A few days ago I had the pleasure of hosting Kenny Paterson, who braved snow and historic cold (by Baltimore standards) to come talk to us about encrypted databases.
Kenny’s newest result is with first authors Paul Grubbs, Marie-Sarah Lacharité and Brice Minaud (let’s call it GLMP). It isn’t so much about building encrypted databases, as it is about the risks of building them badly. And — for reasons I will get into shortly — there have been a lot of badly-constructed encrypted database schemes going around. What GLMP point out is that this weakness isn’t so much a knock against the authors of those schemes, but rather, an indication that they may just be trying to do the impossible.
Hopefully this is a good enough start to get you drawn in. Which is excellent, because I’m going to need to give you a lot of background.
What’s an “encrypted” database, and why are they a problem?
Databases (both relational and otherwise) are a pretty important part of the computing experience. Modern systems make vast use of databases and their accompanying query technology in order to power just about every software application we depend on.
Because these databases often contain sensitive information, there has been a strong push to secure that data. A key goal is to encrypt the contents of the database, so that a malicious database operator (or a hacker) can’t get access to it if they compromise a single machine. If we lived in a world where security was all that mattered, the encryption part would be pretty easy: database records are, after all, just blobs of data — and we know how to encrypt those. So we could generate a cryptographic key on our local machine, encrypt the data before we upload it to a vulnerable database server, and just keep that key locally on our client computer.
Voila: we’re safe against a database hack!
The problem with this approach is that encrypting the database records leaves us with a database full of opaque, unreadable encrypted junk. Since we have the decryption key on our client, we can decrypt and read those records after we’ve downloaded them. But this approach completely disables one of the most useful features of modern databases: the ability for the database server itself to search (or query) the database for specific records, so that the client doesn’t have to.
Unfortunately, standard encryption borks search capability pretty badly. If I want to search a database for, say, employees whose salary is between $50,000 and $100,000, my database is helpless: all it sees is row after row of encrypted gibberish. In the worst case, the client will have to download all of the data rows and search them itself — yuck.
This has led to much wailing and gnashing of teeth in the database community. As a result, many cryptographers (and a distressing number of non-cryptographers) have tried to fix the problem with “fancier” crypto. This has not gone very well.
It would take me a hundred years to detail all of various solutions that have been put forward. But let me just hit a few of the high points:
- Some proposals have suggested using deterministic encryption to encrypt database records. Deterministic encryption ensures that a given plaintext will always encrypt to a single ciphertext value, at least for a given key. This enables exact-match queries: a client can simply encrypt the exact value (“John Smith”) that it’s searching for, and ask the database to identify encrypted rows that match it.
- Of course, exact-match queries don’t support more powerful features. Most databases also need to support range queries. One approach to this is something called order revealing encryption (or its weaker sibling, order preserving encryption). These do exactly what they say they do: they allow the database to compare two encrypted records to determine which plaintext is greater than the other.
- Some people have proposed to use trusted hardware to solve these problems in a “simpler” way, but as we like to say in cryptography: if we actually had trusted hardware, nobody would pay our salaries. And, speaking more seriously, even hardware might not stop the leakage-based attacks discussed below.
This summary barely scratches the surface of this problem, and frankly you don’t need to know all the details for the purpose of this blog post.
What you do need to know is that each of the above proposals entails has some degree of “leakage”. Namely, if I’m an attacker who is able to compromise the database, both to see its contents and to see how it responds when you (a legitimate user) makes a query, then I can learn something about the data being queried.
What some examples of leakage, and what’s a leakage function?
Leakage is a (nearly) unavoidable byproduct of an encrypted database that supports queries. It can happen when the attacker simply looks at the encrypted data, as she might if she was able to dump the contents of your database and post them on the dark web. But a more powerful type of leakage occurs when the attacker is able to compromise your database server and observe the query interaction between legitimate client(s) and your database.
Take deterministic encryption, for instance.
Deterministic encryption has the very useful, but also unpleasant feature that the same plaintext will always encrypt to the same ciphertext. This leads to very obvious types of leakage, in the sense that an attacker can see repeated records in the dataset itself. Extending this to the active setting, if a legitimate client queries on a specific encrypted value, the attacker can see exactly which records match the attacker’s encrypted value. She can see how often each value occurs, which gives and indication of what value it might be (e.g., the last name “Smith” is more common than “Azriel”.) All of these vectors leak valuable information to an attacker.
Other systems leak more. Order-preserving encryption leaks the exact order of a list of underlying records, because it causes the resulting ciphertexts to have the same order. This is great for searching and sorting, but unfortunately it leaks tons of useful information to an attacker. Indeed, researchers have shown that, in real datasets, an ordering can be combined with knowledge about the record distribution in order to (approximately) reconstruct the contents of an encrypted database.
Fancier order-revealing encryption schemes aren’t quite so careless with your confidentiality: they enable the legitimate client to perform range queries, but without leaking the full ordering so trivially. This approach can leak less information: but a persistent attacker will still learn some data from observing a query and its response — at a minimum, she will learn which rows constitute the response to a query, since the database must pack up the matching records and send them over to the client.
If you’re having trouble visualizing what this last type of leakage might look like, here’s a picture that shows what an attacker might see when a user queries an unencrypted database vs. what the attacker might see with a really “good” encrypted database that supports range queries:
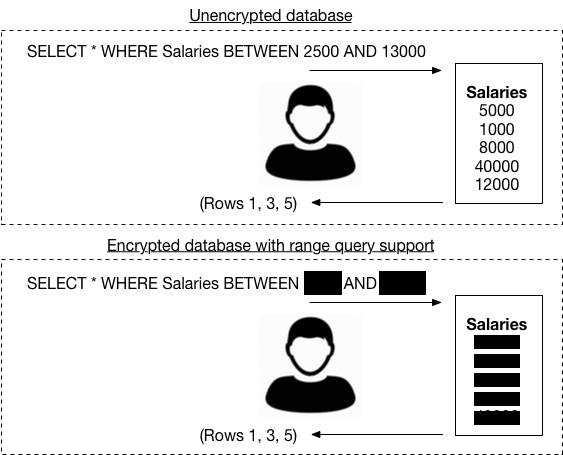
So the TL;DR here is that many encrypted database schemes have some sort of “leakage”, and this leakage can potentially reveal information about (a) what a client is querying on, and (b) what data is in the actual database.
But surely cryptographers don’t build leaky schemes?
Sometimes the perfect is the enemy of the good.
Cryptographers could spend a million years stressing themselves to death over the practical impact of different types of leakage. They could also try to do things perfectly using expensive techniques like fully-homomorphic encryption and oblivious RAM — but the results would be highly inefficient. So a common view in the field is researchers should do the very best we can, and then carefully explain to users what the risks are.
For example, a real database system might provide the following guarantee:
“Records are opaque. If the user queries for all records BETWEEN some hidden values X AND Y then all the database will learn is the row numbers of the records that match this range, and nothing else.”
This is a pretty awesome guarantee, particularly if you can formalize it and prove that a scheme achieves it. And indeed, this is something that researchers have tried to do. The formalized description is typically achieved by defining something called a leakage function. It might not be possible to prove that a scheme is absolutely private, but we can prove that it only leaks as much as the leakage function allows.
Now, I may be overdoing this slightly, but I want to be very clear about this next part:
Proving your encrypted database protocol is secure with respect to a specific leakage function does not mean it is safe to use in practice. What it means is that you are punting that question to the application developer, who is presumed to know how this leakage will affect their dataset and their security needs. Your leakage function and proof simply tell the app developer what information your scheme is (provably) going to protect, and what it won’t.
The obvious problem with this approach is that application developers probably don’t have any idea what’s safe to use either. Helping them to figure this out is one goal of this new GLMP paper and its related work.
So what leaks from these schemes?
GLMP don’t look at a specific encryption scheme. Rather, they ask a more general question: let’s imagine that we can only see that a legitimate user has made a range query — but not what the actual queried range values are. Further, let’s assume we can also see which records the database returns for that query, but not their actual values.
How much does just this information tell us about the contents of the database?
You can see that this is a very limited amount of leakage. Indeed, it is possibly the least amount of leakage you could imagine for any system that supports range queries, and is also efficient. So in one sense, you could say authors are asking a different and much more important question: are any of these encrypted databases actually secure?
The answer is somewhat worrying.
Can you give me a simple, illuminating example?
Let’s say I’m an attacker who has compromised a database, and observes the following two range queries/results from a legitimate client:
Query 1: SELECT * FROM Salaries BETWEEN ⚙️ and 🕹 Result 1: (rows 1, 3, 5)
Query 2: SELECT * FROM Salaries BETWEEN 😨 and 🎱 Result 2: (rows 1, 43, 3, 5)
Here I’m using the emoji to illustrate that an attacker can’t see the actual values submitted within the range queries — those are protected by the scheme — nor can she see the actual values of the result rows, since the fancy encryption scheme hides all this stuff. All the attacker sees is that a range query came in, and some specific rows were scooped up off disk after running the fancy search protocol.
So what can the attacker learn from the above queries? Surprisingly: quite a bit.
At very minimum, the attacker learns that Query 2 returned all of the same records as Query 1. Thus the range of the latter query clearly somewhat overlaps with the range of the former. There is an additional record (row 43) that is not within the range of Query 1. That tells us that row 43 must must be either the “next” greater or smaller record than each of rows (1, 3, 5). That’s useful information.
Get enough useful information, it turns out that it starts to add up. In 2016, Kellaris, Kollios, Nissim and O’Neill showed that if you know the distribution of the query range endpoints — for example, if you assumed that they were uniformly random — then you can get more than just the order of records. You can reconstruct the exact value of every record in the database.
This result is statistical in nature. If I know that the queries are uniformly random, then I can model how often a given value (say, Age=34 out of a range 1-120) should be responsive to a given random query results. By counting the actual occurrences of a specific row after many such queries, I can guess which rows correlate to specific record values. The more queries I see, the more certain I can be.The Kellaris et al. paper shows that this takes 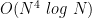
In practice the Kellaris et al. results mean that database fields with small domains (like ages) could be quickly reconstructed after observing a reasonable number of queries from a legitimate user, albeit one who likes to query everything randomly.
So that’s really bad!
The main bright spot in this research —- at least up until recently — was that many types of data have much larger domains. If you’re dealing with salary data ranging from, say, $1 to $200,000, then N=200,000 and this dominant 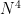
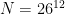
I bet we can’t ignore these results, can we?
Indeed, it seems that we can’t. The reason we can’t sit on our laurels and hope for an attacker to die of old age recovering large-domain data sets is due to something called approximate database reconstruction, or 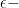
The setting here is the same: an attacker sits and watches an attacker make (uniformly random) range queries. The critical difference is that this attacker isn’t trying to get every database record back at its exact value: she’s willing to tolerate some degree of error, up to an additive 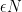
Which finally brings us to this new GLMP paper, which puts 

The important thing to notice about these results is that the value N has dropped out of the equation. The only term that’s left is the error term
Big-O notation doesn’t do anything for me: what does this even mean?
Big-O notation is beloved by computer scientists, but potentially meaningless in practice. There could be huge constants in these terms that render these attacks completely impractical. Besides, weird equations involving epsilon characters are impossible for humans to understand.
Sometimes the easiest way to understand a theoretical result is to plug some actual numbers in and see what happens. GLMP were kind enough to do this for us, by first generating several random databases — each containing 1,000 records, for different values of N. They then ran their recovery algorithm against a simulated batch of random range queries to see what the actual error rate looked like as the query count increased.
Here are their results:

Even after just 100 queries, the error in the dataset has been hugely reduced, and after 500 queries the contents of the database — excluding the tails — can be recovered with only about a 1-2% error rate.
Moreover, these experimental results illustrate the fact that recovery works at many scales: that is, they work nearly as well for very different values of N, ranging from 100 to 100,000. This means that the only variable you really need to think about as an attacker is: how close do I need my reconstruction to be? This is probably not very good news for any real data set.
How do these techniques actually work?
The answer is both very straightforward and deeply complex. The straightforward part is simple; the complex part requires an understanding of Vapnik-Chervonenkis learning theory (VC-theory) which is beyond the scope of this blog post, but is explained in the paper.
At the very highest level the recovery approach is similar to what’s been done in the past: using response probabilities to obtain record values. This paper does it much more efficiently and approximately, using some fancy learning theory results while making a few assumptions.
At the highest level: we are going to assume that the range queries are made on random endpoints ranging from 1 to N. This is a big assumption, and more on it later! Yet with just this knowledge in hand, we learn quite a bit. For example: we can compute the probability that a potential record value (say, the specific salary $34,234) is going to be sent back, provided we know the total value lies in the range 1-N (say, we know all salaries are between $1 and $200,000).
If we draw the resulting probability curve in freehand, it might look something like the chart below. This isn’t actually to scale or (probably) even accurate, but it illustrates a key point: by the nature of (random) range queries, records near the center are going to have a higher overall chance of being responsive to any given query, since the “center” values are more frequently covered by random ranges, and records near the extreme high- and low values will be chosen less frequently.

The high-level goal of database reconstruction is to match the observed response rate for a given row (say, row 41) to the number of responses we’d expect see for different specific concrete values in the range. Clearly the accuracy of this approach is going to depend on the number of queries you, the attacker, can observe — more is better. And since the response rates are lower at the highest and lowest values, it will take more queries to guess outlying data values.
You might also notice that there is one major pitfall here. Since the graph above is symmetric around its midpoint, the expected response rate will be the same for a record at .25*N and a record at .75*N — that is, a $50,000 salary will be responsive to random queries at precisely same rate as a $150,000 salary. So even if you get every database row pegged precisely to its response rate, your results might still be “flipped” horizontally around the midpoint. Usually this isn’t the end of the world, because databases aren’t normally full of unstructured random data — high salaries will be less common than low salaries in most organizations, for example, so you can probably figure out the ordering based on that assumption. But this last “bit” of information is technically not guaranteed to come back, minus some assumptions about the data set.
Thus, the recovery algorithm breaks down into two steps: first, observe the response rate for each record as random range queries arrive. For each record that responds to such a query, try to solve for a concrete value that minimizes the difference between the expected response rate on that value, and the observed rate. The probability estimation can be made more efficient (eliminating a quadratic term) by assuming that there is at least one record in the database within the range .2N-.3N (or .7N-.8N, due to symmetry). Using this “anchor” record requires a mild assumption about the database contents.
What remains is to show that the resulting attack is efficient. You can do this by simply implementing it — as illustrated by the charts above. Or you can prove that it’s efficient. The GLMP paper uses some very heavy statistical machinery to do the latter. Specifically, they make use of a result from Vapnik-Chervonenkis learning theory (VC-theory), which shows that the bound can be derived from something called the VC-dimension (which is a small number, in this case) and is unrelated to the actual value of N. That proof forms the bulk of the result, but the empirical results are also pretty good.
Is there anything else in the paper?
Yes. It gets worse. There’s so much in this paper that I cannot possibly include it all here without risking carpal tunnel and boredom, and all of it is bad news for the field of encrypted databases.
The biggest additional result is one that shows that if all you want is an approximate ordering of the database rows, then you can do this efficiently using something called a PQ tree. Asymptotically, this requires 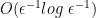
What’s even more important about this ordering result is that it works independently of the query distribution. That is: we do not need to have random range queries in order for this to work: it works reasonably well regardless of how the client puts its queries together (up to a point).
Even better, the authors show that this ordering, along with some knowledge of the underlying database distribution — for example, let’s say we know that it consists of U.S. citizen last names — can also be used to obtain approximate database reconstruction. Oy vey!
And there’s still even more:
- The authors show how to obtain even more efficient database recovery in a setting where the query range values are known to the attacker, using PAC learning. This is a more generous setting than previous work, but it could be realistic in some cases.
- Finally, they extend this result to prefix and suffix queries, as well as range queries, and show that they can run their attacks on a dataset from the Fraternal Order of Police, obtaining record recovery in a few hundred queries.
In short: this is all really bad for the field of encrypted databases.
So what do we do about this?
I don’t know. Ignore these results? Fake our own deaths and move into a submarine?
In all seriousness: database encryption has been a controversial subject in our field. I wish I could say that there’s been an actual debate, but it’s more that different researchers have fallen into different camps, and nobody has really had the data to make their position in a compelling way. There have actually been some very personal arguments made about it.
The schools of thought are as follows:
The first holds that any kind of database encryption is better than storing records in plaintext and we should stop demanding things be perfect, when the alternative is a world of constant data breaches and sadness.
To me this is a supportable position, given that the current attack model for plaintext databases is something like “copy the database files, or just run a local SELECT * query”, and the threat model for an encrypted database is “gain persistence on the server and run sophisticated statistical attacks.” Most attackers are pretty lazy, so even a weak system is probably better than nothing.
The countervailing school of thought has two points: sometimes the good is much worse than the perfect, particularly if it gives application developers an outsized degree of confidence of the security that their encryption system is going to provide them.
If even the best encryption protocol is only throwing a tiny roadblock in the attacker’s way, why risk this at all? Just let the database community come up with some kind of ROT13 encryption that everyone knows to be crap and stop throwing good research time into a problem that has no good solution.
I don’t really know who is right in this debate. I’m just glad to see we’re getting closer to having it.
