This continues the post from Part 1. Note that this is a work in progress, and may have some bugs in it 🙂 I’ll try to patch them up as I go along.
In the previous post I discussed the problem of building CCA-secure public key encryption. Here’s a quick summary of what we discussed in the first part:
- We covered the definition of CCA2 security.
- We described how you can easily achieve this notion in the symmetric encryption setting using a CPA-secure encryption scheme, plus a secure MAC.
- We talked about why this same approach doesn’t work for standard public-key encryption.
In this post I’m going to discuss a few different techniques that actually do provide CCA security for public key encryption. We’ll be covering these in no particular order.
A quick note on security proofs. There are obviously a lot of different ways you could try to hack together a CCA2 secure scheme out of different components. Some of those might be secure, or they might not be. In general, the key difference between a “secure” and “maybe secure” scheme is the fact that we can construct some kind of security proof for it.
The phrase “some kind” will turn out to be an important caveat, because these proofs might require a modest amount of cheating.
The bad and the ugly
Before we get to the constructive details, it’s worth talking a bit about some ideas that don’t work to achieve CCA security. The most obvious place to start is with some of the early RSA padding schemes, particularly the PKCS#1v1.5 padding standard.
PKCS#1 padding was developed in the 1980s, when it was obvious that public key encryption was going to become widely deployed. It was intended as a pre-processing stage for messages that were going to be encrypted using an RSA public key.
This padding scheme had two features. First, it added randomness to the message prior to encrypting it. This was designed to defeat the simple ciphertext guessing attacks that come from deterministic encryption schemes like RSA. It can be easily shown that randomized encryption is absolutely necessary for any IND-CPA (and implicitly, IND-CCA) secure public key encryption scheme. Second, the padding added some “check” bytes that were intended to help detect mangled ciphertexts after decryption; this was designed (presumably) to shore the scheme up against invalid decryption attempts.
PKCS#1v1.5 is still widely used in protocols, including all versions of TLS prior to TLS 1.3. The diagram below shows what the padding scheme looks like when used in TLS with a 2048-bit RSA key. The section labeled “48 bytes PMS” (pre-master secret) in this example represents the plaintext being encrypted. The 205 “non-zero padding” consists of purely random bytes that exclude the byte “0”, because that value is reserved to indicate the end of the padding section and the beginning of the plaintext.

After using the RSA secret key to recover the padded message, the decryptor is supposed to parse the message and verify that the first two bytes (“00 02”) and the boundary “00” byte are all correct and in not violating any rules. The decryptor may optionally conduct other checks like verifying the length and structure of the plaintext, in case that’s known in advance.
One of the most immediate observations about PKCS#1v1.5 is that the designers kind of intuitively understood that chosen ciphertext attacks were a thing. They clearly added some small checks to make sure that it would be hard for an attacker to modify a given ciphertext (e.g., by multiplying it by a chosen value). It’s also obvious that these checks aren’t very strong. In the standardized version of the padding scheme, there are essentially three bytes to check — and one of them (the “00” byte after the padding) can “float” at a large number of different positions, depending on how much padding and plaintext there is in the message.
The use of a weak integrity check leads to a powerful CCA2 attack on the encryption scheme that was first discovered by Daniel Bleichenbacher. The attack is powerful due to the fact that it actually leverages the padding check as a way to learn information about the plaintext. That is: the attacker “mauls” a ciphertext and sends it to be decrypted, and relies on the fact that the decryptor will simply perform the decryption checks they’re supposed to perform — and output a noticable error if they fail. Given only this one bit of information per decryption, the attack can gradually recover the full plaintext of a specific ciphertext by (a) multiplying it with some value, (b) sending the result to be decrypted, (c) recording the success/failure result, (d) adaptively picking a new value and repeating step (a) many thousands or millions of times.
The PKCS#1v1.5 padding scheme is mainly valuable to us today because it provides an excellent warning to cryptographic engineers, who would otherwise continue to follow the “you can just hack together something that looks safe” school of building protocols. Bleichenbacher-style attacks have largely scared the crypto community straight. Rather than continuing to use this approach, the crypto community has (mostly) moved towards techniques that at least offer some semblance of provable security.
That’s what we’ll cover in just a moment.
A few quick notes on achieving CCA2-secure public key encryption
Before we get to a laundry list of specific techniques and schemes, it’s worth asking what types of design features we might be looking for in a CCA2 public key encryption scheme. Historically there have been two common requirements:
- It would be super convenient if we could start with an existing encryption scheme, like RSA or Elgamal encryption, and generically tweak (or “compile”) that scheme into a CCA2-secure scheme. (Re-usable generic techniques are particularly useful in the event that someone comes up with new underlying encryption schemes, like post-quantum secure ones.)
- The resulting scheme should be pretty efficient. That rules out most of the early theoretical techniques that use huge zero knowledge proofs (as cool as they are).
Before we get to the details, I also want to repeat the intuitive description of the CCA2 security game, which I gave in the previous post. The game (or “experiment”) works like this:
- I generate an encryption keypair for a public-key scheme and give you the public key.
- You can send me (sequentially and adaptively) many ciphertexts, which I will decrypt with my secret key. I’ll give you the result of each decryption.
- Eventually you’ll send me a pair of messages (of equal length)
and I’ll pick a bit
at random, and return to you the encryption of
, which I will denote as
.
- You’ll repeat step (2), sending me ciphertexts to decrypt. If you send me
I’ll reject your attempt. But I’ll decrypt any other ciphertext you send me, even if it’s only slightly different from
- You (the attacker) will output your guess
. They “win” the game if
.
- We say a scheme is IND-CCA2 secure if the attacker wins with probability “not much greater” than 1/2 (which is the best an attacker can do if they just guess randomly.)
A quick review of this definition shows that we need a CCA2-encryption scheme to provide at least two major features.
First off, it should be obvious that the scheme must not leak information about the secret key, even when I’m using it to decrypt arbitrary chosen ciphertexts of your choice. There are obvious examples of schemes that fail to meet this requirement: the most famous is the (textbook) Rabin cryptosystem — where the attacker’s ability to obtain the decryption of a single chosen ciphertext can leak the entire secret key.
More subtly, it seems obvious that CCA2 security is related to non-malleability. Here’s why: suppose I receive a challenge ciphertext 


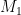
It turns out that an even stronger property that helps achieve both of these conditions is something called plaintext awareness. There are various subtly-different mathematical formulations of this idea, but here I’ll try to give only the English-language intuition:
If the attacker is able to submit a (valid) ciphertext to be decrypted, it must be the case that she already knows the plaintext of that message.
This guarantee is very powerful, because it helps us to be sure that the decryption process doesn’t give the attacker any new information that she doesn’t already have. She can submit any messages she wants (including mauling the challenge ciphertext
Of course, just because your scheme appears to satisfy the above conditions does not mean it’s secure. Both rules above are heuristics: that is, they’re necessary conditions to prevent attacks, but they may or may not be sufficient. To really trust a scheme (in the cryptographic sense) we should be able to offer a proof (under some assumptions) that these guarantees hold. We’ll address that a bit as we go forward.
Technique 1: Optimal Asymmetric Encryption Padding
One of the earlier practical CCA2 transforms was developed by Bellare and Rogaway as a direct replacement for the PKCS#1v1.5 padding scheme in RSA encryption. The scheme they developed — called Optimal Asymmetric Encryption Padding — represents a “drop-in” replacement for the earlier, broken v1.5 padding scheme. It also features a security proof. (Mostly. We’ll come back to this last point.)
(Confusingly, OAEP was adopted into the PKCS#1 standards as of version 2.0, so sometimes you’ll see it referred to as PKCS#1v2.0-OAEP.)
OAEP’s most obvious advance over the previous state of the art is the addition of not one, but two separate hash functions 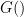
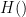
Expressed graphically, this is what OAEP it looks like:
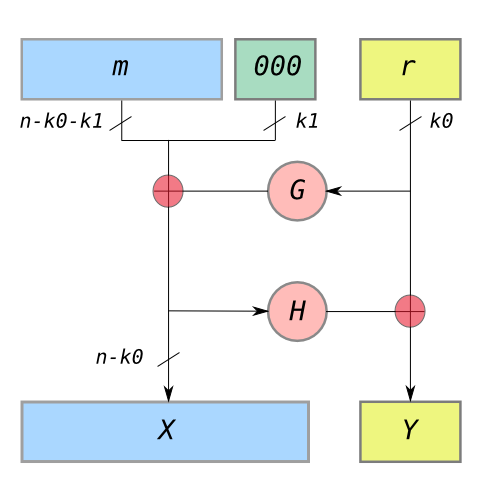
If you’ve ever seen the DES cipher, this structure should look familiar to you. Basically OAEP is a two-round (unkeyed) Feistel network that uses a pair of hash functions to implement the round functions. There are a few key observations you can make right off the bat:
- Just looking at the diagram above, you can see that it’s very easy to compute this padding function forward (going from a plaintext
and some random padding
to a padded message) and backwards — that is, it’s an easily-invertible permutation. The key to this feature is the Feistel network structure.
- Upon decryption, a decryptor can invert the padding of a given message and verify that the “check string” (the string of k1 “0” bits) is correctly structured. If this string is not structured properly, the decryptor can simply output an error. This comprises the primary decryption check.
- Assuming some (strong) properties of the hash functions, it intuitively seems that the OAEP transform is designed to create a kind of “avalanche effect” where even a small modification of a padded message will result in a very different unpadded result when the transform is inverted. In practice any such modification should “trash” the check string with overwhelming probability.
From an intuitive point of view, these last two properties are what makes OAEP secure against chosen-ciphertext attacks. The idea here is that, due to the random properties of the hash function, it should be hard for the attacker to construct a valid ciphertext (one that has a correct check string) if she does not already know the plaintext that goes into the transform. This should hold even if the attacker already has some known valid ciphertext (like
More specifically related to mauling: if I send an RSA-OAEP ciphertext
This all assumes some very strong assumptions about the hash functions, which we’ll discuss below.
The OAEP proof details (at the most ridiculously superficial level)
Proving OAEP secure requires two basic techniques. Both fundamentally rely on the notion that the functions
First: assuming a function is a “random oracle” means that we’re assuming it to have the same behavior as a random function. This is an awesome property for a hash function to have! (Note: real hash functions don’t have it. This means that hypothetically they could have very ‘non-random’ behavior that would make RSA-OAEP insecure. In practice this has not yet been a practical concern for real OAEP implementations, but it’s worth keeping in mind.
It’s easy to see that if the hash functions
At a much deeper level, the use of random oracles in RSA’s security proof gives the security reduction a great deal of “extra power” to handle things like decrypt chosen ciphertexts. This is due to the fact that, in a random oracle proof, the proof reduction is allowed to both “see” every value hashed through those hash functions, and also to “program” the functions so that they will produce specific outputs. This would not be possible if
These properties provide a tool in the security proof to enable decryption even when the secret key is unknown. In a traditional proof of the RSA-OAEP scheme, the idea is to show that an attacker who breaks the encryption (in the IND-CCA2 sense) can be used to construct a second attacker who solves the RSA problem. This is done by taking some random values 



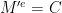
(There turned out to be some issues in the original OAEP proof that make it not quite work for arbitrary trapdoor permutations. Shoup fixed these by providing a new padding padding scheme called OAEP+, but the original OAEP had since gone into heavy usage within standards! It turns out that RSA-OAEP does work, however, for RSA with public exponents 3 and other exponents, though proving this required some ugly band-aids. This whole story is part of a cautionary tail about provably security, which Koblitz discusses here.)
Technique 2: The Fujisaki-Okamoto Transform
One limitation of OAEP (and OAEP+) padding is that it requires a trapdoor permutation in order to work. This applies nicely to RSA encryption, but does not necessarily work with every existing public-key encryption scheme. This motivates the need for other CCA transforms that work with arbitrary existing (non-CCA) encryption schemes.
One of the nicest generic techniques for building CCA2-secure public-key encryption is due to Eiichiro Fujisaki and Tatsuaki Okamoto. The idea of this transform is to begin with a scheme that already meets the definition of IND-CPA security — that is, it is semantically secure, but not against chosen ciphertext attacks. (For this description, we’ll also require that this scheme has a large [exponentially-sized] message space and some specific properties related to randomness.) The beauty of the “Fujisaki-Okamoto transform” (henceforth: F-O) is that, like OAEP before it, given a working public-key encryption scheme, it requires only the addition of some hash functions, and can be proven secure in the random oracle model.
Let’s imagine that we have an IND-CPA encryption public-key encryption algorithm that consists of the algorithms 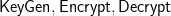
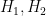
A key observation here is that in every IND-CPA (semantically secure) public key encryption scheme, the 
The main trick that the F-O transform uses is to de-randomize this public-key encryption algorithm. Instead of using real random bits to encrypt, it will instead use the output of the hash function 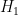
Let’s get to the nuts and bolts. The F-O transform does not change the key generation algorithm of the original encryption scheme at all, except to specify the hash functions
To encrypt a message 
- Instead of encrypting the actual message
from the message space of the original CPA-secure scheme.
- We hash the random message
.
- Next, we’ll encrypt the new random message
. Note that here
- Finally, we derive a “key” for encrypting the real message we want to send. We can compute this as
.
- We now encrypt the original message
.
- We output the “ciphertext”
.
To decrypt
- First, use the original public-key encryption scheme’s secret key to decrypt the ciphertext
, which (if all is well) should give us
.
- Now use knowledge of
to recover the key
and thus the message
.
- Now check that both
are valid by re-computing the randomness
and verifying the condition
. If this final check fails, simply output a decryption error.
Phew. So what the heck is going on here?
Let’s tackle this scheme from a practical perspective. Earlier in this post, we said that to achieve IND-CCA2 security, a scheme must have two features. First, it must be plaintext aware, which means that in order to construct a valid ciphertext (that passes all decryption checks) the attacker should already know the plaintext.
Does F-O have this property? Well, intuitively we would hope that the answer is “yes”. Note for some valid F-O ciphertext 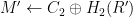
This guarantee (with high probability) comes from the structure of 

Of course, this is only one strategy available to the attacker. She could also maul an existing ciphertext like 
- If she tampers with any bit of
, she will change the recovered message into a new value that we can call
. However this will in turn (with overwhelming probability) cause the decryptor to recover very different random coins
than were used in the original construction of
, and thus decryption check on that piece will probably fail.
- If she tampers with any bit of
- She might try to tamper with both parts of the ciphertext, of course. But this would seem even more challenging.
The problem with the exercise above is that none of this constitutes a proof that the approach works. There is an awful lot of should and probably in this argument, and none of this ought to make you very happy. A rough sketch of the proof for an F-O scheme can be found here. (I warn you that it’s probably got some bugs in it, and I’m offering it mainly as an intuition.)
The F-O scheme has many variants. A slightly different and much more formal treatment by Hofheinz and Kiltz can be found here, and deals with some other requirements on the underlying CPA-secure scheme.
To be continued…
So far in this discussion we’ve covered two basic techniques — both at a very superficial level — that achieve CCA2 security under the ridiculously strong assumption that random oracles exist. Unfortunately, they don’t. This motivates the need for better approaches that don’t require random oracles at all.
There are a couple of those that, sadly, nobody uses. Those will have to wait until the next post.

{kind=link}
> This whole story is part of a cautionary tail about provably security
There are the invisible dachsunds.
A very nice post, thank you.
Looks like you’re missing some closing $-signs or something in the latex formatting in the last list.