 A friend who’s learning cryptography writes with a few questions about block ciphers:
A friend who’s learning cryptography writes with a few questions about block ciphers:
(1) Let’s say we’re using AES-128 — 128 bit keys, 128 bit blocks.
- For a given 128 bit block of plaintext “P” – if I was to iterate through all 2**128 key permutations and encrypt the same plaintext P with each key, would the outputs all be unique, or would there be collisions?
- For a given 128 bit key “K”, if I was to use K to encrypt every possible (2**128) plaintext, would the outputs all be unique, or would there be collisions?
What’s Claude Shannon got to do with it?
Back in the late 1940s when people were still thinking on this whole information theory business, a gentleman named Claude Shannon came up with a model for what a block cipher should do. His idea was — and yes, I’m embellishing a lot here — that an ‘ideal’ block cipher would work kind of like a magical elf.*
You could ask the elf to encipher and decipher things for you. But instead of using a mathematical algorithm, it would just keep a blackboard with a big table. The table would have three columns (Key, Plaintext, Ciphertext), and it would start off empty.
- Check to see if (K, P) were already recorded in some row of the table. If they were, it would read off the corresponding ciphertext value C from the same row, and return C.
- If no matching row was found, it would generate a perfectly random ciphertext C.
- It would then check for an existing table entry containing the same key and ciphertext (K, C). If this entry was found in the table, it would throw C away and repeat step (2).
- Otherwise it would add (K, P, C) to the table and return C to the caller.
Now I realize this looks complicated, but if you think about this for a little while you’ll realize that this little thought experiment does ‘work’ a lot like a real block cipher.
Just like a block cipher, it will always give the same output when you pass it a given key and plaintext. Furthermore — for a given key K, no two plaintexts will ever encipher to the same ciphertext. This models the fact that a block cipher is a permutation.
Of course, you also need the elf to decipher stuff as well. Decipherment works mostly like the process above. When you ask to decipher (K, C), it checks to see whether the given key and ciphertext are already in the table (i.e., they were previously enciphered). If so it looks up and returns the corresponding plaintext. Otherwise it generates a new random plaintext, makes sure it hasn’t previously appeared in the table with that key, and returns the result.
Under the assumption that AES works like our elf, we can now answer my friend’s questions. Clearly if I encrypt the same plaintext with many different keys, I will get many different ciphertexts. They’ll each be random and 128 bits long, which means the probability of any two ciphertexts being the same (colliding) is quite small. But there’s no rule preventing it, and over a large enough set it’s actually quite likely.
Similarly, the second question is answered by the fact that the cipher is a permutation, something that’s captured in our elf’s rule (3).
This is an awful lot of work to answer a few simple questions…
Yes, it certainly is. But the ‘Elf’ model is useful for answering much more interesting questions — like: is a given encryption scheme secure?
For example, take the CBC mode of operation, which is a way to turn a block cipher into an encryption scheme:
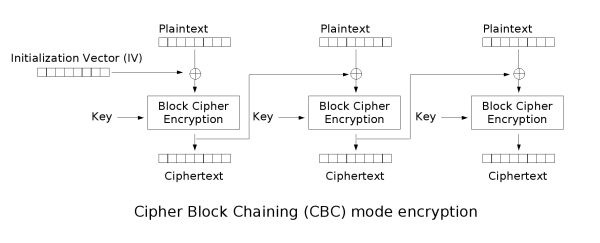
CBC encryption takes in a random key (K) and a random ‘Initialization Vector’ (IV), both of which are chosen by the encryptor. Now let’s see what happens if we CBC-encrypt an N-block message using our elf.
- The encryptor XORs the first plaintext block with the (random) Initialization Vector (IV), which should give a randomly-distributed value. We’ll call this P’.
- He then sends (K, P’) to be enciphered by the elf. Since the elf has never seen (K, P’) — meaning it’s not in the table — it will generate a random value (C1), which will become the first ciphertext block.
- The encryptor now XORs the next plaintext block with C1, which again should yield a randomly-distributed value which we’ll call P”.
- He sends (K, P”) to be enciphered by the elf. Since P” is also random (and, say, 128 bits long), the probability that it’s already in the table is astronomically low. Thus with high probability the elf will again generate a random value (C2), which becomes the second ciphertext block.
- He then repeats steps (3) and (4) for all the remaining blocks.
Of course, an attacker might also talk to the elf to try to learn something about the message. But note that even this attack isn’t useful unless he can guess the (random) key K, since the elf will give him random results unless he asks for a value that includes K. Since K is a randomly-chosen secret key, the attacker should not be able to guess it.
Do ideal ciphers exist?
The problem here is that ideal ciphers are totally unworkable. Obviously we can’t have an actual elf randomly filling in a bulletin board as we encrypt things. I want to carry a copy of the block cipher around with me (in software or hardware). I also want my copy of the cipher to be consistent with your copy, so that I can send you messages and you can decrypt them.
To make the elf idea work, we would each need to carry around a copy of the elf’s table that’s completely filled in from the start — meaning it would already contain entries for every possible plaintext (resp. ciphertext) and key I might ever need to encipher/decipher. When you consider that there would be 2^128 rows just for a single key, you realize that, no, this is not a question of running out to Best Buy and picking up some more SD cards. It’s fundamentally hard.
So carrying ideal ciphers around is not possible. The question then is: is there something that’s as good as an ideal cipher, without requiring us to carry around an exponentially-sized table.
The answer to that question is a mixed bag. The bad news is that nothing really works as well as an ideal cipher. Worse yet, there exists schemes that would be provably secure with an ideal cipher, but would fail catastrophically if you implemented them with any real block cipher. So that sucks.
On the other hand, those are theoretical results. Unless you’re doing some very specific things, the ideal cipher model is a moderately helpful tool for understanding what block ciphers are capable of. It’s also a good jumping off point for understanding the real proofs we actually use for modes like CBC. These proofs use more ‘realistic’ assumptions, e.g., that the block cipher is a pseudorandom permutation.
But those proofs will have to wait for another time. I’ve reached my wonkery limit for today.
Notes:
* For the record, at no point did Claude Shannon ever refer to an ‘elf’. At least not in writing.
** The probability of a ‘collision’ (i.e., asking the elf to encipher a value that’s already been enciphered) goes up as you put encipher more blocks. At a certain point (for AES, close to 2^64 blocks) it becomes quite high. Not coincidentally, this roughly coincides with the number of blocks NIST says you should encrypt with CBC mode.





 That means crypto, but it also means software engineering, protocol design, HCI and hardware engineering (fair warning: my hardware experience mostly consists of solder burns).
That means crypto, but it also means software engineering, protocol design, HCI and hardware engineering (fair warning: my hardware experience mostly consists of solder burns).










