Yesterday Apple announced a big step towards deploying real AI in their Siri ecosystem. In most ways this is good and inevitable: Siri is one of the world’s most widely-used voice agents, and it would be good if it didn’t suck. The idea that Apple would boost its capabilities with frontier models wasn’t so much a matter of if, but a question of when and who.
The who turns out to be Google: Apple looks like it will use some combination of Google Gemini models, combined with Google’s Confidential Inference and Apple’s own Private Cloud Compute for private hosting. These systems will process both your queries and evaluate private data from your devices. Apple’s marketing pitches the advantages as follows:
- First, since your phone already has context about you — meaning, your private information, schedules, email, text messages — an AI-enabled Siri can potentially offer more useful answers to your practical requests than external LLMs. Want to schedule a reservation for next week’s birthday party? In theory, a future Siri-AI might already know who’s coming, and what kind of cake they like.
- Of course, what Apple calls “context” is also the raw data of your life. This is deeply private data from all of your apps, and that data can’t just be shipped to random adtech companies (or Sam Altman) for processing. Your context needs to be protected, and Apple bills itself as a privacy company.
There’s some tension between these goals. Apple has addressed this by marketing a service it calls Private Cloud Compute, or PCC. PCC was introduced in 2024 as a private model inference system that ran entirely on Apple Silicon, using a set of “trusted” hardware security modules running in Apple’s datacenters. The goal of this system is to ensure that your data never leaves Apple’s hardware: it’s encrypted from your phone to a dedicated server, and then it disappears once a response reaches your phone. The stateless design of PCC ensures (in theory) that your data doesn’t linger, and the design of the hardware prevents even Apple from seeing the inputs.
Apple has since “expanded” PCC to encompass Google’s hardware as well. I will confess that I find the details of the new “expanded” PCC just a bit vague. It sounds a lot like Apple is primarily going to rely on Google’s existing confidential compute (running in Google datacenters) to process this data, but they’re bolting on a new layer of technical security to control which models are actually running. In any case: security experts can argue about whether this is good enough to keep Cozy Bear away from your data. What I will grant is that it’s probably good enough to keep Google and Apple from accessing your stuff, which is what most people are worried about in the first place.
So why am I so nervous?
A brief scenario involving private agents
To illustrate how agents might work, it’s helpful to consider an example use case. Let’s imagine that you’re planning a business dinner for six people. This involves several subtasks:
- You need to juggle the participants’ schedules, know when they’re in town and available to meet.
- You need to choose the appropriate restaurant based on menu and location. This might depend on what you know about the participants’ preferences: Mike is wildly allergic to szechuan peppercorn, for example, which rules out quite a few options.
- With these time/cuisine/location constraints in place, you’ll need to search for a restaurant that actually has a table for six in the right place.
- Finally, you’ll need to book the reservation, mark your calendar, and alert your attendees.
In the past, this type of scheduling required a significant amount of human effort. The beauty of AI agents is that, in theory, this is exactly the sort of project that can be automated. The agent can first scan your recent conversations to answer the questions needed for steps (1) & (2), then it can conduct the searches described in step (3). With a nod from you, it can even author the calendar invites and text messages required to complete step (4).
So what’s the problem here?
The first and unsurprising observation is that being useful on these tasks requires your agent to have context, which means: relatively unrestricted access to your private data. You know about your invitees’ availability because they texted it to you. You know about Mike’s allergy because you’ve talked about it with him or jotted it down somewhere. (This could mean iMessages, email, contacts, or personal notes.) Re-entering all of this data into an agent would be annoying and time consuming and the whole point of an agent is to save you time. The winning personal assistant doesn’t win just because it’s smart: it wins because it “already knows” the things you need it to know, like a personal assistant who sits next to your desk.
Allow me to dig into the details just a bit deeper. The agent might scan your messages database to learn the parameters needed to schedule your dinner. Or, in a more token-efficient system, it might read your messages continuously and store a “memory” that distills useful facts that it might need later. Both can be functionally equivalent, but one produces an artifact that may be highly sensitive. And keep in mind that the set of facts that might be useful is very broad. For example, Mike’s allergy is one of those facts. But there are many others. For example, the private conversation you had where you discovered that Mike was having an affair is potentially another fact that could be stored or accessed by a system. Memory or not, this data will all be within the agent’s view, and you’ll have to hope that it knows which one to operate on.
With this data at its fingertips, your agent (which is really an LLM running on a server in a data center somewhere, combined with a bunch of local state and prompting) will need to perform inference over this data, either to summarize it, or to respond to the query itself. This is where Private Cloud Compute and Confidential Inference are designed to protect you. The purpose of these technologies is to ensure that this data, and any inference results, are restricted to you alone. The inputs and outputs should be wiped as soon as inference is done, and the only remaining copy of any of it should exist on your phone.
So far I find this to be a compelling story, as long as you never plan to do anything else beyond inference.
Private inference is nice, but to be useful, agents need to talk to things
An AI that performs only inference is like a human assistant that can read your private files, but is otherwise locked in a windowless room, with no Internet access and no outbound phone. Your data is perfectly safe, but your assistant is worthless for all but the simplest tasks: for example, summarizing inbound messages for your consumption, or helping draft text messages. (In short, what Apple Intelligence does today.)
Now imagine a personal assistant who can actually get things done. This assistant will need Internet access: at minimum the ability to query search engines, or in the future, search LLMs like Gemini or ChatGPT. To accomplish the later steps of our task, you’ll need it to schedule public calendar invites and draft messages to share with your contacts. This assistant is now useful, but the wonderful PCC guarantees of “no private data is accessible to others” are no longer so applicable. The privacy of your data no longer depends on the design of some silicon, but rather, on your assistant’s discretion and judgement.
Let’s move back to our hypothetical business dinner. To accomplish step (3) your agent will need to visit a search engine or non-private LLM, perhaps asking it several queries, each of which leaks some information about your specific requirements. The nature of the data leakage really depends on how cautious the “private” agent is in authoring its queries. A perfectly reasonable case would be for the model to simply collect a series of useful facts, and upload them all to a more powerful “open” search LLM like Gemini, ChatGPT or Claude, as follows:
“Hey, LLM search engine, here is a list of thirty detailed facts about my attendees and the purpose of this meeting, find me a restaurant that works for everyone.“
This would be an incredibly efficient (and somewhat natural) design, since the non-private LLM is most likely going to be more powerful and capable than the private one. Unfortunately, it will also reveal an absurd amount of information about your private data, including some that may not be strictly necessary to get it done. (Is Mike’s affair relevant to the seating chart?) Put differently: private inference can work perfectly, and yet valuable (monetizable) data can still flow outward to a public search engine or LLM, simply because the agent was programmed to do its job in a slightly non-privacy-preserving way.
Ok, so search engines may learn some private data. So what?
You probably don’t care very much if a search engine learns that Mike is allergic to Szechuan food. But there are things you really should care about. In security parlance, they both have to do with different adversaries.
Let’s begin with the most obvious “adversary”. Imagine you’re Mark Zuckerberg or Sundar Pichai, or whoever runs Apple’s advertising business. You have billions of users with piles of deeply useful data stored on their phones. This data is extremely valuable for targeted advertising, something that is about to become wildly more lucrative thanks to generative AI. At the same time, a big chunk of this data is inaccessible, simply because users don’t love the idea of you scanning their private conversations. And so while you might have access to some public data (like web browsing) you can’t read those years worth of intimate private conversations that many users store on their devices.
Now imagine deploying an agent to users’ phones. That agent will have access to all that data. It’ll have access to everything the user does. To do its job, it will literally need to divine each user’s preferences and then operationalize them into queries that will repeatedly hit your search engine or “search LLM”. Whoever operates this search engine will learn a vast amount of useful information about the users’ desires, some of which will come from the most intimate private conversations — even conversations that happened years ago, and that you’ve forgotten about. If the person who operates the search engine is also the person who designs the model and its prompting, then you really have a best-case scenario for data monetization. It’s hard for me to believe that the major tech CEOs are unaware of this.
If your agent can talk to people, then strangers may talk to it
Some folks will shrug at the threat of Google learning more about them. I don’t subscribe to this viewpoint, but I understand it. From the outside, at least, Google has been a reasonably good steward of users’ data. To my knowledge, there have been no major data breaches where our most intimate Google searches were dumped all over the Internet (in the style of AOL‘s search breach.) The company deserves a lot of credit for this.
So while I object to the idea that Google or Meta or Apple may learn even more about us from our private data, it’s at least possible that our most intimate secrets won’t be revealed to the entire world. But this does not mean your private data won’t become public: and that’s why we need to talk about a second adversary. This adversary isn’t a search engine that your agent talks to, it’s all the other people who will talk to your agent.
Simon Willison describes a condition that he calls the lethal trifecta. This occurs when you have a combination of (a) access to private data, (b) untrusted content an LLM must parse, and (c) the ability to send external communications. These together create the perfect storm for data-exfiltration attacks, where a remote attacker simply “tricks” the LLM by sending it instructions to ship out confidential data. Although LLM technology is getting better, it’s still quite common for even frontier LLMs to fall for simple prompt injection attacks in which a malicious user includes text (as part of a website or a piece of data) that causes your LLM to reveal things it should not. This problem is very much alive. Just today, OpenAI recently unveiled a “lockdown mode” feature, where ChatGPT is restricted from making web searches due to the risk that it might upload your sensitive documents.
Agents like the one Apple is building (whether they use confidential inference or not) are a nightmare case of the lethal trifecta. These systems will need to ingest a vast amount of data, much of which will come from highly untrustworthy sources: think incoming emails and text messages. They will have access to everything on your system, like your encrypted messages and documents. And, to be useful, they will need to handle all sorts of actions that have visible external effects, like scheduling calendar invites and sending text messages.
The result is that your private data isn’t just vulnerable to the person who controls the agent, it’s potentially vulnerable to anyone who can cause your agent to misbehave. This problem exists regardless of how well-designed the private inference engines are. And OpenAI’s recent example illustrates that it’s far from solved. It’s possible that we’ll be able to solve these problems technically, or through some careful element of human observation — read all your outbound calendar invitations carefully — but right now we have not.
Or let me put this differently: if you think spam directed at humans is bad, wait until it’s spam directed at agents.
Who does your agent really work for?
So far we’ve discussed two adversaries: the misaligned designers of private agents (such as search operators), and the possibility of remote prompt injection attacks. But of course, in any discussion of technical privacy systems we need to talk about the last elephant in the room: your government.
We live in a society, and that society has laws. If an agent has access to all of your data, messages and actions, then technically speaking it has the ability to detect criminal activity. That criminal activity might include sharing of CSAM, or terrorism-related activity, or it could include tax fraud or any other form of crime. These agents make a perfect one-stop shop for crime detection, since they can identify patterns of bad behavior and also report them.
Is this farfetched? Well, as I’m fond of repeating on this blog, this is more or less what existing rules published by the UK’s OFCOM require for encrypted messengers, and there have been proposals in the EU Commission to do similar things. The UK also maintains a vigorous regime of Technical Capability Notices (TCNs) that allow it to demand that providers make changes to their systems, changes that could potentially affect devices worldwide. Apple is in the midst of a battle with the UK over its other encrypted services.
Traditionally in the United States we’ve shied away from this sort of thing, partly because it’s creepy and mostly because it seems like a direct attack on the Fourth Amendment. With that said, the Fourth Amendment applies only to governments: in theory a private company like Apple or Google could configure their agents to report crimes to them, and then pass along the serious ones to the government. This is more or less what Apple proposed to do in 2021, when they designed a system to monitor photos for CSAM.
At the risk of saying more obvious things, the difference between a helpful private agent, a corporate advertising bot, and a government spy comes down mainly to a matter of prompting, and maybe a bit of model fine-tuning. Once you combine private data access and the ability to send messages, there is essentially no technical protection that private inference alone can offer.
So what does this have to do with cryptography?
For decades the point of cryptography has been to remove trust: to replace “I promise not to look” with “I can’t.”
Private inference is the most ambitious version of that promise. Against the adversary it was designed for — the provider who performs the inference itself — I believe that it probably does what it says. All I’m trying to say in this post is that this adversary is a very small piece of any agentic system.
The adversaries we care about are the ones that deal with the model directly, or even the ones who designed the model or specified its technical requirements. There is no cryptographic primitive that protects you from “upload your search facts to Google” or “report anything suspicious to the government because I programmed you that way.” That protection, if it exists at all, lives in law and politics and corporate incentives: the exact messy human institutions that cryptography was invented to let us stop trusting.



























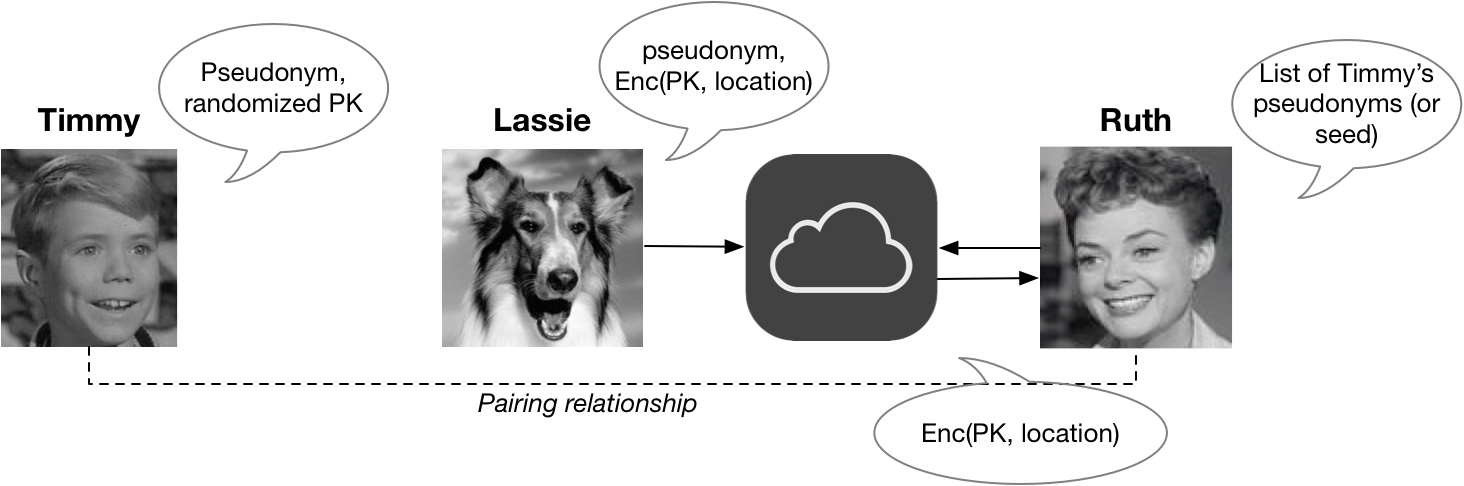
 (Since Timmy and Ruth have to be paired ahead of time, it’s likely they’ll both be devices owned by the same person. Did I mention that you’ll need to buy two Apple devices to make this system work? That’s also just fine for Apple.)
(Since Timmy and Ruth have to be paired ahead of time, it’s likely they’ll both be devices owned by the same person. Did I mention that you’ll need to buy two Apple devices to make this system work? That’s also just fine for Apple.)