Semantic security refers to the concept that an attacker who sees a ciphertext should learn no more (or very little more) information than an attacker who does not see the ciphertext at all. This should hold even when the set of possible plaintexts is small, potentially even chosen by the attacker himself.
Because it’s difficult to formalize the definition above, we typically use a different definition that’s known to be equivalent. This definition is called “Indistinguishability under Chosen Plaintext Attack”, or just “IND-CPA” for short.
The definition is formalized as a game between an adversary and some honest “Challenger”. For the case of public key encryption the game looks like this:
- First the challenger generates an encryption keypair, and sends the public key
to the adversary. (It keeps the secret key.)
- Next, the adversary selects a pair of messages
(of equal length) and sends them to the challenger.
- The challenger picks a random bit
and encrypts one of the two messages as
. It sends back
to the adversary.
- Finally, the adversary outputs a guess
. We say the adversary “wins” if it guesses correctly: that is, if
.
As mentioned in other articles, the adversary can always win with probability 1/2, just by guessing randomly in step (4). So we’re not interested in whether the adversary wins at all. Instead we’re interested in the adversary’s advantage, which is to say: how much better he does than he would if he just guessed randomly.
We can express this advantage as |Probability Adversary Wins – 1/2|. (This probability is taken over many runs of the experiment and all the randomness used — it’s not just the adversary’s success after one game.) An attacker who wins with probability exactly 1/2 will have “zero” advantage in the IND-CPA game. In general for a scheme to be IND-CPA secure it must hold that for all possible (time-bounded) adversaries, the adversary’s advantage will be negligibly small.
One obvious note about the IND-CPA game is that the attacker has the public key. (Recall that he gets it in step [1]). So sometimes people, upon seeing this definition for the first time, propose the following strategy for winning the game:
- The adversary picks two messages
- When the adversary receives the ciphertext
- Voila, the adversary can always figure out which message was encrypted!
If the encryption scheme is not randomized — meaning that every time you encrypt a message using a given public key, you get the same exact ciphertext — this attack works perfectly. In fact it works so well that an attacker who uses this strategy will always win the IND-CPA game, meaning that such a scheme cannot possibly satisfy the IND-CPA security definition.
The implication therefore, is that in order to satisfy the IND-CPA definition, any public-key encryption scheme must be randomized. That is, it must take in some random bits as part of the encryption algorithm — and it must use these bits in generating a ciphertext. Another way to think about this is that for every possible public key and message 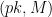

We see this use of randomization in many real-world encryption schemes. For example, most RSA encryption is done using some sort of “encryption padding” scheme, like OAEP or (the very broken) PKCS#1v1.5. Algorithms like Elgamal (and derivatives like ECIES) also use randomness in their encryption.
The important takeaway here is that this use of randomness in the encryption algorithm isn’t just for fun: it’s required in order to get semantic security.
The case of symmetric encryption. As a footnote, it’s also worth mentioning that IND-CPA can be applied to symmetric encryption. The major differences in that definition are (A) that in step (1) there is no public key to give to the adversary, and (B) to replace this lost functionality, the challenger must provide an “encryption” oracle to the adversary. Specifically, that means that the challenger must, when requested, encrypt messages of the adversary’s choice using its secret key. This can happen at any point in the game.
The caveats about deterministic encryption also apply in the symmetric case, and for basically the same reason. In short: ciphertexts must be diversified in some way so that two different encryptions of the same plaintext do not produce the same ciphertext. If this was not the case, then the adversary could easily win the game.
The only major difference is that in the symmetric setting, this diversification doesn’t always need to be done with randomness. Some schemes use “state”. For example, it’s possible to build an encryption scheme where the challenger keeps a simple counter between messages, and uses this counter in place of “true” randomness. (A good example of this is CTR mode encryption, where the attacker ensures that initial counters [IVs] never repeat.) This obviously only works in settings where there is a single encryptor, or all encryptors are guaranteed to not repeat different counters.
