
Trigger warning: incredibly wonky theoretical cryptography post (written by a non-theorist)! Also, this will be in two parts. I plan to be back with some more thoughts on practical stuff, like cloud backup, in the near future.
If you’ve read my blog over the years, you should understand that I have basically two obsessions. One is my interest in building “practical” schemes that solve real problems that come up in the real world. The other is a weird fixation on the theoretical models that underpin (the security of) many of those same schemes. In particular, one of my favorite bugaboos is a particular model, or “heuristic”, called the random oracle model (ROM) — essentially a fancy way to think about hash functions.
Along those lines, my interest was recently piqued by a new theoretical result by Khovratovich, Rothblum and Soukhanov entitled “How to Prove False Statements: Practical Attacks on Fiat-Shamir.” This is a doozy of a paper! It touches nearly every sensitive part of my brain: it urges us towards a better understanding of our theoretical models for proving security of protocols. It includes the words “practical” and “attacks” in the title! And most importantly it demonstrates a real (albeit wildly contrived) attack on the kinds of “ZK” (note: not actually ZK, more on that later) “proving systems” that we are now using inside of real systems like blockchains.
I confess I am still struggling hard to figure out how I “feel” about this result. I understand how odd it seems that my feelings should even matter: this is science after all. Shouldn’t the math speak for itself? The worrying thing is that, in this case, I don’t think it does. In fact, this is what I find most fundamentally exciting about the result: it really does matter how we think about it. (Here I should add that we don’t all think the same say. My theory-focused PhD student Aditya Hegde has been vigorously debating me on my interpretation — and mostly winning on points. So anything non-stupid I say here is probably due to him.)
Oh yes, and I should also mention that there are billions and billions of dollars riding on these questions? I’m not being dramatic. This is really true.
I mentioned that this post is going to be long and wonky, that’s just unavoidable. But I promise it will be fun. (Ok, I can’t even promise that.) Screw it, let’s go.
The shortest background ever (and it will still be really long)
If you’ve read this blog over the long term, you know that I’m obsessed with one particular “trick” we use in proving our schemes secure. This trick is known as the random oracle model, and it’s one of the worst (or best) things to happen to cryptography.
Let me try to break this down as quickly as I can. In cryptography we have a tendency to use an ingredient called a cryptographic hash function. These functions take in a (potentially) long string and output a short digest. In cryptography courses, we present these functions along with various “security definitions” they should meet, properties like collision resistance, pre-image resistance and so on. But out in the real world most schemes require much stronger assumptions in order to be proven secure. When we argue for the security of these schemes, we often demand that our hash functions be even stronger: we require that they must behave like random functions.
If you’re not sure what a random function is, you can read about it in depth here. You should just trust that it is a very strong and beautiful requirement for a hash function! But there is a fly in the ointment. Real-world hash functions cannot possibly be random functions. Specifically: concrete hash functions like SHA-2, SHA-3 etc. are characterized by the inevitable requirement that they possess compact, efficient algorithms that can compute their output. Random functions (of any usefulness) must not. Indeed, the most efficient description of a random function is essentially a giant (i.e., exponentially-sized in the length of the inputs to the function) lookup table. These functions cannot even be computed efficiently, because they’re so big.
So when we analyze schemes where hash functions must behave in this manner, we have to do some pretty suspicious things. The approach we take is bonkers. First, we analyze our schemes inside of an artificial “model” where efficient (polynomial-time) participants can somehow evaluate random functions, despite the fact that this is literally impossible. To make this apparent contradiction work, we “yank” the hash function logic into a magical box that lives outside that participants — this includes both honest participants in a protocol, as well as any adversaries who try to attack the scheme — and we force everyone to call out to that functionality. This new thing is called a “random oracle.”
One weird implication of this approach is that no party can ever know the code of the “hash function” they’re evaluating. They literally cannot know it, since in this model the hash function is comprised of an enormous random lookup table that’s much too big for anyone to actually know! This may seem like a not-very big deal, but it will be exceptionally important going forward.
Of course in the real world we do not have random oracles. I guess we could set up a special server that everyone in the world can call out to in order to compute their hash function values! But we don’t do that because it’s ridiculous. When want to deploy a scheme IRL, we do a terrible thing: we “instantiate the random oracle” by replacing it with an actual hash function like SHA-2 or SHA-3. Then everyone goes on their merry way, hoping that the security proof still has some meaning.
Let me be abundantly clear about this last part. From a theoretical perspective, any scheme “proven secure” in the random oracle model ceases to be provably secure the instant you replace the random oracle with a real (concrete) hash function like SHA-3. Put differently, it’s the equivalent of replacing your engine oil with Crisco. Your car may still run, but you are absolutely voiding the warranty.
But, but, but — and I stress the stammer — voiding your warranty does not mean your engine will become broken! In most of the places where we’ve done this awful random oracle “instantiation” thing (let’s be honest: almost every real-world deployed protocol) the instantiated protocols all seemed to work just fine.
(To be sure: we have certainly seen cryptographic protocols break down due to broken hash functions! But these breaks are almost always due to obvious hash function bugs that anyone can see, such as meaningful collisions being found. They were not magical breaks that come about because you rubbed the “theory lamp” wrong. As far as we can tell, in most cases if you use a “good enough” secure hash function to instantiate the random oracle, everything mostly goes fine.)
Now it should be noted that theoreticians were not happy about this cavalier approach. In the late 1990s, they rebelled and demonstrated something shocking: it was possible to build “contrived” cryptographic schemes that were provably secure in the random oracle model but totally broken when the oracle was “instantiated” with any hash function.
This was shocking, but honestly not that surprising once you’ve had someone else explain the basic idea. Most of these “counterexample schemes” followed from four simple observations:
- In the (totally artificial) random oracle model, you don’t know a compact description of the hash function. You literally can’t know one, since it’s an exponentially-sized random function.
- In the “instantiated” protocol, where you’ve replaced the random oracle with e.g., SHA-2, you very clearly must know a compact description of the hash function (for example, here is one.)
- We can build a “contrived” scheme in which “knowledge of the description of the hash algorithm” forms a kind of backdoor that allows you to break the scheme!
- In the random oracle model where you can’t ever possess this knowledge, the backdoor can never be triggered — hence the scheme is “secure.” In the real world where you instantiate the scheme with SHA-2, any clown can break it.
These results straddle the line between “brilliant” and “fundamentally kind of silly”. Brilliant because, wow! These schemes will be insecure when instantiated with any possible hash function! The random oracle model is a trap! But stupid because, I mean… duh!? In fact what we’re really showing is that our artificial model is artificial. If you build schemes that deliberately fall apart when any adversary knows the code for a hash function, then of course your schemes are going to be broken. You don’t need to be a genius to see that this is going to go poorly.
Nonetheless: theoreticians took the a victory lap and then moved on to ruining other people’s fun. Practitioners waited until every last one of them had lost interest, rolled their eyes, and said “let’s agree not to deploy schemes that do obviously stupid things.” And then they all went on deploying schemes that were only proven secure in the random oracle model. And this has described our world for 28 years or so.
But the theoreticians weren’t totally wrong, were they?
That is the $10,000,000,000 question.
As discussed above, many “contrived counterexample” schemes were built to demonstrate the danger of the random oracle model. But each of them was so obviously cartoonish that nobody would ever deploy one of them in practice. If your signature scheme includes 40 lines of code that essentially scream “FYI: THIS IS A BACKDOOR THAT UNLOCKS FOR ANYONE WHO KNOWS THE CODE OF SHA2”, the best solution is not to have a theoretical argument about whether this code is “valid.” The best solution is to delete the code and maybe write over your hard disk three times with random numbers before you burn it. Practitioners generally do not feel threatened by artificial counterexamples.
But a danger remains.
Cryptographic schemes have been getting more complicated and powerful over time. Since I explained the danger in a previous blog post I wrote five years ago, I’m going to save myself some trouble — and also make myself look prescient:
The probability of [a malicious scheme slipping past detection] accidentally seems low, but it gets higher as deployed cryptographic schemes get more complex. For example, people at Google are now starting to deploy complex multi-party computation and others are launching zero-knowledge protocols that are actually capable of running (or proving things about the execution of) arbitrary programs in a cryptographic way. We can’t absolutely rule out the possibility that the CGH and MRH-type counterexamples could actually be made to happen in these weird settings, if someone is a just a little bit careless.
Let’s drill down on this a moment.
One relatively recent development in cryptography is the rise of succinct “ZK” or “verifiable computation” schemes that allow an untrusted person to prove statements about arbitrary programs. In general terms, these systems allow a Prover (e.g., me) to prove statements of the following form: (1) I know an input to a [publicly-known] program, such that (2) the program, when run on that input, will output “True.”
The neat thing about these systems is that after running the program, I can author a short (aka “succinct”) proof that will convince you that both of these things are true. Even better, I can hand that short proof (sometimes called an “argument”) to anyone in the world. They can run a Verify algorithm to check that the proof is valid, and if it agrees, then they never need to repeat the original computation. Critically, the time required to verify the proof is usually much less than the time required to re-check the program execution, even for really complicated program executions. The resulting systems are called arguments of knowledge and they go by various cool acronyms: SNARGs, SNARKs, STARKs, and sometimes IVC. (The Ethereum world sometimes lumps these together under the moniker “ZK”, for historical reasons we will not dig into.)
This technology has proven to be an exciting and necessary solution for the cryptocurrency world, because that world happens to have a real problem on its hands. Concretely: they’ve all noticed that blockchains are very slow. Those systems require thousands of different computers to verify (“check the validity of”) every financial transaction they see, which places enormous limitations on transaction throughput.
“Succinct” proof systems offer a perfect solution to this conundrum.
Rather than submitting millions of individual transactions to a big, slow blockchain, the blockchain can be broken up. Distinct servers called “rollups” can verify big batches of transactions independently. They can each use a succinct proof system to prove that they ran the transaction-verification program correctly on all those transactions. The base-level blockchains no longer need to look at every single transaction. They only need to verify the short “proofs” authored by the rollup servers, and (magically!) this ensures that all of the transactions are verified — but with the base-level blockchain doing vastly less work. In theory this allows a massive improvement in blockchain throughput, mostly without sacrificing security.
An even cooler fact is that these proof systems can in some cases be applied recursively. This is due to a cute feature: the algorithm for verifying a proof is, after all, itself just a computer program. So I can run that program on some other proofs as input — and then I can use the proof system to prove that I ran that program correctly.
To give a more concrete application:
- Imagine 1,000 different servers each run a program that verifies a distinct batch of 1,000 transactions. Each server produces a succinct proof that they ran their program correctly (i.e., their batch is correct.)
- Now a different server can take in each of those 1,000 different proofs. And it can run a Verify program that goes through each of those 1,000 proofs and verifies that each one is correct. It outputs a proof that it ran this program correctly.
- The result is a single “short” proof that proves all 1,000,000 transactions are correct!
I even made a not-very-excellent picture to try to illustrate how this can look:

This recursive stuff is really useful, and I promise that it will be relevant later.
So what?
The question you might be asking is: what in the world does this have to do with random oracle counterexamples?!
Since these proof systems are now powerful enough to run arbitrary programs (sometimes implemented in the form of arithmetic or boolean “circuits”), there is now a possibility that sneaky counterexample “backdoors” could be smuggled in within the programs we are proving things about. This would mean that even if the actual proving scheme has no obvious backdoors in its code, the actual programs would be able to do creepy stuff that would undermine security for the whole system. Our practitioner friends would no longer be able to exercise their (very reasonable) heuristic of “don’t deploy code that does obviously suspicious things” because, while their implementation might not do stupid things, some user try to run it with a malicious program that does.
(A good analogy is to imagine that your Nintendo system has no exploits built into it, but any specific game might sneak in a nasty piece of code that could blow everything up.)
A philosophical interlude
This has been a whole lot, and there’s lots more to come.
To give you a break, I want pause for a moment to talk about philosophy, metaphysics (meta-cryptography?), or maybe just the Meaning of Life. More concretely, at this point we need to stop and ask a very reasonable question: how much does this threat model even matter? And what even is this threat model?
Allow me to explain. Imagine that we have a proving system that is basically not backdoored. It may or may not be provably secure, but by itself the proving system itself does not contain any obvious backdoors that will cause it to malfunction, even if you implement it using a concrete hash function like SHA-3.
Now imagine that someone comes along and writes a program called “Verify_Ethereum_Transactions_EVIL.py” that we will want to run and prove using our proof system. Based on the name, we can assume this program was developed by a shady engineer who maliciously decide to add a “backdoor” to the code! Instead of merely verifying Ethereum transactions as you might hope for, the functionality of this program does something nastier:
“Given some input, output True if the input comprises 1,000 valid Ethereum transactions…
OR
output True if the input (or the program code itself) contains a description of the hash function used by the proving system.”
This would be really bad for your cryptocurrency network! Any clever user could submit invalid Ethereum transactions to be verified by this program and it would happily output “True.” If any cryptocurrency network then trusted the proof (to mean “these transactions are actually valid”) then you could potentially use this trick to steal lots of money.
But also let me be clear: this would also be an incredibly stupid program to deploy in your cryptocurrency network.
The whole point of a proof system is that it proves you ran a program successfully, including whatever logic happens to be within those programs. If those programs have obvious backdoors inside of them, then proving you ran those programs means you’re also proving that you might have exercised any backdoors in those programs. If the person writing your critical software is out to get you, and/or you don’t carefully audit their output, you will end up being very regretful. And there are many, many ways to add backdoors to software! (Just to illustrate this, there used to be an entire competition called the “Underhanded C Contest” where people would compete to write C programs full of malicious code that was hard to catch. The results were pretty impressive!)
So it’s worthwhile to ask whether this is really a surprise. In the past we knew that (1) if your silly cryptographic scheme had weird code that made it insecure “to anyone who knows how to compute SHA-2“, then (2) it would really be insecure in the real world, since any idiot can download the code for SHA-2, and (3) you should not deploy schemes that have obvious backdoors.
So with this context in mind, let’s talk about what kind of bad things might happen. These can be divided into “best case“, “second worst case” and “oh hell, holy sh*t.“
In the best case, this type of attack might simply move the scary backdoor code out from the cryptographic proving system, and into the modular “application programs” that can be fed into the proving system You still need to make sure the scheme implementation doesn’t have silly backdoors — like special code that breaks everything if you know the code for SHA-2. But now you also need to make sure every program you run using this system doesn’t have a similar backdoors. But to be clear: you kind of had to audit your programs for backdoors anyway!
In fairness, the nature of these cryptographic backdoors is that they might be more subtle than a typical software backdoor. What I mean here is that ordinary software reviewers might not recognize it, and only only an experienced cryptographer will identify that something sketchy is happening. But even if the bug is hard to identify, it’s still a bug — a bug in one specific piece of code — and most critically, it would only affect your own application if you deployed it.
Of course there are worse possibilities as well.
In the second worst case, perhaps the bugdoor can be built into the application code in some clever way that is deeply subtle and fundamentally difficult for code auditors to detect — even if they know how to look for it. Perhaps it could somehow be cryptographically obfuscated, so no code review will detect it! Recursive proof systems are worrying when it comes to this concern, since the “bug” might exist multiple layers down in a tree of recursive proofs, and you might not have the code for all those lower-level programs.1 It’s possible that the set of “bad code behaviors” we we’d need to audit the code for is so large and undefined that we can no longer apply simple heuristics to catch the bad stuff!
This would be very scary. But it is certainly not the worst case.
The (“oh crap!”) worst case: with recursive proofs there is an even more terrible thing that could theoretically happen. Recall that a single top-level recursive proof can recursively verify thousands of different programs. Many of those programs will likely be written by careful, honest developers. Others could be written by scammers. Clearly if the scammers’ code contains bugs (or flaws) then we should expect those bugs to make the scammers’ own programs less secure, at whatever goal they’re supposed to accomplish. So far none of this is surprising. But ideally what we should hope is that any backdoors in the scammers’ programs will remain isolated to the scammers’ code. They should not “jump across program boundaries” and thus undermine the security of the well-written, honest programs elsewhere in the recursive proof stack.
Now imagine a situation where this is not true. That is, a clever bug in one “program” anywhere in the tree could somehow make any other program (proof) in the entire tree of proofs insecure. This is akin to getting one malicious program onto a Linux box, then using it to compromise the Linux kernel and thus undermine the security of any application running on the system. Maybe this seems unlikely? Actually to me it seems genuinely fantastic, but again, we’re in Narnia at this point. Who knows what’s possible!

This is the scary thing about what can happen once we leave the world of provable security. Without some fundamental security guarantees we can rely on, it’s possible that the set of attacks we might suffer could be very limited. But they could also be fundamentally unbounded! And that’s where I have to leave this post for the moment.
This post is continued in Part 2.
Notes:
- We might imagine, for example, that a recursive Verify program might just take in the hash (or commitment) to a program. And then a Prover could simply state “well, I know a real program that matches this commitment AND ALSO I know an input that satisfies the program.” This means the program wouldn’t technically be available to every auditor, only the hash of the program. I am doing a lot of handwaving here, but this is all possible.






































![R_q = {\mathbb Z}_q[X]/(X^n+1)](https://s0.wp.com/latex.php?latex=R_q+%3D+%7B%5Cmathbb+Z%7D_q%5BX%5D%2F%28X%5En%2B1%29&bg=ffffff&fg=000000&s=0&c=20201002) . Each “element” is actually a vector of coefficients
. Each “element” is actually a vector of coefficients 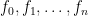 representing a polynomial of the form
representing a polynomial of the form 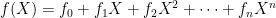 , where every coefficient is a integer modulo q. These polynomials can be added and multiplied using standard operations built from modular arithmetic. For Dilithium, we “conveniently” fix q = 223 − 213 + 1 and n = 256.
, where every coefficient is a integer modulo q. These polynomials can be added and multiplied using standard operations built from modular arithmetic. For Dilithium, we “conveniently” fix q = 223 − 213 + 1 and n = 256. 



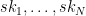 to be her “secret key.”
to be her “secret key.”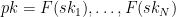 .
.


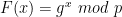
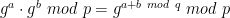
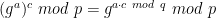


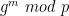 . Recall that in the discussion above, the approach we used was to pick a random point (x, y) first, and then “manufacture” a box as follows:
. Recall that in the discussion above, the approach we used was to pick a random point (x, y) first, and then “manufacture” a box as follows: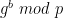 directly from
directly from 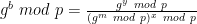
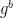 in the instantiation above.) Finally, she will feed her boxed value(s) for both m and b as well as an optional “message” M into the hash function as follows:
in the instantiation above.) Finally, she will feed her boxed value(s) for both m and b as well as an optional “message” M into the hash function as follows: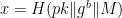

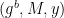 which he can check by re-computing the hash function on the inputs to obtain x and verifying that y is correct (as in the original protocol.)
which he can check by re-computing the hash function on the inputs to obtain x and verifying that y is correct (as in the original protocol.)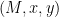 to Victor, who now computes
to Victor, who now computes 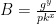 and tests whether
and tests whether 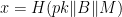 . I will leave the logic of this equation for the reader to work out. Commenter Imuli below points to a
. I will leave the logic of this equation for the reader to work out. Commenter Imuli below points to a 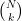 distinct subsets to pick from, the probability that Veronica will select exactly the same subset as Victor did — allowing him to answer her challenge properly — can be made quite small, provided N and k are chosen carefully. (For example, N=128 and k=30 gives about
distinct subsets to pick from, the probability that Veronica will select exactly the same subset as Victor did — allowing him to answer her challenge properly — can be made quite small, provided N and k are chosen carefully. (For example, N=128 and k=30 gives about 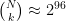 and so Evil Victor will almost never succeed.)
and so Evil Victor will almost never succeed.) 
















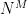 . This probably won’t scale very well for even modest values of M and N, but let’s put this aside for a moment. Given enough paper, we could imagine writing down each unique lookup table on a piece of paper: then we could stack those papers up and admire the minor ecological disaster we’d have just created.
. This probably won’t scale very well for even modest values of M and N, but let’s put this aside for a moment. Given enough paper, we could imagine writing down each unique lookup table on a piece of paper: then we could stack those papers up and admire the minor ecological disaster we’d have just created.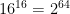 , or about 18 quintillion. It gets worse if you think about “useful” cryptographic functions, say those with the input/output profile of ChaCha20, which has 128-bit inputs and 512-bit outputs. There you’d need a whopping
, or about 18 quintillion. It gets worse if you think about “useful” cryptographic functions, say those with the input/output profile of ChaCha20, which has 128-bit inputs and 512-bit outputs. There you’d need a whopping  (giant) pieces of paper. Since there are only around
(giant) pieces of paper. Since there are only around 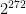 atoms in the observable universe (according to literally the first
atoms in the observable universe (according to literally the first 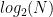 bits of data.
bits of data.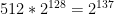 bits.
bits. 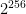 individual functions, where each key value selects exactly one function from the family.
individual functions, where each key value selects exactly one function from the family.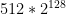 is not.
is not. work, and we assume that there exist reasonable values of n for which no computing device exists that can succeed at this.)
work, and we assume that there exist reasonable values of n for which no computing device exists that can succeed at this.)
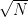 queries. For functions like AES, which has output size
queries. For functions like AES, which has output size 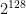 , this will occur around
, this will occur around  queries.
queries. 
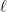 -bit strings, then any statistical “
-bit strings, then any statistical “