Before we get started, fair warning: this is going to be a post about a fairly absurd (but  non-trivial!) attack on cryptographic systems. But that’s ok, because it’s based on a fairly absurd vulnerability.
non-trivial!) attack on cryptographic systems. But that’s ok, because it’s based on a fairly absurd vulnerability.
This work comes from Nadia Heninger, Shaanan Cohney and myself, and follows up on some work we’ve been doing to look into the security of pseudorandom number generation in deployed cryptographic devices. We made a “fun” web page about it and came up with a silly logo. But since this affects something like 25,000 deployed Fortinet devices, the whole thing is actually kind of depressing.
The paper is called “Practical state recovery attacks against legacy RNG implementation“, and it attacks an old vulnerability in a pseudorandom number generator called ANSI X9.31, which is used in a lot of government certified products. The TL;DR is that this ANSI generator really sucks, and is easy to misuse. Worse, when it’s misused — as it has been — some very bad things can happen to the cryptography that relies on it.
First, some background.
What is an ANSI, and why should I care?
A pseudorandom number generator (PRG) is a deterministic algorithm designed to “stretch” a short random seed into a large number of apparently random numbers. These algorithms are used ubiquitously in cryptographic software to supply all of the random bits that our protocols demand.
PRGs are so important, in fact, that the U.S. government has gone to some lengths to standardize them. Today there are three generators approved for use in the U.S. (FIPS) Cryptographic Module Validation Program. Up until 2016, there were four. This last one, which is called the ANSI X9.31 generator, is the one we’re going to talk about here.
ANSI X9.31 is a legacy pseudorandom generator based on a block cipher, typically AES. It takes as its initial seed a pair of values (K, V) where K is a key and V is an initial “seed” (or “state”). The generator now produces a long stream of pseudorandom bits by repeatedly applying the block cipher in the crazy arrangement below:
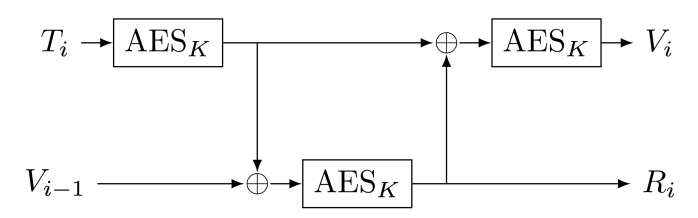
The diagram above illustrates one of the funny properties of the ANSI generator: namely, that while the state value V updates for each iteration of the generator, the key K never changes. It remains fixed throughout the entire process.
And this is a problem. Nearly twenty years ago, Kelsey, Schneier, Wagner and Hall pointed out that this fact makes the ANSI generator terribly insecure in the event that an attacker should ever learn the key K.
Specifically, if an attacker were to obtain K somehow, and then was able to learn only a single 16-byte raw output block (Ri) from a working PRG, she could do the following: (1) guess the timestamp T, (2) work backwards (decrypting using K) in order to recover the corresponding state value V, and now (3) run the generator forwards or backwards (with guesses for T) to obtain every previous and subsequent output of the generator.
Thus, if an application uses the ANSI generator to produce something like a random nonce (something that is typically sent in a protocol in cleartext), and also uses the generator to produce secret keys, this means an attacker could potentially recover those secret keys and completely break the protocol.
Of course, all of this requires that somehow the attacker learns the secret value K. At the time Kelsey et al. published their result, this was viewed as highly unlikely. After all, we’re really good at keeping secrets.
I assume you’re joking?
So far we’ve established that the ANSI generator is only secure if you can forever secure the value K. However, this seems fairly reasonable. Surely implementers won’t go around leaking their critical secrets all over the place. And certainly not in government-validated cryptographic modules. That would be crazy.
Yet crazy things do happen. We figured someone should probably check.
To see how the X9.31 key is managed in real products, our team developed a sophisticated analytic technique called “making a graduate student read every FIPS document on the CMVP website”.
Most of the documents were fairly vague. And yet, a small handful of widely-used cryptographic modules had language that was troubling. Specifically, several vendors include language in their security policy that indicates the ANSI key was either hard-coded, or at least installed in a factory — as opposed to being freshly generated at each device startup.
Of even more concern: at least one of the hard-coded vendors was Fortinet, a very popular and successful maker of VPN devices and firewalls.
To get more specific, it turns out that starting (apparently in 2009, or perhaps earlier), every FortiOS 4.x device has shipped with a hardcoded value for K. This key has been involved in generating virtually every random bit used to establish VPN connections on those appliances, using both the TLS and IPSec protocols. The implication is that anyone with the resources to simply reverse-engineer the FortiOS firmware (between 2009 and today) could theoretically have been able to recover K themselves — and thus passively decrypt any VPN connection.
(Note: Independent of our work, the ANSI generator was replaced with a more secure alternative as of FortiOS 5.x. As a result of our disclosure, it has also been patched in FortiOS 4.3.19. There are still lots of unpatched firewalls out there, however.)
What does the attack look like?
Running an attack against a VPN device requires three ingredients. The first is the key K, which can be recovered from the FortiOS firmware using a bit of elbow grease. Shaanan Cohney (the aforementioned graduate student) was able to pull it out with a bit of effort.
Next, the attacker must have access to some VPN or TLS traffic. It’s important to note that this is not an active attack. All you really need is a network position that’s capable of monitoring full two-sided TLS or IPSec VPN connections.
Specifically, the attacker needs a full AES block (16 bytes) worth of output from the ANSI generator, plus part of a second block to check success against. Fortunately both TLS and IPSec (IKE) include nonces of sufficient length to obtain this output, and both are drawn from the ANSI generator, which lives in the FortiOS kernel. The attacker also needs the Diffie-Hellman ephemeral public keys, which are part of the protocol transcript.
Finally, you need to know the timestamp Ti that was used to operate the generator. In FortiOS, these timestamps have a 1-microsecond resolution, so guessing them is actually a bit of a challenge. Fortunately, TLS and other protocols include the time-in-seconds as one of the outputs of the TLS protocol, so the actually guessing space is typically only about 2^20 at most. Still, this guessing proves to be one of the most costly elements of the attack.
Given all of the ingredients above, the attacker now decrypts the output block taken from the protocol nonce using K, guesses each possible Ti value, and then winds forward or backwards until she finds the random bits that were used to generate that party’s Diffie-Hellman secret key. Fortunately, the key and nonce are generated one after the other, so this is not quite as painful as it sounds. But it is fairly time consuming. Fortunately, computers are fast, so this is not a dealbreaker.
With the secret key in hand, it’s possible to fully decrypt the VPN connection, read all traffic, and modify the data as needed.
Does the attack really work?
Since we’re not the NSA, it’s awfully hard for us to actually apply this attack to real Fortinet VPN connections in the wild. Not to mention that it would be somewhat unethical.
However, there’s nothing really unethical about scanning for FortiOS devices that are online and willing to accept incoming traffic from the Internet. To validate the attack, the team conducted a large-scale scan of the entire IPv4 address space. Each time we found a device that appeared to present as a FortiOS 4.x VPN, we initiated a connection with it and tested to see if we could break our own connection.
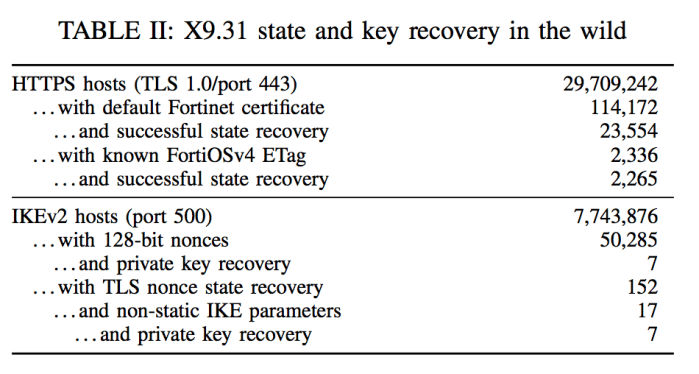
It turns out that there are a lot of FortiOS 4.x devices in the wild. Unfortunately, only a small number of them accept normal IPSec connections from strangers. Fortunately, however, a lot of them do accept TLS connections. Both protocol implementations use the same ANSI generator for their random numbers.
This scan allowed us to validate that — as of October 2017 — the vulnerability was present and exploitable on more than 25,000 Fortinet devices across the Internet. And this count is likely conservative, since these were simply the devices that bothered to answer us when we scanned. A more sophisticated adversary like a nation-state would have access to existing VPN connections in flight.
In short, if you’re using a legacy Fortinet VPN you should probably patch.
So what does it all mean?
There are really three lessons to be learned from a bug like this one.
The first is that people make mistakes. We should probably design our crypto and certification processes to anticipate that, and make it much harder for these mistakes to become catastrophic decryption vulnerabilities like the one in FortiOS 4.x. Enough said.
The second is that government crypto certifications are largely worthless. I realize that seems like a big conclusion to draw from a single vulnerability. But this isn’t just a single vendor — it’s potentially several vendors that all fell prey to the same well-known 20-year old vulnerability. When a vulnerability is old enough to vote, your testing labs should be finding it. If they’re not finding things like this, what value are they adding?
Finally, there’s a lesson here about government standards. ANSI X9.31 (and its cousin X9.17) is over twenty years old. It’s (fortunately) been deprecated as of 2016, but a huge number of products still use it. This algorithm should have disappeared ten years earlier — and yet here we are. It’s almost certain that this small Fortinet vulnerability is just the tip of the iceberg. Following on revelations of a possible deliberate backdoor in the Dual EC generator, none of this stuff looks good. It’s time to give serious thought to how we make cryptographic devices resilient — even against the people who are supposed to be helping us secure them.
But that’s a topic for a much longer post.



