After umpteen weeks writing about broken stuff, I’m thrilled to tell you that for once, nothing awful is happening in the crypto world. It won’t last. But while it does, let’s grab the opportunity to talk about something constructive.
I’m thrilled to tell you that for once, nothing awful is happening in the crypto world. It won’t last. But while it does, let’s grab the opportunity to talk about something constructive.
Now a word of warning: what I’m going to talk about today is fairly wonky and (worse), involves hash functions. If you’re not feeling up for this, this is your cue to bail and go read something nice about buffer overflows.
Merkle-Damgård
 |
| This is not Ivan Damgård. (Seriously Google?) |
The best way to begin any discussion of hash function design is to take a quick peek inside of the hash functions we actually use. Since the most popular hashes today are MD5 (ugh) and SHA, the right place to start is with the ‘Merkle-Damgård’ paradigm.
To understand Merkle-Damgård, you need to understand that cryptographers love to build complicated things out of simpler components. Under the hood of most block ciphers you’ll find S-boxes. Similarly, if you take the lid off a Merkle-Damgård hash function — surprise! — you find block ciphers. Or at least, something very much like them.
This approach dates to a 1979 proposal by a young cryptographer named Ralph Merkle. What Merkle showed is a way to build hash functions with a variable-length input, using any fixed one-way compression function (a one-way function that spits out fewer bits than it takes in). While Merkle wasn’t specific about the function, he suggested that DES might be a good candidate.
Expressed as a colorful diagram, the Merkle construction looks something like this:
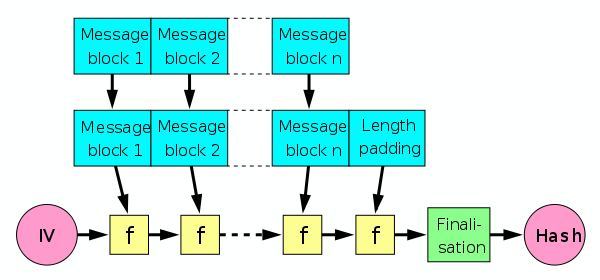 |
| Merkle-Damgård Construction (source: Wikipedia because I’m too lazy to draw my own diagrams). IV is a fixed value. f is a one-way compression function. |
The beauty of Merkle’s proposal is that it’s relatively simple to understand. You simply chop your message into blocks, then feed each block into the function f along with the output of the previous function evaluation. Throw in a finalization stage and you’re done.
Of course there’s a difference between proposing a technique and showing that it actually works. It would take ten more years, but at CRYPTO 1989, Merkle and another cryptographer named Ivan Damgård independently submitted formal analyses of Merkle’s proposal. What they showed is that as long as the function f has certain ideal properties, the resulting hash function is guaranteed to be collision-resistant. The rest, as they say, is history.
The popularity of Merkle-Damgård can be attributed in part to its security proof. But it also owes something to some major practical advantages:
- You can use any secure block cipher as the function f, with just a few tweaks.
- M-D hash functions can be pretty darn fast, again depending on f and how you use it.
- M-D hashes allow you to digest ‘live’ data streams, where you don’t know in advance how much data you’re going to be hashing.
What the heck is a secure hash function?
- Collision resistance. It should be hard to find any pair of messages M1, M2 such that H(M1) == H(M2).
- Pre-image resistance. Given only h it should be hard to find a ‘pre-image’ M2 such that H(M2) == h.
Now leave aside the technical fact that none of the unkeyed hash functions we use today are ‘truly’ collision-resistant. Or that the above definition of pre-image resistance implies that I can hash my cat’s name (‘fluffy’) and nobody can invert the hash (note: not true. Go ask LinkedIn if you don’t believe me.) The real problem is that these definitions don’t cover the things that people actually do with hash functions.
Random oracles and indifferentiability
The answer, if you dig hard enough, is that people want hash functions to be random oracles.
Random oracles are cryptographers’ conception of what an ‘ideal’ hash function should be. Put succinctly, a random oracle is a perfectly random function that you can evaluate quickly. Random functions are beautiful not just because the output is random-looking (of course), but also because they’re automatically collision-resistant and pre-image resistant. It’s the only requirement you ever need.
The problem with random functions is that you just can’t evaluate them quickly: you need exponential storage space to keep them, and exponential time to evaluate one. Moreover, we know of nothing in the ‘real’ world that can approximate them. When cryptographers try to analyze their schemes with random functions, they have to go off into an imaginary fantasy world that we call the ‘random oracle model‘.
But ok, this post is not to judge. For the moment, let’s imagine that we are willing to visit this fantasy world. An obvious question is: what would it take to build a random oracle? If we had a compression function that was good enough — itself a random function — could we use a technique like Merkle-Damgård to get the rest of the way?
- There exists a way to ‘construct’ something ‘like’ A out of B.
- There exists a way to ‘simulate’ something ‘like’ B using A.
- An attacker who interacts with {constructed A-like thing, B} cannot tell the difference (i.e., can’t differentiate it) from {A, simulated B-like thing}
The definition of simulation gets a bit wonky. but expressed in simpler language all this means is: if you can show that your hash function, instantiated with an ‘ideal’ compression function, looks indistinguishable from a random oracle. And you can show that a manufactured compression function, built using a random oracle as an ingredient, looks indistinguishable from an ideal compression function, then you can always replace one with the other. That is, your hash function is ‘good enough’ to be a random oracle.
The following year, Coron, Dodis, Malinaud and Puniya applied this framework to Merkle-Damgård-hash functions. Their first result was immediate: such a proof does not work for Merkle-Damgård. Of course this shouldn’t actually surprise us. We already know that Merkle-Damgård doesn’t behave like a random oracle, since random oracles don’t exhibit length-extension attacks. Still it’s one thing to know this, and another to see a known problem actually turn up and screw up a proof. So far, no problem.
- They proved formally that Merkle-Damgård can be made indifferentiable from a random oracle, as long as you apply a prefix-free encoding to the input before hashing it. Prefix-free encodings prevent length-extensions by ensuring that no message can ever be a prefix of another.
- Next, they proved the security of HMAC applied to a Merkle-Damgård hash.
- Finally, and best of all, they showed that if you simply drop some bits from the last output block — something called a ‘chop’ construction — you can make Merkle-Damgård hashes secure with much less work.
The best part of Coron et al.‘s findings is that the chop construction is already (inadvertently) in place on SHA384, which is constructed by dropping some output bits from its big-brother hash SHA512. The modern hash variants SHA512/224 and SHA512/256 also have this property.** So this theoretical work already has one big payoff: we know that (under certain assumptions) these hashes may be better than some of the others.
And these results have bigger implications. Now that we know how to do this, we can repeat the process for just about every candidate hash function anyone proposes. This lets us immediately weed out obvious bugs, and avoid standardizing another hash with problems like the length extension attack. This process has become so common that all of the SHA3 candidates now sport exactly such an indifferentiability proof.
In conclusion
If I had it in me, I’d go on to talk about the SHA3 candidates, and the techniques that each uses to achieve security in this model. But this has already been a long post, so that will have to wait for another time.
I want to say only one final thing.
This is a practical blog, and I admit that I try to avoid theory. What fascinates me about this area is that it’s a great example of a place where theory has directly come to the aid of practice. You may think of hash functions as whizzing little black boxes of ad-hoc machinery, and to some extent they are. But without theoretical analysis like this, they’d be a whole lot more ad-hoc. They might not even work.
Remember this when NIST finally gets around to picking Keccak BLAKE.
Notes:
* For a ridiculous example, imagine that you have a secure (collision-resistant, pre-image resistant) hash function H. Now construct a new hash function H’ such that H'(M) = {“long string of 0s” || H(M)}. This function is as collision-resistant as the original, but won’t be very useful if you’re generating keys with it.
** Thanks to Paulo Barreto for fixing numerous typos and pointing out that SHA512/256 and /224 make excellent candidates for chop hashes!




 about the title above, I ripped it off from an old Belle Waring
about the title above, I ripped it off from an old Belle Waring 







