A few weeks back, the messaging service WhatsApp sued the Indian government over new legislation that could undermine its end-to-end encryption (E2EE) software. The legislation requires, among other things, that social media and messaging companies must include the ability to “trace” the source of harmful viral content.
This tracing capability has been a major issue in India due to several cases of misinformation content that led to brutal mob attacks. The ostensible goal of the new legislation is to make it possible for police to track down those who originate or disseminate this content. Put simply, what the authorities say they want is a means to identify a piece of content (for example, a video or a meme) that has gone to a large group of people, and then trace the content back to the WhatsApp account that originally sent it.
I don’t plain to weigh in on whether this policy is a good idea or viable on the merits, nor is it in my wheelhouse to say whether the Indian government is being forthright in their reasons for demanding this capability. (I will express a very grave degree of skepticism that this approach will catch any criminal who is remotely malicious and takes steps to cover their tracks.) In this post I mostly want to talk about the technology implications for encrypted messaging services, and what tracing features might mean for end-to-end encrypted systems like WhatsApp.
Why is content tracing hard in the first place?
A first thing to keep in mind is that content tracing is not really a natural feature for messaging system. That is, tracing content poses a challenge even for completely unencrypted messaging apps: the kind where service providers can see all data traveling through the system. Tracing back to a content originator requires that the provider must be able to identify a file received at some end-user’s account, and then “chase” the content backwards through time through each user account that forwarded it. Even this description doesn’t quite respect the difficulty of the problem: not every user literally hits a “forward” button to send content onward. Many will save and re-upload a file, which breaks the forwarding chain and can even produce a slightly different file — thanks to the magic of digital compression.
These problems aren’t intractable. In a system with no end-to-end encryption, they could perhaps be solved using perceptual hash functions that identify similar media files by constructing a “fingerprint” of each file that can easily be compared against other files, and can survive re-encoding or minor edits. (This is the same technology that’s used in detecting child sexual abuse imagery, something I wrote about here.) What’s important is that even with this technology, the obvious approach to content tracing requires the provider to have plaintext access to (at least the hashes of) user content.
This turns out to be a big problem for encrypted communication systems like WhatsApp, in which end-to-end encryption protects the confidentiality of content even from the gaze of the service provider. In WhatsApp, all messages (as well as file attachments) are encrypted directly from sender to recipient, using an encryption key that WhatsApp doesn’t possess. With a few engineering caveats,* tracing content in these systems is very difficult.
But difficult is not the same thing as impossible. A recent post by WhatsApp makes the case that tracing is fundamentally impossible to implement securely in an end-to-end encrypted system. While this claim seems intuitively correct, it’s also kind of unsatisfying. After all, “impossible” is a strong word, and it’s highly dependent on which assumptions you’re making. The problem with imprecise claims is that they invite arguments — and indeed WhatsApp’s claim has has already been disputed by some in the field.
In this post I’m going to consider the following simple question: is traceability in end-to-end encrypted systems actually possible? And if so, what are the costs to privacy and security? For the record: I’m writing this post as much to answer the question for myself as to answer it for anyone else, so don’t expect this to be short or simple. I’m working things out as I go along.
Let’s start with the most basic question.
What is “traceability” in an end-to-end encrypted system?
The biggest problem with the debate over content tracing is that nobody seems to have a terribly rigorous definition of what, precisely an end-to-end encrypted tracing scheme is supposed to do — or more precisely, what its limits will be. To understand whether these systems can be built, we need to think hard about what they’re supposed to do in the first place.
From the perspective of law enforcement, content tracing is a simple feature. A piece of “viral” content (say an image file) has been widely distributed through a messaging platform, and authorities have decided that this content is harmful. Since the content is widespread, we can assume that police have received a copy of the file at an account they control (e.g., their own accounts, or the account of a cooperating user.) The authorities wish to contact the service provider and ask them for the originator and/or major spreaders of the content. This gives us our first requirement:
- Traceability: given a piece of “viral” content received by a device/account (plus any cryptographic keys at the device), a tracing scheme should be able to reliably trace the content back to the originator (or at least, earlier) accounts.
From the user’s side, E2EE systems are supposed to maintain the confidentiality of user communications. Confidentiality is a broad term and can mean a lot of things. In this case it has two specific flavors that are relevant, with names that I just made up now:

- The confidentiality of the content itself: this ensures that forwarded files are known only to the sender and authorized recipients(s) of a conversation. Notice that for viral content, this property isn’t terribly important. Remember: our assumption is that the content itself has ultimately been forwarded widely, until (nearly) everyone has received a copy.
- The confidentiality of “who sent what”: while the content itself may not be secret, the fact that a given user transmitted a piece of content is still quite sensitive. If I send you a political meme — perhaps the one at right, poking fun at the King of Sweden — then I might not care very much about the secrecy of the meme itself. But I sure might want to hide the fact that I sent it, to avoid retribution by a totalitarian Swedish government.** Proper end-to-end encryption is supposed to protect this sort of expression.
In short: traceability can really screw with the “who sent what” side of content confidentiality. It is a fairly harmless thing for, say, the tyrannical Swedish government to learn that specific memes about the King of Sweden exist. It is very different for them to know that I’ve been sending a lot of them to a specific group of friends.
Finally I need to clarify one more thing, since discussions with colleagues have made me realize that it is not obvious. Information revealed about “who sent what” in an E2E system is not the same as metadata. I feel stupid having to point this out, but metadata (information about data that we can’t easily hide from providers, such as the list of contacts you’ve communicated with) is a very different thing. WhatsApp might inevitably learn that I texted 500 people last month because they delivered my (encrypted) messages. They still shouldn’t learn that any of my messages are making fun of the Swedish monarchy.
So can traceability be accomplished without breaking E2E?
It really depends what you mean by “traceability” and what you mean by “breaking.”
While confidentiality and traceability may seem like they’re in conflict, it’s important to point out that some forms of tracing can be implemented in a non-coercive way that does not inherently violate confidentiality. For example, imagine Alice originates a meme, and this meme subsequently makes its way to police officer Eve via the following forwarding path:
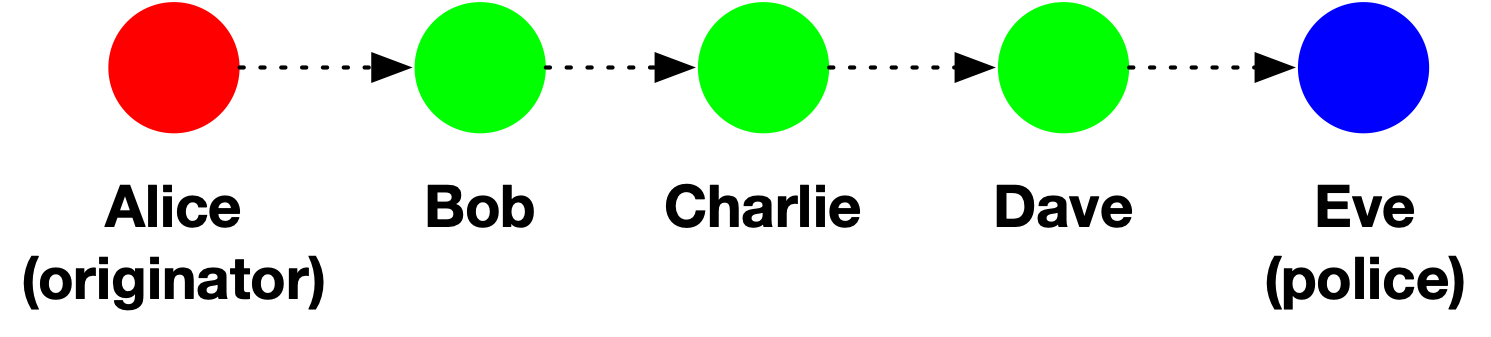
Provided that Bob, Charlie and Dave are willing to cooperate with the police, then Eve can use shoe-leather detective work to trace the content backwards towards Alice. After all: each participant (1) is an authorized recipient of the data and (2) knows who they received the content from. Nobody is “breaking” E2E if they perform this sort of cooperative tracing: it’s just people sharing information they’re already entitled to have.
It’s now time to say a stupid and obvious thing: what’s being proposed in India is not cooperative tracing.
Let’s be clear: if detective work and cooperation was sufficient to trace the originators of harmful content, the police wouldn’t be asking for new encryption laws, and WhatsApp wouldn’t be suing the Indian government.
By passing these laws, police are tacitly admitting that voluntary content tracing is not sufficient to met their investigative needs. This implies that when police try to follow a chain like the one shown above, they’re running into people who are either (1) unwilling to share this information in a timely way, or (2) simply don’t have the information anymore — maybe because they deleted the messages or lost their phone.
Let’s draw a picture of this situation. Below, each node represents a WhatsApp account, with the red node being the originator of some viral content, and the blue node representing police. Green nodes represent users who are willing to cooperate with the police, provided they are contacted. Here the gray nodes are users who won’t cooperate — either because they didn’t keep the information, or maybe because they just don’t like police.
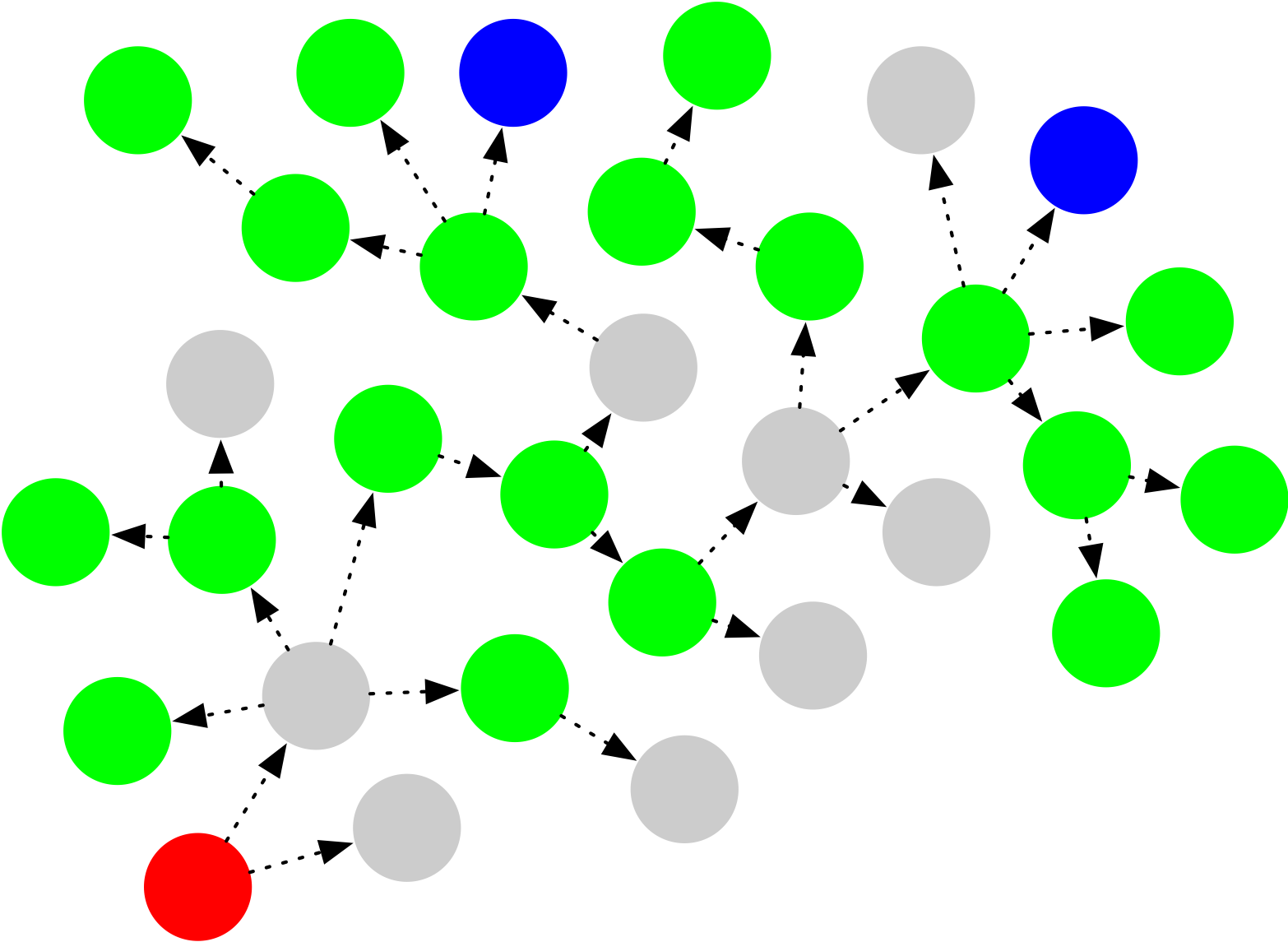
The prevalance of uncooperative nodes in the above graph makes it virtually impossible for cooperative tracing to find the originator. It seems obvious that real-world situations like this will make voluntary tracing very difficult to achieve.
This brings us to the central challenge of all content tracing proposals so far: to make tracing possible, a tracing system needs to turn every WhatsApp user (including the originator) into a cooperative green circle — regardless of whether users actually want to cooperate with police. Moreover, to prevent users from losing their phones and/or going offline, the system will need to force users to place the necessary tracing information into escrow as soon as they receive content, so it will remain available even if users leave the network or lose their phones.
Not only that, but each of these newly “cooperative” users might even be forced to admit to police that they also forwarded the content. Don’t want to tell the Swedish government that you made fun of their beloved King? Then you’d better not use a system that follows this pattern of enforced traceability.
How do we force users to cooperate?
The major questions facing an end-to-end tracing system are twofold: (1) precisely how much information are recipients going to be forced to reveal against their will, and (2) who will be able to access this information?
There are at least two proposals that I’ve seen for adding traceability to E2EE communications schemes, and both start from similar assumptions. They both rely on making changes to the end-users’ client software to ensure that tracing information is stored in “escrow” at the provider every time content is sent from one user to another.
One proposal is academic, and it takes something like the following “strawman” approach:
- Each time someone sends content to another user, they will generate some fresh encryption key K.
- They will use this key to encrypt a record that contains (A) the content (or a hash of it) and (B) the sender and receiver identities. They will store the encrypted record on WhatsApp’s servers as a kind of “key escrow.” Critically, at this point they will not send WhatsApp the key K.
- The sender will transmit the record encryption key K to its recipient, using end-to-end encryption.
- When the next user forwards the same content on to another user, it will repeat steps (1-4) and it will also send all the keys generated by previous users.
Now if the police receive a copy of some viral content on an account they control, they will have a list of encryption keys that correspond to everyone in the forwarding chain for that content. They can just go back to WhatsApp with a subpoena, obtain the encrypted records, and use the chain of keys to decrypt them. This will reveal the entire forwarding path back to the originator.
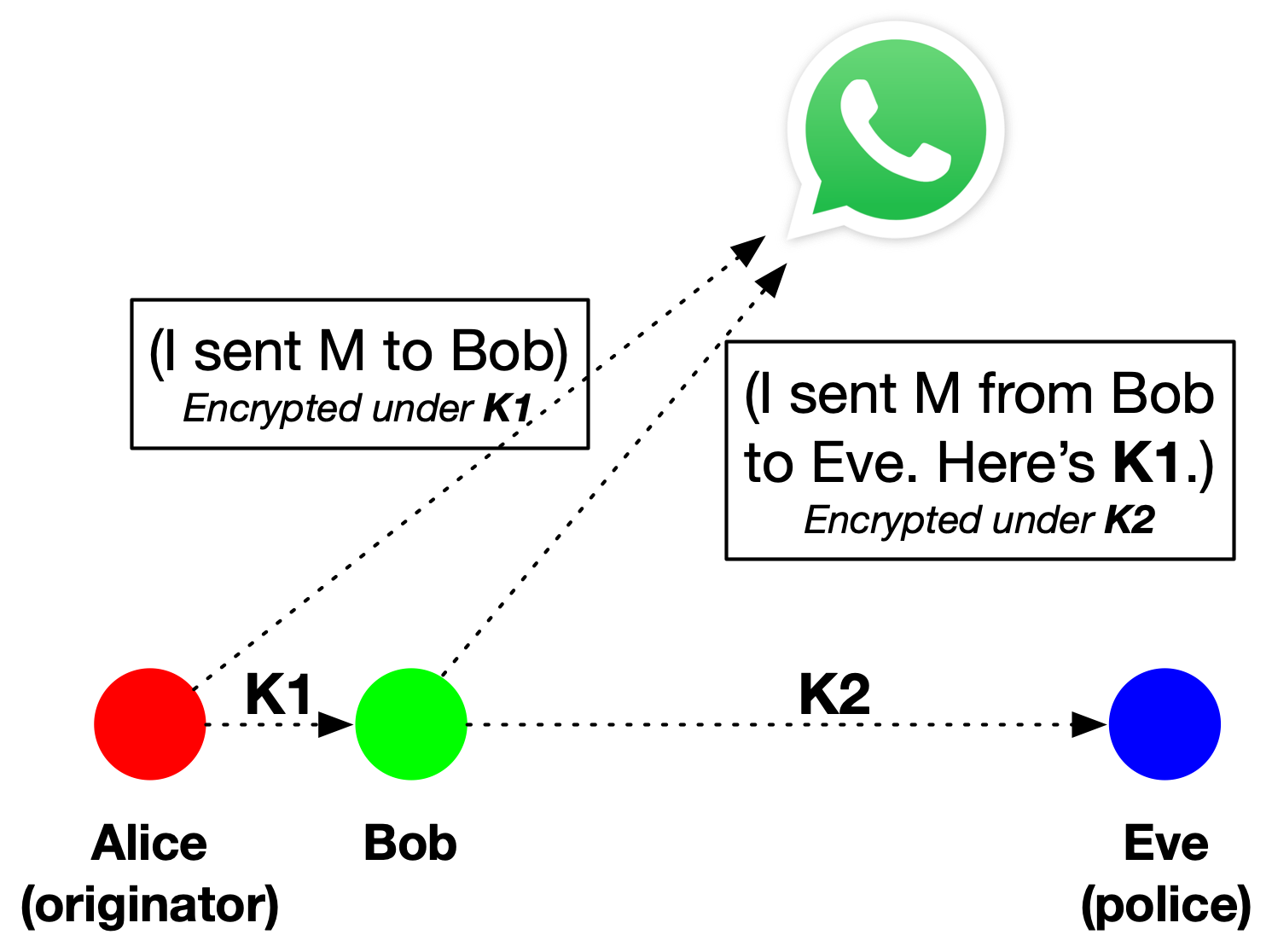
Of course sending thousands of keys along with each forwarded message is kind of a drag, so there are some efficiency optimizations one can use to compress this information. For example, each time a user forwards a message they can store the previous user’s encryption key inside the encrypted record they escrow with WhatsApp. That means if police get one key — corresponding to the last record in a chain — they can decrypt the escrow record, and then they will obtain the key for the previous record in the chain. They can repeat this process until the entire forwarding chain is “unzipped”.
A lazy diagram (at right) shows how this process might work with three participants. Essentially the whole thing is a form of key escrow, with WhatsApp acting as the escrow authority. If the police get included in any chain at all, they (Eve in this diagram) can subpoena WhatsApp to trace the chain back to originator.
Of course, this is a very simple strawman explanation of the ideas: for a more fully-specified (academic) proposal, you can see this paper by Tyagi, Miers and Ristenpart. Not only does it support path traceback, but it also lets you figure out who else the message was forwarded to! The cryptography is a bit more optimized, but the security guarantees are roughly the same.
A second proposal by Dr V. Kamakoti of IIT Madras is far simpler: it essentially requires each person who originates new content into the network (as opposed to forwarding it) to attach a “watermark” to the content that identifies the account ID of the sender. This also assumes a trustworthy WhatsApp client, of course. Presumably that watermark could be encrypted using a key stored at WhatsApp, so this tracing will at least require the provider’s involvement.
Ok, so what’s wrong with these traceability proposals?
Well if you’re ok with the fact that police can determine the identity of every single person who forwarded a piece of viral content regardless of whether they’re not the originator of that content then, I guess, nothing.
That’s the essence of what the Tyagi, Miers and Ristenpart proposal offers, and frankly I’m not particularly ok with it. Even if I accepted the logic that we should have the means to trace “content originators” — the actual justification governments have offered for building systems like this one — I surely would not want to reveal every random user account that happened to forward the content. That seems like a recipe for persecuting innocent people.
Moreover, regardless of whether the system finds “content originators” or just “everyone on the forwarding path”, I think these ideas are pretty much synonymous with mass surveillance — and certainly they buttress WhatsApp’s technical claim that “traceability” breaks end-to-end encryption.
But I want to go just a little farther, and point out that these ideas have a major weakness that makes the entire approach feel confused.
The approaches I describe above rely on a critical assumption: that all participants in the system are going to behave honestly — that is, everyone will run the official WhatsApp client, which will contain logic designed to store an escrow record on WhatsApp’s servers. Nobody in this system will try to bypass this system by running an unofficial client, or by hacking their client to disable the escrow logic.
If you’re willing to make such a strong assumption, why bother with the complicated Tyagi, Miers and Ristenpart proposal? Why not just use the Kamakoti proposal: modify your WhatsApp client to add a small “watermark” to each fresh non-forwarded media file. After all: once you’ve assumed that everyone is running an honest client, you can assume that the content originator will be too — can’t you? This approach would still reveal a lot of information to police, but it wouldn’t reveal the identity of every random person who forwarded the content.
My guess is that Tyagi, Miers and Ristenpart have an answer to this that boils down to something like “maybe you can’t trust the originator to run the correct client, but loads of other people will be running it.” To me this invites a much more detailed discussion about what security assumptions you’re making, and how “bad” the bad guys really are.
One last note to academic authors: don’t help bad people build unrestricted surveillance systems and then punt “preventing abuse” to later papers, ok?
If you read this far to answer the (rarified) question of how traceability could work and whether it breaks E2E encryption, then you can stop here. The rest of this post is not about that. It’s just me alienating a whole bunch of my academic peers.
Here is what I want to say to them.
The debate around key escrow and law enforcement surveillance is a very hard one. People have a lot of opinions about whether this work is “helping the good guys” or “helping the bad guys”, i.e., whether it’s about helping police find criminals, or whether it’s going to build the infrastructure for authoritarianism and spying. I don’t know the answer to this. I suppose the answer depends to some extent on the integrity of the government(s) that are implementing them. I have opinions, but I don’t expect all of my colleagues to share them.

What I would ask my colleagues to think hard about is the following:
When you propose (or review a paper that proposes) a new “lawful access” system, is it solving the hard problems, or is it punting on the hard problems and solving only the easy ones?
Because at the end of the day, building systems that violate the confidentiality of E2E encryption is a relatively easy problem from a scientific perspective. We’ve known how to build key escrow systems from the earliest days of encryption. Building these systems is not interesting, scientifically. It is useful from an engineering perspective, of course — to parties who want to deploy such systems. When respected academics write such papers, it is also politically useful to those same parties.
What is scientifically interesting is whether we can build systems that actually prevent abuse, either by governments that misuse the technology or by criminals who steal keys. We don’t really know to do that very well right now. This is the actual scientific problem of designing law enforcement access systems — not the “access” part, which is relatively easy and mostly consists of engineering. In short, the scientific problem is figuring out how to prevent the wrong type of access.
When I read a paper that builds a sophisticated surveillance system, I expect it to address those abuse problems in a meaningful way. If the paper punts the important problems to subsequent work — if what I get is a paragraph like the one at right — my thinking is that you aren’t solving the right problem. You’re just laying the engineering groundwork for a world I don’t want my kids to live in. I would politely ask you all to stop doing that.
Notes:
* Some messaging systems implement attachment forwarding by passing a pointer to an existing file that is stored on their servers. This is a nice storage optimization, since it avoids the need to make and store a full duplicate copy of each object whenever the user hits “forward”. The downside of this approach is that it makes tracing relatively easy for providers, since they can see exactly which users accessed a given file. Such optimizations are inimical to private systems and really should be avoided.
** All claims about the Swedish government are fictionalized.

The problem they are trying to solve, thus trying to justify the need for this traceability, is the spread of this harmful information. If it didn’t propagate, there wouldn’t be an issue. They didn’t ask ‘why’ enough times, they didn’t drill down to what they wanted to achieve instead they stopped at what they wanted to prohibit, yes?
The far bigger problem in the dissemination of the information, I think, is that it is the business model of the social media companies to spread engagement. This is antithetical to self moderation of harmful content and will have the same consequences as letting the oil companies do their own safety inspections.
I think we are a lot closer to a society that will abuse this type of authority than we are to a society that will only use it to protect the innocent. Honestly, I think it could be argued that the people that get spun up so easily by what I consider ludicrously obviously BS that I can’t accept they are completely innocent. They must really WANT to believe. People like that get bit by snakes, and then blame the devil.
hello I’m a $RANDOM reader,
what about server-side timestamps plus hash functions? Even if some malignant users modify and reupload that particular image, human users require few seconds to share content (and they usually do it at the same times of the day, during pauses, being creatures of habit). That could help narrow down investigations to Bobs, as only a fraction of users upload similar images at any given time. We can correlate things from there. No username is actually given to the police, but it implies that WhatsApp would store everything, which it already does. Having contact lists would help further. But I feel like I’m missing something. What am I doing wrong?
Cool blog anyway