
Ok, this is a little embarrassing and I hate having to admit it publicly. But I can’t hold it in any longer: I think I’m becoming an Internet activist.
This is upsetting to me, since active is the last thing I ever thought I’d be. I have friends who live to make trouble for big corporations on the Internet, and while I admire their chutzpah (and results!), they’ve always made me a little embarrassed. Even when I agree with their cause, I still have an urge to follow along, cleaning up the mess and apologizing on behalf of all the ‘reasonable’ folks on the Internet.
But every man has a breaking point, and the proximate cause of mine is Trustwave. Or rather, the news that Trustwave — an important CA and pillar of the Internet — took it upon themselves to sell a subordinate root cert to some (still unknown) client, for the purposes of undermining the trust assumptions that make the Internet secure eavesdropping on TLS connections.
This kind of behavior is absolutely, unquestionably out of bounds for a trusted CA, and certainly deserves a response — a stronger one than it’s gotten. But the really frightening news is twofold:
- There’s reason to believe that other (possibly bigger) CAs are engaged in the same practice.
- To the best of my knowledge, only one browser vendor has taken a public stand on this issue, and that vendor isn’t gaining market share.
The good news is that the MITM revelation is exactly the sort of kick we’ve needed to improve the CA system. And even better, some very bright people are already thinking about it. The rest of this post will review the problem and talk about some of the potential solutions.
Certificates 101
For those of you who know the TLS protocol (and how certificates work), the following explanation is completely gratuitous. Feel free to skip it. If you don’t know — or don’t understand the problem — I’m going to take a minute to give some quick background.
TLS (formerly SSL) is probably the best-known security protocol on the Internet. Most people are familiar with TLS for its use in https — secure web — but it’s also used to protect email in transit, software updates, and a whole mess of other stuff you don’t even think about.
TLS protects your traffic by encrypting it with a strong symmetric key algorithm like AES or RC4. Unfortunately, this type of cryptography only works when the communicating parties share a key. Since you probably don’t share keys with most of the web servers on the Internet, TLS provides you with a wonderful means to do so: a public-key key agreement protocol.
I could spend a lot of time talking about this, but for our purposes, all you need to understand is this: when I visit https://gmail.com, Google’s server will send me a public key. If this key really belongs to Google, then everything is great: we can both derive a secure communication key, even if our attacker Mallory is eavesdropping on the whole conversation.
If, on the other hand, Mallory can intercept and modify our communications, the game is very different. In this case, she can overwrite Gmail’s key with her own public key. The result: I end up sharing a symmetric key with her! The worst part is that I probably won’t know this has happened: clever Mallory can make her own connection to Gmail and silently pass my traffic through — while reading every word. This scenario is called a Man in the Middle (MITM) Attack.
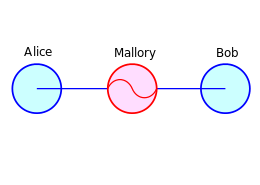 |
| MITM attack. Alice is your grandfather, Bob is BankofAmerica.com, and Mallory establishes connections with both. (Wikipedia/CC license) |
MITM attacks are older than the hills. Fortunately TLS has built-in protections to thwart them. Instead of transmitting a naked public key, the Gmail server wraps its key in a certificate; this is a simple file that embeds both the key and some identifying information, like “gmail.com”. The certificate is digitally signed by someone very trustworthy: one of a few dozen Certificate Authorities (CA) that your browser knows and trusts. These include companies like Verisign, and (yes) Trustwave.
TLS clients (e.g., web browsers) carry the verification keys for a huge number of CAs. When a certificate comes in, they can verify its signature to ensure that it’s legit. This approach works very well, under one very important assumption: namely, Mallory won’t be able to get a signed certificate on a domain she doesn’t own.
What’s wrong with the CA model?
The real problem with the CA model is that every root CA has the power to sign any domain, which completely unravels the security of TLS. So far the industry has policed itself using the Macaroni Grill model: If a CA screws up too badly, they face being removed from the ‘trusted’ list of major TLS clients. In principle this should keep people in line, since it’s the nuclear option for a CA — essentially shutting down their business.
Unfortunately while this sounds good it’s tricky to implement in practice. That’s because:
- It assumes that browser vendors are willing to go nuclear on their colleagues at the CAs.
- It assumes that browser vendors can go nuclear on a major CA, knowing that the blowback might very well hurt their product. (Imagine that your browser unilaterally stopped accepting Verisign certs. What would you do?)
- It assumes that someone will catch misbehaving CAs in the first place.
What’s fascinating about the Trustwave brouhaha is that it’s finally giving us some visibility into how well these assumptions play out in the real world.
So what happened with Trustwave?
We sold the right to generate certificates — on any domain name, regardless of whether it belongs to one of our clients or not — and packed this magical capability into a box. We rented this box to a corporate client for the express purpose of running Man-in-the-Middle attacks to eavesdrop on their employees’ TLS-secured connections. At no point did we stop to consider how damaging this kind of practice was, nor did we worry unduly about its potential impact on our business — since quite frankly, we didn’t believe it would have any.
I don’t know which part is worse. That a company whose entire business is based on trust — on the idea that people will believe them when they say a certificate is legit — would think they could get away with selling a tool to make fraudulent certificates. Or that they’re probably right.
But this isn’t the worst of it. There’s reason to believe that Trustwave isn’t alone in this practice. In fact, if we’re to believe the rumors, Trustwave is only noteworthy in that they stopped. Other CAs may still be up to their ears.
And so this finally brings us to the important part of this post: what’s being done, and what can we do to make sure that it never happens again?
Option 1: Rely on the browser vendors
What’s particularly disturbing about the Trustwave fiasco is the response it’s gotten from the various browser manufacturers.
So far exactly one organization has taken a strong stand against this practice. The Mozilla foundation (makers of Firefox) recently sent a strongly-worded letter to all of their root CAs — demanding that they disclose whether such MITM certificates exist, and that they shut them down forthwith. With about 20% browser share (depending on who’s counting), Mozilla has the means to enforce this. Assuming the vendors are honest, and assuming Mozilla carries through on its promise. And assuming that Mozilla browser-share doesn’t fall any further.
That’s the good news. Less cheerful is the deafening silence from Apple, Microsoft and Google. These vendors control most of the remaining browser market, and to the best of my knowledge they’ve said nothing at all about the practice. Publicly, anyway. It’s possible that they’re working the issue privately; if so, more power to them. But in the absence of some evidence, I find it hard to take this on faith.
Option 2: Sunlight is the best disinfectant
The Trustwave fiasco exposes two basic problems with the CA model: (1) any CA can claim ownership of any domain, and (2) there’s no easy way to know which domains a CA has put its stamp on.
This last is very much by CA preference: CAs don’t want to reveal their doings, on the theory that it would harm their business. I can see where they’re coming from (especially if their business includes selling MITM certs!) Unfortunately, allowing CAs to operate without oversight is one of those quaint practices (like clicking on links sent by strangers) that made sense in a more innocent time, but no longer has much of a place in our world.
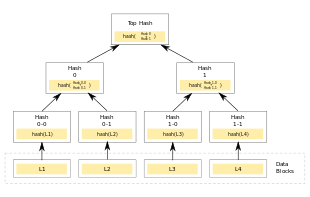 |
| Merkle tree (Wikipedia/CC) |
Ben Laurie and Adam Langley feel the same way, and they’ve developed a plan to do something about it. The basic idea is this:
- Every new certificate should be published in a public audit log. This log will be open to the world, which means that everyone can scan for illegal entries (i.e., their own domain appearing in somebody else’s certificate.)
- Anytime a web server hands out a certificate, it must prove that the certificate is contained in the list.
The beautiful thing is that this proof can be conducted relatively efficiently using a Merkle hash tree. The resulting proofs are quite short (log(N) hashes, where N is the total number of certificates). Browsers will need to obtain the current tree root, which requires either (a) periodic scanning of the tree, or some degree of trust in an authority, who will periodically distribute signed root nodes.
Along the same lines, the EFF has a similar proposal called the Sovereign Keys Project. SKP also proposes a public log, but places stronger requirements on what it takes to get into the log. It’s quite likely that in the long run these projects will merge, or give birth to something even better.
Option 3: Eternal vigilance
The problem with SKP and the Laurie/Langley proposal is that both require changes to the CA infrastructure. Someone will need to construct these audit logs; servers will have to start shipping hash proofs. Both can be incrementally deployed, but will only be effective once deployment reaches a certain level.
Another option is to dispense with this machinery altogether, and deal with rogue CAs today by subjecting them to contant, unwavering surveillance. This is the approach taken by CMU’s Perspectives plugin and by Moxie Marlinspike’s Convergence.
The core idea behind both of these systems is to use ‘network perspectives’ to determine whether the certificate you’re receiving is the same certificate that everyone else is. This helps to avoid MITMs, since presumably the attacker can only be in the ‘middle’ of so many network paths. To accomplish this, both systems deploy servers called Notaries — run on a volunteer basis — which you can call up whenever you receive an unknown certificate. They’ll compare your version of the cert to what they see from the same server, and help you ring the alarm if there’s a mismatch.
A limitation of this approach is privacy; these Notary servers obviously learn quite a bit about the sites you visit. Convergence extends the Perspectives plugin to address some of these issues, but fundamentally there’s no free lunch here. If you’re querying some external party, you’re leaking information.
One solution to this problem is to dispense with online notary queries altogether, and just ask people to carry a list of legitimate certificates with them. If we assume that there are 4 million active certificates in the world, we could easily fit them into a < 40MB Bloom filter. This would allow us to determine whether a cert is ‘on the list’ without making an online query. Of course, this requires someone to compile and maintain such a list. Fortunately there are folks already doing this, including the EFF’s SSL Observatory project.
Option 4: The hypothetical
The existence of these proposals is definitely heartening. It means that people are taking this seriously, and there’s an active technical discussion on how to make things better.
Since we’re in this mode, let me mention a few other things that could make a big difference in detecting exploits. For one thing, it would be awfully nice if web servers had a way to see things through their clients’ eyes. One obvious way to do this is through script: use Javascript to view the current server certificate, and report the details back to the server.
Of course this isn’t perfect — a clever MITM could strip the Javascript or tamper with it. Still, obfuscation is a heck of a lot easier then de-obfuscation, and it’s unlikely that a single attacker is going to win an arms race against a variety of sites.
Unfortunately, this idea has to be relegated to the ‘could be, should be’ dustbin, mostly because Javascript doesn’t have access to the current certificate info. I don’t really see the reason for this, and I sure hope that it changes in the future.
Option 5: The long arm of the law
I suppose the last option — perhaps the least popular — is just to treat CAs the same way that you’d treat any important, trustworthy organization in the real world. That means: you cheat, you pay the penalty. Just as we shouldn’t tolerate Bank of America knowingly opening a credit line in the name of a non-customer, we shouldn’t tolerate a CA doing the same.
Option 6: Vigilante justice
Ok, I’m only kidding about this one, cowboy. You can shut down that LOIC download right now.
In summary
I don’t know that there’s a magical vaccine that will make the the CA system secure, but I’ve come to believe that the current approach is not working. It’s not just examples like Trustwave, which (some might argue) is a relatively limited type of abuse. It’s that the Trustwave revelation comes in addition to a steady drumbeat of news about stolen keys, illegitimately-obtained certificates, and various other abuses.
While dealing with these problems might not be easy, what’s shocking is how easy it would be to at least detect and expose the abuses at the core of it — if various people agreed that this was a worthy goal. I do hope that people start taking this stuff seriously, mostly because being a radical is hard, hard work. I’m just not cut out for it.






 subordinate root (‘skeleton’) certificates to their corporate clients, for the explicit purpose of
subordinate root (‘skeleton’) certificates to their corporate clients, for the explicit purpose of 







{kind=link}
{kind=link}