I learn about cryptographic vulnerabilities all the time, and they generally fill me with some combination of jealousy (“oh, why didn’t I think of that”) or else they impress me with the brilliance of their inventors. But there’s also another class of vulnerabilities: these are the ones that can’t possibly exist in important production software, because there’s no way anyone could still do that in 2025.
Today I want to talk about one of those ridiculous ones, something Microsoft calls “low tech, high-impact”. This vulnerability isn’t particularly new; in fact the worst part about it is that it’s had a name for over a decade, and it’s existed for longer than that. I’ll bet most Windows people already know this stuff, but I only happened to learn about it today, after seeing a letter from Senator Wyden to Microsoft, describing how this vulnerability was used in the May 2024 ransomware attack on the Ascension Health hospital system.
The vulnerability is called Kerberoasting, and TL;DR it relies on the fact that Microsoft’s Active Directory is very, very old. And also: RC4. If you don’t already know where I’m going with this, please read on.
A couple of updates: The folks on HN pointed out that I was using some incorrect terms in here (sorry!) and added some good notes, so I’m updating below. Also, Tim Medin, who discovered and named the attack, has a great post on it here.
What’s Kerberos, and what’s Active Directory?
Microsoft’s Active Directory (AD) is a many-tentacled octopus that controls access to almost every network that runs Windows machines. The system uses centralized authentication servers to determine who gets access to which network resources. If an employee’s computer needs to access some network Service (a file server, say), an Active Directory server authenticates the user and helps them get securely connected to the Service.
This means that AD is also the main barrier ensuring that attackers can’t extend their reach deeper into a corporate network. If an attacker somehow gets a toehold inside an enterprise (for example, because an employee clicks on a malicious Bing link), they should absolutely not be able to move laterally and take over critical network services. That’s because any such access would require the employee’s machine to have access to specialized accounts (called “Service accounts”) with privileges to fully control those machines. A well-managed network obviously won’t allow this. This means that AD is the “guardian” that stands between most companies and total disaster.
Unfortunately, Active Directory is a monster dragged from the depths of time. It uses the Kerberos protocol, which was first introduced in early 1989. A lot of things have happened since 1989! In fairness to Microsoft, Active Directory itself didn’t actually debut until about 1999; but (in less fairness), large portions of its legacy cryptography from that time period appear to still be supported in AD. This is very bad, because the cryptography is exceptionally terrible.
Let me get specific.
When you want to obtain access to some network resource (a “Service” in AD parlance), you first contact an AD server (called a KDC) to obtain a “ticket” that you can send to the Service to authenticate. This ticket is encrypted using a long-term Service “password” established at the KDC and the Service itself, and it’s handed to the user making the call.
Now, ideally, this Service password is not really a password at all: it’s actually a randomly-generated cryptographic key. Microsoft even has systems in place to generate and rotate these keys regularly. This means the encrypted ticket will be completely inscrutable to the user who receives it, even if they’re malicious. But occasionally network administrators will make mistakes, and one (apparently) somewhat common mistake is to set up a Service that’s connected to an ordinary user account, complete with a human-generated password.
Since human passwords probably are not cryptographically strong, the tickets encrypted using them are extremely vulnerable to cracking. This is very bad, since any random user — including our hypothetical laptop malware hacker — can now obtain a copy of such a ticket, and attempt to crack the Service’s password offline by trying many candidate passwords using a dictionary attack. The result of this is that the user learns an account password that lets them completely control that essential Service. And the result of that (with a few extra steps) is often ransomware.
Isn’t that cute?
That doesn’t actually seem very cute?
Of course, it’s not. It’s actually a terrible design that should have been done away with decades ago. We should not build systems where any random attacker who compromises a single employee laptop can ask for a message encrypted under a critical password! This basically invites offline cracking attacks, which do not need even to be executed on the compromised laptop — they can be exported out of the network to another location and performed using GPUs and other hardware.
There are a few things that can stop this attack in practice. As we noted above, if the account has a long enough (random!) password, then cracking it should be virtually impossible. Microsoft could prevent users from configuring services with weak human-generated passwords, but apparently they don’t — at least because this is something that’s happened many times (including at Ascension Health.)
So let’s say you did not use a strong cryptographic key as your Service’s password. Where are you?
Your best hope in this case is that the encrypted tickets are extremely challenging for an attacker to crack. That’s because at this point, the only thing preventing the attacker from accessing your Service is computing power. But — and this is a very weak “but” — computing power can still be a deterrent! In the “standard” authentication mode, tickets are encrypted with AES, using a key derived using 4,096 iterations of PBKDF2 hashing, based on the Service password and a per-account salt (Update: which is not truly random salt, it’s a combination of domain and principal name.) The salt means an attacker cannot easily pre-compute a dictionary of hashed passwords, and while the PBKDF2 (plus AES) isn’t an amazing defense, it puts some limits on the number of password guesses that can be attempted in a given unit of time.
This page by Chick3nman gives some excellent password cracking statistics computed using an RTX 5090. It implies that a hacker can try 6.8 million candidate passwords every second, using AES-128 and PBKDF2.
So that’s not great. But also not terrible, right?
This isn’t the end of the story. In fact it’s self-evident that this is not the end of the story, because Active Directory was invented in 1999, which means at some point we’ll have to deal with RC4.
Here’s the thing. Anytime you see cryptography born in the 1990s and yet using AES, you cannot be dealing with the original. What you’re looking at is the modernized, “upgraded” version of the original. The original probably used an abacus and witchcraft, or (failing that) at least some combination of unsalted hash functions and RC4. And here’s the worst part: it turns out that in Active Directory, when a user does not configure a Service account to use a more recent mode, then Kerberos will indeed fall back to RC4, combined with unsalted NT hashes (basically, one iteration of MD4.)
The main implication of using RC4 (and NT hashing) is that tickets encrypted this way become hilariously, absurdly fast to crack. According to our friend Chick3nman, the same RTX 5090 can attempt 4.18 billion (with a “b”) password guesses every second. That’s roughly 1000x faster than the AES variant.
As an aside, the NT hashes are not salted, which means they’re vulnerable to pre-computation attacks that involve rainbow tables. I had been meaning to write about rainbow tables recently on this blog, but had convinced myself that they mostly don’t matter, given that these ancient unsalted hash functions are going away. I guess maybe I spoke too soon? Update: see Tom Tervoort’s excellent comment below, which mentions that there is a random 8-byte “confounder” acting as a salt during key derivation.
So what is Microsoft doing about this?
Clearly not enough. These “Kerberoasting” attacks have been around for ages: the technique and name is credited to Tim Medin who presented it in 2014 (and many popular blogs followed up on it) but the vulnerabilities themselves are much older. The fact that there are practical ransomware attacks using these ideas in 2024 indicates that (1) system administrators aren’t hardening things enough, but more importantly, (2) Microsoft is still not turning off the unsafe options that make these attacks possible.

To give some sense of where we are, in October 2024, Microsoft published a blog post on how to avoid Kerberos-based attacks (NB: I cannot say Kerberoasting again and take myself seriously).
The recommendations are all kind of dismal. They recommend that administrators should use proper automated key assignment, and if they can’t do that, then to try to pick “really good long passwords”, and if they can’t do that, to pretty please shut off RC4. But Microsoft doesn’t seem to do anything proactive, like absolutely banning obsolete legacy stuff, or being completely obnoxious and forcing admins to upgrade their weird and bad legacy configurations. Instead this all seems much more like a reluctant and half-baked bit of vulnerability management.
I’m sure there are some reasons why this is, but I refuse to believe they’re good reasons, and Microsoft should probably try a lot harder to make sure these obsolete services go away. It isn’t 1999 anymore, and it isn’t even 2014.
If you don’t believe me on these points, go ask Ascension Health.
 PAKE is that this is a shame, because PAKE — which stands for
PAKE is that this is a shame, because PAKE — which stands for 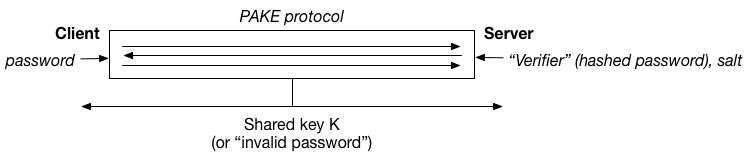
 and the server has the salt, which is expressed as a scalar value
and the server has the salt, which is expressed as a scalar value  . The output of the PRF function should be of the form
. The output of the PRF function should be of the form  , where
, where  is a special hash function that hashes passwords into elements of a cyclic (prime-order) group.
is a special hash function that hashes passwords into elements of a cyclic (prime-order) group. and then “blinds” this password by selecting a random scalar value r, and blinding the result to obtain
and then “blinds” this password by selecting a random scalar value r, and blinding the result to obtain  . At this point, the client can send the blinded value C over to the server, secure in the understanding that (in a prime-order group), the blinding by r hides all partial information about the underlying password.
. At this point, the client can send the blinded value C over to the server, secure in the understanding that (in a prime-order group), the blinding by r hides all partial information about the underlying password. and sends the result R back to the client. If we write this out in detail, the result can be expressed as $R = H(P)^{rs}$. The client now computes the inverse of its own blinding value r and exponentiates one more time as follows:
and sends the result R back to the client. If we write this out in detail, the result can be expressed as $R = H(P)^{rs}$. The client now computes the inverse of its own blinding value r and exponentiates one more time as follows:  . This element
. This element 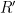 , which consists of the hash of the password exponentiated by the salt, is the output of the desired PRF function.
, which consists of the hash of the password exponentiated by the salt, is the output of the desired PRF function.