It seems like these days I can’t eat breakfast without reading about some new encryption app that will (supposedly) revolutionize our communications — while making tyrannical regimes fall like cheap confetti.
It seems like these days I can’t eat breakfast without reading about some new encryption app that will (supposedly) revolutionize our communications — while making tyrannical regimes fall like cheap confetti.
This is exciting stuff, and I want to believe. After all, I’ve spent a lot of my professional life working on crypto, and it’s nice to imagine that people are actually going to start using it. At the same time, I worry that too much hype can be a bad thing — and could even get people killed.
Given what’s at stake, it seems worthwhile to sit down and look carefully at some of these new tools. How solid are they? What makes them different/better than what came before? And most importantly: should you trust them with your life?
To take a crack at answering these questions, I’m going to look at four apps that seem to be getting a lot of press in this area. In no particular order, these are
Cryptocat,
Silent Circle,
RedPhone and
Wickr.
A couple of notes…
Before we get to the details, a few stipulations. First, the apps we’ll talk about here are hardly the only apps that use encryption. In fact, these days almost everyone advertises some form of ‘end-to-end encryption‘ for your data. This has even gotten Skype and Blackberry into a bit of hot water with foreign governments.
However — and this is a critical point — ‘end-to-end encryption’ is rapidly becoming the most useless term in the security lexicon. That’s because actually encrypting stuff is not the interesting part. The real challenge turns out to be distributing users’ encryption keys securely, i.e., without relying on a trusted, central service.
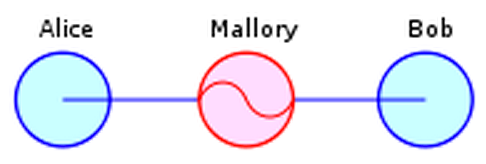
The problem here is simple: if I can compromise such a service, then I can convince you to use my encryption key instead of your intended recipient’s. In this scenario — known as a Man in the Middle (MITM) attack — all the encryption in the world won’t help you.
 |
| Man in the Middle attack (image credit: Privacy Canada via Wikipedia). Mallory convinces Alice and Bob to use her key, then transparently passes messages between the two. |
And this is where most ‘end-to-end’ commercial services (like Skype and iMessage) seem to fall down. Clients depend fundamentally on a central directly server to obtain their encryption keys. This works fine if the server really is trustworthy, but it’s huge problem if the server is ever compromised — or forced to engage in MITM attacks by a nosy government.
(An even worse variant of this attack comes from services that actually store your secret keys for you. In this case you’re truly dependent on their good behavior.*)
One important feature of the ‘new’ encryption apps is that they recognize this concern. That is, they don’t require you to trust the service. A few even point this out in their marketing material, and have included their own dishonesty into the threat model.
Cryptocat
Cryptocat is an IM application developed by Nadim Kobeissi, who — when he’s not busy being harassed by government officials — manages to put out out a very useable app. What truly distinguishes Cryptocat is its platform: it’s designed to run as a plugin inside of a web browser (Safari, Chrome and Firefox).
Living in a browser is Cryptocat’s greatest strength and greatest weakness. It’s a strength because (1) just about everyone has a browser, (2) the user interface is pretty and intuitive, and (3) the installation process is trivial. Cryptocat’s impressive user base testifies to the demand for such an application.
The weakness is that it runs in a frigging web browser.
To put a finer point on it: web browsers are some of the most complex software packages you can run on a consumer device. They do eight million things, most of which require them to process arbitrary and untrusted data. Running security-critical code in a browser is like having surgery in a hospital that doubles as a sardine cannery and sewage-treatment plant — maybe it’s fine, but you should be aware of the risk you’re taking.
If that’s not good enough for you: go check out this year’s pwn2own results.
For non-group messaging, Cryptocat uses a protocol known as off-the-record (OTR) and ships the encrypted data over Jabber/XMPP — using either Cryptocat’s own server, or the XMPP server of your choice. OTR is a well-studied protocol that does a form of dynamic key agreement, which means that two parties who have never previously spoken can quickly agree on a cryptographic key. To ensure that your key is valid (i.e., you’re not being tricked by a MITM attacker), Cryptocat presents users with a key fingerprint they can manually verify through a separate (voice) connection.
So how does Cryptocat stack up?
Code quality: Nadim has taken an enormous amount of crap from people over the past year or two, and the result has been a consistent and notable improvement in Cryptocat’s code quality. While Cryptocat is written in Javascript (aaggh!), the application is distributed as a plugin and not dumped out to you like typical script. This negates some of the most serious complaints people level at Javascript crypto, but not all of them! Cryptocat has also been subject to a couple of commercial code audits.
Crypto: All of the protocols are well-studied and designed by experts. Update: Jake Appelbaum reminds me that while this is true for one-on-one communications, it’s not true for the multi-party (group chat) OTR protocol — which is basically hand-rolled. Don’t use that.
Ease of use: My five year old can use Cryptocat.
Other notes: If the silent auto-update functionality is activated (in Chrome) it is technically possible for someone to compromise Cryptocat’s update keys and quietly push out a malicious version of the app. This concern probably applies to most applications, but it is something you should be aware of.
Should I use it to fight an oppressive regime? Oh god no.
Silent Circle

Silent Circle is the brainchild of PGP inventor Phil Zimmerman and a cadre of smart/paranoid folks. It actually consists of multiple apps, supporting VoIP/IM/PGP-based Email and videoconferencing — with an optional Snapchat-like self-destructing messages feature. The apps can essentially replace the standard Phone and Messages apps in your iPhone or Android device.
Silent Circle is a paid subscription service, which means it’s marketed to folks who (in theory, anyway) really care about their security, but also don’t want to scrounge around with messy open-source software — for example, journalists working in dangerous locations or business executives running overseas operations. In exchange for $240/year you get the ability to securely call other SilentCircle subscribers and to dial ordinary telephone (POTS) numbers.
The termination to POTS is SilentCircle’s best feature, and also its biggest concern. When you directly call another SilentCircle user, your connection is encrypted from your phone to theirs. When you dial a normal phone line, your connection will only be encrypted until it reaches SilentCircle’s servers. From there it will travel on normal, tappable phone lines.
Now most users will probably understand this, and SilentCircle certainly does its best to make sure people do. Still, most users aren’t experts, and it’s easy to imagine a typical user getting confused — and possibly assuming they’re safer than they actually are.
SilentCircle uses ZRTP (and a variant called SCIMP) to generate the keys used in communications. It doesn’t require you to trust a central directory server, or to send your keys outside of the device. Your protection against MITM comes from two features: (1) the app presents a ‘short authentication string’ that users can verbally compare before they communicate, and (2) after you’ve successfully communicated the first time, it caches a ‘secret’ that can be used to protect future sessions.
Overall code quality: It took a while for SilentCircle to publish their code, but they’ve finally put most of it online. It’s much less fun to look at SilentCircle than it is to poke at Cryptocat — mostly because Nadim’s reactions are more entertaining — but the code for SilentCircle looks ok. (I’ve seen a couple of minor comments, but nobody’s found any security issues.) Moreover, the app has been independently audited and given a clean bill of health.
Crypto: SilentCircle uses ZRTP, which I dislike because it’s so complex — it’s like a choose-your-own-adventure by sadists. But ZRTP is old and well-studied so it’s unlikely that there are any serious issues lurking in it. The messaging app uses a simplified variant called SCIMP (Silent Circle Instant Messaging Protocol) which seems much better, since it ditches most of the crazy options I dislike about ZRTP. I’m pretty confident that both of these protocols work just fine.
Ease of use: To quote SilentCircle’s PR: so simple even an MBA can use it. (No, I’m kidding, they don’t say that. They just think it.)
Other thoughts: Rumor has it that the market price for an iOS vulnerability is currently near $500,000. That doesn’t mean iOS (or Silent Circle’s app) is bulletproof. But it should give you a little bit of confidence. If you’re being targeted with an iOS software vulnerability, then someone really wants you.
Should I use this to fight my oppressive regime? SilentCircle’s founders have made it clear that they’ll chew off their own legs before they allow themselves to be a party to eavesdropping on their clients. But even so — I would still have to think on this for a while.
RedPhone/TextSecure
RedPhone and TextSecure are developed by Moxie Marlinspike’s Open Whisper Systems. Note that OWS is actually Moxie’s second company — the original Whisper Systems was purchased by Twitter a couple of years back — not for the software, mind you; just to get hold of Moxie for a while.
RedPhone does a much of what SilentCircle does, though without the paid subscription and termination to POTS. In fact, I’m not quite sure if you can terminate it to POTS (I’ll update if I find out.)
Like Silent Circle, RedPhone uses ZRTP to establish keys, then encrypts voice data using AES. Consequently, most of what I said for SilentCircle also applies here, including the use of a short authentication string to prevent MITM attacks.
Overall code quality: After reading Moxie’s RedPhone code the first time, I literally discovered a line of drool running down my face. It’s really nice.
In fact, it was so nice that I decided to rough it up a little. I assigned it to the grad students in my Practical Crypto course — assuming that they’d find something, anything to take the shine off of it. Unfortunately they basically failed on this score (though see ‘Other thoughts’ below). In short: it’s very well written.
Crypto: Most of what I said about Silent Circle applies here, except that RedPhone uses only ZRTP, not SCIMP. However, RedPhone’s implementation of ZRTP is somewhat simplified and avoids most of the options that make ZRTP a pain to deal with.
Other thoughts: In fairness to my students, they did point out that Redphone does not retain a cache of secrets from connection to connection. Technically this is an optional feature of ZRTP, so it’s not wrong to omit it. However, it means that you have to verify the authentication string on every single call. Moxie is working on this, so it may change in the future.
Should I use this to fight my oppressive regime? Oh look, a pony!
Wickr
Wickr is an encrypted Snapchat-like app for the iPhone. Like the above applications it provides for instant messaging, but it also focuses heavily on the message destruction feature. Chats/messages can be set to self-destruct after a pre-specified period of time.
I’ve included Wickr on this list because I’ve seen it mentioned in a handful of respectable media outlets over the past few months. This means that people are either using Wickr, or that Wickr has very good PR folks. I also included it because it was at least partially designed by Dan Kaminsky, who generally knows his stuff.
Unfortunately I can’t say too much about Wickr because — to date — there’s virtually no technical information available on it. (Not even a white paper!) However, based on Tweets with Dan and this short post on the LiberationTech mailing list, I believe that Wickr uses a centralized directory server to share keys. In theory this could be ok if it provided a mechanism to compare key fingerprints between users, and/or detect invalid keys. But currently this does not seem to be the case.
As for the destruction of secrets, well, this does seem like a nice idea, particularly if the destruction is enforced cryptographically. Unfortunately this is a fundamentally hard problem to solve correctly: if I can get a copy of your phone’s memory while the message is there, I can keep the message forever.
Overall code quality: Who knows.
Crypto: Current versions use some kind of RSA-based key agreement. According to Dan, the next generation will use elliptic curve crypto with perfect forward secrecy. But the real horses head is the (apparent) reliance on a central directory server, which makes the service much more vulnerable to MITM.
Ease of use: Very easy. Just set your message expiration date, key in the destruct time, and send away.
Should I use this to fight my oppressive regime? Yes, as long your fight consists of sending naughty self-portraits to your comrades-at-arms. Otherwise, probably not.
In summary
If you’ve made it this far, I’m guessing you still have one burning question. Namely: What app should I use if I’m trying to overthrow my government?
The simple answer is that I just don’t know. It’s not an easy question.
Each of the above apps seem quite good, cryptographically speaking. But that’s not the problem. The real issue is that they each run on a vulnerable, networked platform. If I really had to trust my life to a piece of software, I would probably use something much less flashy — GnuPG, maybe, running on an isolated computer locked in a basement.
Then I would probably stay locked in the basement with it.
But not everyone is a coward like me. The widespread availability of smartphones has already changed the way people interact with their government. These encryption apps could well be the first wave in an entirely new revolution — one that makes truly private communication a reality.
Notes:
* Some services actually know and store your private keys, while others operate as a Certificate Authority, allowing you to ‘certify’ new public keys under your name. Either of these models makes eavesdropping relatively easy for someone with access to the server.
 A friend who’s learning cryptography writes with a few questions about block ciphers:
A friend who’s learning cryptography writes with a few questions about block ciphers: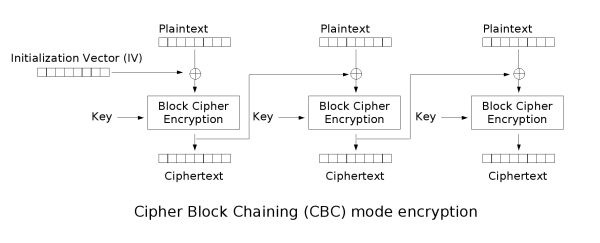






.svg/570px-CBC-MAC_structure_(en).svg.png)