This page has some wonky notes about the Secure Remote Password protocol. TL;DR: I don’t like it. It’s also not obviously broken. But it’s inefficient and you should use OPAQUE.
Like most PAKE protocols, SRP has two phases. In the sign-up phase, the user registers a “password verifier” with the server. This value is not actually the password itself. It’s not even the hashed password. It’s actually a one-way function of the hashed password, of the form 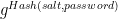
Thus the login process looks something like this:

The SRP (v4) protocol
To generate the verifier, the client first picks some salt, and then computes the following. The values 
x = Hash(salt, passwd) (salt is chosen randomly) v = g^x (computes password verifier)
The server stores the verifier (v, salt) in its database, along with the User ID. To run the actual PAKE protocol, the client and server execute the following steps using the (server)’s stored verifier 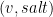
Client -> Svr: User ID, A = g^a (identifies self, a = random number)
Svr -> Client: salt, B = kv + g^b (sends salt, b = random number)
Both: u = H(A, B)
Client: x = Hash(salt, passwd) (user enters password)
Client: S = (B - kg^x) ^ (a + ux) (computes session key)
Client: K = H(S)
Svr: S = (Av^u) ^ b (computes session key)
Svr: K = H(S)
If the protocol above is successful — that is, the client used the right password — the client and server should now share a session key K. To verify that this is the case, the SRP specification recommends they send two additional “check” messages:
Client -> Svr: M = H(H(N) xor H(g), H(I), salt, A, B, K) Svr -> Client: H(A, M, K)
Both parties should have all the ingredients to check the correctness of the value sent by the other party, and that’s the ballgame.
What the hell is going on here?
I’ll be honest, that even to a cryptographer, the design rationale for SRP is not really clear. I mean, there are pieces that I recognize, and obviously some things make sense. Then there’s loads of weirdness.
The first thing you should notice is that SRP is, at its heart, basically an extension of the Diffie-Hellman protocol. The server picks a value 

The next thing you’ll notice is that the server’s first message to the client is:
salt, B = kv + g^b
Which is pretty significant, because this single message actually embeds two different sensitive values that the server stores, and should not leak to an attacker pretending to be the client. The first sensitive value is the salt. Maybe this is ok, since salt isn’t exactly required to be secret — however, giving it away (to a thus-far totally untrusted client) isn’t a really the best idea either. It allows an attacker to perform pre-computation: i.e., the attacker can build a dictionary of candidate password hashes prior to compromising the server’s database.
In this setting, however, the verifier value 



If 


This argument doesn’t quite hold up, for the simple reason that $latex g^b$ can never be equal to 0, so there is a tiny (negligible) bias. It might hold up if we were using multiplication instead of addition, since in that case the 
However, even if we ignore the small bias, using this line of reasoning requires us to choose 

Note that you cannot safely use standard Diffie-Hellman groups with SRP! So be aware of that.
Another possible concern is that a malicious server could attempt to craft a message 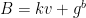

Lest you think these positive results are all by design, I would note that there are three prior versions (Update: no, it’s five prior versions, oy vey) of the SRP protocol, each of which contains vulnerabilities. So the current status seems to have arrived through a process of attrition, more than design.
What claims does the SRP security analysis make?
The original SRP paper claims contains a section discussing the security of the protocol. Unfortunately, this analysis doesn’t really contain a proof of security. Instead, it mostly talks about attacks. (Recall that several protocol flaws were discovered subsequent to the initial publication, which illustrates the weakness of the don’t-prove-security approach.) Here’s an example of the kind of thing the original SRP paper says:
“SRP has been carefully designed to thwart the active attacks illustrated in Sections 3.2.3 and 3.2.4. Although it is difficult to determine conclusively whether or not these precautions bulletproof the protocol completely from all possible active attacks, SRP resists all the well-known attacks that have plagued existing authentication mechanisms, such as the Denning-Sacco attack mentioned previously”
The paper does include a formal reduction from SRP to the Diffie-Hellman protocol — which means SRP is no worse to a passive attacker than Diffie-Hellman. Unfortunately, all this proves is that the protocol stands up to passive attacks, not that it can handle any sort of active attacks. That’s nice, but not exactly useful.
The fact of the matter is that SRP is a relatively simple PAKE protocol. It should be possible to provide a strong security proof, and yet SRP has none. This is not a good situation for a widely-used protocol to be in.
What about elliptic curves?
I mentioned above that SRP uses addition in a place that you would normally expect to see multiplication. This seems like one of those harmless things that only cryptographers fret about, but it’s actually really quite unusual.
You see, protocols like Diffie-Hellman (on which SRP is based) are designed to be set in a cyclic group. In these groups, there is a “group operation” that can be realized in different ways, depending on the setting. In the integer setting that SRP uses, this operation is implemented as multiplication modulo p. If we were using an elliptic curve, we would use EC point addition as the group operation — an operation that is very different from integer addition — and provided the protocol used one of these two operations, the protocol would likely translate from one setting to the other. Indeed, this ease-of-translation is the reason that most Diffie-Hellman-type protocols can be implemented in either setting.
SRP is weird, in that its calculations use both addition and multiplication. This is fine — but requires the setting to be a ring, rather than a generic cyclic group. This requirement implicitly rules out any obvious translation of SRP to the more efficient elliptic curve-land, where a second operation is not available. It also makes any reasonable security proof somewhat challenging.
And this is kind of a big deal for efficiency. The reason the EC thing is a big deal is that to get equivalent security for finite field (integer) arithmetic, we have to use much larger keys. For example, a 256-bit elliptic curve is believed to provide the same security as a mod p group of size 3,072 bits or more. Increasing to 512-bit curves can require equivalent non-EC keys of over 16,000 bits. This is a big hit to take.
In summary?
In summary, SRP is just weird. It was created in 1998 and bears all the marks of a protocol invented in the prehistoric days of crypto. It’s been repeatedly broken in various ways, though the most recent (v4) revision doesn’t seem obviously busted — as long as you implement it carefully and use the right parameters. It has no security proof worth a damn, though some will say this doesn’t matter (I disagree with them.) SRP leaks salt to untrusted users by design, which is a problem, and finally, it’s inefficient because it can’t be implemented in the EC setting.
In conclusion: you should not use SRP in 2018. There are much better PAKE protocols with substantially better properties, like OPAQUE.
