The British government’s undisclosed order, issued last month, requires blanket capability to view fully encrypted material, not merely assistance in cracking a specific account, and has no known precedent in major democracies. Its application would mark a significant defeat for tech companies in their decades-long battle to avoid being wielded as government tools against their users, the people said, speaking under the condition of anonymity to discuss legally and politically sensitive issues.
Apple’s decision to disable their encrypted cloud backup feature has triggered many reactions, including a few angry takes by Apple critics, accusing Apple of selling out its users:
With all this in mind, I think it’s time to take a sober look at what might really happening here. This will require some speculation and educated guesswork. But I think that exercise will be a lot more helpful to us if we want to find out what’s really going on.
Question 1: does Apple really care about encryption?
Encryption is a tool that protects user data by processing it using a key, so that only the holder of the appropriate key can read it. A variant called end-to-end encryption (E2EE) uses keys that only the user (or users) knows. The benefit of this approach is that data is protected from many threats that face centralized repositories: theft, cyber attacks, and even access by sophisticatedstate-sponsored attackers. One downside of this encryption is that it can also block governments and law enforcement agencies from accessing the same data.
Navigating this tradeoff has been a thorny problem for Apple. Nevertheless, Apple has mostly opted to err on the side of aggressive deployment of (end-to-end) encryption. For some examples:
In 2011, the company launched iMessage, a built-in messaging service with default end-to-end encryption for all users. This was the first widely-deployed end-to-end encrypted messaging service. Today these systems are recommended even by the FBI.
In 2013, Apple launched iCloud Key Vault, which encrypts your backed-up passwords and browser history using encryption that even Apple can’t access.
Apple faced law enforcement backlash on each of these moves. But perhaps the most famous example of Apple’s aggressive stance on encryption occurred during the 2016 Apple v. FBI case, where the company actively fought U.S. government’s demands to bypass encryption mechanisms on an iPhone belonging to an alleged terrorist. Apple argued that satisfying the government’s demand would have required Apple to weaken encryption on all of the company’s phones. Tim Cook even took the unusual step of signing a public letter defending the company’s use of encryption:
I wouldn’t be telling you the truth if I failed to mention that Apple has also made some big mistakes. In 2021, the company announced a plan to implement client-side scanning of iCloud Photos to search for evidence of illicit material in private photo libraries. This would have opened the door for many different types of government-enforced data scanning, scanning that would work even if data was backed up in an end-to-end encrypted form. In that instance, technical experts quickly found flaws in Apple’s proposal and it was first paused, then completely abandoned in 2022.
This is not intended to be a hagiography for Apple. I’m simply pointing out that the company has, in the past, taken major public risks to deploy and promote encryption. Based on this history, I’m going to give Apple the benefit of the doubt and assume that the company is not racing to sell out its users.
This was due to a critical feature of the new law: it enables the U.K. government to issue secret “Technical Capability Notices” that can force a provider, such as Apple, to secretlychange the operation of their system — for example, altering an end-to-end encrypted system so that Apple would be forced to hold a copy of the user’s key. With this modification in place, the U.K. government could then demand access to any user’s data on demand.
By far the most concerning part of the U.K. law is that it does not clearly distinguish between U.K. customers and non-U.K. customers, such as those of us in the U.S. or other European nations. Apple’s lawyers called this out in a 2024 filing to Parliament:
In the worst-case interpretation of the law, the U.K. might now be the arbiter of all cybersecurity defense measures globally. Her Majesty’s Government could effectively “cap” the amount of digital security that customers anywhere in the world can depend on, without users even knowing that cap was in place. This could expose vast amounts of data to state-sponsored attackers, such as the ones who recently compromised the entire U.S. telecom industry. Worse, because the U.K.’s Technical Capability Notices are secret, companies like Apple would be effectively forced to lie to their customers — convincing them that their devices are secure, when in fact they are not.
It goes without saying that this is a very dangerous road to start down.
Question 3: how might Apple respond to a broad global demand from the U.K.?
Let us imagine, hypothetically, that this worst-case demand is exactly what Apple is faced with. The U.K. government asks Apple to secretly modify their system for all users globally, so that it is no longer end-to-end encrypted anywhere in the world.
(And if you think about it practically: that flavor of demand seems almost unavoidable in practice. Even if you imagine that Apple is only being asked only to target users in the U.K., the company would either need to build this capability globally, or it would need to deploy a new version or “zone”1 for U.K. users that would work differently from the version for, say, U.S. users. From a technical perspective, this would be tantamount to admitting that the U.K.’s version is somehow operationally distinct from the U.S. version. That would invite reverse-engineers to ask very pointed questions and the secret would almost certainly be out.)
But if you’re Apple, you absolutely cannot entertain, or even engage with this possibility. The minute you engage with it, you’re dead. One single nation — the U.K. — becomes the governor of all of your security products, and will now dictate how they work globally. Worse, engage with this demand would open a hell-mouth of unfortunate possibilities. Do you tell China and Europe and the U.S. that you’ve given the U.K. a backdoor into their data? What if they object? What if they want one too?
There is nothing down that road but catastrophe.
So if you’re Apple and faced with this demand from the U.K., engaging with the demand is not really an option. You have a relatively small number of choices available to you. In order of increasing destructiveness:
Hire a bunch of very expensive lawyers and hope you can convince the U.K. to back down.
Shut down iCloud end-to-end encryption in the U.K. and hope that this renders the issue moot.
???
Exit the U.K. market entirely.
If we can believe the reporting so far, I think it’s safe to say that Apple has almost certainly tried the legal route. I can’t even imagine what the secret court process in the U.K. looks like (does it involve wigs?) but if it’s anything like the U.S.’s FISA courts, I would tend to assume that it is unlikely to be a fair fight for a target company, particularly a foreign one.
In this model, Apple’s decision to disable end-to-end encrypted iCloud Backup means we have now reached Stage 2. U.K. users will no longer be able to sign up for Apple’s end-to-end encrypted backup as of February 21. (We aren’t told how existing users will be handled, but I imagine they’ll be forced to voluntarily downgrade to unencrypted service, or else lose their data.) Any request for a backdoor for U.K. users is now completely moot, because effectively the system no longer exists for U.K. users.
At this point I suppose it remains to see what happens next. Perhaps the U.K. government blinks, and relaxes its demands for access to Apple’s keys. In that case, I suppose this story will sink beneath the waves, and we’ll never hear anything about it ever again, at least until next time.
In another world, the U.K. government keeps pushing. If that happens, I imagine we’ll be hearing quite a bit more about this in the future.
Apple already deploys a separate “zone” for many of its iCloud security products in China. This is due to Chinese laws that mandate domestic hosting of Apple server hardware and keys. We have been assured by Apple (in various reporting) that Apple does not violate its end-to-end encryption for the Chinese government. The various people I’d expect to quit — if that claim was not true — all seem to be still working there.
I’m supposed to be finishing a wonky series on proof systems (here and here) and I promise I will do that this week. In the midst of this I’ve been a bit distracted by world events.
Last week the Washington Post published a bombshell story announcing that the U.K. had filed “technical capability notices” demanding that Apple modify the encryption used in their Advanced Data Protection (ADP) system for iCloud. For those who don’t know about ADP, it’s a system that enables full “end-to-end” encryption for iCloud backups, including photos and other data. This means that your backup data should be encrypted under your phone’s passcode — and critically, neither Apple nor hackers can access it. The U.K. request would secretly weaken that feature for at least some users.
Along with Alex Stamos, I wrote a short opinion piece (version without paywall) at the Wall Street Journal and I wanted to elaborate on the news a bit more here.
What’s iCloud and what’s ADP?
Most Apple phones and tablets are configured to automatically back their contents up to a service called iCloud Backup, which maintains a nearly-mirror copy of every file on your phone. This includes your private notes, contacts, private iMessage conversations, personal photos, and so on. So far I doubt I’m saying anything too surprising to the typical Apple user.
What many people don’t know is that in normal operation, this backup is not end-to-end encrypted. That is, Apple is given a decryption key that can access all your data. This is good in some ways — if you lose your phone and also forget your password, Apple might still be able to help you access your data. But it also creates a huge weakness. Two different types of “bad guys” can walk through the hole created by this vulnerability: one type includes hackers and criminals, including sophisticated state-sponsored cyber-intrusion groups. The other is national governments: typically, law enforcement and national intelligence agencies.
Since Apple’s servers hold the decryption key, the company can be asked (or their servers can be hacked) to provide a complete backup copy of your phone at any moment. Notably, since this all happens on the server side, you’ll never even know it happened. Every night your phone sends up a copy of its contents, and then you just have to hope that nobody else obtains them.
This is a bad situation, and Apple has been somewhat slow to remedy it. This is surprising, since Google has enabled end-to-end encrypted backup since 2018. Usually Apple is the company leading the way on privacy and security, but in this case they’re trailing? Why?
In 2021, Apple proposed a byzantine new system for performing client-side scanning of iCloud Photos, in order to detect child sexual abuse material (CSAM). Technical experts pointed out that this was a bizarre architecture, since client-side scanning is something you do when you can’t scan photos on the server — usually because that data is encrypted. However at that time Apple refused to countenance the notion that they were considering end-to-end encryption for backup data.
Then, at the end of 2022, Apple finally dropped the other shoe. The new feature they were deploying was called Advanced Data Protection (ADP), and it would finally enable end-to-end encryption for iCloud Backup and iCloud Photos. This was an opt-in mode and so you’d have to turn it on manually. But if you did this, your backups would be encrypted securely under your phone’s passcode — something you should remember because you have to type it in every day — and even Apple would not be able to access them.
The FBI found this very upsetting. But, in a country with a Fourth and First Amendment, at least in principle, there wasn’t much they could do if a U.S. firm wanted to deploy software that enabled users to encrypt their own data.
Go into “Settings”, type “Advanced data” and turn it on.
But… what about other countries?
Apple operates in hundreds of different countries, and not all of them have laws similar to the United States. I’ve written before about Apple’s stance in China — which, surprisingly, does not appear to involve any encryption backdoors. But of course, this story involves countries that are closer to the US, both geographically and politically.
In 2016, the U.K. passed the Investigatory Powers Act (IPA), sometimes known as the “Snooper’s Charter.” The IPA includes a clause that allows His Majesty’s government to submit Technical Capabiilty Notices to technology firms like Apple. A Technical Capability Notice (TCN) under U.K. law is a secret request in which the government demands that a technical provider quietly modify the operation of its systems so that they no longer provide the security feature advertised to users. In this case, presumably, that would involve weakening the end-to-end encryption system built into iCloud/ADP so that the U.K. could request downloads of encrypted user backups even without access to the user’s passcode or device.
The secrecy implicit in the TCN process is a massive problem here, since it effectively requires that Apple lie to its users. To comply with U.K. law, they must swear that a product is safe and works one way — and this lying must be directed to both civilian users and U.S. government users, commercial users, and so on — while Apple is forced to actively re-design their products to work differently. The dangers here should be obvious, along with the enormous risks to Apple’s reputation as a trustworthy provider. I will reiterate that this is not something that even China has demanded of Apple, as far as we know, so it is quite alarming.
The second risk here is that the U.K. law does not obviously limit these requests to U.K. customers. In a filing that Apple submitted back in 2024, the company’s lawyers make this point explicitly:
And when you think about it — this part I am admittedly speculating about — it seems really surprising that the U.K. would make these requests of a U.S. company without at least speaking to their counterparts in the United States. After all, the U.K. and the U.S. are part of an intelligence alliance known as Five Eyes. They work together on this stuff! There are at least two possibilities here:
The U.K. is operating alone in a manner that poses serious cybersecurity and business risks to U.S. companies.
The U.S. and the U.K. intelligence (and perhaps some law enforcement agencies) have discussed the request, and both see significant benefit from the U.K. possessing this capability.
We can’t really know what’s going on here, but both options should make us uncomfortable. The first implies that the U.K. is going rogue and possibly harming U.S. security and business, while the latter implies that some level of U.S. agencies are at tacitly signing off on a capability that could be used illegally against U.S. users.
What we do know from the recent Post article is that Apple was allegedly so uncomfortable with the recent U.K. request that they are “likely to stop offering encrypted storage in the U.K.“, i.e., they were at least going to turn off Advanced Data Protection in the U.K. This might or might not have resolved the controversy with the U.K. government, but it at least it indicated that Apple is not going to quietly entertain these requests.
What about other countries?
There are about 68 million people in the U.K., which is not a small number. But compared to other markets Apple sells in, it’s not a big place.
In the past, U.S. firms like WhatsApp and Signal have in the past made plausible threats to exit the U.K. market if the U.K. government makes good on threats to demand encryption backdoors. I have no doubt that Apple is willing to go to the mat for this as well if they’re forced to — as long as we’re only talking about the U.K. This is really sad for U.K. users, who deserve to have nice things and secure devices.
But there are bigger markets than the U.K. The European Union has 449.2 million customers and has been debating laws that would demand some access to encrypted messaging. China has somewhere between two to three times that. These are big markets to risk over encryption! Moreover, Apple builds a lot of its phones (and phone parts) in China. While I’m an optimist about human ethics — even within big companies — I doubt that Apple can convince its shareholders that their relationship with China is worth risking, over something abstract like the value of trust, or over end-to-end encrypted messages or iCloud.
And that’s what’s at stake if Apple gives in to the U.K. demands. If Apple gives in here, there’s zero reason for China not to ask for the same thing, perhaps this time applied to Apple’s popular iMessage service. And honestly, they’re not wrong? Agreeing to the U.K.’s request might allow the U.K. and Five Eyes to do things that would harm China’s own users. In short, abandoning Apple’s principles one place means they ultimately have to give in anywhere (or worse), or — and this is a realistic alternative — Apple is forced to leave many parts of the world. Both are bad for the United States, and both are bad for people in all countries.
So what should we do legally?
If you read the editorial, it has a simple recommendation. The U.S. should pass laws that forbid U.S. companies from installing encryption backdoors at the request of foreign countries. This would put companies like Apple in a bind. But it would be a good bind! To satisfy the laws of one nation, Apple would have to break the laws of their home country. This creates a “conflict of laws” situation where, at very least, simple, quiet compliance against the interest of U.S. citizens and customers is no longer an option for Apple — even if the shareholders might theoretically prefer it.
I hope this is a policy that many people could agree on, regardless of where they stand politically.
So what should we do technically?
I am going to make one more point here that can’t fit in an editorial, but deserves to be said anyway. We wouldn’t be in this jam if Apple had sucked it up and deployed end-to-end encrypted backup more broadly, and much earlier in the game.
Over the past decade I’ve watched various governments make a strong push to stop device encryption, add “warrant” capability to end-to-end encrypted messaging, and then install scanning systems to monitor for illicit content. Nearly all of these attempts failed. The biggest contributor to the failure was widespread deployment and adoption of encryption.
Once a system is widely deployed and people realize it’s adding value and safety to a system, they are loath to mess with that system. You see this pattern first with on-device encryption, and then with messaging. A technology is at first controversial, at first untenable, and then suddenly it’s mandatory for digital security. Even law enforcement agencies eventually start begging people to turn it on:
A key ingredient for this transition to occur is that lots of people must be leaning on that technology. If 1-2% of the customer base uses optional iCloud encryption, then it’s easy to turn the feature off. Annoying for a small subset of the population, maybe, but probably politically viable for governments to risk it. The same thing is less true at 25% adoption, and it is not true at 50% or 100% adoption.
Apple built the technology to deploy iCloud end-to-end encryption way back in 2016. They then fiddled around, not deploying it even as an option, for more than six years. Finally at the end of 2022 they allowed people to opt-in to Advanced Data Protection. But even then they didn’t make it a default, they don’t ask you if you want to turn it on during setup. They barely even advertise it to anyone.
If someone built an encryption feature but nobody heard about it, would it still exist?
This news from the U.K. is a wake up call to Apple that they need to move more quickly. They may feel intimidated due to blowback from Five Eyes nations, and that might be driving their reticence. But it’s too late, the cat is out of the bag. People are noticing their failure to turn this feature on and — while I’m certain there are excellent reasons for them to go slow — the silence and slow-rolling is starting to look like weakness, or even collaboration with foreign governments.
So what I would like, as a technologist, is for Apple to act serious about this technology. It’s important, and the ball is very much in Apple’s court to start pushing those numbers up. The world is not a safe place, and it’s not getting safer. Apple should do the right thing here because they want to. But if not, they should do it because doing otherwise is too much of a liability.
Back in March I was fortunate to spend several days visiting Brussels, where I had a chance to attend a panel on “chat control“: the new content scanning regime being considered by the EU Commission. Among various requirements, this proposed legislation would mandate that client-side scanning technology be incorporated into encrypted text messaging applications like Signal, WhatsApp and Apple’s iMessage. The scanning tech would examine private messages for certain types of illicit content, including child sexual abuse media (known as CSAM), along with a broad category oftextual conversations that constitute “grooming behavior.”
I have many thoughts about the safety of the EU proposal, and you can read some of them here. (Or you’re interested in the policy itself, you can read this recent opinion by the EU’s Council’s Legal Service.) But although the EU proposal is the inspiration for today’s post, it’s not precisely what I want to talk about. Instead, I’d like to clear up some confusion I’ve noticed around the specific technologies that many have proposed to use for building these systems.
Also: I want to talk about Ashton Kutcher.
Ashton Kutcher visits the EU parliament in March 2023 (photo: Roberta Metsola.)
It turns out there were a few people visiting Brussels to talk about encryption this March. Only a few days before my own visit, Ashton Kutcher gave a major speech to EU Parliament members in support of the Commission’s content scanning proposal. (And yes, I’m talking about that Ashton Kutcher, the guy who played Steve Jobs and is married to Mila Kunis.)
Kutcher has been very active in the technical debate around client-side scanning. He’s the co-founder of an organization called Thorn, which aims to develop cryptographic technology to enable content scanning. In March he gave an impassioned speech to the EU Parliament urging the deployment of these technologies, and remarkably he didn’t just talk about the policy side of things. When asked how to balance user privacy against the needs of scanning, he even made a concrete technical proposal: to use fully-homomorphic encryption (FHE) as a means to evaluate encrypted messages.
Now let me take a breath here before my head explodes.
I promise I am not one of those researchers who believes only subject-matter experts should talk about cryptography. Really I’m not!I write this blog because I think cryptography is amazing and I want everyone talking about it all the time. Seeing mainstream celebrities toss around phrases like “homomorphic encryption” isliterally a dream come true and I wish it happened every single day.
And yet, there are downsides to this much winning.
I ran face-first into some of those downsides when I spoke to policy experts about Kutcher’s proposal. Terms like fullyhomomorphic encryption can be confusing and off-putting to non-cryptographers. When filtered through people who are not themselves experts in the technology, these ideas can produce the impression that cryptography is magical pixie dust we can sprinkle on all the hard problems in the world. And oh how I wish that were true. But in the real world, cryptography is full of tradeoffs. Solving one problem often just makes new problems, or creates major new costs, or else shifts the risks and costs to other parts of the system.
So when people on various sides of the debate asked me whether “fully-homomorphic encryption” could really do what Kutcher said it would, I couldn’t give an easy five-word answer. The real answer is something like: (scream emoji)it’s very complicated. That’s a very unsatisfying thing to have to tell people. Out here in the real world the technical reality is eye-glazing and full of dragons.
Which brings me to this post.
What Kutcher is really proposing is that we to develop systems that perform privacy-preserving computation on encrypted data. He wants to use these systems to enable “private” scanning of your text messages and media attachments, with the promise that these systems will only detect the “bad” content while keeping your legitimate private data safe. This is a complicated and fraught area of computer science. In what goes below, I am going to discuss at a highand relatively non-technical level the concepts behind it: what we can do, what we can’t do, and how practical it all is.
In the process I’ll discuss the two most powerful techniques that we have developed to accomplish this task: namely, multi-party computation (MPC) and, as an ingredient towards achieving the former, fully-homomorphic encryption (FHE). Then I’ll try to clear up the relationship between these two things, and explain the various tradeoffs that can make one better than the other for specific applications. Although these techniques can be used for so many things, throughout this post I’m going to focus on the specific application being considered in the EU: the use of privacy-preserving computation to conduct content scanning.
This post will not require any mathematics or much computer science, but it will require some patience. So find a comfortable chair and buckle in.
Computing on private data
Encryption is an ancient technology. Roughly speaking, it provides the ability to convert meaningful messages (and data) into a form that only you, and your intended recipient(s) can read. In the modern world this is done using public algorithms that everyone can look at, combined with secret keys that are held only by the intended recipients.
Modern encryption is really quite excellent. So as long as keys are kept safe, encrypted data can be sent over insecure networks or stored in risky locations like your phone. And while occasionally people find a flaw in an implementation of encryption, the underlying technology works very well.
But sometimes encryption can get in the way. The problem with encrypted data is that it’s, well, encrypted. When stored in this form, such data is virtually useless for practical purposes like performing calculations. Before you can compute on that data, you often need to first decrypt it and thus remove all the beautiful protections we get from encryption.
If your goal is to compute on multiple pieces of data that originate from different parties, the problem can become even more challenging. Who can we trust to do the computing? An obvious solution is to decrypt all that data and hand it to one very trustworthy person, who will presumably swear not to steal it or get hacked. Finding those parties can be quite challenging.
Fortunately for us all, the first academic cryptographers also happened to be computer scientists, and so this was exactly the sortof problem that excited them. Those researchers quickly devised a set of specific and general techniques designed to solve these problems, and also came up with a cool name for them: securemulti-party computation, or MPC for short.
MPC: secure private computation (in sixeight ten paragraphs)
The setting of MPC is fairly simple: imagine that we have two (or more!) parties that each have some private data they don’t want to give to anyone else. Yet each of the parties is willing to provide their data as input to some specific computation, and are all willing to reveal the output of that computation — either to everyone involved, or perhaps just to some agreed subset of the parties. Can these parties now perform the computation jointly, without appointing a trusted party?
Let’s make this easier by using a concrete example.
Imagine a group of workers all know their own salaries, but don’t know anything about anyone else’s salary. Yet they wish to compute some statistics over their salary data: for example, the average of their salaries. These workers aren’t willing to share their own salary data with anyone else, but they are willing to submit it as one input in a large calculation under the strict condition that only the final result is ever revealed.
An MPC protocol allows the workers to do this, without appointing a trusted central party or revealing their inputs (and intermediate calculations) to anyone else. At the conclusion of the protocol each party will learn only the result of the calculation:
The “cloud” at the center of this diagram is actually a complicated protocol where every party sends messages to every other party.
MPC protocols typically provide strong provable guarantees about their properties. The details vary, but typically speaking: no party will learn anything about the other parties’ inputs. Indeed they won’t even learn any partial information that might be produced during the calculation. Even better, all parties can be assured that the result will be correct: as long as all parties submit valid inputs to the computation, none of them should be able to force the calculation to go awry.
Now obviously there are caveats.
In practice, using MPC is a bit like making a deal with a genie: you need to pay very careful attention to the fine print. Even when the cryptography works perfectly, this does not mean that computing your function is actually “safe.” In fact, it’s entirely possible to choose functions that when computed securely are still devastating to your privacy.
For example: imagine that I use an MPC protocol to compute an average salary between myself and exactly one other worker. This could be a very bad idea! Note that if the other worker is curious, then she can figure out how much I make. That is: the average of our two wages reveals enough information that she find my wage given knowledge of her own input. This (obvious) caveat applies to many other uses of MPC, even when the technology works perfectly.
This is not a criticism of MPC, just the observation that it’s a tool. In practice, MPC (or any other cryptographic technology) is not a privacy solution by itself, at least not in the sense of privacy that real-world human beings like to think about. It provides certain guarantees that may or may not be useful for providing privacy in the real world.
What does MPC have to do with client-side scanning?
We began this post by discussing client-side scanning for encrypted messaging apps. This is a perfect example of an application that fits the MPC (or two-party computation) use-case perfectly. That’s because in this setting we generally have multiple parties with secret data who want to perform some joint calculation on their inputs.
In this setting, the first party is typically a client (usually a person using an encrypted messaging app like WhatsApp or Signal), who possesses some private text message or perhaps a media file they wish to send to another user. Under proposed law in the EU, their app could be legally mandated to “scan” that image to see if it contains illegal content.
According to the EU Commission, this scanning can be done in a variety of ways. For example, the device could compare an images against a secret database of known illicit content (typically using a specialized perceptual hash function.) However, while the EU plan starts there, their plans also get much more ambitious: they also intend to look for entirely new instances of illicit content as well as textual “grooming” conversations, possibly using machine learning (ML) models, that is, deep neural networks that will be trained to recognize data that fits these patterns. These various models must be sophisticated enough to understand entirely new images, as well as to derive meaning from complex interactive human conversation. None of this is likely to be very simple.
Now most of this could be done using standard techniques on the client device, except for one major limitation. The challenge in this setting is that the provider doing the scanning usually wants to keep these hashes and/or ML models secret.
There are several reasons for this. The first reason is that knowledge of the scanning model (or database of illicit content) makes it relatively easy for bad actors to evade the model. In other words, with only modest transformations it’s possible to modify “bad” images so that they become invisible to ML scanners.
Knowledge of the model can also allow for the creation of “poisoned” imagery: these include apparently-benign images (e.g., a picture of a cat) that trigger false positives in the scanner. (Indeed this such “colliding” images have been developed for some hash-based CSAM scanning proposals.) More worryingly, in some cases the hashes and neural network models can be “reversed” to extract the imagery and textual content they were trained on: this has all kinds of horrifying implications, and could expose abuse victims to even more trauma.
So here the user doesn’t want to send its confidential data to the provider for scanning, and the provider doesn’t want to hand its confidential model parameters to the user (or even to expose them inside the user’s phone, where they might be stolen by reverse-engineers.) This is exactly the situation that MPC was designed to handle:
Sketch of a client-side scanning architecture that uses (two-party) MPC between the client and the Provider. The client inputs the content to be scanned, while the server provides its secret model and/or hash database. The protocol gives the provider a copy of the user’s content if and only if the model says it’s illicit content, otherwise the provider sees nothing. (Note in this variant, the output goes only to the Provider.)
This makes everything very complicated. In fact, there has only been one real-world proposal for client-side CSAM scanning that has ever come (somewhat) close to deployment: that system was designed by Apple for a (now abandoned) client-side photo scanning plan. The Apple approach is cryptographically very ambitious: it uses neural-network based perceptual hashing, and otherwise exactly follows the architecture described above. However, critically: it relied on a neural-network based hash function that was not kept secret. Disastrous results ensued (see further below.)
Ok, so what kind of MPC protocols are available to us?
Multi-party computation is a broad category. It describes a class of protocols. In practice there are many different cryptographic techniques that allow us to realize it. Some of these (like the Apple protocol) were designed for specific applications, while others are capable of performing general-purpose computation.
I promised this post would not go into the weeds, but it’s worth pointing out that general MPC techniques typically make use of (some combination of) three different techniques: secret sharing, circuit garbling, and homomorphic encryption. Often, efficientmodernsystems will use a mixture of two or three of those techniques, just to make everything more confusing because they’re to maximize efficiency.
What is it that you need to know about these techniques? Here I’ll try, in a matter of a few sentences (that will draw me endless grief) to try to summarize the strengths and disadvantages of each technique.
Both secret sharing and garbling techniques share a common feature, which is that they require a great deal of data to be sent between the parties. In practice the amount of data sent between the parties will grow with (at least) the size of the inputs they’re computing on, but often will grow according to the complexity of the calculation they’re performing. For things like deep neural networks where both the data and calculation are huge, this generally results in fairly surprising amounts of data transfer.
This is not usually considered to be a problem on the general Internet or within EC2 datacenters, where data transfer is cheap. It can be quite a challenge when one of those parties is using a cellphone, however. That makes any scheme using these technologies subject to some very serious limitations.
Homomorphic encryption schemes take a different approach. These systems make use of specialized encryption schemes that are malleable. This means that encrypted data can be “modified” in useful ways without ever decrypting it.
In a bit more detail: in fully-homomorphic encryption MPC systems, a first party can encrypt its data under a public key that it generates. It can then send the encrypted data to a second party. This second party can then perform calculations on the ciphertext while it is still encrypted — adding and multiplying it together with other data (including data encrypted by the second party) to perform some calculation. Throughout this process all of the data remains encrypted. At the conclusion of this process, the second party will end up with a “modified” ciphertext that internally contains a final calculation result, but that it cannot read. To finish the protocol, the second party can send that ciphertext back to the first party, who can then decrypt it using its secret key and obtain the final output.
The major upshot of the pure-FHE technique is that it substantially reduces the amount of data that the two parties need to transmit between them, especially compared to the other MPC techniques. The downside of this approach is… well, there are several. One is that FHE calculations typically require vastly more computational effort (and hence time and carbon emissions) than the other techniques. Moreover, they may still require a good deal of data transfer — in part because the number of calculations that one can perform on a given ciphertext is usually limited by “noise” that turns up within the ciphertext. Hence, calculations must either be very simple or else broken up into “phases”, where the partial calculation result is decrypted and re-encrypted so that more computation can be done. This can be done interactively between the parties, or by the second party alone (using a technique called “bootstrapping”) but in both cases the cost is either much more bandwidth exchanged or a great deal of extra computation.
In practice, cryptographers rarely commit to a single approach. They instead combine all these techniques in order to achieve an appropriate balance of data-transfer and computational effort. These “mixedsystems” tend to have merely large amounts of data transfer and large amounts of computation, but are still amazingly efficient compared to the alternatives.
For an example of this, consider this very optimized two-party MPC scheme aimed at performing neural network classification. This scheme takes (from the client) a 32×32 image, and evaluates a tiny 7-layer neural network held by a server in order to perform classification. As you can see, evaluating the model even on a single image requires about 8 seconds of computation and 200 megabytes of bandwidth exchange, for each image being evaluated:
Source: MUSE paper, figure 8. These are the times for a 7-layer MiniONN network trained on the CIFAR-10 dataset.
These numbers may seem quite high, but in fact they’re actually really impressive as these things go. Previous systems used nearly an order of magnitude more time and bandwidth to do their work. Maybe there will be further improvements in the future! Even on a pure efficiency basis there is much work to be done.
What are the other risks of MPC in this setting?
The final point I would like to make is that secure MPC (or MPC built using FHE as a tool) is not itself enough to satisfy the requirements of a safe content scanning system. As I mentioned above, MPC systems merely evaluate some function on private data. The question of whether that function is safe is left largely to the system designer.
In the case of these content scanning systems, the safety of the resulting system really comes down to a question of whether the algorithms work well, particularly in settings where “bad guys” can find adversarial inputs that try to disrupt the system. It also requires new techniques to ensure that the system cannot be abused. That is: there must be guarantees within the computation to ensure that the provider (or a party who hacks the provider) cannot change the model parameters to allow them to access your private content.
This is a much longer conversation than I want to have in this post, because it fundamentally requires one to think about whether the entire system makes sense. For a much longer discussion of the risks, see this paper.
This was nice, but I would like to learn more about each of these technologies!
The purpose of this post was just to give the briefest explanation of the techniques that exist for performing all of these calculations. If you’re interested in knowing (a lot more!) about these technologies, take a look at this textbook by Evans, Kolesnikov and Rosulek. MPC is an exciting area, and one that is advancing every single (research) conference cycle.
And maybe that is the lesson of this post: these technologies are still research techniques. It’s probably not quite time to put them out in the world.
On March 23 I was invited to participate in a panel discussion at the European Internet Services Providers Association (EuroISPA). The focus of this discussion was on recent legislative proposals, especially the EU Commission’s new “chat control” content scanning proposal, as well as the future of encryption and fundamental rights. These are the introductory remarks I prepared.
Thank you for inviting me today.
I should start by making brief introduction. I am a professor of computer science and a researcher in the field of applied cryptography. On a day-to-day basis this means that I work on the design of encryption systems. Most of what I do involves building things: I design new encryption systems and try to make existing encryption technologies more useful.
Sometimes I and my colleagues also break encryption systems. I wish I could tell you this didn’t happen often, but it happens much more frequently than you’d imagine, and often in systems that have billions of users and that are very hard to fix. Encryption is a very exciting area to work in, but it’s also a young area. We don’t know all the ways we can get things wrong, and we’re still learning.
I’m here today to answer any questions about encryption in online communication systems. But mainly I’m here because the EU Commission has put forward a proposal that has me very concerned. This proposal, which is popularly called “chat control”, would mandate content scanning technology be added to private messaging applications. This proposal has not been properly analyzed at a technical level, and I’m very worried that the EU might turn it into law.
Before I get to those technical details, I would like to address the issue of where encryption fits into this discussion.
Some have argued that the new proposal is not about encryption at all. At some level these people are correct. The new legislation is fundamentally about privacy and confidentiality, and where law enforcement interests should balance against those things. I have opinions about this, but I’m not an EU citizen. Unfortunately this is a fraught debate that Europeans will have to have among themselves. I don’t envy you.
What concerns me is that the Commission does not appear to have a strong grasp on the technical implications of their proposal, and they do not seem to have considered how it will harm the security of our global communications systems. And this does affect me, because the security of our communications infrastructure is not localized to any one continent: if the 447 million citizens of the EU vote to weaken these technical systems, it could affect all consumers of computer security technology worldwide.
So why is encryption so critical to this debate?
Encryption matters because it is the single best tool we have for securing private data. My time here is limited, but if I thought that using all of it to convince you of this single fact was necessary, I would do that. Literally every other approach we’ve ever used to protect valuable data has been compromised, and often quite badly. And because encryption is the only tool that works for this purpose, any system that proposes to scan private data must — as a purely technical requirement — grapple with the technical challenges it raises when that data is protected with end-to-end encryption.
And those technical implications are significant. I have read the Impact Assessment authored by the Commission, and I hope I am not being rude to this audience when I say that I found it deeply naive and alarming. My impression is that the authors do not understand, at a purely technical level, that they are asking technology providers to deploy systems that none of them know how to build safely. Nor has the Commission consulted people with the technical and scientific expertise that would be needed to make this proposal viable.
In order to explain my concerns, I need to give some brief background on how content scanning systems work: both historically, and in the context that the EU is proposing.
Modern content scanning systems are a new creation. They have only been deployed since only about 2009, and widely deployed only after about 2011. These systems normally evaluate messages uploaded to a server, often a social network or public repository. In historical systems — that is, older systems without end-to-end encryption — they would process unencrypted plaintext data, usually to look for known child sexual abuse media files (or CSAM.) Upon finding such an image, they undertake various reporting: typically alerting employees at the provider, who may then escalate to the police.
Historical scanning systems such as Microsoft’s PhotoDNA used a perceptual hashing algorithm to reduce each image to a “fingerprint” that can be checked against a database of knownillicit content. These databases are maintained by child safety organizations such as NCMEC. The hashing algorithms themselves are deliberately imperfect: they are designed to produce similar fingerprints for files that appear (to the human eye) to be identical, even if a user has slightly altered the file’s data.
A first limitation of these systems is that their inaccuracy can be exploited. It is relatively easy, using techniques that have only been developed recently, to make new images that appear to be harmless licit media files, but that will produce a fingerprint that is identical to harmful illicit CSAM.
A second limitation of these hash-based systems is that they cannot detect novel CSAM content. This means that criminals who post newly-created abuse media are effectively invisible to these scanners. Even a decade ago, the task of finding novel CSAM would have required human operators. However, recent advances in AI have made it possible to train deep neural networks on such imagery, so that these networks can try to detect new examples of it:
Of course, the key word in any machine-based image recognition system is “try.” All image recognition systems are somewhat fallible (see example at right) and even when they work well, they often fail to differentiate between licit and illicit content. Moreover these systems can be exploited by malicious users to produce surprising results. I’ll come back to that in a moment.
But allow me to return to the key challenge: integrating these systems with encrypted communication systems.
In end-to-end encrypted systems, such as WhatsApp or Apple iMessage or Signal, server-side scanning is no longer viable. The problem here is that private data is encrypted when it reaches the server, and cannot be scanned. The Commission proposal isn’t specific about how these systems should be handled, but it hints that this scanning should be done on the user’s devicebefore the content is encrypted. This approach is called client side scanning.
There are several challenges here.
First, client-side scanning represents an exception to the privacy guarantees of encrypted systems. In a standard end-to-end encrypted system, your data is private to you and your intended recipient. In a system with client-side scanning, your data is confidential… with an asterisk. That is, the data itself will be private unless the scanning system determines a violation has occurred, at which point your confidentiality will be (silently) revoked and unencrypted data will be transmitted to the provider (and thus, anyone who has compromised your provider.)
This ability to selectively disable encryption creates new opportunities for attacks. If an attacker can identify the conditions that will cause the model to reduce the confidentiality of youe encryption, she can generate new — and apparently harmless — content that will cause this to happen. This will very quickly overwhelm the scanning system, rendering it useless. But it will also seriously reduce the privacy of many users.
A mirror version of this attacker exists as well: he will use knowledge of the model to evade these systems, producing new imagery and content that appear unchanged, but that these systems cannot detect at all. Your most sophisticated criminals — most likely the ones who create this awful content in the first place — will hide in plain sight.
Finally, a more alarming possibility exists: many neural-network classifiers allow for the extraction of the images that were used to train the model. This means every complex neural network model may potentially contain images of abuse victims, who would be exposed to further harm if these models were revealed.
The only known defense against all of these attacks is to tightly protect the models themselves: that is, the ensure that the complex systems of neural network weights and/or hash fingerprints are never revealed. Historical server-side systems to to great lengths to protect this data, even making their very algorithms confidential. This was feasible in server-side scanning systems because the data only exists on a centralized server. It does not work well with client-side scanning, where models must be distributed to users’ phones. And so without some further technical ingredient, models cannot exist either on the server or on the user’s device.
The only serious proposal that has attempted to address this technical challenge was devised — and then subsequently abandoned — by Apple in 2021. That proposal aimed only at detecting known content using a perceptual hash function. The company proposed to use advanced cryptography to “split” the evaluation of hash comparisons between the user’s device and Apple’s servers: this ensured that the device never received a readable copy of the hash database.
Apple’s proposal failed for a number of reasons, but its technical failures provided important lessons that have largely been ignored by the Commission. While Apple’s system protected the hash database, it did not protect the code of the proprietary neural-network-based hash function Apple devised. Within two weeks of the public announcement, users were able to extract this code and devise both the collision attacks and evasion attacks I mentioned above.
One of the first “meaningful” collisions against NeuralHash, found by Gregory Maxwell.
Evasion attacks against Apple’s NeuralHash, from Struppek et al. (source)
The Commission’s Impact Assessment deems the Apple approach to be a success, and does not grapple with this failure. I assure you that this is not how it is viewed within the technical community, and likely not within Apple itself. One of the most capable technology firms in the world threw all their knowledge against this problem, and were embarrassed by a group of hackers: essentially before the ink was dry on their proposal.
This failure is important because it illustrates the limits of our capabilities: at present we do not have an efficient means for evaluating complex neural networks in a manner that allows us to keep them secret. And so model extraction is a real possibility in all proposed client-side scanning systems today. Moreover, as my colleagues and I have shown, even “traditional” perceptual hash functions like Microsoft’s PhotoDNA are vulnerable to evasion and collision attacks, once their code becomes available. These attacks will proliferate, if only because 4chan is a thing: and because some people on the Internet love nothing more than hurting other Internet users.
This example shows how a neural-network based hash function (NeuralHash) can be misled, by making imperceptible changes to an image.
In practice, the Commission’s proposal — if it is implemented in production systems — invites a range of technical attacks that we simply do not comprehend today, and that scientists have barely begun to think about. Moreover, the Commission is not content to restrain themselves to scanning for known CSAM content as Apple did. Their desire to target previously unknown content as well as textual content such as “grooming behavior” poses risks from many parties and requires countermeasures against abuse and surveillance that are completely undeveloped.
Worse: the “grooming behavior” requirement implies that untested, perhaps not-yet-developed AI language models will be a core part of tomorrow’s security systems. This is worrisome, since these models have failure modes and exploit opportunities that we are only beginning to explore.
In my discussion so far I have only scratched the surface of this issue. My analysis today does not consider even more basic issues, such as how we can trust that the purveyors of these opaque models are honest, and that the model contents have not been altered: perhaps by insider attack or malicious outside hackers. Each of these threats was once theoretical, and I have seen them all occur in just the last several years. Nor does it consider how the scope of these systems might be increased by future governments, and how this infrastructure will make future abuses more likely.
In conclusion, I hope that the Commission will rethink its hurried schedule and give this proposal enough time to be evaluated by scientists and researchers here in Europe and around the world. We should seek to understand these technical details as a precondition for mandating new technologies, rather than attempting to “build the airplane while we are flying in it”, which is very much what this proposal will encourage.
A few weeks back, the messaging service WhatsApp sued the Indian government over new legislation that could undermine its end-to-end encryption (E2EE) software. The legislation requires, among other things, that social media and messaging companies must include the ability to “trace” the source of harmful viral content.
This tracing capability has been a major issue in India due to several cases of misinformation content that led to brutal mob attacks. The ostensible goal of the new legislation is to make it possible for police to track down those who originate or disseminate this content. Put simply, what the authorities say they want is a means to identify a piece of content (for example, a video or a meme) that has gone to a large group of people, and then trace the content back to the WhatsApp account that originally sent it.
I don’t plain to weigh in on whether this policy is a good idea or viable on the merits, nor is it in my wheelhouse to say whether the Indian government is being forthright in their reasons for demanding this capability. (I will express a very grave degree of skepticism that this approach will catch any criminal who is remotely malicious and takes steps to cover their tracks.) In this post I mostly want to talk about the technology implications for encrypted messaging services, and what tracing features might mean for end-to-end encrypted systems like WhatsApp.
Why is content tracing hard in the first place?
A first thing to keep in mind is that content tracing is not really a natural feature for messaging system. That is, tracing content poses a challenge even for completely unencrypted messaging apps: the kind where service providers can see all data traveling through the system. Tracing back to a content originator requires that the provider must be able to identify a file received at some end-user’s account, and then “chase” the content backwards through time through each user account that forwarded it. Even this description doesn’t quite respect the difficulty of the problem: not every user literally hits a “forward” button to send content onward. Many will save and re-upload a file, which breaks the forwarding chain and can even produce a slightly different file — thanks to the magic of digital compression.
These problems aren’t intractable. In a system with no end-to-end encryption, they could perhaps be solved using perceptual hash functions that identify similar media files by constructing a “fingerprint” of each file that can easily be compared against other files, and can survive re-encoding or minor edits. (This is the same technology that’s used in detecting child sexual abuse imagery, something I wrote about here.) What’s important is that even with this technology, the obvious approach to content tracing requires the provider to have plaintext access to (at least the hashes of) user content.
This turns out to be a big problem for encrypted communication systems like WhatsApp, in which end-to-end encryption protects the confidentiality of content even from the gaze of the service provider. In WhatsApp, all messages (as well as file attachments) are encrypted directly from sender to recipient, using an encryption key that WhatsApp doesn’t possess. With a few engineering caveats,* tracing content in these systems is very difficult.
But difficult is not the same thing as impossible. A recent post by WhatsApp makes the case that tracing is fundamentally impossible to implement securely in an end-to-end encrypted system. While this claim seems intuitively correct, it’s also kind of unsatisfying. After all, “impossible” is a strong word, and it’s highly dependent on which assumptions you’re making. The problem with imprecise claims is that they invite arguments — and indeed WhatsApp’s claim has has already been disputed by some in the field.
In this post I’m going to consider the following simple question: is traceability in end-to-end encrypted systems actually possible? And if so, what are the costs to privacy and security? For the record: I’m writing this post as much to answer the question for myself as to answer it for anyone else, so don’t expect this to be short or simple. I’m working things out as I go along.
Let’s start with the most basic question.
What is “traceability” in an end-to-end encrypted system?
The biggest problem with the debate over content tracing is that nobody seems to have a terribly rigorous definition of what, precisely an end-to-end encrypted tracing scheme is supposed to do — or more precisely, what its limits will be. To understand whether these systems can be built, we need to think hard about what they’re supposed to do in the first place.
From the perspective of law enforcement, content tracing is a simple feature. A piece of “viral” content (say an image file) has been widely distributed through a messaging platform, and authorities have decided that this content is harmful. Since the content is widespread, we can assume that police have received a copy of the file at an account they control (e.g., their own accounts, or the account of a cooperating user.) The authorities wish to contact the service provider and ask them for the originator and/or major spreaders of the content. This gives us our first requirement:
Traceability: given a piece of “viral” content received by a device/account (plus any cryptographic keys at the device), a tracing scheme should be able to reliably trace the content back to the originator (or at least, earlier) accounts.
From the user’s side, E2EE systems are supposed to maintain the confidentiality of user communications. Confidentiality is a broad term and can mean a lot of things. In this case it has two specific flavors that are relevant, with names that I just made up now:
I wanted to illustrate this post with memes about the Swedish monarchy. Unfortunately, it turns out that Swedish Monarchy memes basically suck.
The confidentiality of the content itself: this ensures that forwarded files are known only to the sender and authorized recipients(s) of a conversation. Notice that for viral content, this property isn’t terribly important. Remember: our assumption is that the contentitself has ultimately been forwarded widely, until (nearly) everyone has received a copy.
The confidentiality of “who sent what”: while the content itself may not be secret, the fact that a given user transmitted a piece of content is still quite sensitive. If I send you a political meme — perhaps the one at right, poking fun at the King of Sweden — then I might not care very much about the secrecy of the meme itself. But I sure might want to hide the fact that I sent it, to avoid retribution by a totalitarian Swedish government.** Proper end-to-end encryption is supposed to protect this sort of expression.
In short: traceability can really screw with the “who sent what” side of content confidentiality. It is a fairly harmless thing for, say, the tyrannical Swedish government to learn that specific memes about the King of Sweden exist. It is very different for them to know that I’ve been sending a lot of them to a specific group of friends.
Finally I need to clarify one more thing, since discussions with colleagues have made me realize that it is not obvious. Information revealed about “who sent what” in an E2E system is not the same as metadata. I feel stupid having to point this out, but metadata (information about data that we can’t easily hide from providers, such as the list of contacts you’ve communicated with) is a very different thing. WhatsApp might inevitably learn that I texted 500 people last month because they delivered my (encrypted) messages. They still shouldn’t learn that any of my messages are making fun of the Swedish monarchy.
So can traceability be accomplished without breaking E2E?
It really depends what you mean by “traceability” and what you mean by “breaking.”
While confidentiality and traceability may seem like they’re in conflict, it’s important to point out that some forms of tracing can beimplemented in a non-coercive way that does not inherently violate confidentiality. For example, imagine Alice originates a meme, and this meme subsequently makes its way to police officer Eve via the following forwarding path:
Provided that Bob, Charlie and Dave are willing to cooperate with the police, then Eve can use shoe-leather detective work to trace the content backwards towards Alice. After all: each participant (1) is an authorized recipient of the data and (2) knows who they received the content from. Nobody is “breaking” E2E if they perform this sort of cooperative tracing: it’s just people sharing information they’re already entitled to have.
It’s now time to say a stupid and obvious thing: what’s being proposed in India is not cooperativetracing.
Let’s be clear: if detective work and cooperation was sufficient to trace the originators of harmful content, the police wouldn’t be asking for new encryption laws, and WhatsApp wouldn’t be suing the Indian government.
By passing these laws, police are tacitly admitting that voluntary content tracing is not sufficient to met their investigative needs. This implies that when police try to follow a chain like the one shown above, they’re running into people who are either (1) unwilling to share this information in a timely way, or (2) simply don’t have the information anymore — maybe because they deleted the messages or lost their phone.
Let’s draw a picture of this situation. Below, each node represents a WhatsApp account, with the red node being the originator of some viral content, and the blue node representing police. Green nodes represent users who are willing to cooperate with the police, provided they are contacted. Here the gray nodes are users who won’t cooperate — either because they didn’t keep the information, or maybe because they just don’t like police.
Police (blue) can try to cooperatively trace content backwards through this forwarding graph by talking to cooperative users (green), but they’ll never reach the originator (red) because there are too many non-cooperating nodes (gray) in the way.
The prevalance of uncooperative nodes in the above graph makes it virtually impossible for cooperative tracing to find the originator. It seems obvious that real-world situations like this will make voluntary tracing very difficult to achieve.
This brings us to the central challenge of all content tracing proposals so far: to make tracing possible, a tracing system needs to turn every WhatsApp user (including the originator) into a cooperative green circle — regardless of whether users actually want to cooperate with police. Moreover, to prevent users from losing their phones and/or going offline, the system will need to force users to place the necessary tracing information into escrow as soon as they receive content, so it will remain available even if users leave the network or lose their phones.
Not only that, but each of these newly “cooperative” users might even be forced to admit to police that they also forwarded the content. Don’t want to tell the Swedish government that you made fun of their beloved King? Then you’d better not use a system that follows this pattern of enforced traceability.
How do we force users to cooperate?
The major questions facing an end-to-end tracing system are twofold: (1) precisely how much information are recipients going to be forced to reveal against their will, and (2) who will be able to access this information?
There are at least two proposals that I’ve seen for adding traceability to E2EE communications schemes, and both start from similar assumptions. They both rely on making changes to the end-users’ client software to ensure that tracing information is stored in “escrow” at the provider every time content is sent from one user to another.
One proposal is academic, and it takes something like the following “strawman” approach:
Each time someone sends content to another user, they will generate some fresh encryption key K.
They will use this key to encrypt a record that contains (A) the content (or a hash of it) and (B) the sender and receiver identities. They will store the encrypted record on WhatsApp’s servers as a kind of “key escrow.” Critically, at this point they will not send WhatsApp the key K.
The sender will transmit the record encryption key K to its recipient, using end-to-end encryption.
When the next user forwards the same content on to another user, it will repeat steps (1-4) and it will also send all the keys generated by previous users.
Now if the police receive a copy of some viral content on an account they control, they will have a list of encryption keys that correspond to everyone in the forwarding chain for that content. They can just go back to WhatsApp with a subpoena, obtain the encrypted records, and use the chain of keys to decrypt them. This will reveal the entire forwarding path back to the originator.
Alice sends a message to Bob and “escrows” some encrypted information on WhatsApp’s servers. She sends the encryption key to Bob. Bob forwards to Eve and “escrows” similar information, sending the key to Eve. Eve (a police officer) can now use her key to decrypt the records stored at WhatsApp until she learns who Alice is.
Of course sending thousands of keys along with each forwarded message is kind of a drag, so there are some efficiency optimizations one can use to compress this information. For example, each time a user forwards a message they can store the previous user’s encryption key inside the encrypted record they escrow with WhatsApp. That means if police get one key — corresponding to the last record in a chain — they can decrypt the escrow record, and then they will obtain the key for the previous record in the chain. They can repeat this process until the entire forwarding chain is “unzipped”.
A lazy diagram (at right) shows how this process might work with three participants. Essentially the whole thing is a form of key escrow, with WhatsApp acting as the escrow authority. If the police get included in any chain at all, they (Eve in this diagram) can subpoena WhatsApp to trace the chain back to originator.
Of course, this is a very simple strawman explanation of the ideas: for a more fully-specified (academic) proposal, you can see this paper by Tyagi, Miers and Ristenpart. Not only does it support path traceback, but it also lets you figure out who else the message was forwarded to! The cryptography is a bit more optimized, but the security guarantees are roughly the same.
A second proposal by Dr V. Kamakoti of IIT Madras is far simpler: it essentially requires each person whooriginates new content into the network (as opposed to forwarding it) to attach a “watermark” to the content that identifies the account ID of the sender. This also assumes a trustworthy WhatsApp client, of course. Presumably that watermark could be encrypted using a key stored at WhatsApp, so this tracing will at least require the provider’s involvement.
Ok, so what’s wrong with these traceability proposals?
Well if you’re ok with the fact that police can determine the identity of every single person who forwarded a piece of viral content regardless of whether they’re not the originator of that content then, I guess, nothing.
That’s the essence of what the Tyagi, Miers and Ristenpart proposal offers, and frankly I’m not particularly ok with it. Even if I accepted the logic that we should have the means to trace “content originators” — the actual justification governments have offered for building systems like this one — I surely would not want to reveal every random user account that happened to forward the content. That seems like a recipe for persecuting innocent people.
Moreover, regardless of whether the system finds “content originators” or just “everyone on the forwarding path”, I think these ideas are pretty much synonymous with mass surveillance — and certainly they buttress WhatsApp’s technical claim that “traceability” breaks end-to-end encryption.
But I want to go just a little farther, and point out that these ideas have a major weakness that makes the entire approach feel confused.
The approaches I describe above rely on a critical assumption: that all participants in the system are going to behave honestly — that is, everyone will run the official WhatsApp client, which will contain logic designed to store an escrow record on WhatsApp’s servers. Nobody in this system will try to bypass this system by running an unofficial client, or by hacking their client to disable the escrow logic.
If you’re willing to make such a strong assumption, why bother with the complicated Tyagi, Miers and Ristenpart proposal? Why not just use the Kamakoti proposal: modify your WhatsApp client to add a small “watermark” to each fresh non-forwarded media file. After all: once you’ve assumed that everyone is running an honest client, you can assume that the content originator will be too — can’t you? This approach would still reveal a lot of information to police, but it wouldn’t reveal the identity of every random person who forwarded the content.
My guess is that Tyagi, Miers and Ristenpart have an answer to this that boils down to something like “maybe you can’t trust the originator to run the correct client, but loads of other people will be running it.” To me this invites a much more detailed discussion about what security assumptions you’re making, and how “bad” the bad guys really are.
One last note to academic authors: don’t help bad people build unrestricted surveillance systems and then punt “preventing abuse” to later papers, ok?
If you read this far to answer the (rarified) question of how traceability could work and whether it breaks E2E encryption, then you can stop here. The rest of this post is not about that. It’s just me alienating a whole bunch of my academic peers.
Here is what I want to say to them.
The debate around key escrow and law enforcement surveillance is a very hard one. People have a lot of opinions about whether this work is “helping the good guys” or “helping the bad guys”, i.e., whether it’s about helping police find criminals, or whether it’s going to build the infrastructure for authoritarianism and spying. I don’t know the answer to this. I suppose the answer depends to some extent on the integrity of the government(s) that are implementing them. I have opinions, but I don’t expect all of my colleagues to share them.
What I would ask my colleagues to think hard about is the following:
When you propose (or review a paper that proposes) a new “lawful access” system, is it solving the hard problems, or is it punting on the hard problems and solving only the easy ones?
Because at the end of the day, building systems that violate the confidentiality of E2E encryption is a relatively easy problem from a scientific perspective. We’ve known how to build key escrow systems from the earliest days of encryption. Building these systems is not interesting, scientifically. It is useful from an engineering perspective, of course — to parties who want to deploy such systems. When respected academics write such papers, it is also politically useful to those same parties.
What is scientifically interesting is whether we can build systems that actually prevent abuse, either by governments that misuse the technology or by criminals who steal keys. We don’t really know to do that very well right now. This is the actual scientific problem of designing law enforcement access systems — not the “access” part, which is relatively easy and mostly consists of engineering. In short, the scientific problem is figuring out how to prevent the wrong type of access.
When I read a paper that builds a sophisticated surveillance system, I expect it to address those abuse problems in a meaningful way. If the paper punts the important problems to subsequent work — if what I get is a paragraph like the one at right — my thinking is that you aren’t solving the right problem. You’re just laying the engineering groundwork for a world I don’t want my kids to live in. I would politely ask you all to stop doing that.
Notes:
* Some messaging systems implement attachment forwarding by passing a pointer to an existing file that is stored on their servers. This is a nice storage optimization, since it avoids the need to make and store a full duplicate copy of each object whenever the user hits “forward”. The downside of this approach is that it makes tracing relatively easy for providers, since they can see exactly which users accessed a given file. Such optimizations are inimical to private systems and really should be avoided.
** All claims about the Swedish government are fictionalized.
This week a group of global newspapers is running a series of articlesdetailingabuses of NSO Group’s Pegasus spyware. If you haven’t seen any of these articles, they’re worth reading — and likely will continue to be so as more revelations leak out. The impetus for the stories is a leak comprising more than 50,000 phone numbers that are allegedly the targets of NSO’s advanced iPhone/Android malware.
Notably, these targets include journalists and members of various nations’ political opposition parties — in other words, precisely the people who every thinking person worried would be the target of the mass-exploitation software that NSO sells. And indeed, that should be the biggest lesson of these stories: the bad thing everyone said would happen now has.
This is a technical blog, so I won’t advocate for, say, sanctioning NSO Group or demanding answers from theluminaries on NSO’s “governance and compliance” committee. Instead I want to talk a bit about some of the technical lessons we’ve learned from these leaks — and even more at a high level, precisely what’s wrong with shrugging these attacks away.
We should all want perfect security!
Don’t feel bad, targeted attacks are super hard!
A perverse reaction I’ve seen from some security experts is to shrug and say “there’s no such thing as perfect security.” More concretely, some folks argue, this kind of well-resourced targeted attack is fundamentally impossible to prevent — no matter how much effort companies like Apple put into stopping it.
And at the extremes, this argument is not wrong. NSO isn’t some script-kiddy toy. Deploying it costs hundreds of thousands of dollars, and fighting attackers with that level of resources is always difficult. Plus, the argument goes, even if we raise the bar for NSO then someone with even more resources will find their way into the gap — perhaps charging an even more absurd price. So let’s stop crapping on Apple, a company that works hard to improve the baseline security of their products, just because they’re failing to solve an impossible problem.
Still that doesn’t mean today’s version of those products are doing everything they could be to stop attacks. There is certainly more that corporations like Apple and Google could be doing to protect their users. However, the only way we’re going to get those changes is if we demand them.
Not all vectors are created equal
Because spyware is hard to capture, we don’t know precisely how Pegasus works. The forensic details we do have come from an extensive investigation conducted by Amnesty International’s technology group. They describe a sophisticated infection process that proved capable of infecting a fully-patched iPhone 12 running the latest version of Apple’s iOS (14.6).
Many attacks used “network injection” to redirect the victim to a malicious website. That technique requires some control of the local network, which makes it hard to deploy to remote users in other countries. A more worrying set of attacks appear to use Apple’s iMessage to perform “0-click” exploitation of iOS devices. Using this vector, NSO simply “throws” a targeted exploit payload at some Apple ID such as your phone number, and then sits back and waits for your zombie phone to contact its infrastructure.
This is really bad. While cynics are probably correct (for now) that we probably can’t shut down every avenue for compromise, there’s good reason to believe we can close down a vector for 0-interaction compromise. And we should try to do that.
What can we do to make NSO’s life harder?
What we know that these attacks take advantage of fundamental weaknesses in Apple iMessage: most critically, the fact that iMessage will gleefully parse all sorts of complex data received from random strangers, and will do that parsing using crappy libraries written in memory unsafe languages. These issues are hard to fix, since iMessage can accept so many data formats and has been allowed to sprout so much complexity over the past few years.
There is good evidence that Apple realizes the bind they’re in, since they tried to fix iMessage by barricading it behind a specialized “firewall” called BlastDoor. But firewalls haven’t been particularly successful at preventing targeted network attacks, and there’s no reason to think that BlastDoor will do much better. (Indeed, we know it’s probably not doing its job now.)
Adding a firewall is the cheap solution to the problem, and this is probably why Apple chose this as their first line of defense. But actually closing this security hole is going to require a lot more. Apple will have to re-write most of the iMessage codebase in some memory-safe language, along with many system libraries that handle data parsing. They’ll also need to widely deploy ARM mitigations like PAC and MTE in order to make exploitation harder. All of this work has costs and (more importantly) risks associated with it — since activating these features can break all sorts of things, and people with a billion devices can’t afford to have .001% of them crashing every day.
An entirely separate area is surveillance and detection: Apple already performs some remote telemetry to detect processes doing weird things. This kind of telemetry could be expanded as much as possible while not destroying user privacy. While this wouldn’t necessarily stop NSO, it would make the cost of throwing these exploits quite a bit higher — and make them think twice before pushing them out to every random authoritarian government.
It’s the scale, stupid
Critics are correct that fixing these issues won’t stop exploits. The problem that companies like Apple need to solve is not preventing exploits forever, but a much simpler one: they need to screw up the economics of NSO-style mass exploitation.
Targeted exploits have been around forever. What makes NSO special is not that they have some exploits. Rather: NSO’s genius is that they’ve done something that attackers were never incentivized to do in this past: democratize access to exploit technology. In other words, they’ve done precisely what every “smart” tech business is supposed to do: take something difficult and very expensive, and make it more accessible by applying the magic of scale. NSO is basically the SpaceX of surveillance.
But this scalability is not inevitable.
NSO can afford to maintain a 50,000 number target list because the exploits they use hit a particular “sweet spot” where the risk of losing an exploit chain — combined with the cost of developing new ones — is low enough that they can deploy them at scale. That’s why they’re willing to hand out exploitation to every idiot dictator — because right now they think they can keep the business going even if Amnesty International or CitizenLab occasionally catches them targeting some human rights lawyer.
But companies like Apple and Google can raise both the cost and risk of exploitation — not just everywhere, but at least on specific channels like iMessage. This could make NSO’s scaling model much harder to maintain. A world where only a handful of very rich governments can launch exploits (under very careful vetting and controlled circumstances) isn’t a great world, but it’s better than a world where any tin-pot authoritarian can cut a check to NSO and surveil their political opposition or some random journalist.
So how do we get to that world?
In a perfect world, US and European governments would wake up and realize that arming authoritarianism is really is bad for democracy — and that whatever trivial benefit they get from NSO is vastly outweighed by the very real damage this technology is doing to journalism and democratic governance worldwide.
But I’m not holding my breath for that to happen.
In the world I inhabit, I’m hoping that Ivan Krstić wakes up tomorrow and tells his bosses he wants to put NSO out of business. And I’m hoping that his bosses say “great: here’s a blank check.” Maybe they’ll succeed and maybe they’ll fail, but I’ll bet they can at least make NSO’s life interesting.
But Apple isn’t going to do any of this if they don’t think they have to, and they won’t think they have to if people aren’t calling for their heads. The only people who can fix Apple devices are Apple (very much by their own design) and that means Apple has to feel responsible each time an innocent victim gets pwned while using an Apple device. If we simply pat Apple on the head and say “gosh, targeted attacks are hard, it’s not your fault” then this is exactly the level of security we should expect to get — and we’ll deserve it.
Yesterday a bipartisan group of U.S. Senators introduced a new bill called the EARN IT act. On its face, the bill seems like a bit of inside baseball having to do with legal liability for information service providers. In reality, it represents a sophisticated and direct governmental attack on the right of Americans to communicate privately.
I can’t stress how dangerous this bill is, though others have tried. In this post I’m going to try to do my best to explain why it scares me.
“Going Dark”, and the background behind EARN IT
Over the past few years, the U.S. Department of Justice and the FBI have been pursuing an aggressive campaign to eliminate end-to-end encryption services. This is a category that includes text messaging systems like Apple’s iMessage, WhatsApp, Telegram, and Signal. Those services protect your data by encrypting it, and ensuring that the keys are only available to you and the person you’re communicating with. That means your provider, the person who hacks your provider, and (inadvertently) the FBI, are all left in the dark.
The government’s anti-encryption campaign has not been very successful. There are basically two reasons for this. First, people like communicating privately. If there’s anything we’ve learned over the past few years, it’s that the world is not a safe placefor your private information. You don’t have to be worried about the NSA spying on you to be worried that some hacker will steal your messages or email. In fact, this kind of hack occurs so routinely that there’s a popular website you can use to check if your accounts have been compromised.
The second reason that the government has failed to win hearts and minds is that providers like Facebook and Google and Microsoft also care very much about encryption. While some firms (*cough* Facebook and Google) do like to collect your data, even those companies are starting to realize that they hold way too much of it. This presents a risk for them, and increasingly it’s producing a backlash from their own customers. Companies like Facebook are realizing that if they can encrypt some of that data — such that they no longer have access to it — then they can make their customers happier and safer at the same time.
Governments have tried to navigate this impasse by asking for “exceptional access” systems. These are basically “backdoors” in cyrptographic systems that would allow providers to occasionally access user data with a warrant, but only when a specific criminal act has occurred. This is an exceptionally hard problem to get right, and many experts have written about why this is. But as hard as that problem is, it’s nothing compared to what EARN IT is asking for.
What is EARN IT, and how is it an attack on encryption?
Because the Department of Justice has largely failed in its mission to convince the public that tech firms should stop using end-to-end encryption, it’s decided to try a different tack. Instead of demanding that tech firms provide access to messages only in serious criminal circumstances and with a warrant, the DoJ and backers in Congress have decided to leverage concern around the distribution of child pornography, also known as child sexual abuse material, or CSAM.
I’m going to be a bit more blunt about this than I usually would be, but only because I think the following statement is accurate. The real goal here is to make it financially impossible for providers to deploy encryption.
Now let me be clear: the existence of CSAM is despicable, and represents a real problem for many providers. To address it, many file sharing and messaging services voluntarily perform scanning for these types of media. This involves checking images and videos against a database of known “photo hashes” and sending a report to an organization called NCMEC when one is found. NCMEC then passes these reports on to local authorities.
End-to-end encryption systems make CSAM scanning more challenging: this is because photo scanning systems are essentially a form of mass surveillance — one that’s deployed for a good cause — and end-to-end encryption is explicitly designed to prevent mass surveillance. So photo scanning while also allowing encryption is a fundamentally hard problem, one that providers don’t yet know how to solve.
All of this brings us to EARN IT. The new bill, out of Lindsey Graham’s Judiciary committee, is designed to force providers to either solve the encryption-while-scanning problem, or stop using encryption entirely. And given that we don’t yet know how to solve the problem — and the techniques to do it are basically at the research stage of R&D — it’s likely that “stop using encryption” is really the preferred goal.
EARN IT works by revoking a type of liability called Section 230 that makes it possible for providers to operate on the Internet, by preventing the provider for being held responsible for what their customers do on a platform like Facebook. The new bill would make it financially impossible for providers like WhatsApp and Apple to operate services unless they conduct “best practices” for scanning their systems for CSAM.
Since there are no “best practices” in existence, and the techniques for doing this while preserving privacy are completely unknown, the bill creates a government-appointed committee that will tell technology providers what technology they have to use. The specific nature of the committee is byzantine and described within the bill itself. Needless to say, the makeup of the committee, which can include as few as zero data security experts, ensures that end-to-end encryption will almost certainly not be considered a best practice.
So in short: this bill is a backdoor way to allow the government to ban encryption on commercial services. And even more beautifully: it doesn’t come out and actually ban the use of encryption, it just makes encryption commercially infeasible for major providers to deploy, ensuring that they’ll go bankrupt if they try to disobey this committee’s recommendations.
It’s the kind of bill you’d come up with if you knew the thing you wanted to do was unconstitutional and highly unpopular, and you basically didn’t care.
So why is EARN IT a terrible idea?
At the end of the day, we’re shockingly bad at keeping computer systems secure. This has expensive, trillion dollar costs to our economy, More than that, our failure to manage the security of data has intangible costs for our ability to function as a working society.
There are a handful of promising technologies that could solve this problem. End-to-end encryption happens to be one of those. It is, in fact, the single most promising technology that we have to prevent hacking, loss of data, and all of the harm that can befall vulnerable people because of it.
Right now the technology for securing our infrastructure isn’t mature enough that we can appoint a government-appointed committee to dictate what sorts of tech it’s “ok” for firms to provide. Maybe some day we’ll be there, but we’re years from the point where we can protect your data and also have Washington DC deciding what technology we can use to do it.
This means that yes, some technologies, like CSAM scanning, will have to be re-imagined and in some cases their effectiveness will be reduced. But tech firms have been aggressive about developing this technology on their own (see here for some of the advanced work Google has been doing using Machine Learning), and they will continue to do so. The tech industry has many problems, in many areas. But it doesn’t need Senators to tell it how to do this specific job, because people in California have kids too.
Even if you support the goals of EARN IT, remember: if the U.S. Senate does decide to tell Silicon Valley how to do their job — at the point of a liability gun — you can bet the industry will revert to doing the minimum possible. Why would the tech firms continue to invest in developing more sophisticated and expensive technology in this area, knowing that they could be mandated to deploy any new technology they invent, regardless of the cost?
And that will be the real outcome of this bill.
On cynicism
Over the past few years there has been a vigorous debate about the value of end-to-end encryption, and the demand for law enforcement to have access to more user data. I’ve participated in this debate, and while I’ve disagreed with many on the other side of it, I’ve always fundamentally respected their position.
EARN IT turns all of this on its head. It’s extremely difficult to believe that this bill stems from an honest consideration of the rights of child victims, and that this legislation is anything other than a direct attack on the use of end-to-end encryption.
My hope is that the Internet community and civil society will treat this proposal with the seriousness it deserves, and that we’ll see Senators rally behind a bill that actually protects children from abuse, rather than using those issues as a cynical attempt to bring about a “backdoor ban” on encryption.
A few weeks ago, U.S. Attorney General William Barr joined his counterparts from the U.K. and Australia to publish an open letter addressed to Facebook. The Barr letter represents the latest salvo in an ongoing debate between law enforcement and the tech industry over the deployment of end-to-end (E2E) encryption systems — a debate that will soon be moving into Congress.
The latest round is a response to Facebook’s recent announcement that it plans to extend end-to-end encryption to more of its services. It should hardly come as a surprise that law enforcement agencies are unhappy with these plans. In fact, governments aroundtheworld have been displeased by the increasing deployment of end-to-end encryption systems, largely because they fear losing access to the trove of surveillance data that online services and smartphone usage has lately provided them. The FBI even has a website devoted to the topic.
If there’s any surprise in the Barr letter, it’s not the government’s opposition to encryption. Rather, it’s the new reasoning that Barr provides to justify these concern. In pastepisodes, law enforcement has called for the deployment of “exceptional access” mechanisms that would allow law enforcement access to plaintext data. As that term implies, such systems are designed to treat data access as the exception rather than the rule. They would need to be used only in rare circumstances, such as when a judge issued a warrant.
The Barr letter appears to call for something much more agressive.
Rather than focusing on the need for exceptional access to plaintext, Barr focuses instead on the need for routine, automated scanning systems that can detect child sexual abuse imagery (or CSAI). From the letter:
More than 99% of the content Facebook takes action against – both for child sexual exploitation and terrorism – is identified by your safety systems, rather than by reports from users. …
We therefore call on Facebook and other companies to take the following steps:
Embed the safety of the public in system designs, thereby enabling you to continue to act against illegal content effectively with no reduction to safety, and facilitating the prosecution of offenders and safeguarding of victims;
To many people, Barr’s request might seem reasonable. After all, nobody wants to see this type of media flowing around the world’s communications systems. The ability to surgically detect it seems like it could do some real good. And Barr is correct that true that end-to-end encrypted messaging systems will make that sort of scanning much, much difficult.
What’s worrying in Barr’s letter is the claim we can somehow square this circle: that we can somehow preserve the confidentiality of end-to-end encrypted messaging services, while still allowing for the (highly non-exceptional) automated scanning for CSAI. Unfortunately, this turns out to be a very difficult problem — given the current state of our technology.
In the remainder of this post, I’m going to talk specifically about that problem. Since this might be a long discussion, I’ll briefly list the questions I plan to address:
How do automated CSAI scanning techniques work?
Is there a way to implement these techniques while preserving the security of end-to-end encryption?
Could these image scanning systems be subject to abuse?
I want to stress that this is a (high-level) technical post, and as a result I’m going to go out of my way not to discuss the ethical questions around this technology, i.e., whether or not I think any sort of routine image scanning is a good idea. I’m sure that readers will have their own opinions. Please don’t take my silence as an endorsement.
Let’s start with the basics.
How do automated CSAI scanning techniques work?
Facebook, Google, Dropbox and Microsoft, among others, currently perform various forms of automated scanning on images (and sometimes video) that are uploaded to their servers. The goal of these scans is to identify content that contains child sexual abuse imagery (resp. material), which is called CSAI (or CSAM). The actual techniques used vary quite a bit.
The most famous scanning technology is based on PhotoDNA, an algorithm that was developed by Microsoft Research and Dr. Hany Farid. The full details of PhotoDNA aren’t public — this point is significant — but at a high level, PhotoDNA is just a specialized “hashing” algorithm. It derives a short fingerprint that is designed to closely summarize a photograph. Unlike cryptographic hashing, which is sensitive to even the tiniest changes in a file, PhotoDNA fingerprints are designed to be robust even against complex image transformations like re-encoding or resizing.
The key benefit of PhotoDNA is that it gives providers a way to quickly scan incoming photos, without the need to actually deal with a library of known CSAI themselves. When a new customer image arrives, the provider hashes the file using PhotoDNA, and then compares the resulting fingerprint against a list of known CSAI hashes that are curated by the National Center for Missing and Exploited Children (NCMEC). If a match is found, the photo gets reported to a human, and ultimately to NCMEC or law enforcement.
PhotoDNA hashing (source: Microsoft.) Note that the hashes aren’t identical. PhotoDNA uses a similarity metric to determine whether an image is a likely match.
The obvious limitation of the PhotoDNA approach is that it can only detect CSAI images that are already in the NCMEC database. This means it only finds existing CSAI, not anything new. (And yes, even with that restriction it does find a lot of it.)
To address that problem, Google recently pioneered a new approach based on machine learning techniques. Google’s system is based on a deep neural network, which is trained on a corpus of known CSAI examples. Once trained — a process that is presumably ongoing and continuous — the network can be applied against fresh images in to flag media that has similar characteristics. As with the PhotoDNA approach, images that score highly can be marked for further human review. Google even provides an API that authorized third parties can use for this purpose.
Both of these approaches are very different. But they have an obvious commonality: they only work if providers to have access to the plaintext of the images for scanning, typically at the platform’s servers. End-to-end encrypted (E2E) messaging throws a monkey wrench into these systems. If the provider can’t read the image file, then none of these systems will work.
For platforms that don’t support E2E — such as (the default mode) of Facebook Messenger, Dropbox or Instagram — this isn’t an issue. But popular encrypted messaging systems like Apple’s iMessage and WhatsApp are already “dark” to those server-side scanning technologies, and presumably future encrypted systems will be too.
Is there some way to support image scanning while preserving the ability to perform E2E encryption?
Some experts have proposed a solution to this problem: rather than scanning images on the server side, they suggest that providers can instead push the image scanning out to the client devices (i.e., your phone), which already has the cleartext data. The client device can then perform the scan, and report only images that get flagged as CSAI. This approach removes the need for servers to see most of your data, at the cost of enlisting every client device into a distributed surveillance network.
The idea of conducting image recognition locally is not without precedent. Some device manufacturers (notably Apple) have already moved their neural-network-based image classification onto the device itself, specifically to eliminate the need to transmit your photos out to a cloud provider.
Local image classification on an iPhone.
Unfortunately, while the concept may be easy to explain, actually realizing it for CSAI-detection immediately runs into a very big technical challenge. This is the result of a particular requirement that seems to be present across all existing CSAI scanners. Namely: the algorithms are all secret.
While I’ve done my best to describe how PhotoDNA and Google’s techniques work, you’ll note that my descriptions were vague. This wasn’t due to some lack of curiosity on my part. It reflects the fact that all thedetails of these algorithms — as well as the associated data they use, such as the database of image hashes curated by NCMEC and any trained neural network weights — are kept under strict control by the organizations that manage them. Even the final PhotoDNA algorithm, which is ostensibly the output of an industry-academic collaboration, is not public.
While the organizations don’t explicitly state this, the reason for this secrecy seems to be a simple one: thesetechnologies are probably veryfragile.
Presumably, the concern is that criminals who gain free access to these algorithms and databases might be able to subtly modify their CSAI content so that it looks the same to humans but no longer triggers detection algorithms. Alternatively, some criminals might just use this access to avoid transmitting flagged content altogether.
This need for secrecy makes client-side scanning fundamentally much more difficult. While it might be possible to cram Google’s neural network onto a user’s phone, it’s hugely more difficult to do so on a billion different phones, while also ensuring that nobody obtains a copy of it.
Can fancy cryptography help here?
The good news is that cryptographers have spent a lot of time thinking about this exact sort of problem: namely, finding ways to allow mutually-distrustful parties to jointly compute over data that each, individually, wants to keep secret. The name for this class of technologies is securemulti-party computation, or MPC for short.
CSAI scanning is exactly the sort of application you might look to MPC to implement. In this case, both client and service provider have a secret. The client has an image it wants to keep confidential, and the server has some private algorithms or neural network weights.* All the parties want in the end is a “True/False” output from the detection algorithm. If the scanner reports “False”, then the image can remain encrypted and hidden from the service provider.
So far this seems simple. The devil is in the (performance) details.
While general MPC (and two-party, or 2PC) techniques have long existed, some recent papers have investigated the costs of implementing secure image classification via neural networks using these techniques. (This approach is much more reminiscent of the Google technique, rather than PhotoDNA, which would have its own complexities. See notes below.***)
The papers in question (e.g., CryptoNets, MiniONN, Gazelle, Chameleon and XONN) employ sophisticated cryptographic tools such as leveled fully-homomorphic encryption,partially-homomorphic encryption, and circuit garbling, in many cases making specific alterations to the neural network structure in order to allow for efficient evaluation. The tools are also interactive: a client and server must exchange data in order to perform the classification task, and the result appears only after this exchange of data.
All of this work is remarkable, and really deserves a much more in-depth discussion. Unfortunately I’m only here to answer a basic question — are these techniques practical yet? To do that I’m going to do a serious disservice to all this excellent research. Indeed, the current state of the art can largely be summarized by following table from one of the most recent papers:
Left: runtime and communication bandwidth costs for two-party secure evaluation of an image classifier on the CIFAR-10 dataset, measured for several MPC frameworks (source: XONN paper). Right: each image is a 32×32 color image (examples at right) divided into ten categories, and the neural network used here comprises 9 convolution layers, 3 max-pooling layers and 1 fully-connected layer (see paper for details). Red text is mine.
What this table shows is the bandwidth and computational cost of securely computing a single image classification using several of the tools I mentioned above. A key thing to note here is that the images to be classified are fairly simple — each is a 32×32-bit pixel color thumbnail. And while I’m no judge of such things, the neural networks architectures used for the classification also seem relatively simple. (At very least, it’s hard to imagine that a CSAI detection neural network is going to be that much less complex.)
Despite the relatively small size of these problem instances, the overhead of using MPC turns out to be pretty spectacular. Each classification requires several seconds to minutes of actual computation time on a reasonably powerful machine — not a trivial cost, when you consider how many images most providers transmit every second. But the computational costs pale next to the bandwidth cost of each classification. Even the most efficient platform requires the two parties to exchange more than 1.2 gigabytes of data.**
Hopefully you’ve paid for a good data plan.
Now this is just one data point. And the purpose here is certainly not to poo-poo the idea that MPC/2PC could someday be practical for image classification at scale. My point here is simply that, at present, doing this sort of classification efficiently (and privately) remains firmly in the domain of “hard research problems to be solved”, and will probably continue to be there for at least several more years. Nobody should bank on using this technology anytime soon. So client-side classification seems to be off the table for the near future.
But let’s imagine it does become efficient. There’s one more question we need to consider.
Are (private) scanning systems subject to abuse?
As I noted above, I’ve made an effort here to dodge the ethicaland policy questions that surround client-side CSAI scanning technologies. I’ve done this not because I back the idea, but because these are complicated questions — and I don’t really feel qualified to answer them.
Still, I can’t help but be concerned about two things. First, that today’s CSAI scanning infrastructure represents perhaps the most powerful and ubiquitous surveillance technology ever to be deployed by a democratic society. And secondly, that the providers who implement this technology are so dependent on secrecy.
This raises the following question. Even if we accept that everyone involved today has only the best intentions, how can we possibly make sure that everyone stays honest?
Unfortunately, simple multi-party computation techniques, no matter how sophisticated, don’t really answer this question. If you don’t trust the provider, and the provider chooses the (hidden) algorithm, then all the cryptography in the world won’t save you.
Abuse of a CSAI scanning system might range from outsider attacks by parties who generate CSAI that simply collides with non-CSAI content; to insider attacks that alter the database to surveil specific content. These concerns reach fever pitch if you imaginea corrupt government or agency forcing providers to alter their algorithms to abuse this capability. While that last possibility seems like a long shot in this country today, it’s not out of bounds for the whole world. And systems designed for surveillance should contemplate their own misuse.
Which means that, ultimately, these systems will need some mechanism to ensure that service providers are being honest. Right now I don’t quite know how to do this. But someone will have to figure it out, long before these systems can be put into practice.
Notes:
* Most descriptions of MPC assume that the function (algorithm) to be computed is known to both parties, and only the inputs (data) is secret. Of course, this can be generalized to secret algorithms simply by specifying the algorithm as a piece of data, and computing an algorithm that interprets and executes that algorithm. In practice, this type of “general computation” is likely to be pretty costly, however, and so there would be a huge benefit to avoiding it.
** It’s possible that this cost could be somewhat amortized across many images, though it’s not immediately obvious to me that this works for all of the techniques.
*** Photo hashing might or might not feasible to implement using MPC/2PC. The relatively limited information about PhotoDNA describes is as including a number of extremely complex image manipulation phases, followed by a calculation that occurs on subregions of the image. Some sub-portions of this operation might be easy to move into an MPC system, while others could be left “in the clear” for the client to compute on its own. Unfortunately, it’s difficult to know which portions of the algorithm the designers would be willing to reveal, which is why I can’t really speculate on the complexity of such a system.
Yesterday I happened upon a Wired piece by Steven Levy that covers Ray Ozzie’s proposal for “CLEAR”. I’m quoted at the end of the piece (saying nothing much), so I knew the piece was coming. But since many of the things I said to Levy were fairly skeptical — and most didn’t make it into the piece — I figured it might be worthwhile to say a few of them here.
Ozzie’s proposal is effectively a key escrow system for encrypted phones. It’s receiving attention now due to the fact that Ozzie has a stellar reputation in the industry, and due to the fact that it’s been lauded by law enforcement (and some famous people like Bill Gates). Ozzie’s idea is the just the latest bit of news in this second edition of the “Crypto Wars”, in which the FBI and various law enforcement agencies have been arguing for access to end-to-end encryption technologies — like phone storage and messaging — in the face of pretty strenuous opposition by (most of) the tech community.
In this post I’m going to sketch a few thoughts about Ozzie’s proposal, and about the debate in general. Since this is a cryptography blog, I’m mainly going to stick to the technical, and avoid the policy details (which are substantial). Also, since the full details of Ozzie’s proposal aren’t yet public — some are explained in the Levy piece and some in this patent — please forgive me if I get a few details wrong. I’ll gladly correct.
[Note: I’ve updated this post in several places in response to some feedback from Ray Ozzie. For the updated parts, look for the *. Also, Ozzie has posted some slides about his proposal.]
How to Encrypt a Phone
The Ozzie proposal doesn’t try tackle every form of encrypted data. Instead it focuses like a laser on the simple issue of encrypted phone storage. This is something that law enforcement has been extremely concerned about. It also represents the (relatively) low-hanging fruit of the crypto debate, for essentially two reasons: (1) there are only a few phone hardware manufacturers, and (2) access to an encrypted phone generally only takes place after law enforcement has gained physical access to it.
I’ve written about the details of encrypted phone storage in a couple of previousposts. A quick recap: most phone operating systems encrypt a large fraction of the data stored on your device. They do this using an encryption key that is (typically) derived from the user’s passcode. Many recent phones also strengthen this key by “tangling” it with secrets that are stored within the phone itself — typically with the assistance of a secure processor included in the phone. This further strengthens the device against simple password guessing attacks.
The upshot is that the FBI and local law enforcement have not — until very recently (more on that further below) — been able to obtain access to many of the phones they’ve obtained during investigation. This is due the fact that, by making the encryption key a function of the user’s passcode, manufacturers like Apple have effectively rendered themselves unable to assist law enforcement.
The Ozzie Escrow Proposal
Ozzie’s proposal is called “Clear”, and it’s fairly straightforward. Effectively, it calls for manufacturers (e.g., Apple) to deliberatelyput themselves back in the loop. To do this, Ozzie proposes a simple form of key escrow (or “passcode escrow”). I’m going to use Apple as our example in this discussion, but obviously the proposal will apply to other manufacturers as well.
Ozzie’s proposal works like this:
Prior to manufacturing a phone, Apple will generate a public and secret “keypair” for some public key encryption scheme. They’ll install the public key into the phone, and keep the secret key in a “vault” where hopefully it will never be needed.
When a user sets a new passcode onto their phone, the phone will encrypt a passcode under the Apple-provided public key. This won’t necessarily be the user’s passcode, but it will be an equivalent passcode that can unlock the phone.* It will store the encrypted result in the phone’s storage.
In the unlikely event that the FBI (or police) obtain the phone and need to access its files, they’ll place the phone into some form of law enforcement recovery mode. Ozzie describes doing this with some special gesture, or “twist”. Alternatively, Ozzie says that Apple itself could do something more complicated, such as performing an interactive challenge/response with the phone in order to verify that it’s in the FBI’s possession.
The phone will now hand the encrypted passcode to law enforcement. (In his patent, Ozzie suggests it might be displayed as a barcode on a screen.)
The law enforcement agency will send this data to Apple, who will do a bunch of checks (to make sure this is a real phone and isn’t in the hands of criminals). Apple will access their secret key vault, and decrypt the passcode. They can then send this back to the FBI.
Once the FBI enters this code, the phone will be “bricked”. Let me be more specific: Ozzie proposes that once activated, a secure chip inside the phone will now permanently “blow” several JTAG fuses monitored by the OS, placing the phone into a locked mode. By reading the value of those fuses as having been blown, the OS will never again overwrite its own storage, will never again talk to any network, and will become effectively unable to operate as a normal phone again.
When put into its essential form, this all seems pretty simple. That’s because it is. In fact, with the exception of the fancy “phone bricking” stuff in step (6), Ozzie’s proposal is a straightforward example of key escrow — a proposal that people have been making in various guises for many years. The devil is always in the details.
A vault of secrets
If we picture how the Ozzie proposal will change things for phone manufacturers, the most obvious new element is the key vault. This is not a metaphor. It literally refers to a giant, ultra-secure vault that will have to be maintained individually by different phone manufacturers. The security of this vault is no laughing matter, because it will ultimately store the master encryption key(s) for every single device that manufacturer ever makes. For Apple alone, that’s about a billion active devices.
Does this vault sound like it might become a target for organized criminals and well-funded foreign intelligence agencies? If it sounds that way to you, then you’ve hit on one of the most challenging problems with deploying key escrow systems at this scale. Centralized key repositories — that can decrypt every phone in the world — are basically a magnet for the sort of attackers you absolutely don’t want to be forced to defend yourself against.
So let’s be clear. Ozzie’s proposal relies fundamentally on the ability of manufacturers to secure extremely valuable key material for a massive number of devices against the strongest and most resourceful attackers on the planet. And not just rich companies like Apple. We’re also talking about the companies that make inexpensive phones and have a thinner profit margin. We’re also talking about many foreign-owned companies like ZTE and Samsung. This is key material that will be subject to near-constant access by the manufacturer’s employees, who will have to access these keys regularly in order to satisfy what may be thousands of law enforcement access requests every month.
If ever a single attacker gains access to that vault and is able to extract, a few “master” secret keys (Ozzie says that these master keys will be relatively small in size*) then the attackers will gain unencrypted access to every device in the world. Even better: if the attackers can do this surreptitiously, you’ll never know they did it.
Now in fairness, this element of Ozzie’s proposal isn’t really new. In fact, this key storage issue an inherent aspect of all massive-scale key escrow proposals. In the general case, the people who argue in favor of such proposals typically make two arguments:
We already store lots of secret keys — for example, software signing keys — and things works out fine. So this isn’t really a new thing.
It is certainly true that software manufacturers do store secret keys, with varying degrees of success. For example, many software manufacturers (including Apple) store secret keys that they use to sign software updates. These keys are generally locked up in various ways, and are accessed periodically in order to sign new software. In theory they can be stored in hardened vaults, with biometric access controls (as the vaults Ozzie describes would have to be.)
But this is pretty much where the similarity ends. You don’t have to be a technical genius to recognize that there’s a world of difference between a key that gets accessed once every month — and can be revoked if it’s discovered in the wild — and a key that may be accessed dozens of times per day and will be effectively undetectable if it’s captured by a sophisticated adversary.
Moreover, signing keys leak all the time. The phenomenon is so common that journalists have given it a name: it’s called “Stuxnet-style code signing”. The name derives from the fact that the Stuxnet malware — the nation-state malware used to sabotage Iran’s nuclear program — was authenticated with valid code signing keys, many of which were (presumably) stolen from various software vendors. This practice hasn’t remained with nation states, unfortunately, and has now become common in retail malware.
The folks who argue in favor of key escrow proposals generally propose that these keys can be stored securely in special devices called Hardware Security Modules (HSMs). Many HSMs are quite solid. They are not magic, however, and they are certainly not up to the threat model that a massive-scale key escrow system would expose them to. Rather than being invulnerable, they continue to cough up vulnerabilities like this one. A single such vulnerability could be game-over for any key escrow system that used it.
In some follow up emails, Ozzie suggests that keys could be “rotated” periodically, ensuring that even after a key compromise the system could renew security eventually. He also emphasizes the security mechanisms (such as biometric access controls) that would be present in such a vault. I think that these are certainly valuable and necessary protections, but I’m not convinced that they would be sufficient.
Assume a secure processor
Let’s suppose for a second that an attacker does get access to the Apple (or Samsung, or ZTE) key vault. In the section above I addressed the likelihood of such an attack. Now let’s talk about the impact.
Ozzie’s proposal has one significant countermeasure against an attacker who wants to use these stolen keys to illegally spy on (access) your phone. Specifically, should an attacker attempt to illegally access your phone, the phone will be effectively destroyed. This doesn’t protect you from having your files read — that horse has fled the stable — but it should alert you to the fact that something fishy is going on. This is better than nothing.
This measure is pretty important, not only because it protects you against evil maid attacks. As far as I can tell, this protection is pretty much the only measure by which theft of the master decryption keys might ever be detected. So it had better work well.
The details on how this might work aren’t very clear in Ozzie’s patent, but the Wired article describes it as follows. This quote to repeat Ozzie’s presentation at Columbia University:
What Ozzie appears to describe here is a secure processor contained within every phone. This processor would be capable if securely and irreversibly enforcing that once law enforcement has accessed a phone, that phone could no longer be placed into an operational state.
My concern with this part of Ozzie’s proposal is fairly simple: this processor does not currently exist. To explain why this, let me tell a story.
Back in 2013, Apple began installing a secure processor in each of their phones. While this secure processor (called the Secure Enclave Processor, or SEP) is not exactly the same as the one Ozzie proposes, the overall security architecture seems very similar.
One main goal of Apple’s SEP was to limit the number of passcode guessing attempts that a user could make against a locked iPhone. In short, it was designed to keep track of each (failed) login attempt and keep a counter. If the number of attempts got too high, the SEP would make the user wait a while — in the best case — or actively destroy the phone’s keys. This last protection is effectively identical to Ozzie’s proposal. (With some modest differences: Ozzie proposes to “blow fuses” in the phone, rather than erasing a key; and he suggests that this event would triggered by entry of a recovery passcode.*)
For several years, the SEP appeared to do its job fairly effectively. Then in 2017, everything went wrong. Two firms, Cellebrite and Grayshift, announced that they had products that effectively unlocked every single Applephone, without any need to dismantle the phone. Digging into the details of this exploit, it seems very clear that both firms — working independently — have found software exploits that somehow disable the protections that are supposed to be offered by the SEP.
The cost of this exploit (to police and other law enforcement)? About $3,000-$5,000 per phone. Or (if you like to buy rather than rent) about $15,000. Aso, just to add an element of comedy to the situation, the GrayKey source code appears to have recently been stolen. The attackers are extorting the company for two Bitcoin. Because 2018. (🤡👞)
Let me sum this up my point in case I’m not beating you about the head quite enough:
The richest and most sophisticated phone manufacturer in the entire worldtried to build a processor that achieved goals similar to those Ozzie requires. And as of April 2018, after five years of trying, they have been unable to achieve this goal — a goal that is critical to the security of the Ozzie proposal as I understand it.
Now obviously the lack of a secure processor today doesn’t mean such a processor will never exist. However, let me propose a general rule: if your proposal fundamentally relies on a secure lock that nobody can ever break, then it’s on you to show me how to build that lock.
Conclusion
While this mainly concludes my notes about on Ozzie’s proposal, I want to conclude this post with a side note, a response to something I routinely hear from folks in the law enforcement community. This is the criticism that cryptographers are a bunch of naysayers who aren’t trying to solve “one of the most fundamental problems of our time”, and are instead just rejecting the problem with lazy claims that it “can’t work”.
As a researcher, my response to this is: phooey.
Cryptographers — myself most definitely included — love to solve crazy problems. We do this all the time. You want us to deploy a new cryptocurrency? No problem! Want us to build a system that conducts a sugar-beet auction using advanced multiparty computation techniques? Awesome. We’re there. No problem at all.
But there’s crazy and there’s crazy.
The reason so few of us are willing to bet on massive-scale key escrow systems is that we’ve thought about it and we don’t think it will work. We’ve looked at the threat model, the usage model, and the quality of hardware and software that exists today. Our informed opinion is that there’s no detection system for key theft, there’s no renewability system, HSMs are terrifically vulnerable (and the companies largely staffed with ex-intelligence employees), and insiders can be suborned. We’re not going to put the data of a few billion people on the line an environment where we believe with high probability that the system will fail.
Maybe that’s unreasonable. If so, I can live with that.
Yesterday, David Benjamin posted a pretty esoteric note on the IETF’s TLS mailing list. At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and some of my colleagues, however, it was like that scene in X-Files where Mulder and Scully finally learn that aliens are real.
Those fossilized printers confirmed a theory we’d developed in 2014, but had been unable to prove: namely, the existence of a specific feature in RSA’s BSAFE TLS library called “Extended Random” — one that we believe to be evidence of a concerted effort by the NSA to backdoor U.S. cryptographic technology.
Before I get to the details, I want to caveat this post in two different ways. First, I’ve written about the topic of cryptographic backdoors way too much. In 2013, the Snowden revelations revealed the existence of a campaign to sabotage U.S. encryption systems. Since that time, cryptographers have spent thousands of hours identifying, documenting, and trying to convince people to care about these backdoors. We’re tired and we want to do more useful things.
The second caveat covers a problem with any discussion of cryptographic backdoors. Specifically, you never really get absolute proof. There’s always some innocent or coincidental explanation that could sort of fit the evidence — maybe it was all a stupid mistake. So you look for patterns of unlikely coincidences, and use Occam’s razor a lot. You don’t get a Snowden every day.
With all that said, let’s talk about Extended Random, and what this tells us about the NSA. First some background.
Dual_EC_DRBG and RSA BSAFE
To understand the context of this discovery, you need to know about a standard called Dual EC DRBG. This was a proposed random number generator that the NSA developed in the early 2000s. It was standardized by NIST in 2007, and later deployed in some important cryptographic products — though we didn’t know it at the time.
Dual EC has a major problem, which is that it likely contains a backdoor. This was pointed out in 2007 by Shumow and Ferguson, and effectively confirmed by the Snowden leaks in 2013. Drama ensued. NIST responded by pulling the standard. (For an explainer on the Dual EC backdoor, see here.)
Somewhere around this time the world learned that RSA Security had made Dual EC the default random number generator in their popular cryptographic library, which was called BSAFE. RSA hadn’t exactly kept this a secret, but it was such a bonkers thing to do that nobody (in the cryptographic community) had known. So for years RSA shipped their library with this crazy algorithm, which made its way into all sorts of commercial devices.
The RSA drama didn’t quite end there, however. In late 2013, Reuters reported that RSA had taken $10 million to backdoor their software. RSA sort of denies this. Or something. It’s not really clear.
Regardless of the intention, it’s known that RSA BSAFE did incorporate Dual EC. This could have been an innocent decision, of course, since Dual EC was a NIST standard. To shed some light on that question, in 2014 my colleagues and I decided to reverse-engineer the BSAFE library to see if it the alleged backdoor in Dual EC was actually exploitable by an attacker like the NSA. We figured that specific engineering decisions made by the library designers could be informative in tipping the scales one way or the other.
It turns out they were.
Extended Random
In the course of reverse engineering the Java version of BSAFE, we discovered a funny inclusion. Specifically, we found that BSAFE supports a non-standard extension to the TLS protocol called “Extended Random”.
The Extended Random extension is an IETF Draft proposed by an NSA employee named Margaret Salter (at some point the head of NSA’s Information Assurance Directorate, which worked on “defensive” crypto for DoD) along with Eric Rescorla as a contractor. (Eric was very clearly hired to develop a decent proposal that wouldn’t hurt TLS, and would primarily be used on government machines. The NSA did not share their motivations with him.)
It’s important to note that Extended Random by itself does not introduce any cryptographic vulnerabilities. All it does is increase the amount of random data (“nonces”) used in a TLS protocol connection. This shouldn’t hurt TLS at all, and besides it was largely intended for U.S. government machines.
The only thing that’s interesting about Extended Random is what happens when that random data is generated using the Dual EC algorithm. Specifically, this extra data acts as “rocket fuel”, significantly increasing the efficiency of exploiting the Dual EC backdoor to decrypt TLS connections.
In short, if you’re an agency like the NSA that’s trying to use Dual EC as a backdoor to intercept communications, you’re muchbetter off with a system that uses both Dual EC DRBG and Extended Random. Since Extended Random was never standardized by the IETF, it shouldn’t be in any systems. In fact, to the best of our knowledge, BSAFE is the only system in the world that implements it.
In addition to Extended Random, we discovered a variety of features that, combined with the Dual EC backdoor, could make RSA BSAFE fairly easy to exploit. But Extended Random is by far the strangest and hardest to justify.
So where did this standard come from? For those who like technical mysteries, it turns out that Extended Random isn’t the only funny-smelling proposal the NSA made. It’s actually one of four failed IETF proposals made by NSA employees, or contractors who work closely with the NSA, all of which try to boost the amount of randomness in TLS. Thomas Ptacek has a mind-numbingly detailed discussion of these proposals and his view of their motivation in this post.
Oh my god I never thought spies could be so boring. What’s the new development?
Despite the fact that we found Extended Random in RSA BSAFE (a free version we downloaded from the Internet), a fly in the ointment was that it didn’t actually seem to be enabled. That is: the code was there but the switches to enable it were hard-coded to “off”.
This kind of put a wrench in our theory that RSA might have included Extended Random to make BSAFE connections more exploitable by the NSA. There might be some commercial version of BSAFE out there with this code active, but we were never able to find it or prove it existed. And even worse, it might appear only in some special “U.S. government only” version of BSAFE, which would tend to undermine the theory that there was something intentional about including this code — after all, why would the government spy on itself?
Which finally brings us to the news that appeared on the TLS mailing list the other day. It turns out that certain Canon printers are failing to respond properly to connections made using the new version of TLS (which is called 1.3), because they seem to have implemented an unauthorized TLS extension using the same number as an extension that TLS 1.3 needs in order to operate correctly. Here’s the relevant section of David’s post:
The web interface on some Canon printers breaks with 1.3-capable ClientHello messages. We have purchased one and confirmed this with a PIXMA MX492. User reports suggest that it also affects PIXMA MG3650 and MX495 models. It potentially affects a wide range of Canon printers.
These printers use the RSA BSAFE library to implement TLS and this library implements the extended_random extension and assigns it number 40. This collides with the key_share extension and causes 1.3-capable handshakes to fail.
So in short, this news appears to demonstrate that commercial (non-free) versions of RSA BSAFE did deploy the Extended Random extension, and made it active within third-party commercial products. Moreover, they deployed it specifically to machines — specifically off-the-shelf commercial printers — that don’t seem to be reserved for any kind of special government use.
(If these turn out to be special Department of Defense printers, I will eat my words.)
Ironically, the printers are now the only thing that still exhibits the features of this (now deprecated) version of BSAFE. This is not because the NSA was targeting printers. Whatever devices they were targeting are probably gone by now. It’s because printer firmware tends to be obsolete and yet highly persistent. It’s like a remote pool buried beneath the arctic circle that preserves software species that would otherwise vanish from the Internet.
Which brings us to the moral of the story: not only are cryptographic backdoors a terrible idea, but they totally screw up the assigned numbering system for future versions of your protocol.
Actually no, that’s a pretty useless moral. Instead, let’s just say that you can deploy a cryptographic backdoor, but it’s awfully hard to control where it will end up.


























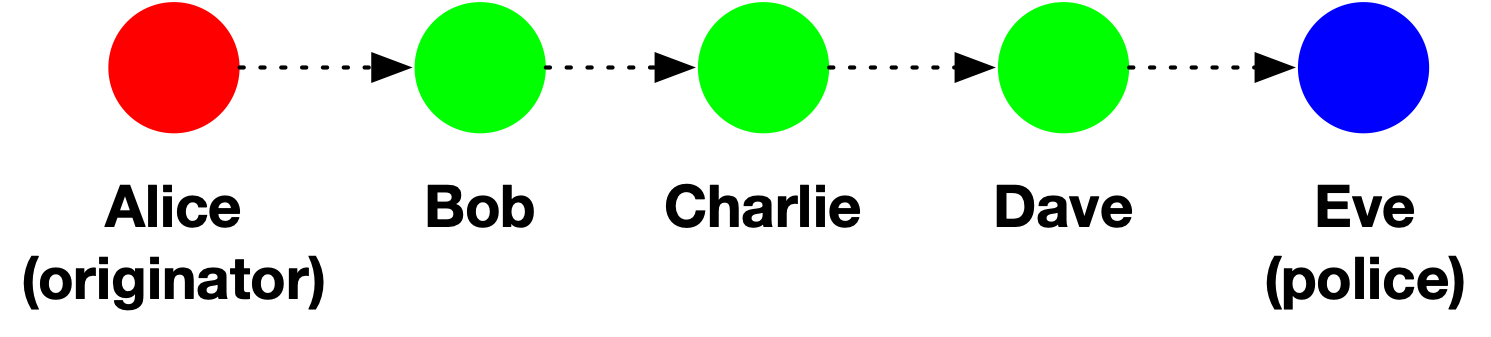
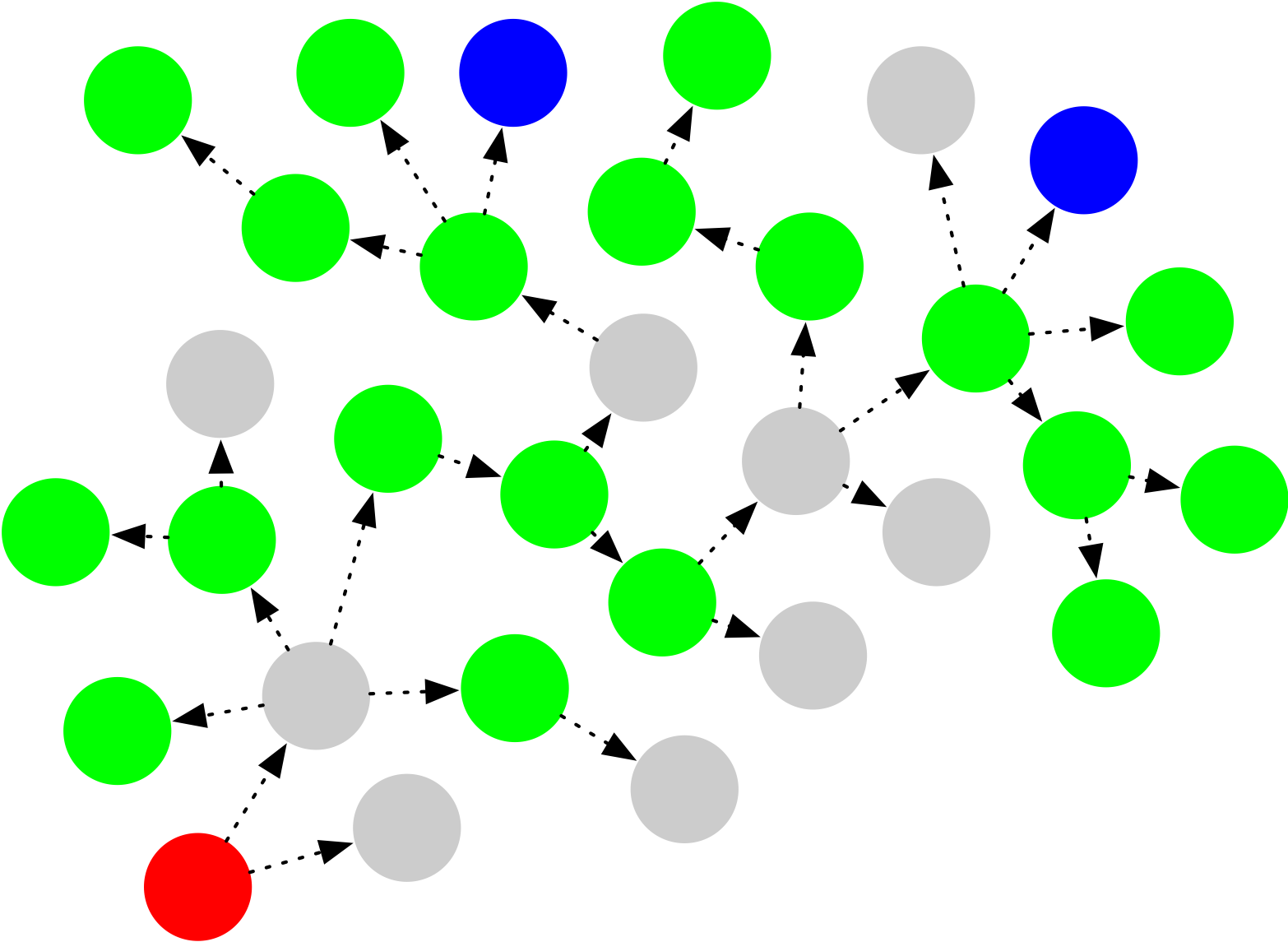
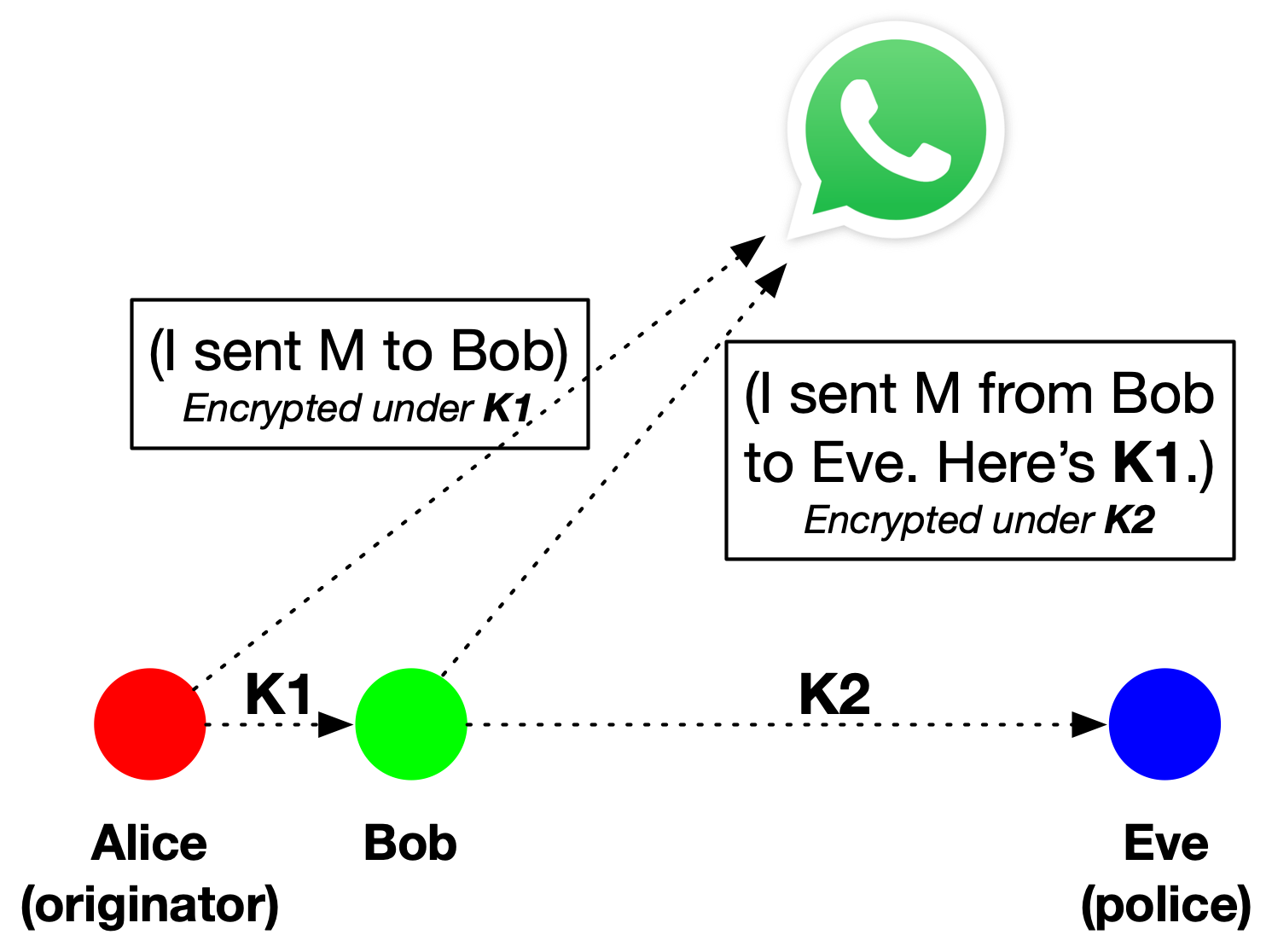






 much), so I knew the piece was coming. But since many of the things I said to Levy were fairly skeptical — and most didn’t make it into the piece — I figured it might be worthwhile to say a few of them here.
much), so I knew the piece was coming. But since many of the things I said to Levy were fairly skeptical — and most didn’t make it into the piece — I figured it might be worthwhile to say a few of them here.
 At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and
At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and 