 |
| SafeNet eToken PRO Anywhere |
There was a time just a few weeks ago when it seemed like the CRYPTO 2012 accepted papers list might not be posted in time for, well, CRYPTO 2012. Fortunately the list is public now, which means (1) we’ve avoided the longest rump session in the history of cryptography, and (2) I get to tell you about a particularly neat paper.
The paper in question is ‘Efficient Padding Oracle Attacks on Cryptographic Hardware‘ by Bardou, Focardi, Kawamoto, Simionato, Steel and Tsay. This is a typically understated academic title for a surprisingly nifty result.
Here’s the postage stamp version: due to a perfect storm of (subtle, but not novel) cryptographic flaws, an attacker can extract sensitive keys from several popular cryptographic token devices. This is obviously not good, and it may have big implications for people who depend on tokens for their day-to-day security. If that describes you, I suggest you take a look at this table:
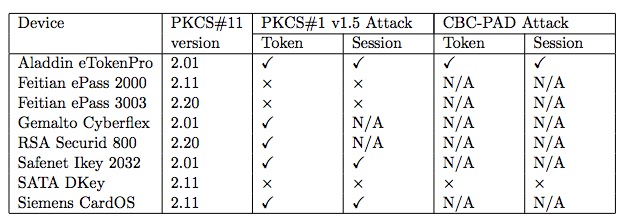 |
| Tokens affected by the Bardou et al. attacks. A checkmark means “vulnerable”. (source). |
That’s the headline news, anyway. The more specific (and important) lesson for cryptographic implementers is: if you’re using PKCS#1v1.5 padding for RSA encryption, cut it out. Really. This is the last warning you’re going to get.
So much for the short version. Keep reading for the long one.
What are cryptographic tokens?
If you’ve ever developed cryptographic software, you know that general-purpose computers aren’t the safest place to store keys. Leaving aside stuff like this, all it takes is one nasty software bug to send all your important key material (e.g., TLS server keys, certificate signing keys, authentication keys) into someone else’s hands.
Since it seems increasingly difficult to harden standard computers, a popular solution is to simply put the keys somewhere else. The most popular ‘somewhere’ is onboard a cryptographic co-processor. When the co-processor is expensive and powerful, we often refer to it as a Hardware Security Module (HSM). When it’s removable and consumer-grade we call it a ‘token‘. Most tokens are used for authentication purposes (think SecurID), but they’re useful for other things like disk encryption. Modern tokens typically look like USB sticks.
Tokens operate under some of the most challenging conditions you can imagine. The computer they’re connected to may be completely pwned. An attacker could steal a token and physically dismember it in an attempt to extract its secrets. None of this is easy to deal with, and manufacturers have invested a lot of time and money getting this right.
Unfortunately, what Bardou et al. are telling us is: maybe they didn’t invest enough. Several popular token brands are still vulnerable to cryptographic attacks that have been well-known since the 1990s. And that is bad news.
But this paper is brand new. Why are you talking about ‘a bad couple of years’?
While this new paper is a bad result for the token industry, it’s not the first bad news we’ve had about these devices.
Let me explain. You see, while tokens won’t let you extract sensitive keys, they make an exception if the sensitive keys are encrypted (aka: ‘wrapped’). This makes a lot of sense. How else are you supposed to import/export/back up keys from a token? In theory, this encryption (wrapping) should keep the keys safe even if an attacker has totally compromised your computer.
An older problem — discovered by a series of researchers in 2009 and 2010 — is that token manufacturers were careless in the way they implemented the PKCS#11 Cryptographic Token Interface Standard. The spec says that encryption keys are to be used for either (a) encryption/decryption of normal data, OR (b) for wrapping sensitive keys. But never both. If you allow users to perform both operations with a given key, you enable the following attack:
- Ask the token to encrypt a sensitive key K and export the ciphertext.
- Ask the token to decrypt the ciphertext and hand you the result.
- Congratulations, you have K!
It’s hard to believe that something this ‘stupid’ actually worked, but for some tokens it did. The whole mess reached a head in 2010 when Bortolozzo, Focardi, Centenaro and Steel automated the process of finding API bugs like this, and were able to ‘break’ a whole bunch of tokens in one go.
(Token manufacturers were not happy with this, by the way. At CCS 2010, Graham Steel described being invited to a major French token manufacturer where the CEO held him captive and berated him gently tried to persuade him not to publish his results. Such are the hazards of responsible disclosure.)
The above issues should be long fixed by now. Still, they raised questions! If token manufacturers can’t implement a secure API, how well are they doing with things like, say, complicated cryptographic algorithms? And that’s the question this new paper tries to answer.
So what’s wrong with the crypto?
What the CRYPTO paper shows is that several commercial tokens (but not all of them!) are vulnerable to practical padding oracle attacks on both symmetric (AES-CBC) and asymmetric (RSA PKCS #1v1.5) encryption. These attacks are a huge problem, since they give an attacker access to keys that otherwise should be safely encrypted outside of the token.
Padding attacks take different forms, but the general intuition is this:
- Many encryption schemes apply padding to the plaintext before encryption.
- After decrypting a given ciphertext, most implementations check to see if the padding is valid. Some output a recognizable error (or timing differential) when it isn’t.
- By mauling a legitimate (intercepted) ciphertext in various ways, the attacker can submit many modified versions of the ciphertext to be decrypted. Some of these will have valid padding, others will produce error results. Suprisingly, just these bits of information can be sufficient to gradually reveal the underlying plaintext.
For tokens, you start with an encrypted key you want to learn, and you submit it to the token for import. Normally the token will just accept it, which isn’t very helpful. So instead, you modify the ciphertext in some way, and send the mangled ciphertext to be imported. If the token responds with something like ‘could not import key: the ciphertext had bad padding’, you may be able to run a padding oracle attack.
(Note that it doesn’t take an explicit error: if decryption is simply faster when the padding is bad, you’ve got everything you need.)
The most famous (and efficient) padding oracle attack is Vaudenay’s attack on padded CBC-mode encryption, proposed back in 2002. (See here for an idea of what the attack looks like.) The first finding of Bardou et al. is that many tokens are vulnerable to Vaudenay’s attack. Yikes.
But what about RSA encryption? This is important, since many tokens only support RSA to import secret keys.
Fortunately (for the researchers) RSA encryption also uses padding, and even better: these tokens use a scheme that’s long been known to have padding oracle problems of its own. That scheme is known as RSA-PKCS#1v1.5, and it was famously broken by Daniel Bleichenbacher in the late 1990s. As long as these implementations produce obvious errors (or timing differences) when they encounter bad padding, there should be an ‘off the shelf’ attack that works against them.
But here the researchers ran into a problem. Bleichenbacher’s attack is beautiful, but it’s too slow to be useful against tokens. When attacking a 1024-bit RSA key, it can require millions of decryption attempts! Your typical consumer-grade token token can only compute a few decryptions per second.
No problem! To make their attack work, Bardou et al. ‘simply’ optimized Bleichenbacher’s attack. The new version requires mere thousands (or tens of thousands) of decryption attempts, which means you can unwrap sensitive keys in just a few minutes on some tokens.
This table tells us how long the attacks actually took to run against real tokens:
 |
| Timing results for the optimized Bleichenbacher attacks (on 1024-bit RSA encryptions). ‘Oracle’ indicates the nature of the RSA decryption/padding check implementation. (source) |
Is my HSM secure?
If you’re an HSM manufacturer I have ‘good’ news for you. You’re ok. For now.
Oh, not because your HSM is secure or anything. Hilariously, the researchers were unable to run their attacks on a commercial HSM because they couldn’t afford one. (They can costs upwards of EUR20,000.) Don’t get complacent: they’re working on it.
How does the RSA attack work?
For the real details you should see the paper. Here I can offer only the tiniest little intuition.
The Bleichenbacher attack relies on the fact that RSA is homomorphic with respect to multiplication. That means you can multiply a hidden RSA plaintext (the “m” in “m^e mod N”) by some known value “s” of your choosing. What you do is compute “m^e * s^e mod N”. The decryption of this value is “(m*s) mod N”.
Now consider the details of RSA-PKCS#1v1.5. To encrypt a legitimate message, the encryptor first pads it with the following bytes, and treats the padded result as the integer “m” to be RSA encrypted.
So you’ve intercepted a valid, PKCS#1v1.5 padded RSA ciphertext, and you have access to a decryptor who knows the secret key. The trick now is to ‘mangle’ the legitimate ciphertext in various clever ways and submit these new results to the decryptor.
The basic approach is to multiply the ciphertext by different chosen values “s^e mod N” (for known “s”) until eventually you find one that does not produce a padding error. This means that the decrypted value “(m*s mod N)” is itself a PKCS-padded message. This seems inconsequential, but actually it tells you quite a lot. Presumably you know “s”, since you chose it. You also know that “m*s mod N” is an integer of a very specific form, one that satisfies the padding checks. By adaptively choosing new “s” values and submitting many, many ciphertexts for decryption, these tiny bits of information will allow you to ‘zero in’ on the underlying plaintext.
The authors of this paper describe several optimizations to Bleichenbacher’s attack. What I find most interesting is the way they exploited differences in the way that tokens actually implement their padding checks. It turns out that this nature of this implementation makes a huge difference to the efficiency of the attack.
Five possible ‘implementations’ are described below.
- FFF: padding is ‘ok’ only if correctly padded and plaintext is of a specific length (e.g., it’s a 128-bit AES key)
- FFT: padding is ‘ok’ only if correctly padded, but plaintext can be any length.
- FTT: same as above, but also allows 0s in the “non-zero random bytes”.
- TFT: same as above, but ‘ok’ even if there are no zeros after the first byte.
- TTT: padding is ‘ok’ as long as it starts with ‘0x 00 02’.
These all look quite similar, but have very different practical implications!
You see, intuitively, the Bleichenbacher attack only ‘works’ if sometimes the decryptor says ‘hey, this mauled ciphertext has good padding!’. As a general rule, the more often that happens, the faster the attack works.
It goes without saying that the TTT padding check is a lot more likely to produce ‘good padding’ results than the ‘FFF’, and correspondingly for the intermediate ones. FFF is so challenging that it’s basically impractical. The ‘good’ (uh, ‘bad’) news is that many tokens tend towards the more useful implementations. And as you can see in the table below, little details like this have huge impacts.
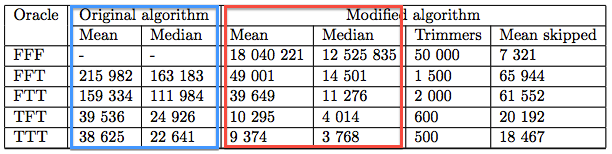 |
| Total number of decryption queries required to decrypt an RSA-PKCS#1v1.5-encrypted symmetric (AES) key. ‘Original algorithm’ (blue box) shows the mean/median performance of the standard Bleichenbacher attack. ‘Modified algorithm’ (red box) is the mean/median performance of the new, optimized algorithm. Note that the specific implementation of the padding check (FFF/TTT etc.) makes a huge difference in the cost. (source) |
What can I do to protect my own code from padding oracle attacks?
If you’re using symmetric encryption, that’s easy. Simply use authenticated encryption, or put a MAC on all of your ciphertexts. Do this correctly and Vaudenay padding oracles will not trouble you.
RSA encryption is more difficult. The ‘best practice’ in implementing RSA is: don’t implement RSA. Other people have done it better than you can. Go find a good implementation of RSA-OAEP and use that. End of story.
Unfortunately, even with RSA-OAEP, this can be difficult. There are attacks on OAEP encryption too (some are mentioned in this paper). And if you’re working in hardware, life is particularly difficult. Even small timing differentials can leak details about your padding check. If this describes your use case: find a professional and be very, very careful.
Are there any broad security lessons, any wisdom, to be drawn from this result?
Usually the lesson I glean from these attacks is: people make mistakes. Which is barely a lesson, and it’s certainly not wisdom. For some of the issues in this paper, namely the symmetric padding oracle attacks, that’s still about what I get. Manufacturers made unforced errors.
But the RSA-PKCS#1v1.5 attacks are, to me, a bit more meaningful. I run into bad implementations of this obsolete standard this all the time. Most of the time when I bring it up, nobody really cares. The typical response is something like: it’s called the ‘million message attack’ for a reason. There’s no way anyone run that thing against our system.
Bruce Schneier says ‘attacks only get better, they never get worse’. In my opinion, the lesson of this paper is that attacks not only get better, but if you go around tempting fate, they’re quite capable of getting better by precisely the amount necessary to break your (high-value) system. You should never use a broken primitive just because the ‘known’ attack seems impractical.
And while this may not be ‘wisdom’ either, I think it’s advice to live by.


 bad guys figure out how to neutralize
bad guys figure out how to neutralize 


 Oswald and Christof Paar’s recent
Oswald and Christof Paar’s recent 

