
One of the things I like to do on this blog is write about new research that has a practical angle. Most of the time (I swear) this involves writing about other folks’ research: it’s not that often that I write about work that comes out of my own lab. Today I’m going make an exception to talk about a new paper that will be appearing at TCC ’22. This is joint work with my colleagues Abhishek Jain and Aarushi Goel along with our students Harry Eldridge and Max Zinkus.
This paper is fun for three reasons: (1) it addresses a cool problem, (2) writing about it gives me a chance to cover a bunch of useful, general background that fits the scope of this blog [indeed, our actual research won’t show up until late in the post!], and most critically (3) I want people to figure out how to do it better, since I think it would be neat to make these ideas more practical. (Note, if you will, that TCC stands for Theory of Cryptography conference, which is kind of a weird fit.)
Our work is about realizing a cryptographic primitive called the One-Time Program (OTP). This is a specific kind of cryptographically obfuscated computer program — that is, a program that is “encrypted” but that you can mail (literally) to someone who can run it on any untrusted computer, using input that the executing party provides. This ability to send “secure, unhackable” software to people is all by itself of a holy grail of cryptography, since it would solve so many problems both theoretical and practical. One-time programs extend these ideas with a specific property that is foreshadowed by the name: the executing computer can only run a OTP once.
OTPs are one of the cooler ideas to pop out of our field, since they facilitate so many useful things. Aside from the obvious dark-side implications (perfect DRM! scary malware!) they’re useful for many constructive applications. Want to send a file encrypted under a weak password, but ensure nobody can just brute-force the thing? Just send a OTP that checks the password and outputs the file. Want to send a pile of sensitive data and let users compute statistical functions over it using differential privacy? Sure. Time-lock encryption? Why not. In fact, OTPs are powerful enough that you can re-invent many basic forms of cryptography from them… provided you’re not too worried about how efficient any of it will be.
As we’ll see in a minute, OTPs might be nice, but they are perhaps a little bit too good to be true. Most critically they have a fundamental problem: building them requires strong model-breaking assumptions. Indeed, many realizations of OTPs require the program author to deliver some kind of secure hardware to the person who runs the program.* This hardware can be ridiculously simple and lightweight (much simpler than typical smartcards) but the need to have some of it represents a very big practical limitation. This is likely why we don’t have OTPs out in the world — the hardware required by scientists does not actually exist.
In this work we tried to answer a very similar question. Specifically: can we use real hardware (that already exists inside of phones and cloud services) to build One-Time Programs? That’s the motivation at a high level.
Now for the details… and boy are there a lot of them.
One-Time Programs
One-Time Programs (OTPs) were first proposed by Goldwasser, Kalai and Rothblum (GKR) back in CRYPTO 2008. At a surface level, the idea is quite simple. Let’s imagine that Alice has some (secret) computer program P that takes in some inputs, cogitates for a bit, and then produces an output. Alice wishes to mail a copy of P to her untrustworthy friend Bob who will then be able to run it. However Alice (and Bob) have a few very strict requirements:
- Bob can run the program on any input he wants, and he will get a correct output.
- Bob won’t learn anything about the program beyond what he learns from the output (except, perhaps, an upper-bound on its size/runtime.)
- Bob can run the program exactly once.
Let’s use a very specific example to demonstrate how these programs might work. Imagine that Alice wants to email Bob a document encrypted under a relatively weak password such as a 4-digit PIN. If Alice employed a traditional password-based encryption scheme, this would be a very bad idea! Bob (or anyone else who intercepts the message before it reaches Bob) could attempt to decrypt the document by systematically testing each of the (10,000) different passwords until one worked correctly.
Using a one-time program, however, Alice can write a program with code that looks like this, and turn it into an OTP:
Program P: takes an argument "password"
1. if password != "<secret password>",
output "BAD"
2. else output <secret document>

When Bob receives an OTP of the program above, he can then run it on some password input he chooses — even if Alice is no longer around to help him. More critically, because it’s a one-time program, Bob will only be able to try a single password guess. Assuming Bob knows the right password this is just fine. But a recipient who does not know the password will have to guess it correctly the first time. The nice implication is that even a “weak” 4-digit PIN reasonably to safe to use as a password.
(Of course if Alice is worried about Bob innocently fat-fingering his password, she can send him a few different copies of the same program. Put differently: one-time programs trivially imply N-time programs.)
One-time programs have many other useful applications. Once I can make “unhackable” limited-use software, I can send you all sorts of useful functionalities based on secret intellectual property or private data rather than keeping that stuff locked up on my own server. But before we can do those things, we need to actually build OTPs.
Why hardware?
If you spend a few minutes thinking about this problem, it should become obvious that we can’t build OTPs using (pure) software: at least not the kind of software that can run on any general-purpose computer.
The problem here stems from the “can only run once” requirement.
Imagine that you send me a pure software version of a (purported) One-Time Program. (By this I mean: a piece of software I can run on a standard computer, whether that’s a Macbook or a VM/emulator like QEMU.) I’m supposed to be able to run the program once on any input I’d like, and then obtain a valid output. The program is never supposed to let me run it a second time on a different input. But of course if I can run the software once that way, we run into the following obvious problem:
What stops me from subsequently wiping clean my machine (or checkpointing my VM) and then re-installing a fresh copy of the same software you sent—and running it a second time on a different input?
Sadly the answer is: nothing can prevent any of this. If you implement your purported “OTP” using (only) software then I can re-run your program as many times as I want, and each time the program will “believe” it’s running for the very first time. (In cryptography this is sometimes called a “reset attack”.)

For those who are familiar with multi-party computation (MPC), you’ll recognize that such attacks can be thwarted by requiring some interaction between the sender and recipient each time they want to run the program. What’s unique about OTPs is that they don’t require any further interaction once Alice has sent the program: OTPs work in a “fire and forget” model.
In their original paper, GKR noted this problem and proposed to get around it by changing the model. Since pure software (on a single machine) can’t possibly work, they proposed to tap the power of tamper-resistant hardware. In this approach, the program author Alice sends Bob a digital copy of the OTP along with a physical tamper-resistant hardware token (such as a USB-based mini-HSM). The little token would be stateful and act like one of those old copy-protection dongles from the 1990s: that is, it would contains cryptographic key material that the program needs in order to run. To run the program, Bob would simply pop this “hardware token” into his computer.

Now you might object: doesn’t using hardware make this whole idea kind of trivial? After all, if you’re sending someone a piece of specialized tamper-resistant hardware, why not just pop a general-purpose CPU into that thing and run the whole program on its CPU? Why use fancy cryptography in the first place?
The answer here has to do with what’s inside that token. Running general programs on tamper-proof hardware would require a token with a very powerful and expensive (not to mention complex) general-purpose CPU. This would be costly and worse, would embed a large attack software and hardware attack surface — something we have learned a lot about recently thanks to Intel’s SGX, which keeps getting broken by researchers. By contrast, the tokens GKR propose are absurdly weak and simple: they’re simple memory devices that spit out and erase secret keys when asked. The value of the cryptography here is that Bob’s (untrusted) computer can still do the overwhelming share of the actual computing work: the token merely provides the “icing” that makes the cake secure.
But while “absurdly weak and simple” might lower the hardware barrier to entry, this is not the same thing as having actual tokens exist. Indeed it’s worth noting that GKR proposed their ideas way back in 2008, it is now 2022 and nobody (to my knowledge) has ever built the necessary token hardware to deploy the in the world. (One could prototype such hardware using an open HSM platform, but how secure would that actually be — compared to a proper engineering effort by a major company like Apple, Google or Amazon?)
And yet One-Time Programs are neat. It would be useful to be able to write and run them on real devices! For many years I’ve run into problems that would melt away if we could deploy them easily on consumer devices. Wouldn’t it be great if we could build them using some hardware that already exists?
How to build a (GKR) One-Time Program
In order to explain the next part, it’s necessary to give an extremely brief overview of the GKR construction for One-Time Programs, and more specifically: their specialized tokens. This construction is based on garbled circuits and will make perfect sense if you’re already familiar with that technique. If not, it will require a little bit more explanation.
GKR’s idea is to rely on many individual tokens called One-Time Memories (OTM). An invidual OTM token works like this:
- When a program author (Alice) sets one up, she gets to install two different strings into it: let’s call them K0 and K1. She can then mail the token to Bob.
- When Bob receives the token and wants to use it, he can ask the token for either of the two strings (0/1). The token will hand Bob the desired string (either K0 or K1.)
- Once the token has given Bob the string he asked for, it permanently erases the other string.
The strings themselves need not be very long: 128 bits is ideal. To use these tokens for building One-Time Programs, Alice might need to set up a few hundred or a few thousand of these “tokens” (which can technically all be glommed together inside a single USB device) and send them to Bob.
Once you assume these tokens, the GKR style of building One-Time Programs is pretty straightforward if you’re a cryptographer. Summarized to someone who is familiar with garbled circuits: the basic idea is to take the classical Yao two-party computation (2PC) scheme and replace the (interactive) Oblivious Transfer portion by sending the evaluator a set of physical One-Time Memory tokens.
If that doesn’t work for you, a slightly more detailed explanation is as follows:
Alice first converts her program P into a boolean circuit, like the one below:
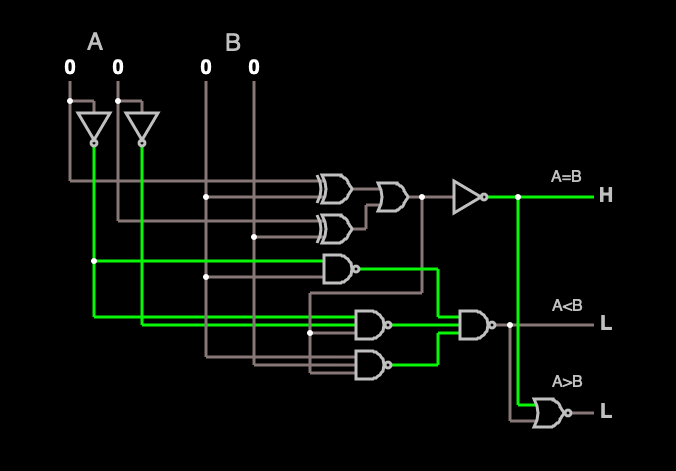
Having done that, she then assigns two random cryptographic keys (annoyingly called ‘labels’) to every single wire in the circuit. One key/label corresponds to the “0” value on that wire, and the other to the “1” bit. Notice that the input wires (top-left) also count here: they each get their own pair of keys (labels) that correspond to any input bit.
Alice next “garbles” the circuit (encrypting each gate) using a clever approached devised by Andrew Yao, which I won’t describe precisely here but Vitalik Buterin nicely explains it in this blog post. The result is that each table is replaced with an encrypted table of ciphertexts: anyone who has two of the appropriate labels going into that gate will be able to evaluate it, and in return they will receive the appropriate label for the gate’s output wire. Hence all Bob needs is the appropriate keys/labels for the value Bob wishes to feed into the input wires at the top-left of the circuit — and then he can then recursively evaluate the circuit all the way to the output wires.
From Bob’s perspective, therefore, all he needs to do is obtain the labels that correspond to the input arguments he wants to feed into the circuit. He will also need a way to translate the labels on the output wires into actual bits. (Alice can send Bob a lookup table to help him translate those labels into actual bits, or she can just make the circuit output raw binary values instead of labels on those wires.)
A critical warning is that Bob must receive only one input label for each wire: if he had more than that, he could run the circuit on two “different inputs.” (And in this case, many other bad things would probably happen.) Hence the high-level problem is how to deliver the appropriate input labels to Bob, while ensuring that he gets exactly one label for each wire and never more.
And this is where the One-Time Memory tokens fit in perfectly. Alice will set up exactly one OTM token for each input wire: it will contain both labels for that wire. She’ll send it to Bob. Bob can then query each token to obtain exactly one label for that wire, and then use those labels to evaluate the rest of the circuit. The OTM token will destroy all of the unused labels: this ensures that Bob can only run the program on exactly one input. And that’s the ballgame.**
So where do I pick myself up some One-Time Memories?
You buy them at your local One-Time Memory store, obviously.
Seriously, this is a huge flaw in the hardware-based OTP concept. It would be awfully useful to have OTPs for all sorts of applications, assuming we had a bunch of One-Time Memory tokens lying around and it was easy to ship them to people. It would be even more awesome if we didn’t need to ship them to people.
For example:
- Imagine there was a publicly-accessible cloud provider like Google or Apple that had lots of One-Time Memories sitting in your data center that you could rent. Alice could log in to Google and set up a bunch of OTM “tokens” remotely, and then simply send Bob the URLs to access them (and hence evaluate a OTP that Alice mails him.) As long as the cloud provider uses really good trusted hardware (for example, fancy HSMs) to implement these memories, then even the cloud provider can’t hack into the secrets of Alice’s One-Time Programs or run them without Bob’s input.
- Alternatively, imagine we had a bunch of One-Time Memories built into every smartphone. Alice couldn’t easily send these around to people, but she could generate One-Time Programs that she herself (or someone she sends the phone to) could later run. For example, if Alice could build a sophisticated biometric analysis program that uses inputs from the camera to unlock secrets in her app, and she could ensure that the program stays safe and can’t be “brute-forced” through repeated execution. Even if someone stole Alice’s phone, they would only be able to run the program (once) on some input, but they would never be able to run it twice.
The problem is that, of course, cloud providers and phone manufacturers are not incentivized to let users build arbitrary “unhackable” software, nor are they even thinking about esoteric things like One-Time Memories. No accounting for taste.
And yet cloud providers and manufacturers increasingly are giving consumers access to specialized APIs backed by secure hardware. For example, every single iPhone ships with a specialized security chip called the Secure Enclave Processor (SEP) that performs specific cryptographic operations. Not every Android phone has such processor, but most include a small set of built-in TrustZone “trustlets” — these employ processor virtualization to implement “secure” mini-apps. Cloud services like Google, Apple iCloud, Signal and WhatsApp have begun to deploy Hardware Security Modules (HSMs) in their data centers — these store encryption keys for consumers to use in data backup, and critically, are set up in such a way that even the providers can’t hack in and get the keys.
Unfortunately none of the APIs for these hardware services offer anything as powerful as One-Time Programs or (even) One-Time Memories. If anything, these services are locked down specifically to prevent people from doing cool stuff: Apple’s SEP supports a tiny number of crypto operations. TrustZone does support arbitrary computation, but today your applet must be digitally signed by a phone manufacturer or a TEE-developer like Qualcomm before you can touch it. Consumer-facing cloud providers definitely don’t expose such powerful functionality (for that you’d need something like AWS Nitro.) The same goes for “simple” functionalities like One-Time Memories: they may be “simple”, but they are also totally weird and why would any consumer manufacturer bother to support them?
But let’s never forget that cryptography is a sub-field of computer security. In that field when someone doesn’t let you run the machine you want to run, you figure out how to build it.
What hardware APIs do manufacturers and cloud providers support?
Not very many, unfortunately.

If you hunt around the Apple Developer Documentation for ways to use the iPhone SEP, for example, you’ll find APIs for generating public keys and using them, as well as ways to store keys under your passcode. Android (AOSP) provides similar features via the “Gatekeeper” and “Keymaster” trustlets. Consumer-facing cloud services provide HSM-backed services that also let you store your keys by encrypting them under a password.
None of this stuff is a “One-Time Memory,” unfortunately. Most of it isn’t even stateful… with one exception.
“Counter lockboxes”
Reading through documentation reveals one functionality that isn’t exactly what we need, but at least has some promise. In its documentation, Apple calls this function a “counter lockbox“, and it’s designed to store encryption keys that are protected with a user-selected password. The same person (or someone else) can later retrieve the key by sending in the right passcode. In the event that the entered passcode is not the right one, the lockbox increments an “attempt counter” that caps the number of incorrect guesses that will be permitted before the key is locked forever.
And I do mean forever. When the user exceeds the maximum number of guesses, something interesting happens (here is Apple’s version):

While I’m going to use Apple’s terminology, lockboxes are not just an Apple thing: a nearly-identical functionality exists inside every phone and in basically all of the consumer-facing cloud services I mentioned above.
Since counter lockboxes erase things, and they’re pretty much ubiquitous, this gives us hope. Even though they are not OTMs, maybe we can somehow use them to build OTMs. To explain how this works, we first need to give a clear description of how a basic a counter lockbox works. Here’s a simplified version:***
- To set up a fresh lockbox, Alice provides an encryption key K and a password P as well as a “maximum attempt counter” M. The initial attempt counter is set to A := 0. The token stores (K, P, A, M).
- When Bob wants to access the lockbox, he sends in a “guess” P’.
1. If P’ == P (i.e., the guess is correct), the token returns K and resets A := 0.
2. Else if P’ != P (the guess is incorrect), the token sets A := A + 1 and returns “bad password”. - If A == M (i.e., the maximum attempts have been reached) then the token wipes its memory completely.
If you remember our description of a one-time memory (OTM) further above, you’ll notice that a lockbox stores only one string (key), but that an OTM has two different strings stored in it. Moreover, the OTM will always give us one or the other string, but a counter lockbox only gives us its single string when we enter a password.
But perhaps we can simulate OTMs by using multiple lockboxes.
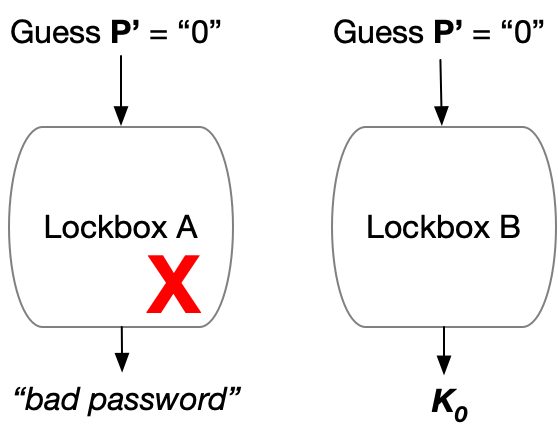
Imagine that Alice has access to two different (fresh) counter lockboxes, as illustrated below. Let’s assume she configures both lockboxes to permit exactly one password attempt (M=1). Next, she stores the string K0 into the lockbox on the left, and sets it up to use password “0”. She then places the string K1 into the lockbox on the right and set it up with password “1”, as follows:
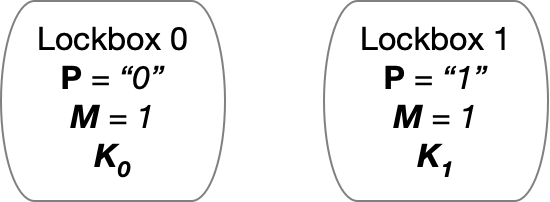
The picture above shows you what’s inside each lockbox. But you need to remember that to anyone other than Alice, lockboxes are kind of a black box. That is, they don’t reveal the key or password they’ve set up with — until the lockbox is queried on a specific password. To exploit this fact, Alice can shuffle the two lockboxes’ and send them to Bob in a random ordering. Until he tries to access one, these lockboxes will look like this to Bob:
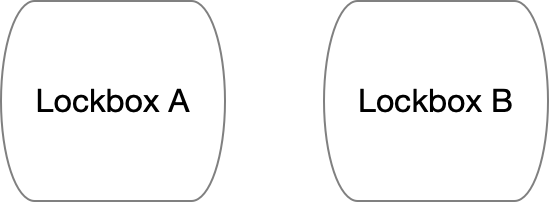
So how does Bob “open” the lockboxes to reliably obtain one of the two strings?
For a moment let’s assume that Bob is honest, and wants to get either K0 or K1. He does not know which of the two lockboxes contains the string he wants. He can, however, employ a simple strategy to obtain it.
Assuming Bob’s choice is “0”, he can simply query both lockboxes on password “0”. One of the two lockboxes will output K0, and the other will output “bad password”. (If his choice is “1”, then he can do the same using that as the password.) This strategy works perfectly. In either case Bob always obtains the string he wanted, and the other string ends up getting erased: just like a One-Time Memory!
The problem with this approach is that Bob might not be honest.
A cheating Bob can query the first lockbox on password “0”, and if that lockbox hands him K0, he can switch strategies and query the remaining lockbox on password “1”. If this works, he will end up with both of the strings — something that should never happen in a One-Time Memory. And this is very bad! Imagine we use such broken “memories” to build GKR one-time programs and Bob pulls this off for even a single input wire in our garbled circuit, then he will be able to query the circuit on multiple distinct inputs. (And it gets worse: if Bob obtains two labels on the same input wire, the garbled circuit construction will often unravel like a cheap sweater.)
The good news here is that Bob’s strategy doesn’t always work. He will sometimes get both strings, but sometimes he won’t. Half the time he’ll query the first lockbox on “0” and it will say “bad password”… and the key it holds will be gone forever. (Bob can still go on to get the other string from the untouched lockbox, but that’s not a problem.) This means we have at best a 1/2 probability of thwarting a cheating Bob. That’s good… but can we reduce Bob’s chances even more?
The most obvious approach is to use more lockboxes. Instead of two lockboxes, imagine Alice sets up, say, 80 different shuffled lockboxes divided into two sets. The first forty lockboxes can be programmed with the “0” password, and the other forty can be programmed with password “1”: then all will be mixed together. Our goal in this is to ensure that Bob will obtain K0 only if he guesses where all of the “0” lockboxes are. To ensure this, Alice will use secret sharing to split K0 into 40 different “shares”, with the property that all of the shares are needed to obtain the original string. Each share can be placed into one of the 40 boxes. (A similar process will be used to protect K1.)
Of course Bob can still cheat and try to guess his way through this maze Alice has built, but he will need to correctly guess where each of the “0”-password lockboxes are located without making a single mistake: since even a single wrong guess will doom his chances to get both strings. Such a lucky guessing strategy is extremely challenging for Bob to pull off. (The analysis is not quite equivalent to Bob flipping a coin “heads” forty times in a row [1/240] but it results in a probability that’s similarly low.)
By adjusting the number of lockboxes she uses, Alice can carefully tune the security level of each “virtual one-time memory” so that cheating (almost) never works.
This sure seems like a lot of lockboxes
Well, I said this paper is appearing in the Theory of cryptography conference, didn’t I?
Obviously the proposal above is not the end of the story. In that solution, for an desired S-bit security level the “naive” approach requires Alice to set up 2S lockboxes (or O(S) if you don’t like constants.) To build GKR one-time programs from this, Alice would need to use that O(S) lockboxes for every input bit Bob might want to feed into the program. Surely we can do better.
The rest of our paper looks at ways to reduce the number of lockboxes required, mainly focusing on the asymptotic case. Our second proposal reduces the number of lockboxes to about O(1) lockboxes for every input bit (when there are many input wires) and the final proposal removes the dependence on the number of input bits entirely. This means in principle we can run programs of arbitrary input length using some reasonable fixed number of lockboxes.
I can’t possibly do justice to the full details here, except to note that we rely on some very cool techniques proposed by others. Our first transform relies on a ‘robust garbling’ technique devised by Almashaqbeh, Benhamouda, Han, Jaroslawicz, Malkin, Nicita, Rabin, Shah and Tromer. The second uses an underappreciated tool called “Laconic OT” that was proposed by Cho, Dottling, Garg, Gupta, Miao and Polychroniadou. (Sadly, Laconic OT constructions are not quite “concretely” practical yet, so I hope these new applications will motivate some more practical research into that area.)
The upshot is that we can, in principle, manufacture programs that run on user inputs of arbitrary size with a fixed cost of at most several thousand lockboxes. While this is still quite a large number in practice(!), it isn’t not infeasible. Such a quantity of lockboxes could be obtained by, for example, setting up boatloads of fake iCloud or Google accounts and then using Apple’s iCloud Key Vault or Google’s Titan Backup service to store a “backup key” for each of them.
(I do not recommend you actually do any of this: I suspect both Apple and Google find such things irritating, and will make your life unpleasant if you try it.)
Are there any downsides to this research?
Maybe. There are many applications of obfuscated programs (including one-time programs) that are extremely bad for the world. One of those applications is the ability to build extremely gnarly ransomware and malware. This is presumably one of the reasons that systems like TrustZone and Intel SGX require developers to possess a certificate in order to author code that can run in those environments.
For example: a ransomware author could encrypt a whole system and the store the keys inside of a One-Time Program that would, in turn, need to be executed on a valid chunk of a blockchain in order to release the keys. This blockchain would then incorporate a fragment that proves that the system owner has paid some sum of money to the malware developer. This system would be fully ‘autonomous’ in the sense that your computer, once infected, would never need to phone home to any “command and control” infrastructure operated by the ransomware author. This would make malware networks harder to take down.
If systems designers are worried about malware on SGX, our research shows that (eventually) those designers may also need to think about the availability of “lockbox”-type functionalities as well. Or to give a shorter summary: don’t let the bad guys get more than a few thousand lockboxes, or they gain the power of secure computation and all that comes with it. And the exact number they need could be much smaller than the results we achieve in this paper.
Perhaps at a higher level, the main lesson of this research is that computation is much easier than you’d expect it to be. If someone wants to do it badly enough, they’ll always find a way.
Notes:
* There is a second line of work that uses very powerful cryptographic assumptions and blockchains to build such programs. I am very enthusiastic about this work [and my co-authors and I have also written about this], but this post is going to ignore those ideas and stick with the hardware approach.
** Of course that’s not really the ballgame. As with all simple descriptions of complex protocol papers, this simple explanation omits all the subtle details that matter for the security proof, but that aren’t terribly relevant for the purposes of this blog. These include all sorts of interesting questions about how to prove security in an environment where an adversary can query the tokens in a weird, arbitrary order. It’s a good paper!
*** Some implementations will pick the key K for you. Others fix the maximum attempt counter at some constant (usually 10 attempts) rather than supporting any amount. All of these details can be worked around in practice.




