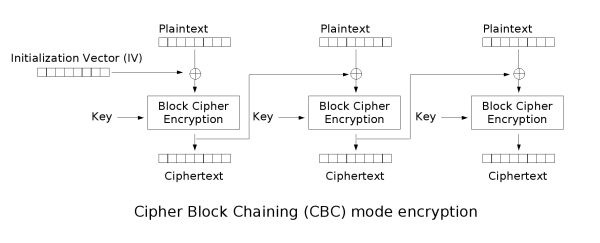
Protocols
Once upon a time there were no cryptographic protocols. Most cryptographic communication took the form of one-move operations like this one:

There are plenty of things that can go wrong in this scenario. But if you’re the sender (as opposed to the sap carrying the message) you could restrict your concerns to the security of the primitive (e.g., cipher), or perhaps to the method of key distribution. Admittedly, through most of history it was almost impossible to get these things “right”. Still, you knew where your weaknesses were.
Not only is the communication here vastly more complicated, but it takes place in the presence of a more dangerous adversary. For one thing, he owns the communication channel and the hardware — it’s probably sitting in his living room or lab. Most importantly, he’s got time on his hands. Your typical barbarian only got one chance to capture a ciphertext. If this guy needs to, he can run the protocol 100,000 times.
Now, most people will tell you that cryptography is one of the most settled areas of computer security. Relative to the disaster that is software security, this is true. Particularly in when it comes to standardized cryptographic primitives, we’ve made enormous progress — to the point where attacks lag by years, if not decades (though, see my previous post). If you use reasonable primitives, your attacker will not get you by breaking the algorithm.
As Gibson said, the future is here, but it’s not evenly distributed. And in the field of cryptography, protocol design is one area in which progress has definitely not been as fast.
We’ve learned a huge amount about what not to do. We have tools that can sometimes catch us when we trip up. Unfortunately, we still don’t have a widely-accepted methodology for building provably-secure protocols that area as practical as they are safe to use.
Maybe I’m getting ahead of myself. What do I even mean when I refer to a “cryptographic protocol”?
For the purposes of this discussion, a protocol is an interactive communication between two or more parties. Obviously a cryptographic protocol is one that combines cryptographic primitives like encryption, digital signing, and key agreement to achieve some security goal.
What makes cryptographic protocol special is the threat. When we analyze cryptographic protocols, we assume that the protocol will be conducted in the presence of an adversary, who (at minimum) eavesdrops on all communications. More commonly we assume that the adversary also has the ability to record, inject and modify communications flowing across the wire. This feature is what makes cryptographic protocols so much more interesting — and troublesome — than the other types of protocol that crop up in computer networking.
A first example: SSL and TLS
SSL and its younger cousin TLS are probably the best-known security protocols on the Internet. The most recent version is TLS 1.2 and we think it’s a pretty solid protocol now. But it didn’t reach achieve this status in one fell swoop. The history of each SSL/TLS revision includes a number of patches, each improving on various flaws found in the previous version.
The original SSL v1 was a proprietary protocol created by Netscape Inc. back in 1994 to secure web connections between a browser and a web server. SSL v2 was standardized the next year. The protocol is a highly flexible framework by which two parties who have never met before can authenticate each other, agree on transport keys, and encrypt/authenticate data. Part of the flexible nature of the protocol is that it was designed to support many different ciphersuites and modes of operation. For example, it’s possible to configure SSL to authenticate data without encrypting it, even though almost nobody actually does this.
Now let me be clear. There’s nothing wrong with flexibility, per se. The benefits of flexibility, extensibility and modularity are enormous in software design — there’s nothing worse than re-factoring 100,000 lines of production code because the original designers didn’t consider the possibility of new requirements. It’s just that when it comes to building a secure cryptographic protocol, flexibility almost always works against you.
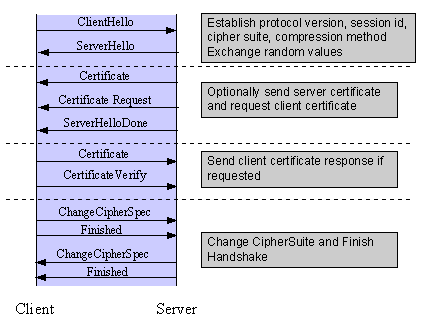
There’s nothing fundamentally wrong with ciphersuite negotiation. It clearly gives a lot of flexibility to SSL, since the protocol can easily be upgraded to support new ciphersuites without breaking compatibility with older implementations. From the spec, you can see that this section of the protocol was treated as something of an abstraction by the designers. The negotiation is handled via its own dedicated set of messages. Looking at this, you can almost hear some long-ago dry erase marker scribbling “ciphersuite negotiation messages go here”.
Unfortunately, in providing all of this flexibility, the designers of SSL v2 essentially created many implicit protocols, each of which could be instantiated by changing the details of the ciphersuite negotiation process. Worse, unlike the messages in the “main” protocol, the ciphersuite negotiation messages exchanged between client and server in the SSLv2 protocol were not authenticated.
In practice, this means that our adversary can sit on the wire in between the two, replacing and editing the messages passing by to make it look like each party only supports the lowest common ciphersuite. Thus, two parties that both support strong 128-bit encryption can be easily tricked into settling on the 40-bit variant. And 40 bits is not good.
Now, the good news is that this vulnerability is a piece of history. It was closed in SSL v3, and the fix has held up well through the present day. But that doesn’t mean TLS and SSL are home free.
This post is continued in the next section: “Where Things Fall Apart: Protocols (Part 2)”.