Update 9/22/11: It appears that OpenSSL may have actually written a patch for the problem I describe below, all the way back in 0.9.6d (2002), so this attack may not be relevant to OpenSSL systems. But I haven’t reviewed the OpenSSL code to verify this. More on the patch at the bottom of this post.
Update 10/2/11: Yes, the attack works pretty much as described below (and see comments). To advise future standards committees considering non-standard crypto, I have also prepared this helpful flowchart.
There’s some news going around about a successful attack on web browsers (and servers) that support TLS version 1.0. Since this is ostensibly a blog, I figured this subject might be good for a little bit of real-world speculation.
My first thought is that “attacks” on TLS and SSL need to be taken with a grain of salt. The protocol has been around for a long time, and new attacks typically fall into one of two categories: either they work around SSL altogether (e.g., tricking someone into not using SSL, or going to an untrusted site), or they operate on some obscure, little-used feature of SSL.
(Please don’t take this as criticism of the attacks I link to above. At this point, any attack against TLS/SSL is a big deal, and those are legitimate vulnerabilities. I’m trying to make a point about the strength of the protocol.)
This attack is by researchers Juliano Rizzo and Thai Duong, and if we’re to believe the press, it’s a bit more serious than usual. Ostensibly it allows a man-in-the-middle to decrypt HTTPS-protected session cookies, simply by injecting a little bit of Javascript into the user’s web browser. Since we’re constantly running third-party Javascript due to web advertising, this might not be a totally unrealistic scenario.
The attack is claimed to make use of a theoretical vulnerability present in all versions of SSL and TLS 1.0 (but not later versions of TLS). Unfortunately there are few details in the news reports, so until the researchers present their findings on Friday, we have to rely on some educated guesses. And thus, here’s a big caveat:
Every single thing I write below may be wrong!
What the heck is a Blockwise-Adaptive Chosen Plaintext Attack?
Based on a quick Google search, the attack may be based a paper written by Gregory Bard at the University of Maryland. The basic idea of this attack is that it exploits the particular way that TLS encrypts long messages using block ciphers. To do this, Bard proposes using Javascript.
Besides being incredibly annoying, Javascript is a huge potential security hole for most web browsers. This is mostly mitigated in browsers, which place tight restrictions on the sorts of things that a Javascript program can do. In terms of network communication, Javascript programs can barely do anything. About the only exception to this rule is that they can communicate back to the server from which they were served. If the page is HTTPS-protected, then communication gets bundled under the same TLS communication session used to secure the rest of the web page.
In practice, this means that any data sent by the Javascript program gets encrypted under the same key that is also used to ship sensitive data (e.g., cookies) up from the web browser to the server. Thus, the adversary now has a way to encrypt any message she wants, under a key that matters. All she has to do is sneak a Javascript program onto the user’s web page, then somehow intercept the encrypted data sent to the server by the browser. This type of thing is known as a chosen plaintext attack.
Normally chosen plaintext attacks are not a big deal. In fact, most encryption schemes are explicitly designed to deal with them. But here is where things get interesting.
TLS 1.0 uses a block cipher to encrypt data, and arranges its use of the cipher using a variant of the Cipher Block Chaining mode of operation. CBC mode is essentially a means of encrypting long messages using a cipher that only encrypts short, fixed-size blocks.
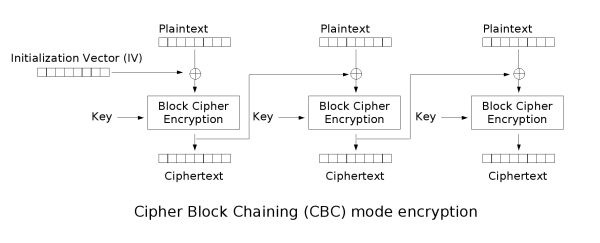 |
| CBC mode encryption (diagram: Wikipedia). The circular cross denotes the XOR operation. The message is first divided into even-sized blocks. A random Initialization Vector (IV) is used for the first block. Each subsequent block is “chained” to the message by XORing the next block of plaintext with the previous block of ciphertext. |
CBC mode encryption is illustrated above. Note that it uses a block cipher as an ingredient. It also depends on a random per-message nonce called an Initialization Vector, or IV for short.
If you asked me to describe the security properties of CBC, I would recite the following mantra: as long as you use a secure block cipher, and as long as you generate a new, random IV for each message, this mode is very secure against eavesdroppers — even when the adversary can obtain the encryption of chosen plaintexts. If you doubted me, I would point you here for a formal proof.
You may have noticed that I emphasized the phrase “as long as”. This caveat turns out to be important.
In the implementation of CBC mode, the TLS designers made one, tiny optimization. Rather than generating a fresh IV for each message, the protocol re-uses the last block of the previous ciphertext message that was sent. This value becomes the IV for the new message.
In practice, this tiny modification has huge implications. If we assume that the adversary — let’s call her Sue — is sniffing the encrypted data sent by the browser, then she can obtain the IV that will be used for the next message. Now let’s say she has also identified a different block of ciphertext C that she wants to decrypt, maybe because it contains the session cookie. While she’s at it, she can easily obtain the block of ciphertext C’ that immediately precedes C.
None of this requires more than simple eavesdropping. Sue doesn’t know what message C encrypts — that value, which we’ll call M, is what she wants to learn — but she does know that C can be expressed using the CBC encryption formula as:
C = AES-ENC(key, M ⊕ C’)
Sue also knows that she can get her Javascript program to transmit any chosen block of data M* that she wants. If she does that, it will produce a ciphertext C* that she can sniff.
Now let’s make one more huge assumption. Imagine that Sue has a few guesses for what that unknown value of M might be. It’s 16 bytes long, but maybe it only contains a couple of bytes worth of unknown data, such as a short PIN number. If Sue generates her value M* based on one of those guesses, she can confirm whether C actually encrypts that value.
To cut through a lot of nonsense, let’s say that she guesses M correctly. Then she’ll generate M* as:
M* = IV ⊕ M ⊕ C’
When her Javascript program sends out M* to be encrypted, the TLS layer will encrypt it as:
C* = AES-ENC(key, IV ⊕ M*) = (which we can re-write as…)
AES-ENC(key, IV ⊕ IV ⊕ M ⊕ C’ ) = (and XORing cancels…)
AES-ENC(key, M ⊕ C’)
All I’ve done above is write out the components of M* in long form, and simplify the equation based on the fact that the IV ⊕ IV term cancels out (a nice property of XOR). The important thing to notice is that if Sue guessed correctly, the ciphertext C* that comes out of the browser will be identical to the captured ciphertext C she wants to decrypt! If she guessed wrong, it won’t.
So assuming that Sue has time on her hands, and that there are only a few guesses, she can repeat this technique over and over again until she figures out the actual value of M.
But this guessing stuff is crazy!
If you’re paying attention, you’ll already have twigged to the one huge problem with this attack. Yes, it works. But it only works if she has a small number of guesses for the value M. But in practice, M is 16 bytes long. If she somehow knows the value of all but two bytes of that value, she might be able to guess the remaining bytes in about 2^15 (32,768) attempts on average. But in the more likely case that she doesn’t know any of the plaintext, she has to try on average about 2^127 possible values.
In other words, she’ll be guessing until the sun goes out.
Let’s get aligned
And this is where the cleverness comes in. I don’t know exactly what Rizzo and Duong did, but the paper by Bard hints at the answer. Recall that when the browser encrypts a CBC-mode message, the first step is to chop the message into equal-length blocks. If it’s using AES, these will each be 16 bytes long.
If Sue needs to guess the full contents of a random 16-byte block, she’s hosed — there are too many possibilities. The only way this technique works in general is if she knows most of a given block, but not all of it.
But what if Sue could convince the browser to align the TLS messages in a manner that’s useful to her? For example, she could fix things so that when the browser sends the cookie to the server, the cookie would be pre-pended with something that she knows — say, a fixed 15-byte padding. That would mean that the stuff she wants to learn — the start of the cookie — takes up only the last byte of the block.
If Sue knows the padding, all she has to guess is the last byte. A mere 256 possible guesses!
Now what if she can repeat this trick, but this time using a 14-byte known padding. The block would now end with two bytes of the cookie, the first of which she already knows. So again, 256 more guesses and she now knows two bytes of the cookie! Rinse, repeat.
This technique could be quite effective, but notice that it relies on some strong assumptions about the way Sue can get the browser to format the data it sends. Does the Rizzo and Duong attack do this? I have absolutely no idea. But based on my understanding of the attack and the descriptions I’ve read, it represents my best speculation.
I guess pretty soon we’ll all know how good I am at guessing.
Update 9/22/11: This post by James Yonan offers the first piece of confirmation suggesting that BEAST is based on the Bard attack. Yonan also points out that OpenSSL has included a “patch” to defend against this issue, all the way back to version 0.9.6d (2002). In a nutshell, the OpenSSL fix encrypts random message fragments at the start of each new message sent to the server. This additional message fragment works like an IV, ensuring that M* is no longer structured as I describe above. Yonan also notes that NSS very recently added a similar patch, which indicates that NSS-based browsers were the problem (this includes Firefox, Chrome).
I’m usually critical of OpenSSL for being a code nightmare. But (pending verification) I have to give those guys a lot of credit for this one.

The way to continue the attack is actually quite simple.
1. Use third-party JS, which takes executes in context from http://eve.com and uses image-tags or the like to introduce chosen-plaintext into the SSL-connection to https://bob.com. Just bump up wireshark and you will see, that e.g. chromium keeps the TLS-connection alive for 5 minutes of idle and any connection attempt is served via the same TLS-connection (via http-keep-alive).
2. Alignment. Include an imagetag to https://bob.com/XXXXX
We know everything of the request except the cookie. The GET-parameter comes before the cookie, so by choosing the correct number of XXXX we force the first (or the last) byte of the cookie to land in its own block.
3. Since most cookies are base64, we need worst-case a measly 64*len(cookie) http requests until we recovered the cookie.
4. Speed. Thanks to http-keep-alive, we just need a single round-trip between alice and eve for any attempt (the TCP and TLS connection stays open).
Nicely explained theory. Its known that this technique works against block based ciphers, which both AES AND DES USE.
The most important thing is both the researchers have confirmed this vulnerability is not seen in TLS V1.1 & TLS V1.2.
But, most of the browsers and servers continue to use TLS V1.0, a decade old protocol. As of now IIS 7.5 is the only web server which supports these 2 new protocols, at least my search on internet suggest, Apache doesn't yet support this.
As far as browsers are concerned, only opera and IE support this on Win 7. Yes, the Security protocols are tied to platforms. Firefox, chrome and Safari continue to use decade long protocols.
Irrespective of whether this is a vulnerability or not, we should be using the latest security protocols. It doesn't make any sense to use older ones. At least not in web security.
Super article! Thanks! It helped me to understand the Content of the lecture I have had a the University
Thanks! Helped me a lot.