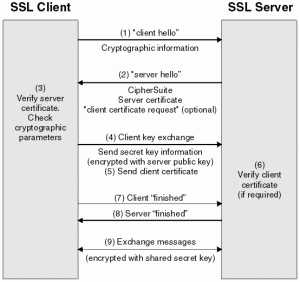
Arvind Narayanan just gave a fascinating talk at Princeton’s Center for Information Technology Policy entitled ‘What Happened to the Crypto Dream?‘. That link is to the video, which unfortunately you’ll actually have to watch — I have yet to find a transcript.
Information Technology Policy entitled ‘What Happened to the Crypto Dream?‘. That link is to the video, which unfortunately you’ll actually have to watch — I have yet to find a transcript.
From the moment I heard the title of Arvind’s talk I was interested, since it asks an important question that I wanted a chance to answer. Specifically: what happened to the golden future of crypto? You know, the future that folks like Phil Zimmermann offered us — the one that would have powered the utopias of Neal Stephenson and the dystopias of William Gibson (or do I have that backwards?) This was the future where cryptography fundamentally altered the nature of society and communications and set us free in new and exciting ways.
That future never quite arrived. Oh, mind you, the technology did — right on schedule. We’re living in a world where it’s possible to visit Tokyo without ever leaving your bed, and where governments go to war with software rather than tanks. Yet in some ways the real future is more Stephen King than William Gibson. The plane landed; nobody was on board.
So what did happen to the crypto dream?
The premise, explained
Once upon a time most important human transactions were done face-to-face, and in those transactions we enjoyed at least the promise that our communications would be private. Then everything changed. First came the telephones and telegraphs, and then computer networks. As our friends and colleagues spread farther apart geographically, we eagerly moved our personal communications to these new electronic networks. Networks that, for all their many blessings, are anything but private.
 |
| People affected by telephonic surveillance (1998-2011). Source: ACLU |
Some people didn’t like this. They pointed out that our new electronic communications were a double-edge sword, and were costing us protections that our ancestors had fought for. And a very few decided to do something about it. If technological advances could damage our privacy, they reasoned, then perhaps the same advances could help us gain it back.
By 1990s, the conditions were in place for a privacy renaissance. For the first time in history, the average person had access to encryption technology that was light years beyond what most governments had known before. The flagbearer of this revolution was Philip Zimmermann and his Pretty Good Privacy (PGP), which brought strong encryption to millions. Sure, by modern standards PGP 1.0 was a terrible flaming piece of crap. But it was a miraculous piece of crap. And it quickly got better. If we just hung in there, the dream told us, the future would bring us further miracles, things like perfect cryptographic anonymity and untraceable electronic cash.
It’s worth pointing out that the ‘dream’ owes a lot of its power to government itself. Congress and the NSA boosted it by doing what they do best — freaking out. This was the era of export regulations and 40-bit keys and Clipper chips and proposals for mandatory backdoors in all crypto software. Nothing says ‘clueless old dinosaurs’ like the image of Phil Zimmermann being searched at the border — for copies of a program you could download off the Internet!
Obviously none of this actually happened.
If you sent an email today — or texted, or made a phone call — chances are that your communication was just as insecure as it would have been in 1990. Maybe less so. It probably went through a large service provider who snarfed up the cleartext, stuffed it into an advertising algorithm, then dropped it into a long term data store where it will reside for the next three years. It’s hard to be private under these circumstances.
Cryptography is still everywhere, but unfortunately it’s grown up and lost its ideals. I don’t remember the last time I bothered to send someone a GPG email — and do people actually have key signing parties anymore?
Problem #1: Crypto software is too damned hard to use.
Cryptographers are good at cryptography. Software developers are good at writing code. Very few of either camp are good at making things easy to use. In fact, usability is a surprisingly hard nut to crack across all areas of software design, since it’s one of a few places where 99% is just not good enough. This is why Apple and Samsung sell a zillion phones every year, and it’s why the ‘year of Linux on the Desktop‘ always seems to be a few years away.
Security products are without a doubt the worst products for usability, mostly because your user is also the enemy. If your user can’t work a smartphone, she might not be able to make calls. But if she screws up with a security product, she could get pwned.
Back in 1999 — in one of the few usability studies we have in this area — Alma Whitten and J.D. Tygar sat down and tried to get non-experts to use PGP, a program that experts generally thought of as being highly user friendly. Needless to say the results were not impressive. And as fun as it is to chuckle at the people involved (like the guy who revoked his key and left the revocation message on his hard drive) the participants weren’t idiots. They were making the same sort of mistakes everyone makes with software, just with potentially more serious consequences.
And no, this isn’t just a software design problem. Even if you’re a wizard with interfaces, key management turns out to be just plain hard. And worse, your brililant idea for making it easier will probably also make you more vulnerable. Where products have ‘succeeded’ in marketing end-to-end encryption, they’ve usually done so by making radical compromises that undermine the purpose of the entire exercise.
Think Hushmail, where the crypto client was delivered from a (potentially) untrustworthy server. Or S/MIME email certificates which are typically generated in a way that could expose private key to the CA. And of course, there’s Skype, which operates their own user-friendly CAs, a CA that can potentially pwn you in a heartbeat.
Problem #2: Snake-oil cryptography has cluttered the space.
As Arvind points out, most people don’t really understand the limitations of cryptography. This goes for people who rely on it for their business (can’t tell you how many times I’ve explained this stuff to DRM vendors.) It goes double for the average user.
The problem is that when cryptography does get used, it’s often applied in dangerous, stupid and pointless ways. And yet people don’t know this. So bad products get equal (or greater) billing than good ones, and the market lacks the necessary information to provide a sorting function. This is a mess, since cryptography — when treated as a cure-all with magical properties — can actually make us less secure than we might otherwise be.
Take VPN services, for example. These propose to secure you from all kinds of threats, up to and including totalitarian governments. But the vast majority of commercial VPN providers do terribly insecure things, like use a fixed shared-secret across all users. Data encryption systems are another big offender. These are largely purchased to satisfy regulatory requirements, and buying one can get you off the hook for all kinds of bad behavior: regulations often excuse breaches as long as you encrypt your data — in some way — before you leave it in a taxi. The details are often overlooked.
With so much weak cryptography out there, it’s awfully hard to distinguish a good system. Moreover, the good system will probably be harder to use. How do you convince people that there’s a difference?
Problem #3: You can’t make money selling privacy.
As I’ll explain in a minute this one isn’t entirely true. Yet of all the answers in this post I tend to believe that it’s also the one with the most explanitory power.
Here’s the thing: developing cryptographic technology isn’t cheap, and it isn’t fast. It takes time, love, and a community of dedicated developers. But more importantly, it requires subject matter experts. These people often have families and kids, and kids can’t eat dreams. This means you need a way to pay them. (The parents, that is. You can usually exploit the kids as free labor and call it an ‘internship’.)
Across the board, commercialization of privacy technologies has been something of a bust. David Chaum gave it a shot with his anonymous electronic cash company. Didn’t work. Hushmail had a good run. These guys are giving it a shot right now — and I wish them enormous luck. But I’m not sure how they’re going to make people pay for it.
In fact, when you look at the most successful privacy technologies — things like PGP or Tor or Bitcoin — you notice that these are the exceptions that prove the rule. Tor was developed with US military funding and continues to exist thanks to generous NGO and government donations. PGP was a labor of love. Bitcoin is… well, I mean, nobody really understands what Bitcoin is. But it’s unique and not likely to be repeated.
I could think of at least two privacy technologies that would be wonderful to have right now, and yet implementing them would be impossible without millions in seed funding. And where would you recover that money? I can’t quite figure it out. Maybe Kickstarter is the answer to this sort of thing, but I’ll have to let someone else prove it to me.
Problem #4: It doesn’t matter anyway. You’re using software, and you’re screwed.
Some of the best days of the crypto dream were spent fighting government agencies that legitimately believed that crypto software would render them powerless. We generally pat ourselves on the back for ‘winning’ this fight (although in point of fact, export regulations still exist). But it’s more accurate to say that governments decided to walk away.
With hindsight it’s pretty obvious that they got the better end of the deal. It’s now legal to obtain strong crypto software, but the proportion of (non-criminal) people who actually do this is quite small. Worse, governments have a trump card that can circumvent the best cryptographic algorithm. No, it’s not a giant machine that can crack AES. It’s the fact that you’re implementing the damned thing in software. And software vulnerabilities will overcome all but the most paranoid users, provided that the number of people worth tracking is small enough.
Arvind points this out in his talk, and refers to a wonderful talk by Jonathan Zittrain called ‘The End of Crypto’ — in which Jonathan points out how serious the problem is. Moreover, he notes that we’re increasingly losing control of our devices (thanks to the walled garden model), and argues that such control is a pre-condition for secure communications This may be true, but let me play devil’s advocate: the following chart shows a price list for 0days in commercial software. You tell me which ones the government has the hardest time breaking into.
 |
| Estimated price list for 0-days in various software products. (Source: Forbes) |
Whatever the details, it seems increasingly unlikely that we’re going to live the dream while using the software we use today. And sadly nobody seems to have much of an answer for that.
Problem #5: The whole premise of this post is wrong — the dream is alive!
Of course, another possibility is that the whole concept is just mistaken. Maybe the dream did arrive and we were all just looking the other way.
Sure, GPG adoption may be negligible, and yes, most crypto products are a disaster. Yet with a few clicks I can get on a user-friendly (and secure!) anonymous communications network, where my web connections will be routed via an onion of encrypted tunnels to a machine on the other side of the planet. Once there I can pay for things using a pseudonymous electronic cash service that bases its currency on nothing more than the price of a GPU.
If secure communications is what I’m after, I can communicate through OTR or RedPhone or one of a dozen encrypted chat programs that’ve recently arrived on the scene. And as long as I’m not stupid, there’s surprisingly little that anyone can do about any of it.
In conclusion
This has been a very non-technical post, and that’s ok — you don’t have to get deeply technical in order to answer this particular question. (In fact, this one place I slightly disagree with Arvind, who also brings up the efficiency of certain advanced technologies like Secure Multiparty Computation. I truly don’t think this is a story about efficiency, because we have lots of efficient privacy protocols, and people still don’t use them.)
What I do know is that there’s so much we can do now, and there are so many promising technologies that have now reached maturity and are begging to be deployed. These include better techniques for anonymizing networks, adding real privacy to currencies like Bitcoin, and providing user authentication that actually works. The crypto dream can still live. Maybe all we need is a new generation of people to dream it.



_1870.jpg)