
It’s been a busy week for crypto flaws. So busy in fact, that I’m totally overwhelmed and paralyzed trying to write about them. It’s made blogging almost impossible.
So let’s just blast through it, then we can get to the subject I actually want to talk about.
First, at the start of the week we received news that many Android applications and a few (critical!) Java libraries simply don’t validate certificates on TLS/SSL connections. This is disastrous, embarrassing and stupid, since lack of certificate verification makes TLS trivially vulnerable to man-in-the-middle attacks. I was going to say something shrill and over-the-top about all of this, but turns out that Threatpost has already totally beaten me there with this synopsis:
The death knell for SSL is getting louder.
Yes indeed, Threatpost. Thank you for making me feel better.
In other news, we learned that major email providers — who should remain nameless, but are actually Microsoft, Google, Apple, Yahoo and everyone else — have been competing to see who can deploy the shortest RSA key for DomainKeys Identified Mail (DKIM). I’m told that Yahoo was ahead with 384 bits, but Microsoft had a research team working on a 22-bit key and Apple had abandoned keys altogether, opting for a simple note from Tim Cook asserting that any invalid email messages were probably the recipient’s fault. (Ba-dum-tschch.)
So that’s the headline news, and I don’t want to write about any of it.
What I do want to write about is a result that’s gotten a lot less attention — mostly because it’s subtle, falls into the category of ‘things we thought of knew about, but didn’t explore‘ and because it involves Hidden Markov models — which are to tech reporters as raw garlic and silver are to vampires.
This new result is by Zhang, Juels, Reiter and Ristenpart, and it appeared in the ACM CCS conference just a few weeks ago, and it deals with something very relevant to the way we build modern systems. Specifically, if we’re going to go and stick all of cryptographic services in cloud-based VMs, how secure can we possibly expect them to be?
The answer is: unfortunately, not very. To get into the details I’m going to use the standard ‘fun’ question/answer format I usually save for these kinds of attacks.
Why would I put my cryptography in a VM anyway?
In case you missed it, the cloud is our future. The days of running our own cranky hardware and dealing with problems like power-supply faults are long gone. If you’re deploying a new service, there’s a good chance it’ll be at least partly cloud-based. There’s a decent chance it will be entirely cloud-based.
Take Instagram, for instance. Their entire $1bn service runs on a few hundred cleverly-managed EC2 instances. While Instagram itself isn’t exactly a security product, they do use TLS and SSH (presumably on the instances themselves), and this implies public key crypto and the use of secret keys.
Now this shouldn’t be a problem, but VM instances often share physical hardware with other instances, and since EC2 is a public service, those co-resident VMs may not be entirely friendly. The major threat here is, of course, software vulnerabilities — things that can let an attacker break out of one VM and into another. But even if you perfect the software, there’s another more insidious threat: namely, that the attacker VM instance could be able to run a side-channel attack on the co-resident VM.
This threat has long been discussed, and security people generally agree that it’s a concern. But actually implementing such an attack has proven surprisingly difficult. This is because real hypervisors put a lot of fluff between the attacking process and the bare metal of the server. Different VMs often run on different cores. Moreover, since each VM has an entire OS running inside of it, there’s tons of noise.
In fact, there’s been plenty of reason to wonder if these attacks are simply the product of security researchers’ fevered imaginations, or if something we need to worry about. What Zhang, Juels, Reiter and Ristenpart tell us is: yes, we should worry. And oh boy, do they do it in a nifty way.
So what is it and how does it work?
The new result focuses specifically on the Xen Hypervisor, which is the one actually used by services like Amazon EC2. Although the attack was not implemented in EC2 itself, it focuses on similar hardware: multi-core servers with SMT turned off. The threat model assumes that the attacker and victim VM are co-resident on the machine, and that the victim is decrypting an Elgamal ciphertext using libgcrypt v.1.5.0.
Now, Elgamal encryption is a great example for side-channel attacks, since it’s implemented by taking a portion of the ciphertext, which we’ll call x, and computing x^e mod N, where e is the secret key and N is (typically) a prime number. This exponentiation is implemented via the ‘square and multiply‘ algorithm, shown in the figure below:
 |
| Square and multiply algorithm (source: Zhang et al.) |
The first thing you notice about square-and-multiply is that its operation depends fundamentally on the bits of the secret key. If the ith bit of e is 1, the steps labeled (M) and (R) are conducted. If that bit is 0, they aren’t. The bits of the key results in a distinctive set of computations that can be detected if the attacking VM is able to precisely monitor the hardware state.
Now, side-channel attacks on square-and-multiply are not new. They date back at least to Paul Kocher’s observations in the mid-to-late 90s using power and operating time as a channel, and they’ve been repeatedly optimized as technology advances. More recent attacks have exploited cache misses in a shared processor cache (typical in hyper-threading environments) as a means by which a single process can monitor the execution of another one.
However, while these attacks have worked from one process to another, they’ve never been applied to the full Xen VM setting. This is a pretty challenging problem for a variety of reasons, including::
- The difficulty of getting the attacking process to run frequently enough to take precise measurements.
- The problem that VCPUs can be assigned to different cores, or irrelevant VCPUs can be assigned to the same core.
- Noisy measurements that give only probabilistic answers about which operations occurred on the target process.
So what’s the basic idea?
At a fundamental level, the attack in this paper is quite similar to previous attacks that worked only across processes. The attacking VM first ‘primes‘ the L1 instruction cache by allocating continuous memory pages, then executing a series of instructions designed to load the cache with cache-line-sized blocks it controls.
The attacker then gives up execution and hopes that the target VM will run next on the same core — and moreover, that the target is in the process of running the square-and-multiply operation. If it is, the target will cause a few cache-line-sized blocks of the attacker’s instructions to be evicted from the cache. Which blocks are evicted is highly dependent on the operations that the attacker conducts.
To see what happened, the attacking VM must recover control as quickly as possible. It then ‘probes‘ to see which blocks have been evicted from the cache set. (This is done by executing the same instructions and timing the results. If a given block has been evicted from the cache, execution will result in a cache miss and a measurable delay.) By compiling a list of which blocks were missing, the attacker gains insight into which instructions may have been executed while the target VM was running.
A big challenge for the attacker is the need to regain control quickly. Wait too long and all kinds of things will happen — the state of the cache won’t give any useful information.
Normally Xen doesn’t allow VCPUs to rapidly regain control, but there are a few exceptions: Xen gives high priority to Virtual CPUs (VCPUs) that receive an interrupt. The authors were able to exploit this by running a 2-VCPU VM, where the second VCPU’s only job is to issue Inter-Processor Interrupts (IPIs) in an effort to get the first VCPU back in control as quickly as possible. Using this approach they were able to get back in the saddle within about 16 microseconds — an eternity in processing time, but enough to give useful information.
But isn’t that data noisy as hell? And fragmented?
Yes. The challenge here is that the attacking VM has no control over where in the computation it will jump in. It could get just a small fragment of the square-and-multiply operation (which is hundreds or thousands operations long), it could jump into the OS kernel, it could even get the wrong VM, thanks to the fact that they can run on any core. Plus the data could be pretty noisy.
The solution to these problems is what’s so nifty about this paper. First, they don’t just monitor one execution — they assume that the device is constantly decrypting different ciphertexts, all with the same key. This is a pretty reasonable assumption for something like an SSL web server.
Next, they use machine learning techniques to identify which of the many possible instruction sequences are associated with particular cache measurements. This requires the researchers to train the algorithm beforehand on the target hardware, having the target VCPU conduct of square, multiply and modular reduce calls in order build a training model. During the attack, the data was further processed using a Hidden Markov Model to eliminate errors and bogus measurements from non-cryptographic processes.
Even after all this work, the attacker winds up with thousands of fragments, some of which contain errors or low-confidence results. These can be compared against each other to reduce errors, then stitched together to recover the key itself. Fortunately this is a problem that’s been solved in many other domains (most famously: DNA sequencing), and the techniques used here are quite similar.
A good way to illustrate the process is to present a totally made-up example, in which six fragments are reconstructed to form a single spanning sequence:
S1: SRSRMRSRMRSRSRSMR
S2: MRSRSRSRMR**SRMRSR
S3: SRMRSRSR
S4: MRSRSRSR**SRMRSR
S5: MR*RSRMRSRMRSR
S6: MRSRSRMRSRSRSRMR
————————————————
SRSRMRSRMRSRSRSMRSRSRMRSRSRSRMRSRMRSRSRMRSRMRSR
This is obviously a huge simplification of a very neat (and complex) process that’s very well described in the paper. And if all this technical stuff is too much for you: it’s basically like the scene in Argo where the little kids reconstructed the shredded photos of the embassy workers. Just without the kids. Or the photos.
So does it actually work?
It would be a hell of a bad paper if it didn’t.
With everything in place, the researchers applied their attack against a 4096-bit Elgamal public key, which (due to an optimization in libgcrypt) actually has a 457-bit private key e. After several hours of data collection, they were able to obtain about 1000 key-related fragments, of which 330 turned out to be long enough to be useful for key reconstruction. These allowed the attackers to reconstruct the full key with only a few missing bits, and those they were able to guess using brute force.
And that, as they say, is the ballgame.
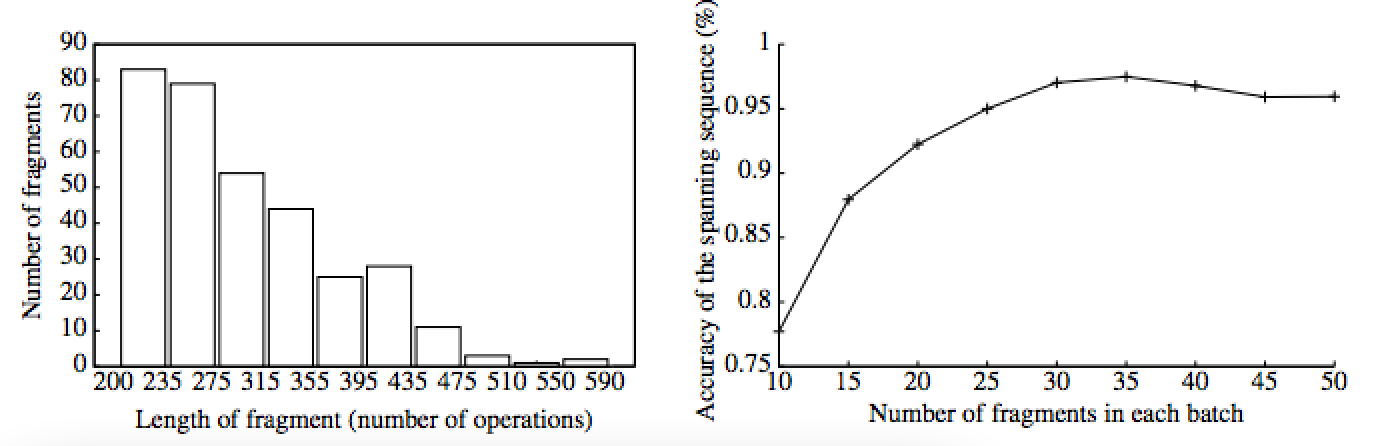 |
| Left: Fragment size vs. number of fragments recovered, Right: sequence accuracy as a function of fragments in a batch. (source: Zhang et al.) |
Oh my god, we’re all going to die.
I would note that this isn’t actually a question. But before you start freaking out and pulling down your cloud VMs, a few points of order.
First: there’s a reason these researchers did this with libgcrypt and Elgamal, and not, say OpenSSL and RSA (which would be a whole lot more useful). That’s because libgcrypt’s Elgamal implementation is the cryptographic equivalent of a 1984 Stanley lawnmower engine — it uses textbook square-and-multiply with no ugly optimizations to get in the way. OpenSSL RSA decryption, on the other hand, is more like a 2012 Audi turbo-diesel: it uses windowing and CRT and blinding and two different types of multiplication, all of which make it a real pain in the butt to deal with.
Secondly, this attack requires a perfect set of conditions. As proposed it works only works with two VMs, and requires specific training on the target hardware. This doesn’t mean that the attack isn’t viable (especially since cloud services probably do use lots of identical hardware), but it does mean that messiness — the kind you get in real cloud deployments — is going to be more of an obstacle than it seems.
One last thing worth mentioning is that before you can attack a VM, you have to get your attack VM onto the same physical hardware with your target. This seems like a pretty big challenge. Unfortunately, some slightly older research indicates that this is actually very feasible in existing cloud deployments. In fact, for only a few dollars, researchers were able to co-locate themselves with a given target VM with about 40% probability.
In the short term, you certainly shouldn’t panic about this, especially given how elaborate the attack is. But it does indicate that we should be thinking very hard about side-channel attacks, and considering how we can harden our systems and VMMs to be sure they aren’t going to happen to us.

Very nice summary!
I haven't seen any discussion regarding the weakness of the UNIX random(4), functionality in a virtual machine. And, yes, I've looked.
According to all the versions of UNIX manual pages for random(4) and urandom(4) I have read over the past decade, interrupts and other forms of electronic noise form a significant input to the resulting pool of random numbers (AKA 'pool of entropy').
But VMs don't have physical buses or interrupts. And so where does the entropy come from?
Some random device generators will give you a number even if the 'pool' is empty. It just won't be as random as it should be.
And so one might not even notice … unless one looked.
And so I wonder if keys generated on VMs might not be as cryptographically strong as keys generated on physical instances?
I mentioned this (ever so briefly) in an earlier post on random number generation. But I agree it hasn't gotten much detailed treatment:
https://blog.cryptographyengineering.com/2012/02/random-number-generation-illustrated.html
See : http://pages.cs.wisc.edu/~rist/papers/sslhedge.pdf
In short, your random number might be the same as someone else's random number!
While you are allowed to choose where your guest OS runs, this sort of attack is possible.
However, if you can control where you run then you're probably an admin of the system and can do “bad stuff” with much less hassle than this.
I hope that cloud providers will stop letting people choose where they run or who they run with. It's sort of breaking the idea of cloud, you shouldn't care where you run, that's up to the provider to optimise, not you. That would make attacks a lot harder. Right now you're running on host A with your target, in a minute you might be running on host C with your target on host B. And you don't even know that host C is in a different continent to host B or A. You may not see your target again for a month.
If you want to absolutely avoid any remote possibility of this attack and can afford it, You can always launch a dedicated VM instance ensuring an attacker is not sharing the same hardware. In EC2 You can do this on a VPC and launch a dedicated instance.
You have got a great deal of expressing a lot to supply. Let's hope people understand this kind of check out to your site.
A fantastic blog always comes-up with new and helpful information and while reading I have feel that this blog is really have all those quality that qualify a blog to be a good one.
Incredible solutions of your stuff, people.I have examine your blog post and i had a extremely helpful and experienced
Information and facts from the blog page.it is a legitimate very good article.
Everyone loves what exactly you’ve attained listed here, surely like what you’re explaining and the best way in which you claim it.
You’re rendering it interesting and you carry on and care for to remain it realistic.
Hello! I really wish to give an fantastical thumbs up for your awesome knowledge you have got on this post. I will apt to be returning to your website for further shortly.
Hello sir, I got you by Google search.
This article will help everyone to know so much important information about on cryptographyengineering.com.It is very helpful in using social media sites. It is very alternative for people and helpful to anybody. You may know me by it No Pay No Stay Provides Services For Eviction Process, Eviction Service, Houston Eviction Texas, Vacate Notices, File For Eviction, Property Management, Sell Your Property And More.
Thank You Very Much For a Nice & Cool Article.
This post truly made my day. You can’t imagine just how much time I had spent for this information! Thanks. all about essay writing
Thanks for sharing your great ideas with us through this site. custom logo design service
This was a really fantastic post that I really do appreciate. support in dissertation , thesis provider , writing service , pay for accounting help , uk university , written papers
This post made my day. Much a informative blog. Really great search. Well Done. funny pictures
I am surfing via google and i found your blog full of interesting material really enjoyed here and i am wondering that you will keep updated on every post.
I guess you are being writing on the topic from a long time. You must be having a good comand over this subject. You should shart to publish the information on the e-book stores.
To create a such kind of article is really amazing,I daily read your blogs and give my announcement for that here this article is too great and so entertaining.
It’s easy to scan, the content is good, and you’re an informed author not like most of the blogs I locate when reckoning on this subject.
I am so pleased for your content.Really thank you! Really Awesome.
doctor who jacket
Anything you love doing would surely give you more drive to be more productive in the said field or expertise.
This is a great inspiring article.I am pretty much pleased with your good work.You put really helpful information. Keep it up.
agen bola
This is because real hypervisors put a lot of fluff between the attacking process and the bare metal of the server.
Batman Begins Leather Jacket
Brad Pitt jacket
Thank you for for sharing so great thing to us. I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post nice post, thanks for sharing.
Jasa SEO