords.
Problem 2: Proving that the client got the right key K. Of course, at this point, the client has derived a key K, but the server has no idea what it is. Nor does the server know whether it’s the right key.
The solution OPAQUE uses based an old idea due to Gentry, Mackenzie and Ramzan. When the user first registers with the server, she generates a strong public and private key for a secure agreement protocol (like HMQV), and encrypts the resulting private key under K, along with the server’s public key. The resulting authenticated ciphertext (and the public key) is stored in the password database.
C = Encrypt(K, client secret key | server’s public key)

When the client wishes to authenticate using the OPAQUE protocol, the server sends it the stored ciphertext C. If the client entered the right password into the first phase, she can derive K, and now decrypt this ciphertext. Otherwise it’s useless. Using the embedded secret key, she can now run a standard authenticated key agreement protocol to complete the handshake. (The server verifies the clients’ inputs against its copy of the client’s public key, and the client does similarly.)
Putting it all together. All of these different steps can be merged together into a single protocol that has the same number of rounds as SRP. Leaving aside the key verification steps, it looks like the protocol above. Basically, just two messages: one from the client and one returned to the server.
The final aspect of the OPAQUE work is that it includes a strong security proof that shows the resulting protocol can be proven secure under the 1-more discrete logarithm assumption in the random oracle model, which is a (well, relatively) standard assumption that appears to hold in the settings we work with.
In conclusion
So in summary, we have this neat technology that could make the process of using passwords much easier, and could allow us to do it in a much more efficient way — with larger hashing parameters, and more work done by the client? Why isn’t this everywhere?
Maybe in the next few years it will be.

As somebody who maintained an implementation of SRP designed for the browser in the Meteor web framework (https://github.com/meteor/meteor/blob/devel/packages/srp/srp.js), the feedback we got from real crypto people (which led to us replacing it with password hashing) was that there was a more specific problem with doing SRP in the web context than doing “fancy crypto in the browser” — specifically, getting good randomness in the browser was hard, and that’s necessary for SRP in a way that it isn’t for password hashing. (Browsers may be better at randomness today than 5 years ago, though.)
I believe our original motivation to use SRP was that we didn’t trust that non-sophisticated users would all use TLS, so we wanted to give an out-of-the-box experience that was moderately secure even over HTTP. Of course, there were other problems here — the app’s source could would be downloaded over HTTP, and despite the use of SRP for initial login, the session tokens used for subsequent connections would let you take over an account if stolen over HTTP.
I believe this is already implemented in Chrome. (If you’re not using it, then what is wrong you?)
By “this”, you mean strong randomness? As alluded to above, this is code we wrote in 2012 and deprecated in 2014. Not sure that web randomness was pervasive enough to be a good idea in 2014. (And given that our motivation was “we want developers who aren’t sophisticated enough to use SSL to have some level of security”, we didn’t think “security that only is secure for apps whose user base was all on recent browsers” was great either.)
Just wait until Green censors Chrome in your comment, he definitely feels betrayed by his blind love for a privacy-loving closed-source piece of utter spyware!
Informative read. Did you forget to link Opaque’s internet draft proposal?
Fixed now. Thanks!
V4?? SRP-6a is over a decade old. We would have greater confidence in your analysis if you based it on the current 6a. — (Thanks! Big fan!)
“(The server verifies this with its copy of the client’s secret key.)”
Shouldn’t this be the server’s copy of the public key? The server having a copy of the client’s private key would seem to be worse than having a hash of the client’s password…
i have an implementation of OPAQUE for a few months already in libsphinx: https://github.com/stef/libsphinx/blob/master/src/opaque.c
@Matthew,
He has more mentions of secret key than private key so I think that’s a symmetric key obtained under a key pair used only at enrollment.
“and encrypts the resulting private key under K, along with” <<< perhaps means "secret"
> much more efficient way — with larger hashing parameters, and more work done by the client? Why isn’t this everywhere?
Is this going to be friendly for mobile clients?
OPAQUE RFC link is missing, probably it should be https://tools.ietf.org/html/draft-krawczyk-cfrg-opaque-00
The third paragraph reads “and then store only the hashed result”, but it should be “and then store only the hashed result and the salt” as the salt needs to be stored in plaintext alongside the password.
i have an implementation of OPAQUE for a few months already in libsphinx: https://github.com/stef/libsphinx/blob/master/src/opaque.c
Reply
Cool. Adding documentation in header files to each public function would make it a bit more usable tho. Right now it is a bit of a mess. 😉
Also ability to encrypt (and sign) essential state of Opaque_ServerSession on server and send to client as a opaque data to be send back (“encrypted cookie”), would make this into stateless algorithm on server, thus allow running on multiple servers easily.
Right now Opaque_ServerSession must be stored somewhere, either in memory on one server, or in some database / cache that can be accessed from multiple machines. And when doing so, you need to ensure security of stored ServerSession somehow.
thanks a lot for having a look Witold!
> Cool. Adding documentation in header files to each public function would make it a bit more usable tho. Right now it is a bit of a mess. 😉
good idea. will do so, thanks for this remark.
> Also ability to encrypt (and sign) essential state of Opaque_ServerSession on server and send to client as a opaque data to be send back (“encrypted cookie”), would make this into stateless algorithm on server, thus allow running on multiple servers easily.
that is a nice extension, i like this. however you might have noticed currently all serialization, storage and transmission of messages is deferred to the application using this – low-level – library. however it might make sense to provide a higher level API which hides all the unnecessary details and provides also services like what you propose, i’ll start working on that.
there is also some documentation about the OPAQUE API here: https://github.com/stef/libsphinx#opaque-api – would this be enough for the header file, or is this overkill?
Comments that WPA3 will use a PAKE:
https://www.schneier.com/blog/archives/2018/07/wpa3.html
J-PAKE?
As of salt, why not just simply encrypt salt using symmetric cipher with a key derived from user password?
That is server stores encrypted salt only and this encrypted salt is transmitted in clear text over unsecured channel to the user in the first stage of protocol? It would be setup during verifier setup as usual.
Then client does:
actual_salt = decrypt(encrypted_salt, someKDF(password))
where decrypt could be a single block AES-128 (i.e. no need to any cipher modes, and both encrypted_salt is always fixed length, lets say 128 bits) or Salsa20, and someKDF could be scrypt or Argon2-id with big parameters (~500ms of CPU computation and 500MB RAM of space usage).
If attacker tries to brute force passwords over encrypted salt, they will not be able to figure out which password is correct, because each password will generated some decrypted salt. And observing interactions between server and client will not allow to figure out which salt was used either.
That is worse than most PAKEs as that acts as an unsalted password hash. As you only do “someKDF(password)” once per password and use that to decrypt all the salts in the DB and do a fast check on each of those salts. Let’s say it’s this:
salt’ = decrypt(encryptedSalt, kdf(password))
key = pwKdf(password, salt’, costSettings)
sessionKey = pake(key)
* kdf() is a fast KDF like HKDF. pwKdf() is a slow password KDF like Argon2. encryptedSalt has no padding or MAC so you can’t just check if it is correct (eg single block ECB of random binary data).
This still works as if you gave the salt. You can just guess passwords and store their keys as a precomputational attack. Wrong passwords give you wrong keys and the correct password gives you the correct key.
Can you expand on why “precomputation attacks” are a problem here? Salts are not usually considered secret. The purpose of a salt is to require the attacker to brute force each password individually, which would still be the case here. An attacker who learns the salt still has an awful lot of work to do if the password hash parameters are well chosen.
It is not a big problem, but it is generally better to disclose less information than more.
The main issue is that with the PAKE, it is likely users will select weak passwords. Thus creation of rainbow tables by dictionary attack is a problem. Disclosure of salt, means that the attacker can precompute rainbow tables after observation of one client-server interaction, then do precomputations over few weeks time period. Then attempt to break server security, steal verifiers and if successful be able to use all precomputed hashes to recover original password in a matter of hours, if not less.
This is a problem, because SRP and OPAQUE subgoal is to prevent attacker obtaining verifiers from the compromised server to be able to recover original password easily or quickly. You can always brute force your way in once you have verifiers, but the brute force attack should be as high as possible for the attacker.
Sure the total amount of work is the same, in fact the precomputation attack might require more work, because you have no way to verify which precomputations are wasted and you can’t stop early after finding correct password. But the fact that you can do precomputation without detection, and then recover password almost immediately after server compromise, means you have larger usable time window where you can use recovered password for accessing other systems for example (if password is reused, or is just a part of larger authentication system).
Without cleartext salt, this work needs to be done after compromise of the server, and that allows for longer response, i.e. it could be detected with higher probability, humans can act on knowledge of server being compromised, etc. It can be difference between 1 hour response time and 1 week response time, and that is a huge thing.
The reason why websites won’t use PAKE isn’t merely complexity, it simply makes no sense in that setup. Intercepting cleartext passwords requires a way to MITM the connection or run code on the server itself. If you have that, you can also modify JavaScript code running on the login page. Even if that JavaScript code is normally doing PAKE, a malicious version could extract the cleartext password before it is hashed.
two things:
1/ it still makes sense insofar leaks of the user database still have very little value
2/ it depends on the implementation, if opaque is (re-)implemented (over-and-over again) in jscrypto (yuk!) then yes, but if opaque would be implemented in the browser or even better outside of the browser, then your scenario does not work.
1. No, the leaked database would still contain all the information required to test guesses. So how difficult it is to recover original passwords would still depend on the hashing function used. And here requiring a hash computation on the client side might even be counterproductive. While the server is a known figure as far as hash computations go and can be made pretty efficient, the client’s capabilities vary largely. In particular, websites that need to support mobile devices might be inclined to use a weaker hashing function to avoid noticeable delays for these users.
2. JavaScript is very much capable of doing crypto, particularly with WebCrypto around. But even if the browser would take over all of the calculations, the real issue is the password field being present on a compromised page. This can only be solved by making the browser display a trusted and unspoofable login prompt, sort of like it does that for HTTP auth (everybody *loves* those prompts, right?). And even that isn’t a complete solution, because a compromised server can always revert to a regular login page – very few people would suspect anything with this kind of change.
your answer to 1/ makes me suspect you do not quite understand how opaque works. since the server does not store anything related to the password, only a random salt and some encrypted keymaterial which is used in a DH-like setting generating a per-session shared secret which can only be decrypted on the client. so the leak of a user-db would leak you some salts and some encrypted blobs that decrypt to entropy and are useless without the client.
regarding 2/ i think we agree the state of browsers handling sensitive data is an unsolved problem. thus i recommended handling this outside the browser.
please disregard my references to the client. that of course is irrelevant and misleading here. sorry.
Your answer makes me suspect that you didn’t really think things through, despite creating an implementation. There is nothing special about the client. It doesn’t store any keys or salts, it has only one secret: the password. And that’s exactly what bruteforcing would attack. Whoever steals the database won’t have any issues emulating the client and testing their guesses for the password. What if this user’s password is “password1”? Let’s generate the client-side salt with this password, derive the key and try to decrypt the blob then. The server-side salt and the blob are in the database. If the decryption succeeded – bingo! Otherwise – repeat with another guess. The only part of the protocol slowing down this process is the hashing function. So absolutely no difference to the “cleartext password transmitted” scenario.
Regarding handling passwords outside the browser: are we still talking about web applications? If so, how do you expect this to work?
yeah, i’m sorry, i was ignoring dictionary password, in my context passwords are lot’s of high entropy chars, coming out of a password manager. of course nothing protects you if your password is weak and in a dictionary.
This is not about weak passwords, just generally any human-chosen password. That’s why the choice of hashing function matters. With an average entropy of 40 bits, hashing passwords with MD5 or SHA1 is only marginally better than leaving them in clear text. If scrypt or argon2 with proper parameters are used, only very weak passwords will be recovered.
Sure, password managers and randomly generated passwords are better, but as long as only a minority of the population is using them service providers cannot ignore this issue.
sphinx (as specified by krawczyk et al – same authors as opaque) combined with opaque gives you some very strong security guarantees, like no offline dictionary attacks and also no replay attacks. which is pretty cool, and goes way beyond simply hashing passwords.
furthermore with hash functions (be it md5 or argon2) you still generate some token that can be reused in replay attacks as in pass-the-hash or simply sniffing the password itself. with opaque the ephemeral keys also eliminate this.
This conversation is getting weird. I didn’t deny that OPAQUE has some appeal. I’m merely saying that it doesn’t offer any advantages in the specific scenario of web pages. Replay attacks? In order to replay something you would need to intercept that something first. Which most likely means that you could have manipulated the login page and simply stolen the password. No offline dictionary attacks? If I understood this correctly while skimming the description, this requires an additional hardware token. Of course having a hardware token allows you to go beyond simply hashing passwords. Pass-the-hash? Only if the hash were calculated on the client side, which it usually isn’t – because doing crypto on the client side is pointless in a web application.
PAKE removes possible operational problems in real-life large deployments, where multiple 3rd party infrastructure pieces are involved in the process and passwords could be passively logged either on purpose or by mistake (Twitter example). Imagine a large site that uses a chain like Cloudfare -> Some 3rd party Envoy Proxy -> microservice. Using a PAKE protocol no intermediary party has enough information to directly impersonate the user. Furthermore, using a PAKE + nonce + per-request HMAC signing (similar to AWS API request signing I guess), no intermediary party would be able to impersonate _requests_ from a user either.
I’ve written a more detailed blog post on the issues of using OPAQUE in web applications: https://palant.de/2018/10/25/should-your-next-web-based-login-form-avoid-sending-passwords-in-clear-text
Very nice writeup, thanks. I always rely on your writings to demystify the internals of cryptographic algorithms.
Is it only me or does someone else notice a similarity with U2F (the idea of the private key being stored at the server, and being handed to the client in an encrypted form that only the genuine client can decrypt and use in the next step?)
Why does OPAQUE require a prime order group? What prevents it to use a curve with a cofactor?